




热点分裂——有效解决数据热点
对于热点数据,PolarDB分布式版支持两种处理方式:
第一种方案是将热点数据所在的分区数据迁移到特定的数据节点,让热点数据以独享存储资源的方式服务业务,能够实现热点数据不影响非热点数据的业务。具体操作步骤如下:
执行以下语句,将特定的热点数据提取到一个单独的分区。
ALTER TABLEGROUP #tgName EXTRACT to PARTITION #hotPartitionName BY HOT VALUE(#keyVal)执行以下语句,将这个单独的分区调度到指定的物理资源。
ALTER TABLEGROUP #tgName MOVE PARTITIONS #hotPartitionName TO #dn
如果热点数据突破了机器的单点性能,在PolarDB-X中可以对其采用第二种处理方法,通过以下命令将热点数据散列,更好的支持业务的线性扩展:
ALTER TABLEGROUP #tgName SPLIT INTO PARTITIONS #hotPartitionNamePrefix #N BY HOT VALUE(#keyVal);以上命令可以将keyVal对应的热点数据分裂成N份,并且将分裂后的分区名字加上指定的前缀,然后将新分裂后的分区均匀的调度到不同的数据节点,从而将热点数据在不同数据节点中线性分布,消除数据热点。
分区调度——更灵活的数据均衡
DRDS模式的分库分表使用的是按哈希取模的路由方式,分库与分表位置是强绑定的(即第n号分库必须包含第m号分表,这些库表对应关系不能修改)。这意味着,除非对全表数据进行rehash,否则所有分表都不能被分裂、合并与迁移。
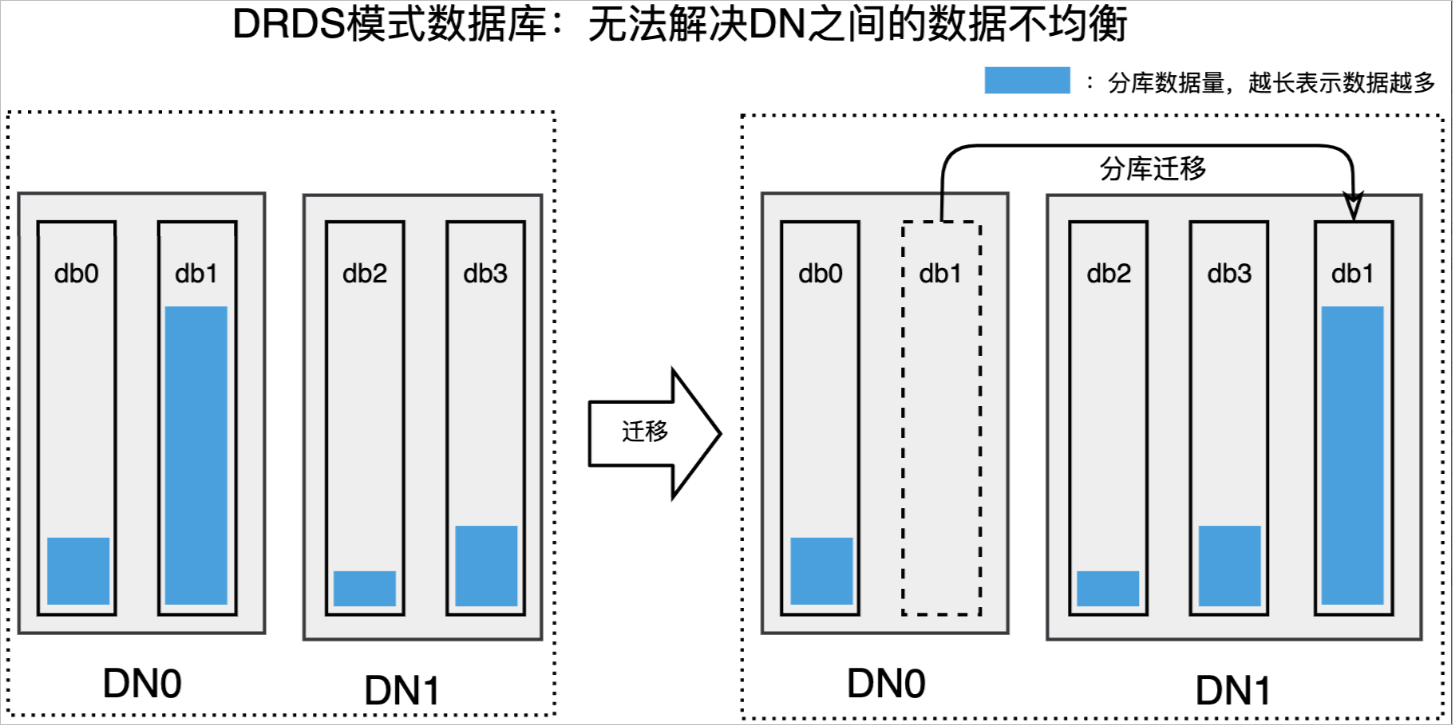
由于分表不能随意的迁移到其他DN(数据节点),调度的基本单位就是一个分库,要调度必须整个分库一起调度,粒度很大,如果某个分库的数据量很大,不管怎么调度,DN之间都无法做到数据均衡(如下图所示)。
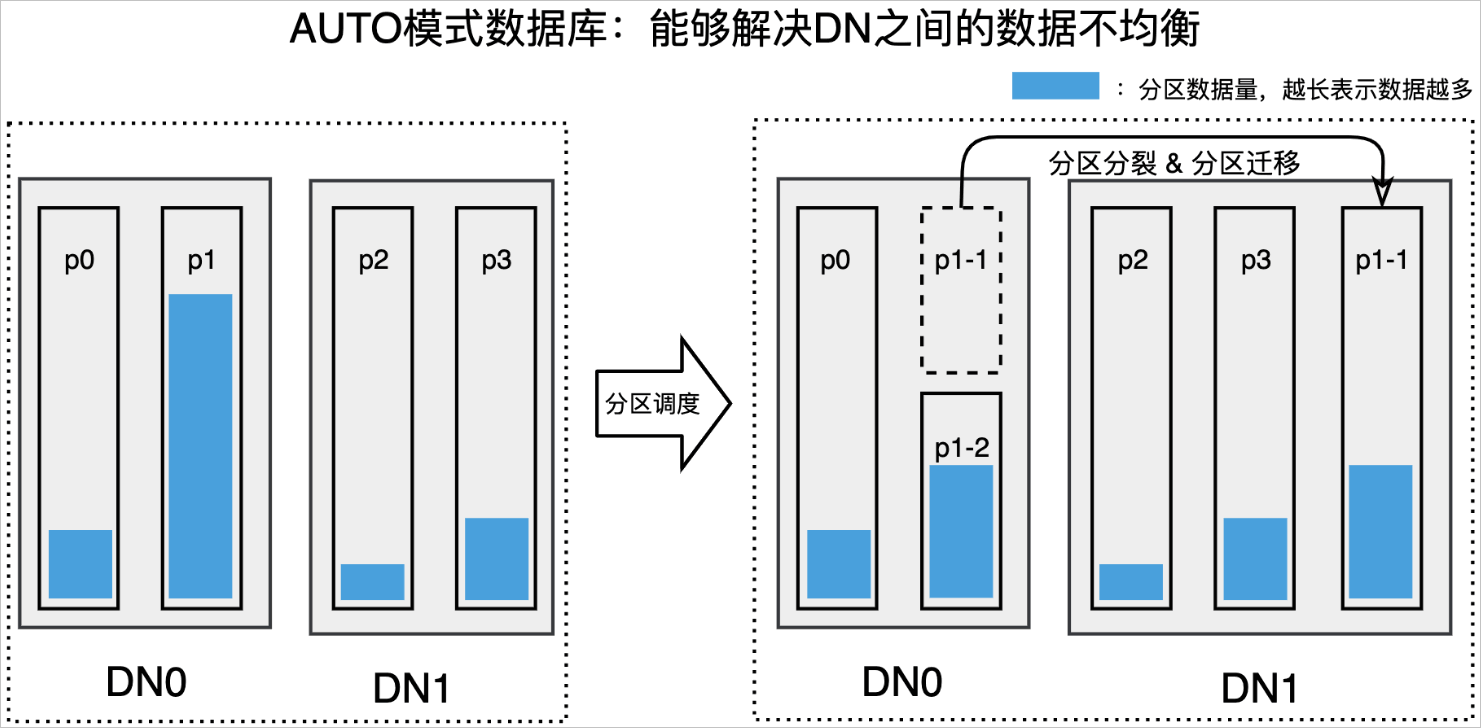
但是,AUTO模式的分区表由于采用了一致性哈希的路由算法,它的分区可以更灵活的进行合并、分裂与迁移,分区可以按需调度到指定的DN中,并且不会影响到不相关的分区数据。通过分区的合并分离等操作并结合分区调度,PPolarDB分布式版可以将数据均匀的分布到各个DN中(如下图所示),从而实现DN间的数据均衡。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
