





官网定义:

白话说: 当执行完 checkpoint的进程之后,PG 后台进程会把第一次修改的PAGE(一般是8K) 全部写入到WAL日志中。
为什么会有full page write呢?
当数据库所在的操作系统发生crash的时候,WAL保存的行级别的数据change 不足以修复磁盘上的一个物理page,所以保存一个完整的PAGE的COPY 在WAL文件里面可以修复一个磁盘上8K的物理page.
代价是WAL 写放大。 (一般OS的文件系统的page 是4K, 那么就造成了OS page的原子性小于PG page (通常8K) 的原子性, OS crash之后,OS修复文件系统一个page 4K, 可能会造成PG page依然是损坏的)
为什么要发生在checkpoint 之后?
WAL文件的回放发生在上次checkpoint 之后,上次checkpoint已经把share buffer 中的dirty page 刷新到磁盘上了,所以从下一次checkpoint 开始写入full page 是最安全的。
如何减小full page writes 的生成量?
调大checkpoint 刷盘的时间间隔。
full page writes 是在checkpoint 中是如何写入的?
我们借用JP知名PG专家网站上的图:
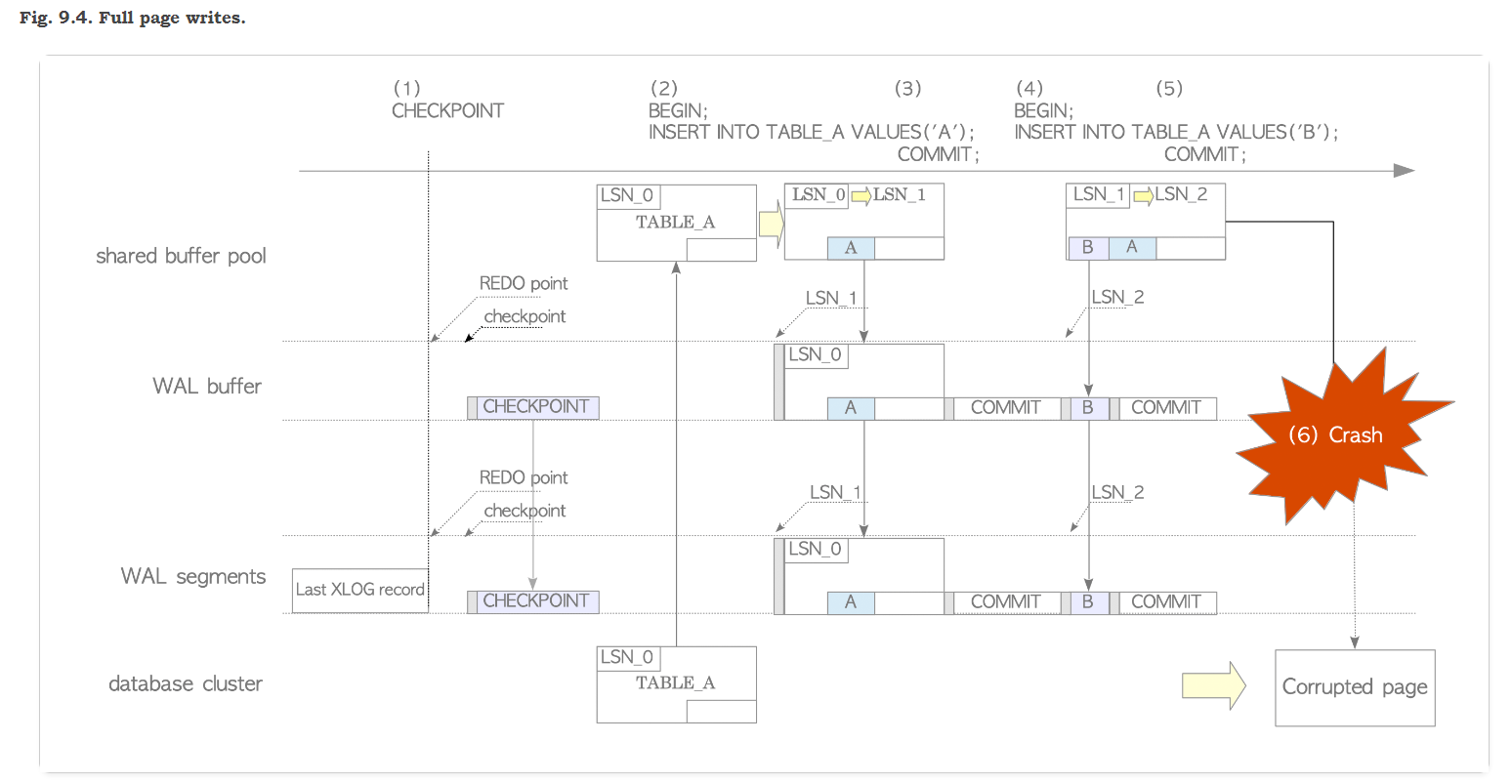
我们可以这张图想象为话剧中的一幕:
四大主角: shared buffer pool , database cluster(data page) , checkpoint, wal segments(buffer).
剧本顺序:
(1)Checkpoint 这一幕中,首先出场, 执行checkpoint , 后台刷新shared buffer 中的 dirty page 到 data page 中并更新 control file中最后一次 checkpint 的LSN = 0 日志点和时间。
(2)这个时候进来了一条A记录,首先写入shared buffer 的page中, 如此同时写入wal segments(buffer) 中:由于是上次checkpoint后的第一次写入( page_LSN = last check point LSN) 这个时候page会全部写入WAL中,做一个full page image(copy)
(3)执行commit, 一起写入到WAL中,修改内存中PAGE HEADER 中的信息 LSN =1
(4) 这个时候记录B请求写入,shared buffer 写入刚才的page中(我们假设page空间足够),如此同时写入WAL中: 这是时候会做个判断(page_LSN = 1) > (last check point LSN = 0), PAGE中的LSN 大于 last check point 的LSN, 看来不需要full page write, 只需要写入B这行记录了
(5)执行commit, 一起写入到WAL中,修改内存中PAGE HEADER 中的信息 LSN =2
(6)发生了OS文件系统crash , disk 上的page损坏了, 之前WAL的full page copy 该发挥作用了, 直接从wal 文件中 replay 这个full page copy + 增量行记录变化 就可以修复这个disk page 了
如下图, 感觉 full page 备份和恢复与大多数RDBMS的备份和恢复是比较类似的,全量(full page copy)+增量的原理(同样是基于日志点LSN)
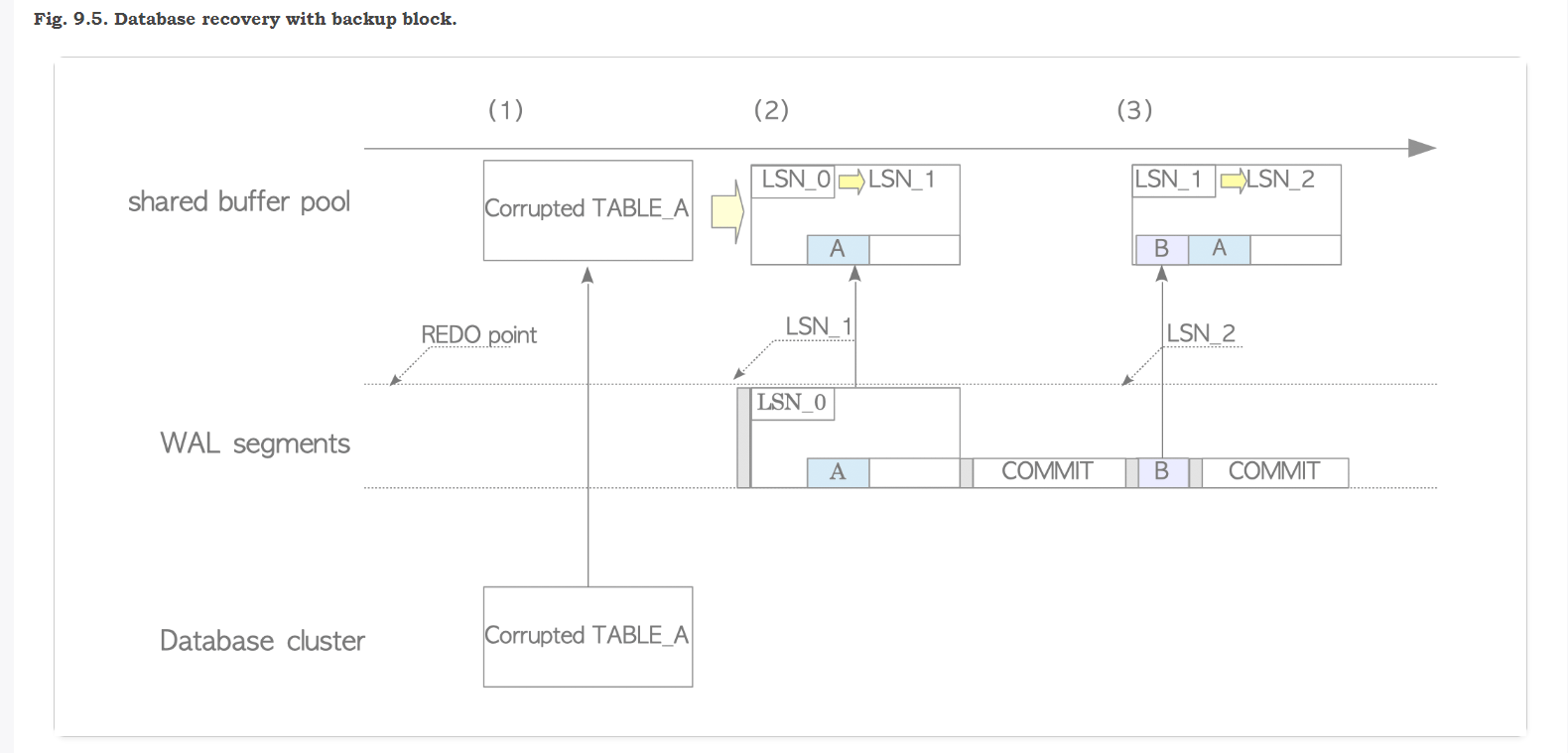
话剧第二幕: 损坏的page是如何恢复的?
(1) load 损坏磁盘上的page 到shared_buffer
(2)在WAL中找到最近一次full page的copy 进行replay 还原修复
(3) full page copy 修复还原之后,进行增量行级别的修复
(4)等待执行checkpoint 刷新到 disk 中
以上都是一些理论上的介绍,实际工作中如何规避一些full page write的影响呢?
A) 测试案例: 数据迁移(ETL初始化导入),如何避免写放大?
调整参数前: max_wal_size = 1GB, wal_compression = off, checkpoint_timeout = 1min (为了试验效果故意往下调整小了这些参数)
postgres@[local:/tmp]:2031=#87505 set wal_compression = off;
SET
postgres@[local:/tmp]:2031=#87505 show wal_compression ;
wal_compression
-----------------
off
(1 row)
postgres@[local:/tmp]:2031=#87505 show max_wal_size ;
max_wal_size
--------------
1GB
(1 row)
postgres@[local:/tmp]:2031=#87505 alter system set checkpoint_timeout = '1min';
ALTER SYSTEM
postgres@[local:/tmp]:2031=#87505 select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
postgres@[local:/tmp]:2031=#87505 show checkpoint_timeout;
checkpoint_timeout
--------------------
1min
(1 row)
为了方便计算WAL的生成数量,我们清除一下 WAL的动态的采集指标的试图:
我们可以看到 wal_bytes 已经在 2023-07-26 10:04:46.927637+08 这个时间点被reset 了
注意这个 wal_fpi 是 0 :
postgres@[local:/tmp]:2031=#96024 select pg_stat_reset_shared('wal');
pg_stat_reset_shared
----------------------
(1 row)
postgres@[local:/tmp]:2031=#115579 select * from pg_stat_wal;
wal_records | wal_fpi | wal_bytes | wal_buffers_full | wal_write | wal_sync | wal_write_time | wal_sync_time | stats_reset
-------------+---------+-----------+------------------+-----------+----------+----------------+---------------+-------------------------------
15 | 0 | 1085 | 0 | 5 | 5 | 0 | 0 | 2023-07-26 10:04:46.927637+08
(1 row)
PG端尝试插入 2000万的数据:
postgres@[local:/tmp]:2031=#96024 create table t_wal_size(id int, context varchar(500));
CREATE TABLE
postgres@[local:/tmp]:2031=#96024 insert into t_wal_size select generate_series(1,20000000),'hsjwkwklwllwlwlsnsnsnnskkakakkkkkkkananannaka';
INSERT 0 20000000
我们查询一下WAL大致生成是 2.2 个GB, WAL full page image 副本的个数是 206307
postgres@[local:/tmp]:2031=#115579 select wal_fpi,wal_bytes/1024/1024/1024 from pg_stat_wal;
wal_fpi | ?column?
---------+--------------------
206307 | 2.2187267830595374
(1 row)
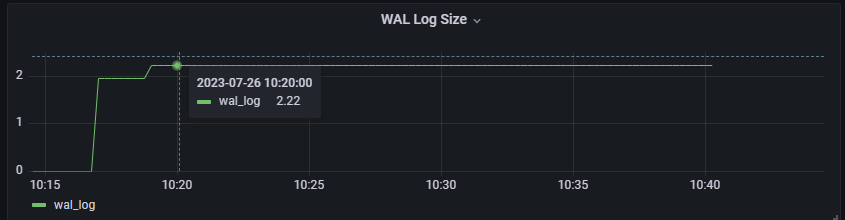
查看checkpoint 的发生的次数: 发生了多次 checkpoint , 并提示我们 checkpoints are occurring too frequently 发生的太频繁了, 建议增大max_wal_size
2023-07-26 10:25:30.815 CST [16719] LOG: checkpoint complete: wrote 8017 buffers (6.1%); 0 WAL file(s) added, 8 removed, 0 recycled; write=3.289 s, sync=0.164 s, total=3.480 s; sync files=21, longest=0.159 s, average=0.008 s; distance=84574 kB, estimate=227568 kB 2023-07-26 10:25:31.425 CST [16719] LOG: checkpoints are occurring too frequently (4 seconds apart) 2023-07-26 10:25:31.425 CST [16719] HINT: Consider increasing the configuration parameter "max_wal_size". 2023-07-26 10:25:31.425 CST [16719] LOG: checkpoint starting: wal ... 2023-07-26 10:26:04.047 CST [16719] LOG: checkpoint complete: wrote 45421 buffers (34.7%); 0 WAL file(s) added, 55 removed, 0 recycled; write=24.217 s, sync=0.143 s, total=24.459 s; sync files=7, longest=0.119 s, average=0.021 s; distance=573441 kB, estimate=574369 kB 2023-07-26 10:26:04.047 CST [16719] LOG: checkpoint starting: immediate force wait 2023-07-26 10:26:04.339 CST [16719] LOG: checkpoint complete: wrote 37306 buffers (28.5%); 0 WAL file(s) added, 21 removed, 0 recycled; write=0.249 s, sync=0.002 s, total=0.293 s; sync files=8, longest=0.002 s, average=0.001 s; distance=397109 kB, estimate=556643 kB ... 2023-07-26 10:28:52.068 CST [16719] LOG: checkpoint complete: wrote 76258 buffers (58.2%); 0 WAL file(s) added, 6 removed, 0 recycled; write=47.968 s, sync=0.002 s, total=47.985 s; sync files=14, longest=0.002 s, average=0.001 s; distance=141992 kB, estimate=477312 kB ....
下面我们开始调整一下参数:
postgres@[local:/tmp]:2031=#96024 set wal_compression = on;
SET
postgres@[local:/tmp]:2031=#96024 alter system set checkpoint_timeout = '15min';
ALTER SYSTEM
postgres@[local:/tmp]:2031=#96024 select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
postgres@[local:/tmp]:2031=#96024 alter system set max_wal_size = '5GB';
ALTER SYSTEM
postgres@[local:/tmp]:2031=#96024 select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
重置一下WAL采集信息:
postgres@[local:/tmp]:2031=#115579 select pg_stat_reset_shared('wal');
pg_stat_reset_shared
----------------------
(1 row)
postgres@[local:/tmp]:2031=#115579 select * from pg_stat_wal;
wal_records | wal_fpi | wal_bytes | wal_buffers_full | wal_write | wal_sync | wal_write_time | wal_sync_time | stats_reset
-------------+---------+-----------+------------------+-----------+----------+----------------+---------------+-------------------------------
12 | 0 | 868 | 0 | 5 | 5 | 0 | 0 | 2023-07-26 11:27:35.272107+08
(1 row)
重复上次PG端插入2000万的操作:
postgres@[local:/tmp]:2031=#96024 insert into t_wal_size select generate_series(1,20000000),'hsjwkwklwllwlwlsnsnsnnskkakakkkkkkkananannaka';
INSERT 0 20000000
我们查询一下WAL大致生成是 1.9 个GB, full page image 副本是 17个
postgres@[local:/tmp]:2031=#115579 select wal_fpi,wal_bytes/1024/1024/1024 from pg_stat_wal;
wal_fpi | ?column?
---------+--------------------
17 | 1.9558383412659168
(1 row)
WAL size 生成量的比较: 2.2 GB vs 1.9GB , 大致增长了 15% 左右
可能有的小伙伴会提问:
- WAL 15% 的增长也不算太多?
回答: 测试的插入SQL是在1分钟之内的,如果是长时间的跑批大量插入修改,这个 full page writes 生成量是惊人的。 - 即使checkpoint_timeout 参数调大了,下一次发生 checkpoint 的时候还是会触发 full page writes?
回答:是这样的! 发生full page writes 是无法避免的! 增大 max_wal_size 和 checkpoint_timeout 的意义是, 减少发生full_page_write的触发几率。
假设同一个page, 如果不停地被修改, 每天触发 checkpoint 是 100 次的话, 会有100个 full page image 写入WAL 日志。
如果通过修改参数, 每天触发checkpoint 减少到 48次(每30分钟触发一次),那么就会减少到48个full page image 写入WAL 日志。 (FPI 减少了50%)
B)测试案例:
场景2: UUID 数据类型造成的WAL写放大
我们创建2张表: 分别是主键int 类型的和UUID 这2种类型的,我们来做一个比对:
postgres@[local:/tmp]:2031=#117689 create table tab_pk_int(id bigint,content varchar(200));
CREATE TABLE
postgres@[local:/tmp]:2031=#117689 create table tab_pk_uuid(id uuid,content varchar(200));
CREATE TABLE
我们重置一下WAL stat的采集视图:
postgres@[local:/tmp]:2031=#117689 select pg_stat_reset_shared('wal');
pg_stat_reset_shared
----------------------
(1 row)
向tab_pk_int 表 load 进入2000万的数据:手动执行checkpoint, 触发FPI
postgres@[local:/tmp]:2031=#117689 insert into tab_pk_int select generate_series(1,20000000),'hsjwkwklwllwlwlsnsnsnnskkakakkkkkkkananannaka';
INSERT 0 20000000
postgres@[local:/tmp]:2031=#117689 checkpoint;
CHECKPOINT
观察WAL 采集的试图:FPI = 163176, WAL 生成量大致是2.24GB
postgres@[local:/tmp]:2031=#117689 select * from pg_stat_wal;
wal_records | wal_fpi | wal_bytes | wal_buffers_full | wal_write | wal_sync | wal_write_time | wal_sync_time | stats_reset
-------------+---------+------------+------------------+-----------+----------+----------------+---------------+-------------------------------
20369685 | 163176 | 2405650987 | 259681 | 262526 | 2939 | 0 | 0 | 2023-07-26 17:01:59.256776+08
(1 row)
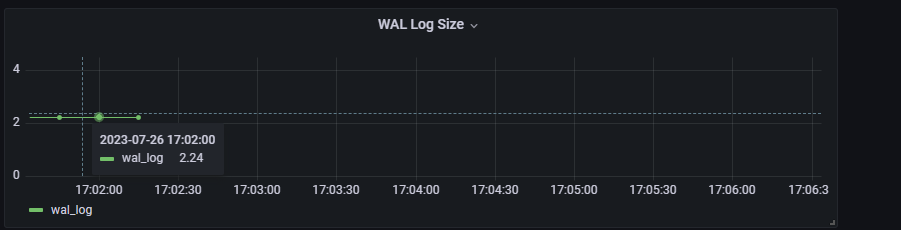
接下来,我们重复一下实验:向带有主键UUID的表中插入数据
为了对比方便: 我们重置一下WAL stat的采集视图:
postgres@[local:/tmp]:2031=#117689 select pg_stat_reset_shared('wal');
pg_stat_reset_shared
----------------------
(1 row)
向tab_pk_uuid 表 load 进入2000万的数据:手动执行checkpoint, 触发FPI
postgres@[local:/tmp]:2031=#117689 insert into tab_pk_uuid select gen_random_uuid(),'hsjwkwklwllwlwlsnsnsnnskkakakkkkkkkananannaka' from generate_series(1,20000000);
INSERT 0 20000000
postgres@[local:/tmp]:2031=#117689 checkpoint;
CHECKPOINT
观察WAL 采集的试图:FPI = 227346, WAL 生成量大致是2.75GB
postgres@[local:/tmp]:2031=#117689 select * from pg_stat_wal;
wal_records | wal_fpi | wal_bytes | wal_buffers_full | wal_write | wal_sync | wal_write_time | wal_sync_time | stats_reset
-------------+---------+------------+------------------+-----------+----------+----------------+---------------+-------------------------------
20455512 | 227346 | 2957110985 | 243239 | 247426 | 4133 | 0 | 0 | 2023-07-26 17:09:16.273316+08
(1 row)
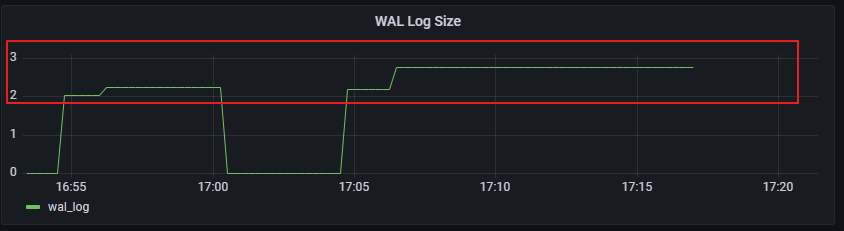
2次对比图: 可以查看UUID主键的表的FPI 会明显增加,
原因也是很简单的, UUID 作为主键索引本身是离散的, btree+ 插入的时候更加离散,所以涉及到的page会更多, 在执行checkpoint后, 发生full page image 拷贝的个数也就越多。
写到最后:
1)Full page write 作为数据页自身的机制,默认就是打开的,也是强烈建议打开的
2)设置适当的 checkpoint的间隔时间和适当的max_wal_size , 来规避数据库频繁的刷盘操作,既可以提升数据库本身的性能,也可以节省WAL空间,archive 归档的空间
3)规划合理的数据库磁盘空间,特别是数据目录下WAL的空间, 之前ORACLE 如果归档是500GB的话, 迁移到PG建议增大到1.5-2倍: 800GB 到 1TB左右比较合理
4)打开WAL 压缩参数,进一步减小磁盘的占有空间(CPU会有10%左右的下降,需要平衡一下)
5)代码设计和审核的时候,规避UUID或者应用端雪花生成器这种离散的类型作为主键,或者作为索引列。 离散的page写入,会带来大量的FPI。
Have a fun 🙂 !
