前言
B+树是上世纪70年代针对硬盘和单核处理器设计的。为了减少机械硬盘的寻道次数,它采用多叉树结构,降低了索引结构的深度,减少了外存访问延迟对性能的影响。因为B+树在单键值和范围查找操作等方面具有良好的性能,所以它作为索引结构的构建模块,在长达四十多年的各类大型系统发展历程中发挥了极其重要的作用。此外,为了提高B+树在多核处理器场景下的并发性能,学术界/工业界进行了长达数十年的研究。在前文《B+树并发控制机制的前世今生》中,笔者详细分析了latch-based B+树自上世纪70年以来的发展历程。业界在多个角度优化了B+树的并发机制:1. 减小加锁粒度,从索引粒度的S/X锁到树节点粒度的S/X/SX锁;2. 降低加锁频率,利用基于版本号的乐观读机制 + 自底向上的细粒度写锁。因此,B+树的多线程扩展性得到了极大提升。然而,在四十多年的硬件发展历程中,不管是片上处理器的架构设计,还是存储器件的访问特性,都发生了颠覆性的变化。在面对新的硬件特性时,B+树原有的结构设计很大程度上导致它无法发挥出最优的硬件性能,无法榨干所有的硬件红利,这主要表现在两个方面:
多核处理器的迅速发展。随着摩尔定律的逐渐失效,单核处理器的性能无法持续地线性增长,CPU制造商们向多核处理器方向转变。为了发挥出多核处理器的性能优势,索引结构需要设计更加优秀的并发控制机制。然而,现有的latch-based B+树存在两个难以解决的问题:1. 修改树节点的线程需要先持有树节点的锁,锁机制会带来一定程度的堵塞,并且可能导致死锁/活锁等问题;2. 传统B+树的修改操作是本地更新的(In-place),这会导致其它处理器上包含该行数据的缓存行失效,这类开销称之为cache coherence cost。尤其在以NUMA架构为基础的多核处理器平台上,传统in-place更新机制容易引入昂贵的cache coherence cost(具体看前文《B+树并发控制机制的前世今生》)。上述两个问题会随着线程数量的增加变得更加严重,所以传统latch-based B+树依然容易引入性能瓶颈,限制了它的多线程扩展性。存储器件的颠覆性变革。传统磁盘的I/O寻道延迟很高,这导致它的访问延迟(~10ms)远高于内存(~100ns),并且它的随机访问性能远低于顺序访问性能,这对上层软件系统的设计产生了极大的影响。为了解决这一问题,存储器件的演进方向主要包含两类:(1)闪存(Solid State Disk,SSD)将I/O访问延迟降低了三个数量级(~10us),并且它的随机读取性能与顺序读取性能相似;(2)非易失内存(Non-Volatile Main Memory,NVMM)具备传统内存的性能和字节寻址的特性,并且具备磁盘的数据持久性。它将传统的快速易失性内存+慢速持久性外存两层存储架构合并成字节寻址的单层持久性内存架构,这将对上层软件系统的设计产生颠覆性的变化。然而,B+树是针对磁盘设计的,无法完全发挥出新型存储器件的性能优势。
正因此,笔者不禁发问:在处理器和存储器技术迅速发展的今天,B+树的演进方向又在何方?为了解答这个问题,笔者阅读了几十年来数十篇B+树的代表性论文,尝试分析出B+树的未来优化方向,故有此文。本文将从两个方向讨论B+树的发展方向:
多核处理器+闪存场景下B+树的演进方向。Bw树[3]作为范围索引的构建模块,被使用在SQL Server的Hekaton内存OLTP引擎[1,2]。笔者以Bw树为例,详细分析Bw树的索引设计[3]、存储层设计[4]和Bw树在数据库中的实际应用[1,2],并分析它的优势劣势[5]。多核处理器+非易失内存场景下B+树的演进方向。首先,由于非易失内存的特性极大影响了B+树的设计,这会导致B+树结构发生较大的变化,因此笔者先分析单线程场景下B+树的设计与优化[8-12]。其次,笔者将分析多线程场景下B+树的设计。与latch-based B+树不同,笔者将分析一些新的并发控制机制,包括利用硬件事务内存(Hardware Transaction Memory,HTM)的FPTree[11]和Bw树在SCM上的变体latch-free BzTree[13]。
由于篇幅和时间限制,本文着力于讨论多核处理器+闪存场景下B+树的演进方向,而将多核处理器+非易失内存场景下B+树的演进方向放在下一篇文章中分析。本文的部分观点可能尚不完善,读者可根据文章末尾的引用论文,深入阅读相关工作。
多核处理器 + 闪存场景下的B+树
如上文所述,多核处理器+闪存场景下的B+树需要克服多核处理器和闪存特性带来的问题。
- 针对多核处理器的两个瓶颈问题,Bw树提出了相应的解决方案:1. 对于锁带来的扩展性问题,Bw树采用
latch-free的并发控制机制,即通过CAS操作避免锁操作带来的堵塞问题,有效提高了CPU的利用率;2. 针对本地更新带来的cache coherence问题,Bw树通过增量更新操作,避免对数据的本地更新,避免了原数据在其它处理器缓存中的实效问题; - 针对闪存,虽然它将I/O访问性能提升了3个数量级,并且具有性能相似的顺序读写操作/随机读操作,但是它存在一个必须解决的问题:在每次执行更新操作前,它需要执行一个昂贵的块粒度的擦除操作(这里的块粒度远大于文件系统中的页粒度,一个块往往包含64个以上的数据页,因此涉及合法数据页的数据迁移等开销),这导致随机写操作的性能远低于顺序写操作,尤其是小粒度的随机写操作会导致闪存性能/寿命下降十分严重。实验表明,高端FusionIO设备的顺序写操作的性能要比随机写操作快了3倍[2]。为了解决这个问题,Bw树采用了
基于日志结构(Log-structured)的存储层,通过append+batch write机制减少随机写操作。
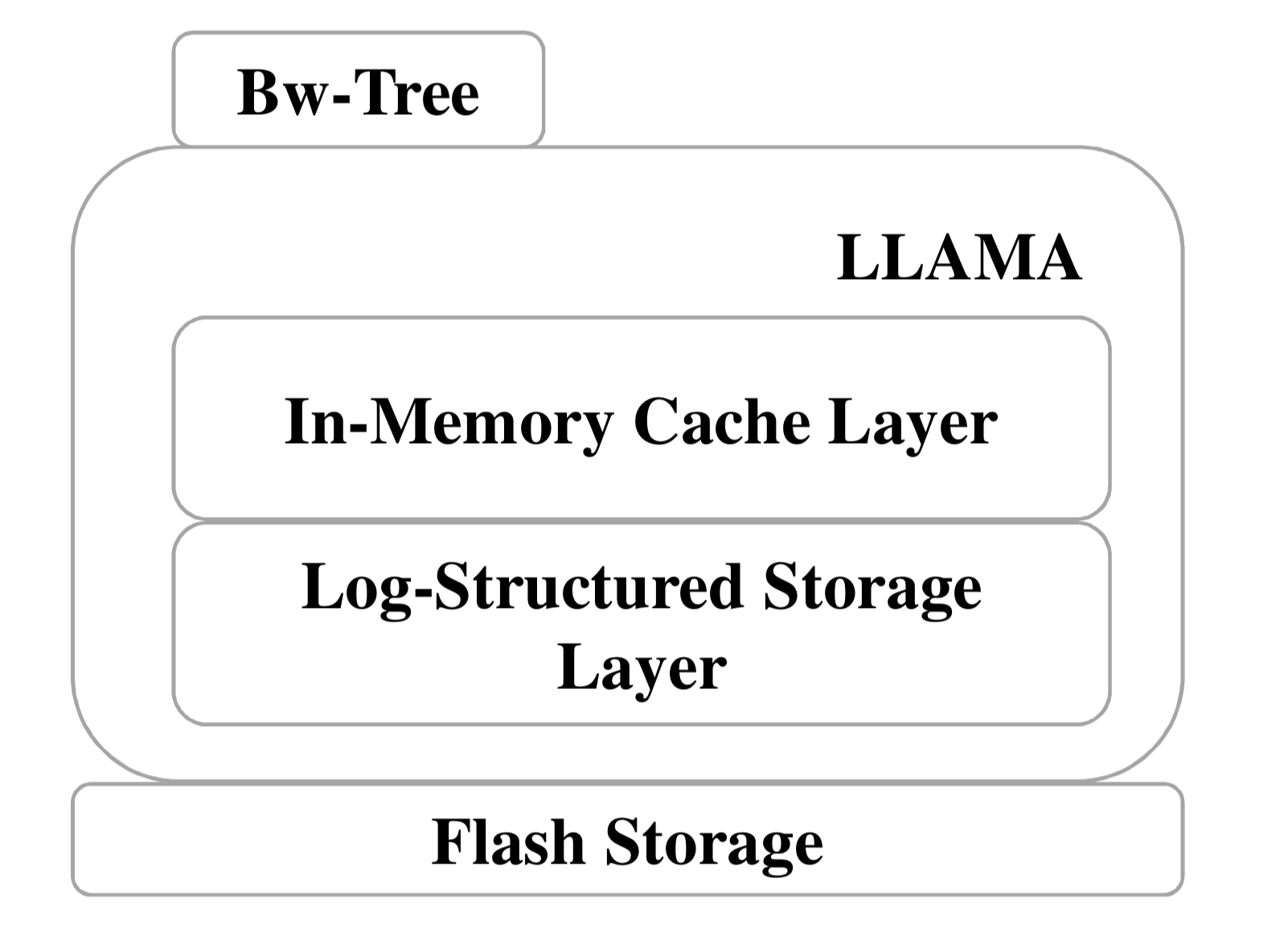
如下图所示,Bw树主要包含以下3个层次:
索引结构层(Bw-Tree),提供供上层应用访问数据的相关接口(CRUDS API,Create/Read/Update/Delete/Range Search),针对内存中的数据页提供latch-free的更新访问机制;缓存层(In-Memory Cache,IMC),提供索引结构层访问的逻辑页抽象,维护内存中逻辑页到闪存中物理页的映射表信息,并且当发生页缺失操作时将数据页从闪存读取到内存中;基于日志结构的存储层(Log-Structured Store,LSS),支持对闪存的顺序写入操作和垃圾回收机制。
IMC和LSS两层构成了LLAMA层,基于LLAMA层构建了Bw树索引结构。值得注意的是,LLAMA层与传统数据库系统的存储层相似(例如MySQL),提供了page粒度的抽象访问接口和内存/外存的交互机制。由于LLAMA层提供的是通用页粒度的接口,在LLAMA层上也可以构建其它索引结构,例如哈希表。在Bw树系列的论文中,分别通过两篇论文描述了Bw树索引结构[3]和LLAMA层[4],本文也会详细分析这两个部分。