




背景
很多时候业务架构设计里面最重要的一环就是数据库模型设计, 由于单机MySQL 的限制, 很多业务架构师不得不考虑对大表进行拆分, 通过中间件或者其他手段进行分库分表.
很多业务在快速发展阶段,开始考虑数据拆分的原因其实并不是计算能力遇到了瓶颈,而是海量数据的存储到达了单实例的上限,但是由于最初设计的时候没有考虑到海量数据的使用方式,或是在业务逻辑中,数据无法进行清理或归档。
运维团队要对业务的稳定性负责,随着数据量还是每天上涨,不得不开始考虑数据拆分的问题,由于分库分表的兼容性问题需要业务修改业务的代码, 需要按照分库分表的形式重写SQL,这就要所有开发团队投入到架构改造。但业务团队更多的考虑业务的发展,这个时候是没有精力做这些事情的, 那么拆分只能无限推迟到不得不做的那天,这期间整体系统的稳定性一直运行在风险之下。
当然, 有一些老的DBA 还记得在很早的时候, 坊间流传的是在MySQL里面单表不要超过500万行,其实规定是有其历史背景的。资源方面来说早期服务器IO能力都比较低,单表过大会增加Btree 的高度,导致IO问题;同时磁盘容量也比较低,要考虑到存储上限以及备份空间的问题;运维层面来说旧版本的MySQL(5.5以前)基本不支持online ddl,大表运维时可能导致业务异常。
现在无论是软件还是硬件都有非常显著的提高, 在PolarDB体系中,上述问题已经基本得到解决。目前PolarDB相对MySQL来说,大表已经不再是问题,目前公共云上客户的生产系统表最大已经有几十T的容量,业务都在平稳运行。
那么PolarDB 是如何解决大表场景下PolarDB 遇到的一系列问题呢?
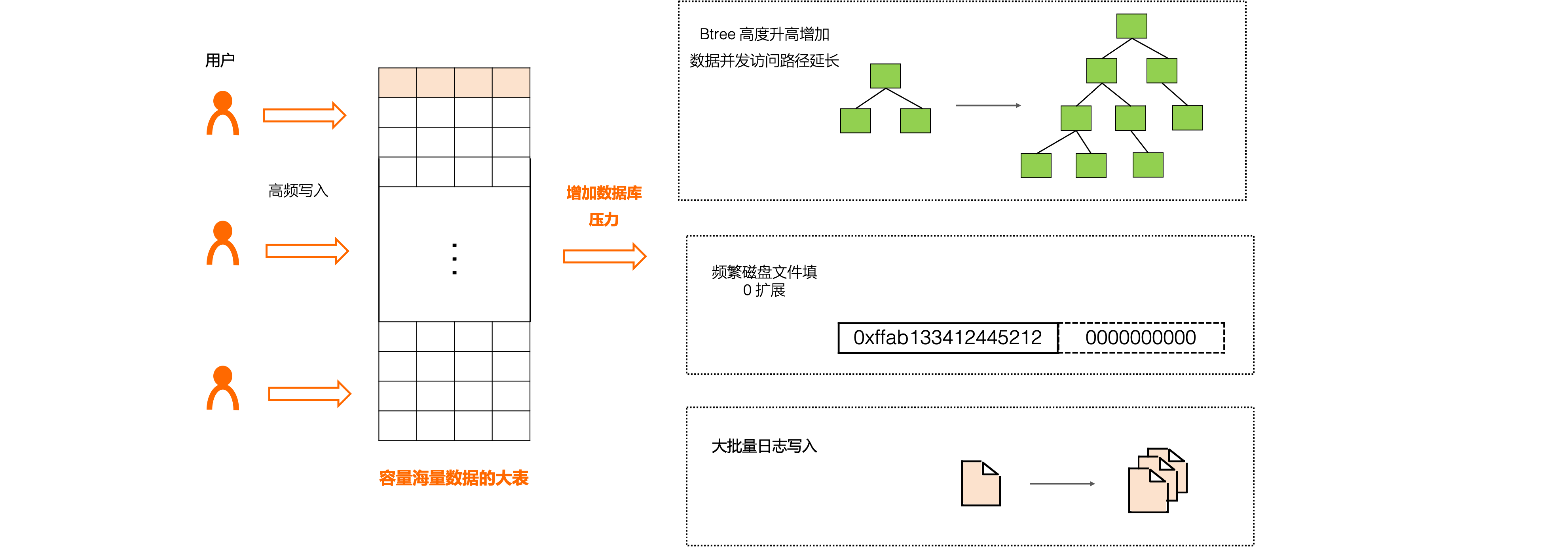
接下来我们有一系列的文章介绍PolarDB 大表场景性能优化.容纳海量数据的大表一直是数据库使用者的诉求。PolarDB 采用了计存分离,共享分布式存储的架构。相比于传统针对单机系统设计的 MySQL,分布式的存储设计让 PolarDB 的实例拥有近乎无限的容量,用户不用苦恼于磁盘容量限制和扩缩容问题,只需专注于业务的需求设计,并且不用进行分库分表的数据拆分,极大减轻了业务系统的复杂程度。为了让大表不再成为数据库使用的瓶颈,PolarDB 做了大量的探索和验证,如图 1 所示,根据实际的业务统计,拥有大表的业务,往往伴随着大批量的插入负载,使得数据库的日志、索引和文件空间都将迅速膨胀,造成 MySQL 性能出现不同程度衰退。为此,针对大表插入场景的痛点,我们研究了引入瓶颈的各个模块机制,进行了相应的优化,通过基准测试和实际业务场景验证,最多能有 10 倍性能提升。
1. 索引并发控制的优化
我们知道 MySQL 采用了索引组织表的形式组织数据,单表数据量的膨胀,同时会增加了 B+Tree 索引的高度,延长了索引的搜索路径,在原有 MySQL 实现中,当 B+Tree 索引发生分裂、合并等结构变化(SMO,Struction-Modification-Operation)时,会持有一把全局的 index 大锁,index 锁的持有时间极大影响 MySQL 性能,这也是 MySQL ”三座大山“ 之一。在大表索引膨胀的场景下,SMO index 大锁的阻塞时间被急剧延长,从而降低了系统并发执行的效率。这也是”单表超过500万行,需要分库分表“这条 MySQL 使用者曾经流行一时的经验产生的原因之一。
我们回顾 MySQL 的索引优化历程,在 MySQL 5.6之前,当索引发生SMO 时,会对index lock加 X 锁,阻塞所有的并发访问;在MySQL 5.7以后,MySQL 引入了 SX 读写锁,当索引发生 SMO 时,对index lock加 SX 锁,只阻塞并发的 SMO 操作,而允许在和本 SMO 操作没有冲突的情况下其他类型的访问,这减缓了大量并发访问的冲突开销。
但依旧没有解决大表带来的瓶颈,面对海量的数据表场景,PolarDB 是如何实现的呢?
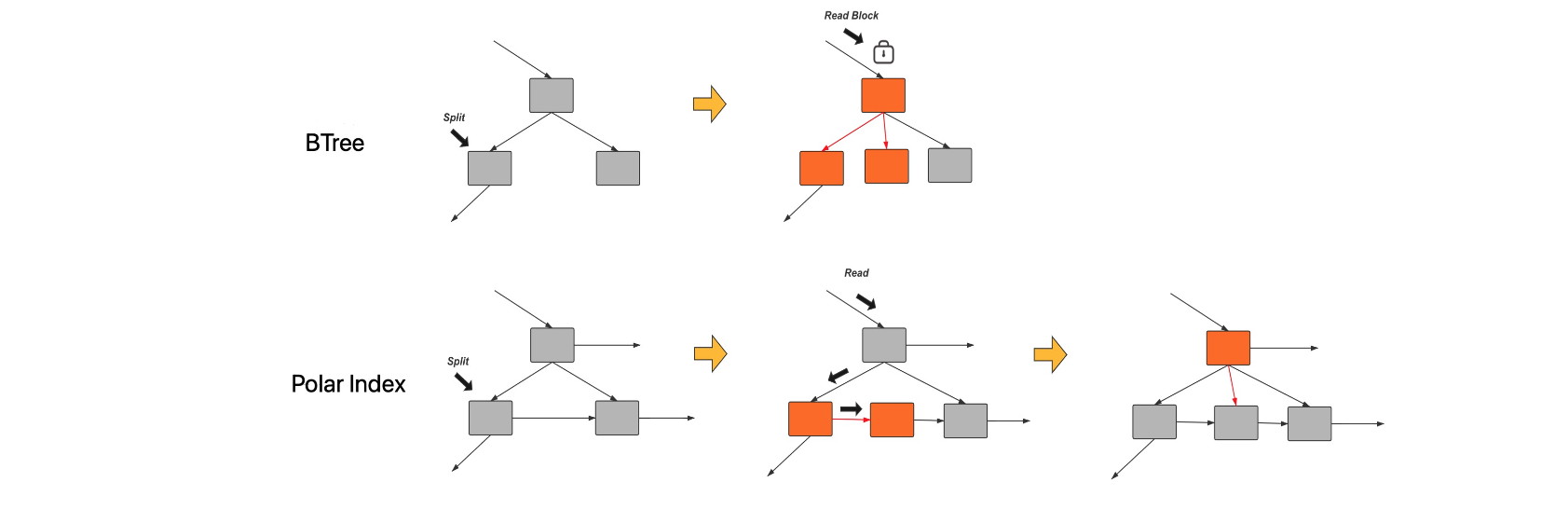
PolarDB 将传统 B+Tree 向 Polar Index 进行演进,如图 1 所示,不再限制同一时刻,只允许发生一个SMO。在没有page冲突情况下,即使 SMO 存在,仍然允许各种类型的并发访问,同时保证更新的正确性。
并且与原生 MySQL 索引沿着搜索路径遍历加锁方式不同,PolarDB 采用 latch coupling 的相邻加锁方式,只有在成功获取下一节点锁才释放父节点锁。加锁更加细粒度,并发性更好。
最后 PolarDB 深度结合 MySQL 数据库各个模块,使得索引访问具有更高的并发性能。
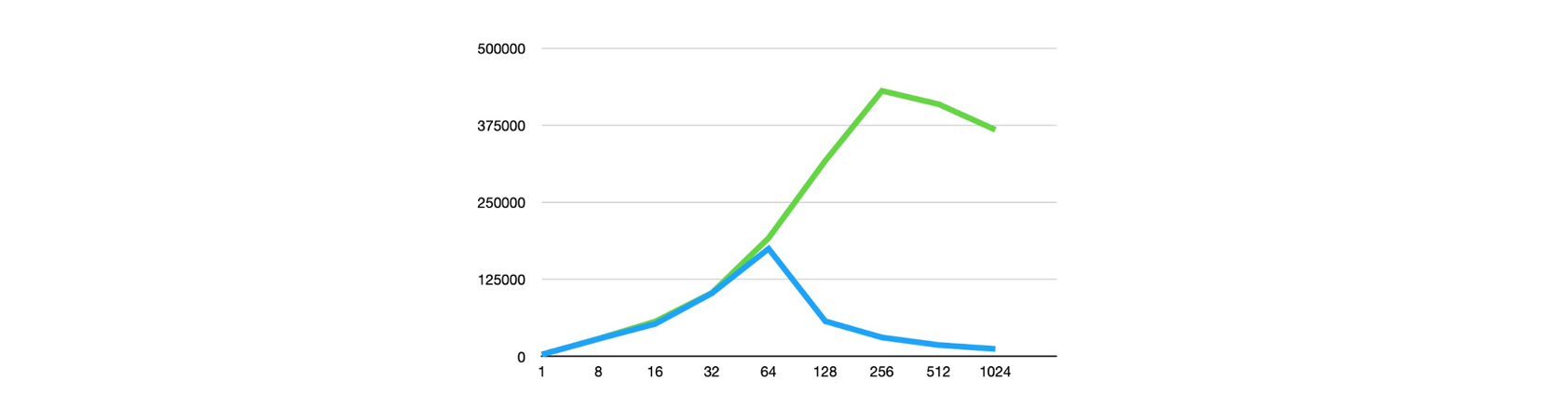
在我们某一个线上业务的实际场景中, 性能能够有3倍的提升, 在TPCC 场景下更是能够有11倍的性能提升。
2. 表文件扩展优化
随着数据的持续写入,数据表文件的扩展是不可避免的。高频的数据插入,同样会增加了表空间扩展的频次。在 MySQL 中,表空间扩展是一个很“重”的操作,高频的操作会直接影响到事务的执行性能。
为了更加直观理解高频扩展的开销,我们首先介绍 MySQL 是如何扩展表空间的。在MySQL内,表文件的扩展逻辑主要有两个操作:
- 扩展表文件的大小,主要是读取和修改表文件的元信息;
- 对新扩展的区域做填0处理。
上面的两个操作都是在锁保护下进行的(如 space锁和index锁等)。这么做是为了数据的正确性,如果数据库在表文件扩展的过程中宕机了,在做恢复的时,保证读取到的数据都是确定且有效的,而不是随机的。然而上述锁临界区的长度会很大程度的影响前台事务的执行。
MySQL 官方对此也做了相应优化:
- 适当调大单次扩展的size,可以减少表文件扩展的次数,从而提升性能;
- posix_fallocate调用后,本身可以保证后续对该区域的读是确定的(都为0),所以在posix_fallocate调用后,不对新扩展区域做填0操作,也可以保证正确性,并且可以很大程度的减少临界区的长度。
注:在MySQL原来的逻辑里,表文件单次扩展的大小一般为1个extent(表空间比较小时会有例外)
但是上述的方法存在弊端的。
- 调大单次表文件扩展的size,对性能提升的帮助有限,并且单次文件扩展的大小需要限定在一定范围内,单次扩展太大的size会影响性能的稳定,造成卡顿。
- posix_fallocate虽然可以保证后续对该扩展区域的读返回的是确定的值,但是它也引入了元信息维护的开销,会增加后续对该扩展区域的写IO的开销。
注:通常写入数据,还需要修改元信息;这点在分布式文件系统中表现尤为明显,因为在分布式系统里,元信息的修改会涉及到分布式锁的操作,甚至在有的分布式文件系统里,随着表文件的扩大,元信息修改的开销也逐渐变大;在DB层的直观的表现为,后台刷脏效率会降低,随着数据大批量的写入,逐渐增加的脏页率最终会拉低SQL的执行效率,造成性能下降。
为了优化大表插入场景下,文件扩展的开销,PolarDB 基于底层自研分布式文件系统,在表文件扩展的过程中,最低程度修改文件系统元信息,同时优化去除填 0 操作,通过与其他模块如 crash recovery 等,协同处理可能引入的数据不确定性问题,使得文件扩展中,锁开销不再成为瓶颈。这极大程度提升了PolarDB在数据大批量写入场景下的性能。
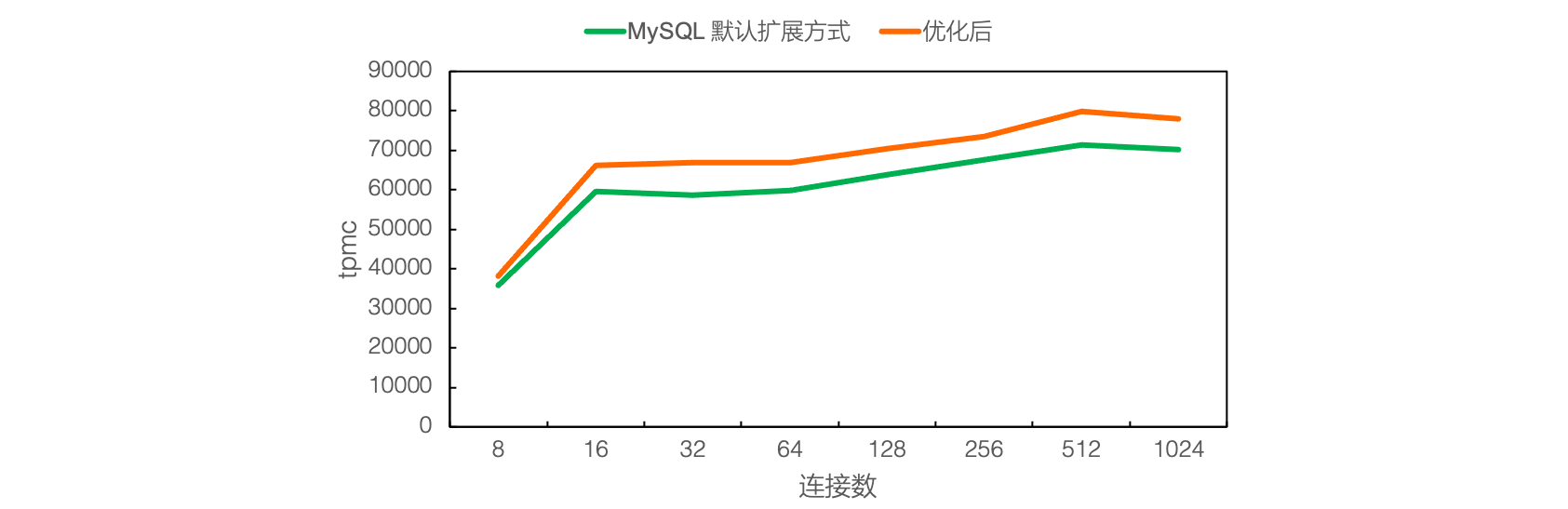
我们进行了两种扩展方式的数据插入性能对比,和 MySQL 默认扩展方式相比,优化后的写入模式具有明显性能提升。
3. redo 日志写入优化
高负载的插入,必然伴随着大批量redo日志的产生,特别是在行长比较长的业务场景,比如说游&戏业务。
为了保证事务的持久性,需要在redo日志都落盘后,事务才可以返回;因此redo日志写入的延迟和吞吐是直接影响数据库性能。
通常单盘的 IO 存在上限的,例如 Intel 5520 在稳态下的写入带宽是200-400MB/s左右,在吞吐达到上限后,IO 时延必然上涨;而 MySQL内的 redo 日志写入都是单线程进行的(在MySQL 5.7以前,虽然允许多线程写redo日志,但是相互间都是串行的),吞吐会更低,按照经验值,上限在150MB/s左右。
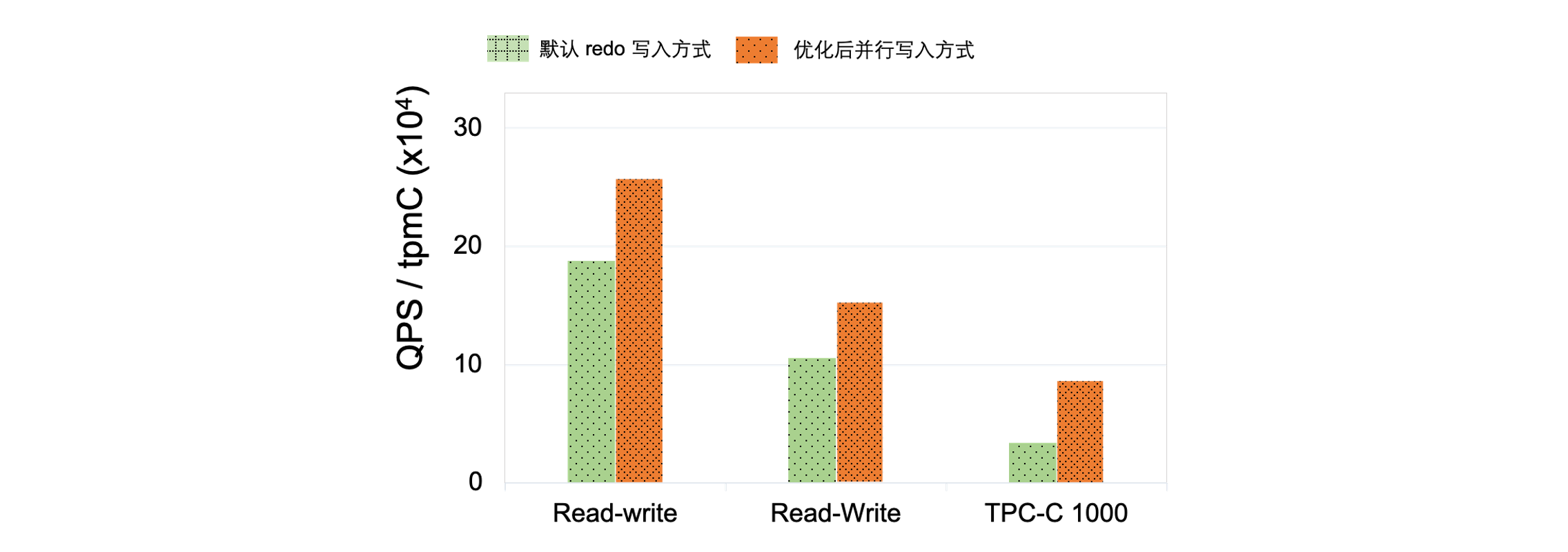
PolarDB 创新性提出了 redo 并行写入机制,解决大表日志落盘痛点。
PolarDB 对 redo日志模块进行了改进。首先是在redo日志文件布局上进行了条带化处理,让逻辑上相邻redo日志单元打散到底层不同的存储节点上,将原来单盘上的负载更好的分摊到多盘上;其次是允许对redo日志进行多线程写入,可以并行的利用多个存储节点上的IO带宽; 此外,我们在redo日志模块的写入链路上加入了自适应处理,按照负载的高低,自动进行redo日志IO大小、并行写入的线程数和同步或者异步的选择。
我们在三个 benchmark 进行验证,通过测试,日志写入优化后,性能提高 2 - 3 倍。
引用
[1] CloudJump: Optimizing Cloud Database For Cloud Storage. VLDB 2022.
[2] A Survey of B-Tree Locking Techniques
[4] 路在脚下, 从BTree 到Polar Index.
[5] 配置表空间自动扩展的size
