




点击蓝字 关注我们

前言
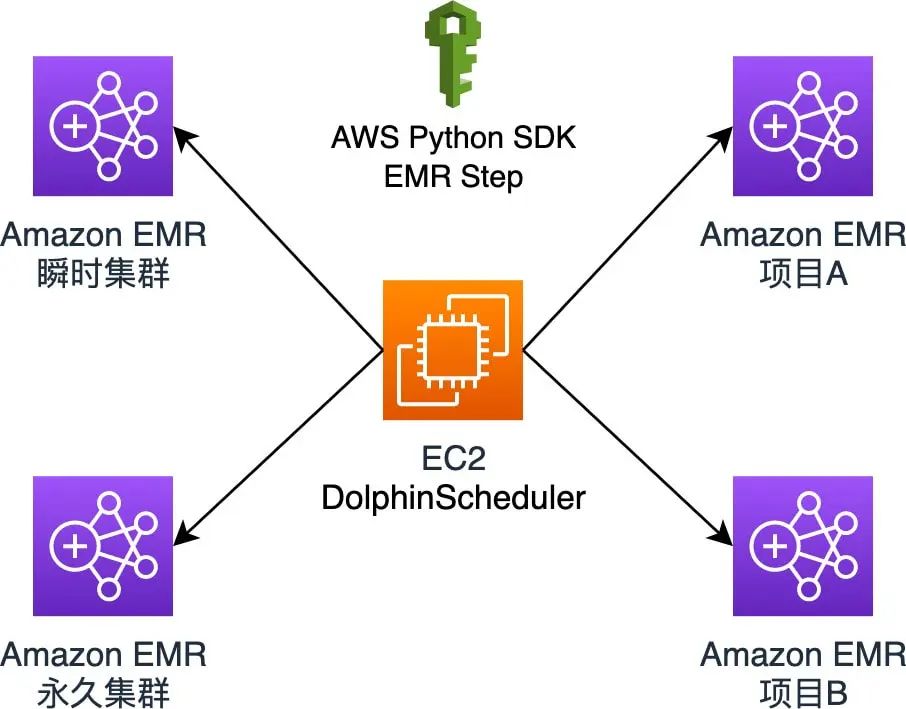
Amazon EMR
Apache DolphinScheduler
“
特性
可视化 DAG:⽤户友好的,通过拖拽定义工作流的,运行时控制工具模块化 操作:模块化,有助于轻松定制和维护
支持多种任务类型:支持 Shell、MR、Spark、SQL 等 10 余种任务类型,支持跨语言 易于扩展丰富的工作流操作:⼯作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数
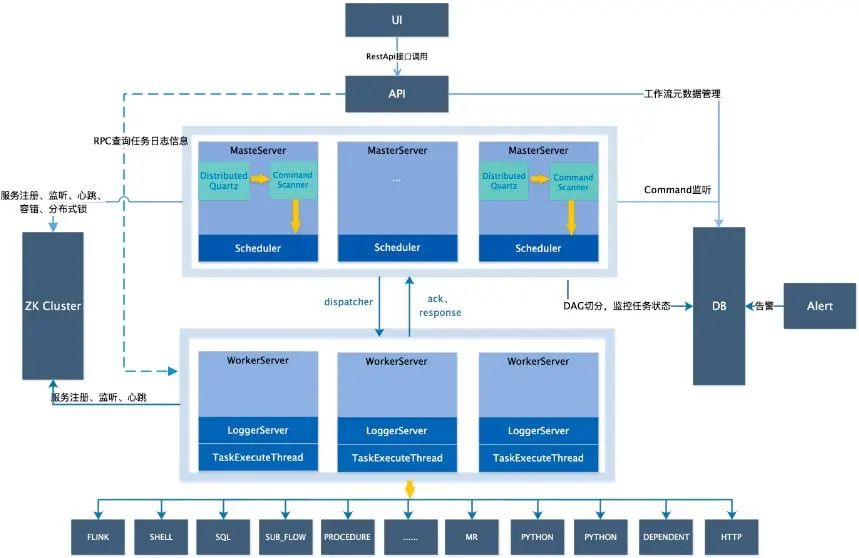
以 DAG 图的方式将 Task 按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态 支持丰富的任务类型:Shell、MR、Spark、SQL(mysql、oceanbase、postgresql、hive、sparksql)、Python、Sub_Process、Procedure 等 支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill 任务等操作 支持工作流优先级、任务优先级及任务的故障转移及任务超时告警/失败 支持工作流全局参数及节点自定义参数设置 支持资源文件的在线上传/下载,管理等,支持在线文件创建、编辑 支持任务日志在线查看及滚动、在线下载日志等 实现集群 HA,通过 Zookeeper 实现 Master 集群和 Worker 集群去中心化 支持对 Master/Worker CPU load,memory,CPU 在线查看 支持工作流运行历史树形/甘特图展示、支持任务状态统计、流程状态统计 支持补数 支持多租户
安装 DolphinScheduler
单机部署:Standalone 仅适用于 DolphinScheduler 的快速体验 伪集群部署:伪集群部署目的是在单台机器部署 DolphinScheduler 服务,该模式下 master、worker、api server 都在同⼀台机器上 集群部署:集群部署目的是在多台机器部署 DolphinScheduler 服务,用于运行⼤量任务情况
java -versionopenjdk version "1.8.0_362"OpenJDK Runtime Environment (build 1.8.0_362-b08) OpenJDK 64-Bit Server VM (build 25.362-b08, mixed mode)
bin/zkServer.sh status/usr/bin/javaZooKeeper JMX enabled by defaultUsing config: /usr/local/src/apache-zookeeper-3.8.1-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false.Mode: standalone

aws --versionaws-cli/2.11.4 Python/3.11.2 Linux/5.10.167-147.601.amzn2.x86_64 exe/x86_64.amzn.2 prompt/off
python --versionPython 3.9.1
cd usr/local/srcwget https://dlcdn.apache.org/dolphinscheduler/3.1.4/apache-dolphinscheduler-3.1.4-bin.tar.gz
# 创建用户需使用 root 登录useradd dolphinscheduler# 添加密码echo "dolphinscheduler" | passwd --stdin dolphinscheduler# 配置 sudo 免密sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' etc/sudoerssed -i 's/Defaults requirett/#Defaults requirett/g' etc/sudoers# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限cd usr/local/srcchown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-*-bin
# 切换 dolphinscheduler 用户su dolphinschedulerssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keys# 注意:配置完成后,可以通过运行命令 ssh localhost 判断是否成功,如果不需要输⼊密码就能 ssh 登陆则证明成功
cd usr/local/src# 下载 mysql-connectorwget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.31.tar.gztar -zxvf mysql-connector-j-8.0.31.tar.gz# 驱动拷贝cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/api-server/libs/cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/alert-server/libs/cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/master-server/libs/cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/worker-server/libs/cp mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar ./apache-dolphinscheduler-3.1.4-bin/tools/libs/# 安装 mysql 客户端# 修改 {mysql-endpoint} 为你 mysql 连接地址# 修改 {user} 和 {password} 为你 mysql ⽤户名和密码mysql -h {mysql-endpoint} -u{user} -p{password}mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;# 修改 {user} 和 {password} 为你希望的用户名和密码mysql> CREATE USER '{user}'@'%' IDENTIFIED BY '{password}';mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%';mysql> CREATE USER '{user}'@'localhost' IDENTIFIED BY '{password}';mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost';mysql> FLUSH PRIVILEGES;修改数据库配置vi bin/env/dolphinscheduler_env.sh# Database related configuration, set database type, username and password # 修改 {mysql-endpoint} 为你 mysql 连接地址# 修改 {user} 和 {password} 为你 mysql ⽤户名和密码,{rds-endpoint}为数据库连接地址export DATABASE=${DATABASE:-mysql}export SPRING_PROFILES_ACTIVE=${DATABASE}export SPRING_DATASOURCE_URL="jdbc:mysql://{rds-endpoint}/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"export SPRING_DATASOURCE_USERNAME={user}export SPRING_DATASOURCE_PASSWORD={password}# 执行数据初始化bash apache-dolphinscheduler/tools/bin/upgrade-schema.sh
cd usr/local/src/apache-dolphinschedulervi bin/env/install_env.sh# 替换 IP 为 DolphinScheduler 所部署 EC2 私有 IP 地址ips=${ips:-"10.100.1.220"}masters=${masters:-"10.100.1.220"}workers=${workers:-"10.100.1.220:default"}alertServer=${alertServer:-"10.100.1.220"}apiServers=${apiServers:-"10.100.1.220"}installPath=${installPath:-"~/dolphinscheduler"}
cd usr/local/src/mv apache-dolphinscheduler-3.1.4-bin apache-dolphinschedulercd ./apache-dolphinscheduler# 修改 DolphinScheduler 环境变量vi bin/env/dolphinscheduler_env.shexport JAVA_HOME=${JAVA_HOME:-/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.362.b08-1.amzn2.0.1.x86_64}export PYTHON_HOME=${PYTHON_HOME:-/bin/python}
cd /usr/local/src/apache-dolphinschedulersu dolphinschedulerbash ./bin/install.sh
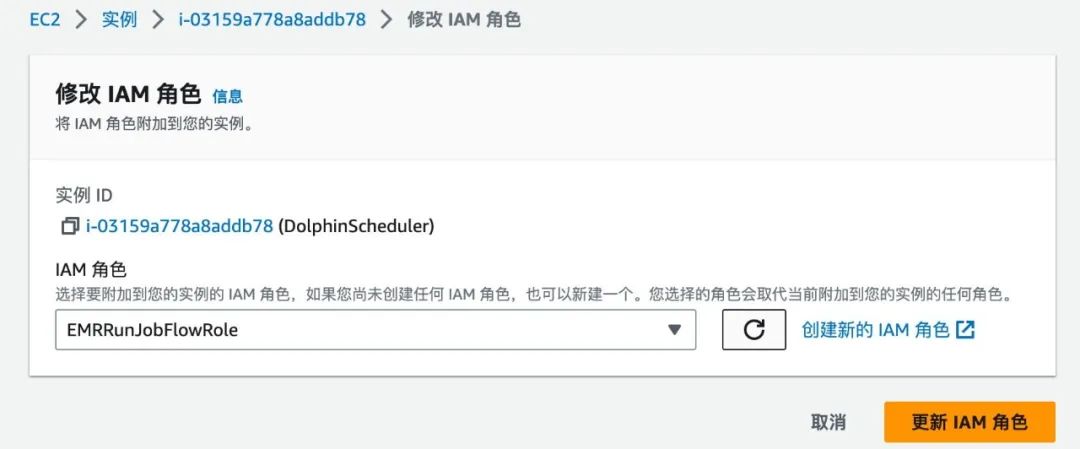
配置 DolphinScheduler

{"Version":"2012-10-17","Statement":[{"Sid":"ElasticMapReduceActions","Effect":"Allow","Action":["elasticmapreduce:RunJobFlow","elasticmapreduce:DescribeCluster","elasticmapreduce:AddJobFlowSteps","elasticmapreduce:DescribeStep","elasticmapreduce:TerminateJobFlows","elasticmapreduce:SetTerminationProtection"],"Resource":"*"},{"Effect":"Allow","Action":["iam:GetRole","iam:PassRole"],"Resource":["arn:aws:iam::accountid:role/EMR_DefaultRole","arn:aws:iam::accountid:role:role/EMR_EC2_DefaultRole"]}]}
sudu pip install boto3sudu pip install redis
使用DolphinScheduler进行作业编排
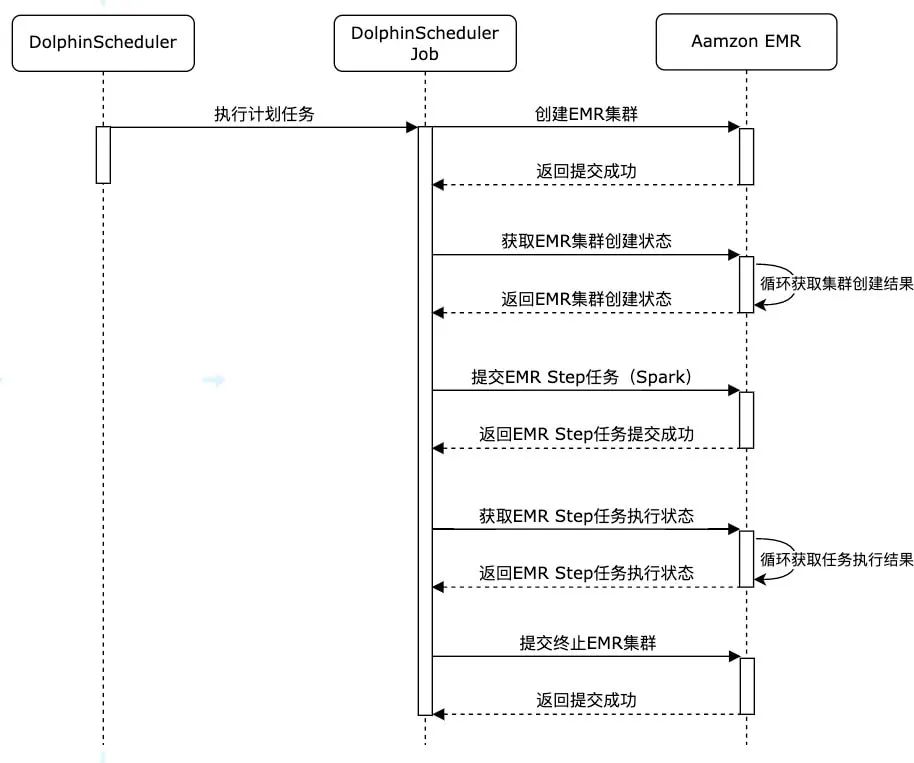
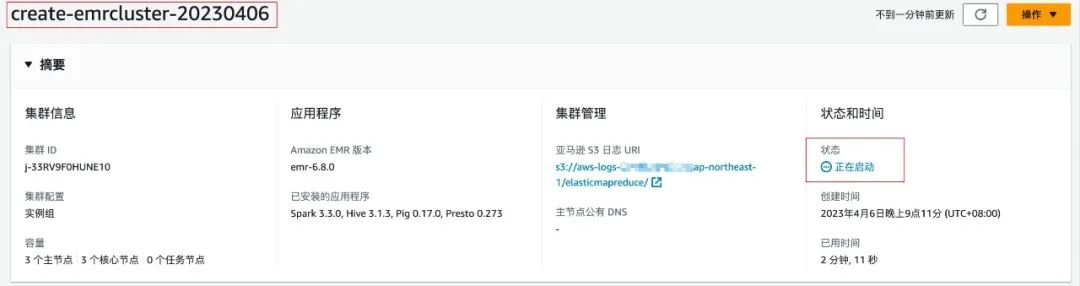
import boto3from datetime import dateimport redisdef run_job_flow():response = client.run_job_flow(Name='create-emrcluster-'+ d1,LogUri='s3://s3bucket/elasticmapreduce/',ReleaseLabel='emr-6.8.0',Instances={'KeepJobFlowAliveWhenNoSteps': False,'TerminationProtected': False,# 替换{Sunbet-id}为你需要部署的子网 id'Ec2SubnetId': '{Sunbet-id}',# 替换{Keypairs-name}为你 ec2 使用密钥对名称'Ec2KeyName': '{Keypairs-name}','InstanceGroups': [{'Name': 'Master','Market': 'ON_DEMAND','InstanceRole': 'MASTER','InstanceType': 'm5.xlarge','InstanceCount': 3,'EbsConfiguration': {'EbsBlockDeviceConfigs': [{'VolumeSpecification': {'VolumeType': 'gp3','SizeInGB': 500},'VolumesPerInstance': 1},],'EbsOptimized': True},},{'Name': 'Core','Market': 'ON_DEMAND','InstanceRole': 'CORE','InstanceType': 'm5.xlarge','InstanceCount': 3,'EbsConfiguration': {'EbsBlockDeviceConfigs': [{'VolumeSpecification': {'VolumeType': 'gp3','SizeInGB': 500},'VolumesPerInstance': 1},],'EbsOptimized': True},}],},Applications=[{'Name': 'Spark'},{'Name': 'Hive'},{'Name': 'Pig'},{'Name': 'Presto'}],Configurations=[{ 'Classification': 'spark-hive-site','Properties': {'hive.metastore.client.factory.class': 'com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory'}},{ 'Classification': 'hive-site','Properties': {'hive.metastore.client.factory.class': 'com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory'}},{ 'Classification': 'presto-connector-hive','Properties': {'hive.metastore.glue.datacatalog.enabled': 'true'}}],JobFlowRole='EMR_EC2_DefaultRole',ServiceRole='EMR_DefaultRole',EbsRootVolumeSize=100,# 集群空闲十分钟自动终止AutoTerminationPolicy={'IdleTimeout': 600})return responseif __name__ == "__main__":today = date.today()d1 = today.strftime("%Y%m%d")# {region}替换为你需要创建 EMR 的 Regionclient = boto3.client('emr',region_name='{region}')# 创建 EMR 集群clusterCreate = run_job_flow()job_id = clusterCreate['JobFlowId']# 使用 redis 来保存信息,作为 DolphinScheduler job step 的参数传递,也可以使用 DolphinScheduler 所使用的 mysql 或者其他方式存储# 替换{redis-endpoint}为你 redis 连接地址pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)r = redis.Redis(connection_pool=pool)r.set('cluster_id_'+d1, job_id)
import boto3import redisimport timefrom datetime import dateif __name__ == "__main__":today = date.today()d1 = today.strftime("%Y%m%d")# {region}替换为你需要创建 EMR 的 Regionclient = boto3.client('emr',region_name='{region}')# 替换{redis-endpoint}为你 redis 连接地址pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)r = redis.Redis(connection_pool=pool)# 获取创建的 EMR 集群 idjob_id = r.get('cluster_id_' + d1)print(job_id)while True:result = client.describe_cluster(ClusterId=job_id)emr_state = result['Cluster']['Status']['State']print(emr_state)if emr_state == 'WAITING':# EMR 集群创建成功breakelif emr_state == 'FAILED':# 集群创建失败# do something...breakelse:time.sleep(10)
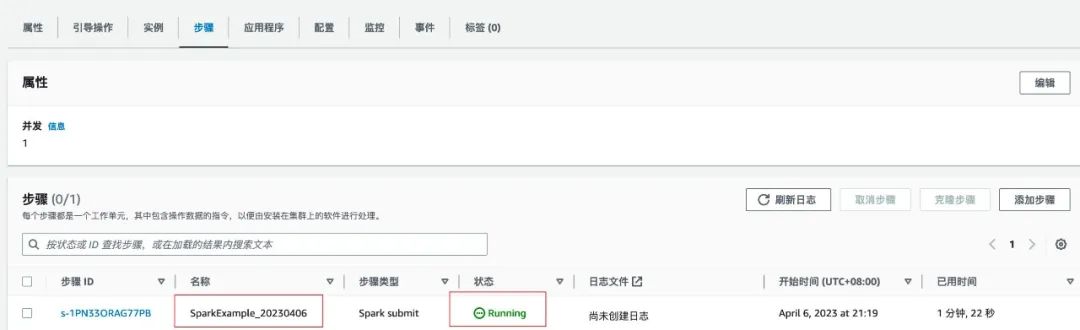
import timeimport reimport boto3from datetime import dateimport redisdef generate_step(step_name, step_command):cmds = re.split('\\s+', step_command)print(cmds)if not cmds:raise ValueErrorreturn {'Name': step_name,'ActionOnFailure': 'CANCEL_AND_WAIT','HadoopJarStep': {'Jar': 'command-runner.jar','Args': cmds}}if __name__ == "__main__":today = date.today()d1 = today.strftime("%Y%m%d")# {region}替换为你需要创建 EMR 的 Regionclient = boto3.client('emr',region_name='{region}')# 获取 emr 集群 id# 替换{redis-endpoint}为你 redis 连接地址pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)r = redis.Redis(connection_pool=pool)job_id = r.get('cluster_id_' + d1)# job 启动命令spark_submit_cmd = """spark-submits3://s3bucket/file/spark/spark-etl.pys3://s3bucket/input/s3://s3bucket/output/spark/"""+d1+'/'steps = []steps.append(generate_step("SparkExample_"+d1 , spark_submit_cmd),)# 提交 EMR Step 作业response = client.add_job_flow_steps(JobFlowId=job_id, Steps=steps)step_id = response['StepIds'][0]# 将作业 id 保存,以便于做任务检查r.set('SparkExample_'+d1, step_id)
import boto3import redisimport timefrom datetime import dateif __name__ == "__main__":today = date.today()d1 = today.strftime("%Y%m%d")# {region}替换为你需要创建 EMR 的 Regionclient = boto3.client('emr',region_name='{region}')# 替换{redis-endpoint}为你 redis 连接地址pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)r = redis.Redis(connection_pool=pool)job_id = r.get('cluster_id_' + d1)step_id = r.get('SparkExample_' + d1)print(job_id)print(step_id)while True:# 查询作业执行结果result = client describe_step(ClusterId=job_id,StepId=step_id)emr_state = result['Step']['Status']['State']print(emr_state)if emr_state == 'COMPLETED':# 作业执行完成breakelif emr_state == 'FAILED'# 作业执行失败# do somethine# ......breakelse:time.sleep(10)
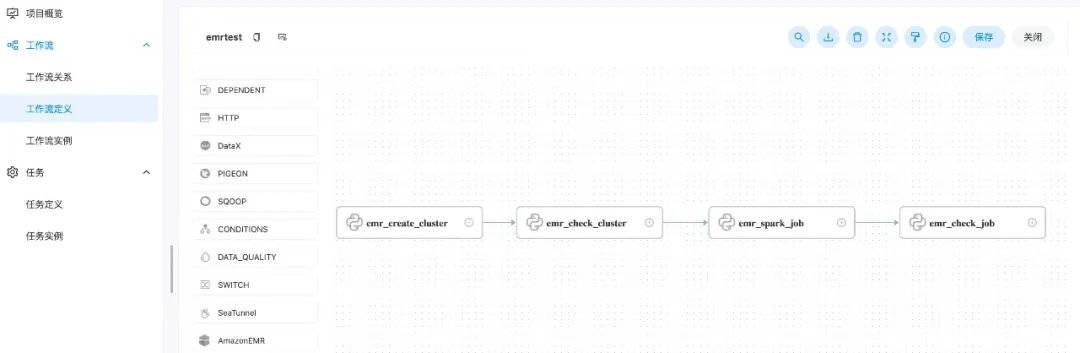


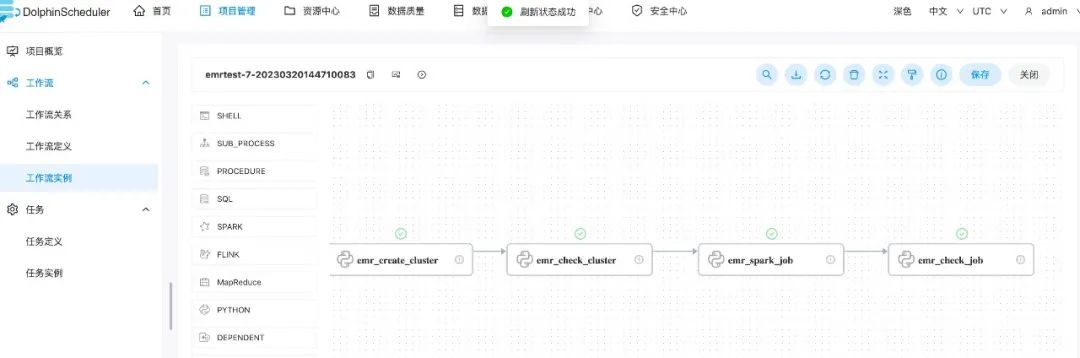
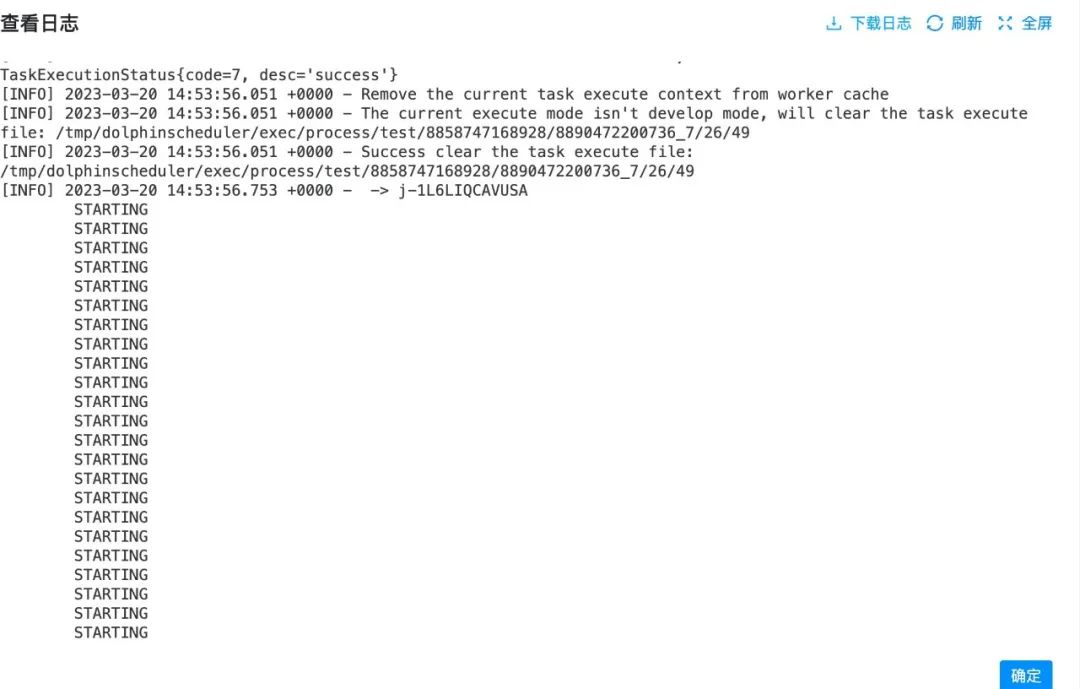
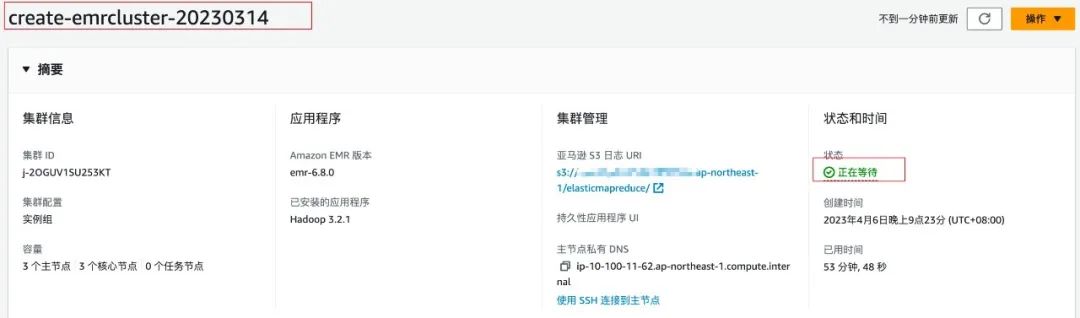
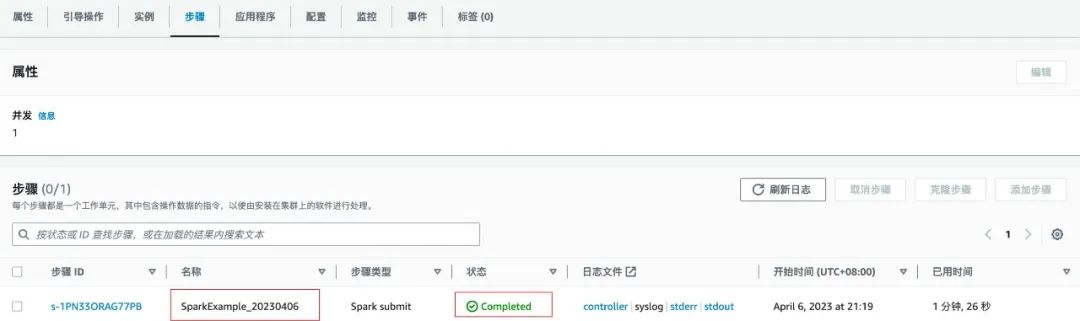
AutoTerminationPolicy={'IdleTimeout': 600}
import boto3from datetime import dateimport redisif __name__ == "__main__":today = date.today()d1 = today.strftime("%Y%m%d")# 获取集群 id# {region}替换为你需要创建 EMR 的 Regionclient = boto3.client('emr',region_name='{region}')# 替换{redis-endpoint}为你 redis 连接地址pool = redis.ConnectionPool(host='{redis-endpoint}', port=6379, decode_responses=True)r = redis.Redis(connection_pool=pool)job_id = r.get('cluster_id_' + d1)# 关闭集群终止保护client.set_termination_protection(JobFlowIds=[job_id],TerminationProtected=False)# 终止集群client.terminate_job_flows(JobFlowIds=[job_id])
总结
作者
王骁
AWS 解决方案架构师,负责基于 AWS 云计算方案架构的咨询和设计,在国内推广 AWS 云平台技术和各种解决方案,具有丰富的企业 IT 架构经验,目前侧重于于大数据领域的研究。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds,好友申请注明“入交流群+姓名+公司+职位信息“,群里是实名制,仅用于验证身份)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。

