




一、使用OGG同步表,使用Rowid字段同步
使用OGG Rowid字段进行同步,这个问题老生常谈了。最早看到Rojer在09年好像就发表过一篇文章,讲述rowid字段的同步操作。
具体为什么使用rowid字段,rowid字段同步和其它方式同步有什么区别,请看如下文档~不在重复讲述。
https://www.modb.pro/doc/44822
本篇文档重点在于客户认为我的rowid同步的方案存在漏洞,需要解决这个漏洞,以及如何加快rowid同步的时间,进行的测试!
项目原因,某客户需要将DB从11g升级到19c,原有的11g db存在多条OGG链路,那么这些OGG有使用rowid字段进行同步的表;oracle db 11g to 19c 使用的是数据泵expdp\impdp进行的数据迁移,因此ogg源端的rowid同步的表rowid值会全部改变,因此这种迁移方式对应的ogg处理,需要对所有rowid表同步重新初始化! 那么如何加快初始化的操作,以及安全的操作!就是本次测试的重点!
二、实验测试
2.1 原Rowid方案同步
1)源库,创建一个tmp表新增rowid字段,将需要同步的表数据及rowid数据写入到临时表中;
2) 源库,数据泵导出临时表;
3) 目标库,数据泵导入临时表,直接remap 使用drop-create方式重建写入到目标表中;
以上就是完成数据初始化!!!
临时数据处理
--expdp
sqlplus / as sysdba <<EOF
col current_scn for 999999999999999
select current_scn from v\$database;
exit
EOF
--exec
>/home/oracle/cwjx_create_tmp_script.sh
A_TMP=$(echo "C_OWNER.GL_TABLE_NAME")
echo "${A_TMP}"|while read TABLE_NAME_LIST
do
I_SCN=890209223545
TMP_TAB=${TABLE_NAME_LIST}
Pnumber=$(echo "${TABLE_NAME_LIST}"|awk -F'.' '{print $2}')
echo "echo 'script exec ${TMP_TAB}_ENMOTMP ' " >>/home/oracle/create_tmp_script.sh
echo "sqlplus / as sysdba <<EOF
alter session set container=xxxD;
set timing on
alter session enable parallel dml;
DROP TABLE ${TMP_TAB}_ENMOTMP purge;
create table ${TMP_TAB}_ENMOTMP as SELECT * FROM ${TMP_TAB} WHERE 1=2;
alter table ${TMP_TAB}_ENMOTMP add (row_id rowid);
alter table ${TMP_TAB}_ENMOTMP add constraint
pk_rowid_${Pnumber} unique (row_id) enable;
insert into ${TMP_TAB}_ENMOTMP
select /*+ PARALLEL(t,12) */ t.*,t.rowid from ${TMP_TAB} as of scn ${I_SCN} t;
COMMIT;
exit
EOF" >>/home/oracle/cwjx_create_tmp_script.sh
done
nohup sh /home/oracle/cwjx_create_tmp_script.sh &
导出临时表
dump_process=20211111_001
nohup expdp dump_enmo/dump_enmo@10.xx:1521/pxx
directory=dump dumpfile=${dump_process}%U.dmp logfile=${dump_process}.log
cluster=n parallel=8 filesize=20g COMPRESSION=DATA_ONLY
tables=xx.xxTS_ENMOTMP VERSION=12.2 &
导入数据
–导入测试确认remap正确,否则直接导入使用参数不正确可能删除业务数据表
dump_process=20211107
impdp dump_enmo/dump_enmo@10.xx/jxx.xxx.com directory=dump
dumpfile=${dump_process}%U.dmp logfile=${dump_process}.log
cluster=n parallel=8 REMAP_SCHEMA=xL:OGG_xx REMAP_TABLESPACE=%:OGG_DATA
TABLES=xxL.GLxxENMOTMP sqlfile=a.sql
dump_process=20211107
nohup impdp dump_enmo/dump_enmo@10.xx:1521/jxx.xx.com
directory=dump dumpfile=${dump_process}%U.dmp logfile=${dump_process}.log
cluster=n parallel=8 REMAP_SCHEMA=xxxL:OGG_xxx REMAP_TABLESPACE=%:OGG_DATA
TABLE_EXISTS_ACTION=REPLACE TABLES=xxx.GL_Bxxxxx_ENMOTMP &
-- EXCLUDE=CONSTRAINT,index
--特殊说明Row_id的索引手工无法明确创建,所以是创建约束的时候oracle自动去创建,但是如果有其它索引的干扰可以单独手工创建索引和约束!
--数据泵导入索引是否并行可以看如下的博客文章
https://www.cnblogs.com/lvcha001/p/15129982.html
这个方案存在一个问题! 那就是目标端是直接drop ,create 随后灌入数据!
tmp表是不包含目标端的表拥有的权限以及同义词等其它依赖的对象! 因此这个方案存在严重对风险问题! 因为如果OGG不在是单纯的只提供读写数据,而在目标端存在其它业务表对读写权限,与源库的权限已经不同了!!!
这里对OGG多次升级迁移测试进行点赞,测试后确实能提前发现一些问题,提前处理。
2.2 如何编写耗时短、不出错的Rowid数据迁移方案呢?
2.2.1 源库临时表调整
insert临时表数据时使用了并行+apend直接路径写
sqlplus / as sysdba <<EOF
col current_scn for 999999999999999
select current_scn from v\$database;
exit
EOF
892525017391
>/home/oracle/create_jyfx_tmp_script.sh
>nohup.out
A_TMP=$(echo "XX.XXXXXX
XX.GL_XXXXX")
echo "${A_TMP}"|while read TABLE_NAME_LIST
do
I_SCN=892525017391
TMP_TAB=${TABLE_NAME_LIST}
Pnumber=$(echo "${TABLE_NAME_LIST}"|awk -F'.' '{print $2}')
echo "echo 'script exec ${TMP_TAB}_ENMOTMP ' "
>>/home/oracle/create_jyfx_tmp_script.sh
echo "sqlplus / as sysdba <<EOF
alter session set container=xxx;
set timing on
alter session enable parallel dml;
truncate TABLE ${TMP_TAB}_ENMOTMP;
create table ${TMP_TAB}_ENMOTMP as SELECT * FROM ${TMP_TAB} WHERE 1=2;
alter table ${TMP_TAB}_ENMOTMP add (row_id rowid);
insert /*+ append PARALLEL(a,12) */ into ${TMP_TAB}_ENMOTMP a
select /*+ PARALLEL(t,12) */ t.*,t.rowid from ${TMP_TAB} as of scn ${I_SCN} t;
COMMIT;
exit
EOF" >>/home/oracle/create_jyfx_tmp_script.sh
done
修改后的SQL删除对源库创建row_id主键对约束
修改前
insert into ${TMP_TAB}_ENMOTMP
select /*+ PARALLEL(t,12) */ t.*,t.rowid from ${TMP_TAB} as of scn ${I_SCN} t;
等同如下SQL,观察执行计划
insert into XXX.XXXselect /*+ PARALLEL(t,12) */ t.*
from XXX.XXX_ENMOTMP t;
292564666 rows created.
Elapsed: 01:04:49.81
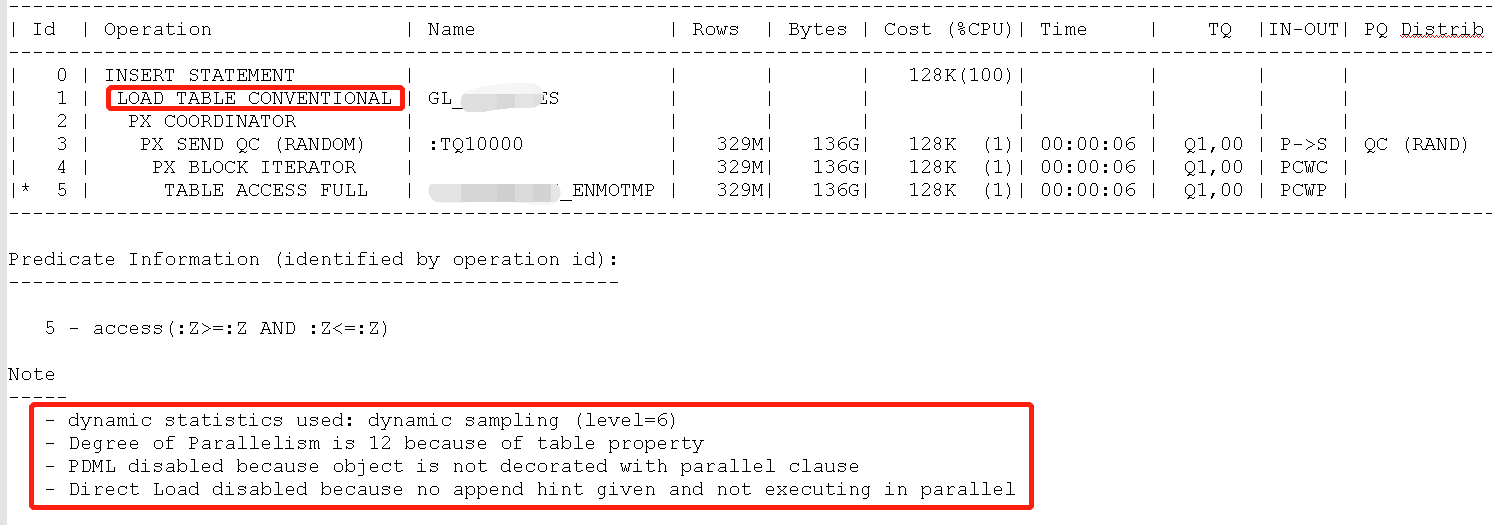
从提示已经可以看到并行DML已禁用,没有使用apend
修改后
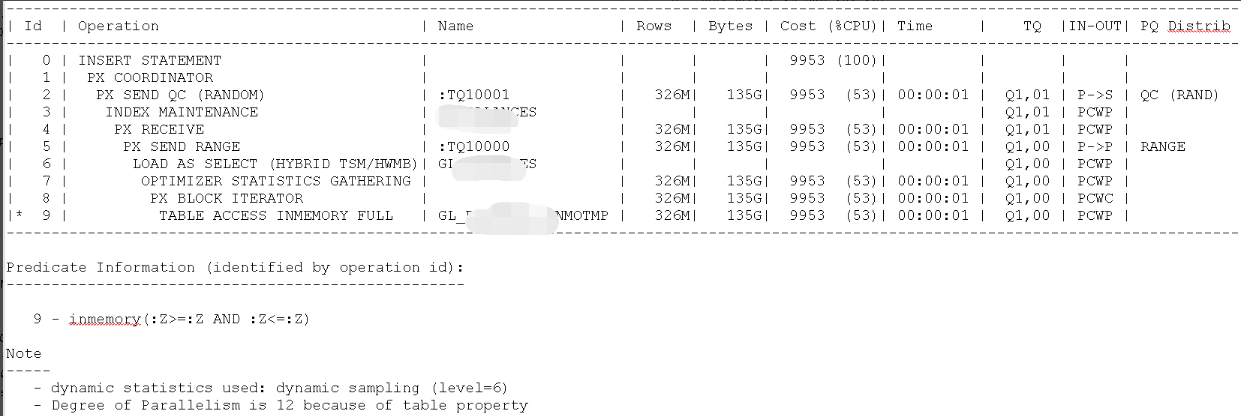
alter session enable parallel dml;
insert /*+ append PARALLEL(a,12) */ into XXX.XXX a
select /*+ PARALLEL(t,12) */ t.* from XXX.XXX_ENMOTMP t;
292564666 rows created.
Elapsed: 00:11:45.42
从时间维度看,原本1个小时执行现在11分钟就搞定了。
Drop改成truncate
最开始是drop tmp临时表;
abk07pgbsgfqx enq: RO - fast object reuse
select BLOCKING_SESSION_STATUS,BLOCKING_INSTANCE
,BLOCKING_SESSION from v$session
where event='enq: RO - fast object reuse';
BLOCKING_SE BLOCKING_INSTANCE BLOCKING_SESSION
----------- ----------------- ----------------
VALID 1 170
select sql_id,p.program from v$process p,v$session s
where p.addr=s.paddr and s.sid=170;
SQL_ID PROGRAM
-------------- ----------------------------------------
oracle@XX (CKPT)
2.2.2 源库数据泵导出
dump_process=jyfx20211111
nohup expdp dump_enmo/dump_enmo@xx directory=dump
dumpfile=${dump_process}%U.dmp logfile=${dump_process}.log cluster=n parallel=8
filesize=20g COMPRESSION=DATA_ONLY tables=xx_ENMOTMP exclude=trigger VERSION=12.2 &
数据泵语法没啥好调整的
2.2.3 目标库数据泵导入
export ORACLE_SID=xxx
dump_process=jyfx20211111
nohup impdp dump_enmo/dump_enmo directory=IMPDPDIR
dumpfile=${dump_process}%U.dmp logfile=${dump_process}.log
cluster=n parallel=8 TABLE_EXISTS_ACTION=REPLACE
REMAP_TABLESPACE=%:XXXOGG REMAP_SCHEMA=XX:XXOGG,XXX:XXXOGG &
数据泵语法也没有调整,但是之前最开始的方案是导入之后,直接修改名称进行导入;
但是为了避免删除目标表,重新创建新表导致目标库的一些权限出现丢失;
因此本次导入先导入目标库,名称还是XX_ENMOTMP临时表;
2.2.4 目标库Insert写入数据
>/home/orauat/ywxt_jyfx_create_tmp_script.sh
>nohup.out
A_TMP=$(echo "XX.XX
XX.XX")
echo "${A_TMP}"|while read TABLE_NAME_LIST
do
TMP_TAB=${TABLE_NAME_LIST}
echo "echo 'script exec ${TMP_TAB}_ENMOTMP ' "
>>/home/orauat/ywxt_jyfx_create_tmp_script.sh
echo "sqlplus / as sysdba <<EOF
--alter session set container=Jxx;
set timing on
alter session enable parallel dml;
truncate table ${TMP_TAB};
insert /*+ append PARALLEL(a,12) */ into ${TMP_TAB} a
select /*+ PARALLEL(t,12) */ t.* from ${TMP_TAB}_ENMOTMP t;
COMMIT;
exit
EOF" >>/home/orauat/ywxt_jyfx_create_tmp_script.sh
done
nohup sh /home/orauat/ywxt_jyfx_create_tmp_script.sh &
这样整体的Rowid对表数据同步就完成了,由于基本上可以进行批量化的同步,使用linux while循环输出脚本,后台执行就可以了。
2.2.5 统计信息收集
A_TMP=$(echo "XX")
echo "${A_TMP}"|while read TABLE_NAME_LIST
do
VAR_OWNER=$(echo $TABLE_NAME_LIST|awk -F'.' '{print $1}')
VAR_TABLE=$(echo $TABLE_NAME_LIST|awk -F'.' '{print $2}')
sqlplus / as sysdba <<EOF
alter session set container=XX;
set timing on
EXEC dbms_stats.gather_table_stats(ownname=>'${VAR_OWNER}',
TABNAME=>'${VAR_TABLE}',CASCADE=>TRUE,DEGREE=>12,
ESTIMATE_PERCENT=>10,NO_INVALIDATE=>false);
exit
EOF
done
2.2.6 脚本使用注意事项
1.临时表空间建议新增30G >insert表大小+索引,insert 过程中临时表空间不足,扩容后可能会导致事务中断,回滚后再来一遍,提前加最好
–备注:如果是直接 导入PDB,那么临时表空间在CDB层面加可能pdb根本不会去使用,相当于白干活,然后导入报temp不足!!!;
2.Undo表空间建议提前新增30G,还是根据空间来,提前进行扩容,并且建议resize 30g,否则undo extent申请也需要一定对时间;
3.Redo 扩容,导入关注log switch 切换,如果存在都处于active,未过期状态,则说明日志空间不足,多扩几组日志组提前进行,避免insert产生日志切换等待日志写时间;
4.缺陷,由于本次为了安全对考虑,导入分2次进行,先导入临时表,然后从临时表拿数据写入到OGG的目标表中,实际操作这个步骤耗时很长,因为目标环境存在多个索引。
5.使用这种方案,还有一个需要注意的点,需要在目标环境找到最后一个字段不是rowid对字段,并且手工调整字段顺序!!!
A_TMP=$(echo "XXX")
echo "${A_TMP}"|while read TABLE_NAME_LIST
do
VAR_OWNER=$(echo $TABLE_NAME_LIST|awk -F'.' '{print $1}')
VAR_TABLE=$(echo $TABLE_NAME_LIST|awk -F'.' '{print $2}')
sqlplus / as sysdba <<EOF
alter session set container=XXX;
set linesize 200
col owner for a20
col table_name for a35
col COLUMN_NAME for a35
select owner,table_name,COLUMN_NAME from dba_tab_columns
where owner='${VAR_OWNER}'
and table_name='${VAR_TABLE}'
and COLUMN_ID=(select max(COLUMN_ID) from dba_tab_columns
where owner='${VAR_OWNER}'
and table_name='${VAR_TABLE}' );
exit
EOF
done
$ cat a.log |grep -A5 OWNER
OWNER TABLE_NAME COLUMN_NAME
--------------------------------------- -----------------------------------
xx xx_ALL_BK DXXID
truncate table XX;
alter table XX drop column ROW_ID;
alter table XX drop column DXXID;
alter table XX add (DXXID NUMBER);
alter table XX add (row_id rowid);
方案优化:
1.还是使用原来的一次性导入方案,将临时表remap转换后直接导入目标表中;
2.由于客户目标端历史使用rowid字段同步对表存在没有创建唯一或主键约束,导致大表同步OGG全表扫描,因此如果后续还有机会,对导入对rowid表对主键约束要保留不要删除!!!
3.针对客户提出对drop,create导致目标表丢失部分同义词等之类对依赖对象,可以对目标库表删除之前使用数据泵或脚本备份表相关对权限、依赖对象对创建语句,在临时表覆盖之后,在导入或手工创建!比现有的2次insert加快很多!
