




PolarDB PostgreSQL版(以下简称 PolarDB-PG)是一款阿里云自主研发的企业级数据库产品,采用计算存储分离架构,兼容 PostgreSQL 与 Oracle。PolarDB-PG 的存储与计算能力均可横向扩展,具有高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB-PG 具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载;还具有时空、向量、搜索、图谱等多模创新特性,可以满足企业对数据处理日新月异的新需求。
PolarDB-PG 支持多种部署形态:存储计算分离部署、X-Paxos 三节点部署、本地盘部署。
传统数据库的问题
随着用户业务数据量越来越大,业务越来越复杂,传统数据库系统面临巨大挑战,如:
- 存储空间无法超过单机上限。
- 通过只读实例进行读扩展,每个只读实例独享一份存储,成本增加。
- 随着数据量增加,创建只读实例的耗时增加。
- 主备延迟高。
PolarDB-PG 云原生数据库的优势
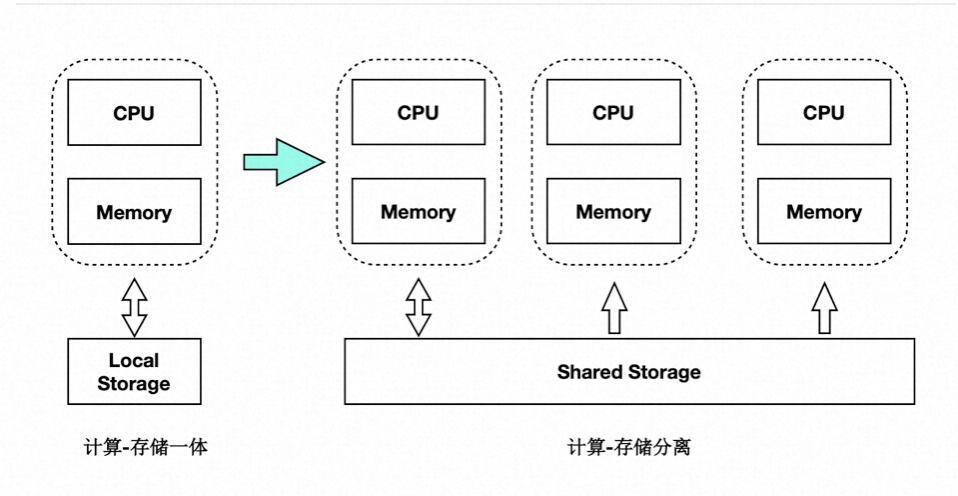

针对上述传统数据库的问题,阿里云研发了 PolarDB-PG 云原生数据库。采用了自主研发的计算集群和存储集群分离的架构。具备如下优势:
- 扩展性:存储计算分离,极致弹性。
- 成本:共享一份数据,存储成本低。
- 易用性:一写多读,透明读写分离。
- 可靠性:三副本、秒级备份。
PolarDB-PG 整体架构概述
下面会从两个方面来解读 PolarDB-PG 的架构,分别是:存储计算分离架构、HTAP 架构。
存储计算分离架构概述

PolarDB-PG 是存储计算分离的设计,存储集群和计算集群可以分别独立扩展:
- 当计算能力不够时,可以单独扩展计算集群。
- 当存储容量不够时,可以单独扩展存储集群。
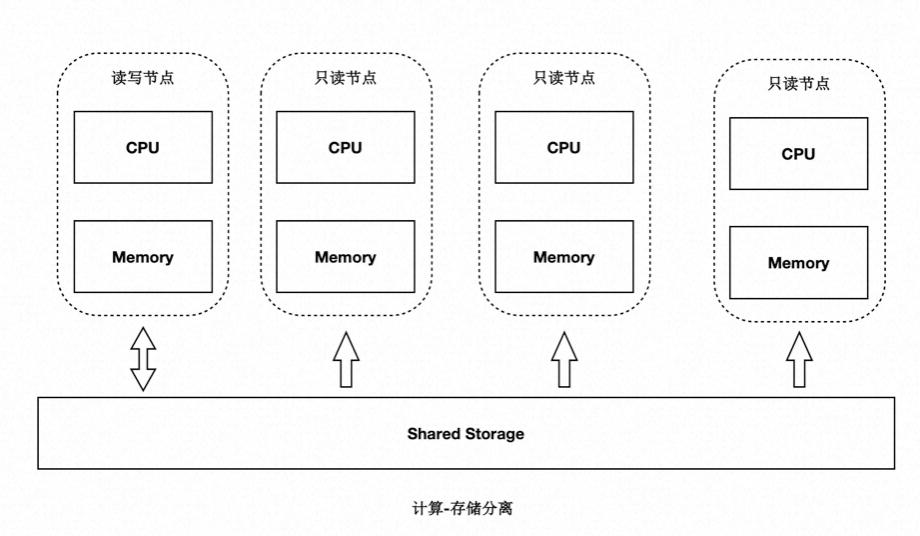
基于 Shared-Storage 后,主节点和多个只读节点共享一份存储数据,主节点刷脏不能再像传统的刷脏方式了,否则:
- 只读节点去存储中读取的页面,可能是比较老的版本,不符合他自己的状态。
- 只读节点指读取到的页面比自身内存中想要的数据要超前。
- 主节点切换到只读节点时,只读节点接管数据更新时,存储中的页面可能是旧的,需要读取日志重新对脏页的恢复。
对于第一个问题,我们需要有页面多版本能力;对于第二个问题,我们需要主库控制脏页的刷脏速度。
HTAP 架构概述
读写分离后,单个计算节点无法发挥出存储侧大 IO 带宽的优势,也无法通过增加计算资源来加速大的查询。我们研发了基于 Shared-Storage 的 MPP 分布式并行执行,来加速在 OLTP 场景下 OLAP 查询。
PolarDB-PG 支持一套 OLTP 场景型的数据在如下两种计算引擎下使用:
- 单机执行引擎:处理高并发的 OLTP 型负载。
- 分布式执行引擎:处理大查询的 OLAP 型负载。
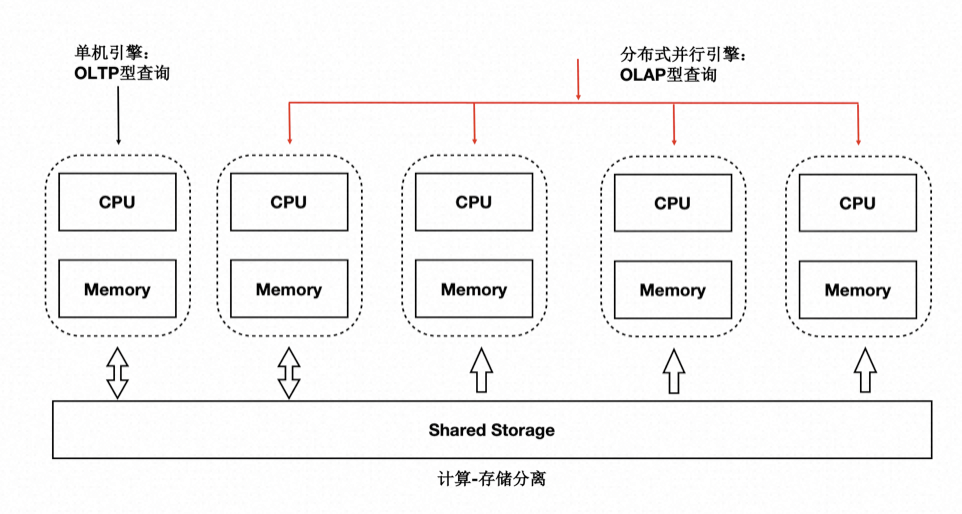

在使用相同的硬件资源时性能达到了传统 MPP 数据库的 90%,同时具备了 SQL 级别的弹性:在计算能力不足时,可随时增加参与 OLAP 分析查询的 CPU,而数据无需重分布。
