




01
引言
作为金融机构的核心服务平台,行情中心能提供实时行情数据的获取、指标计算、数据存储和数据分发等服务,为交易、投资、风险管理等业务部门提供重要支持。在投研和仿真系统方面,行情中心的价值也不断凸显,能大大提升基金尤其是私募的投研效率和质量。
02
什么是新型行情中心
从用户服务角度,行情中心的核心服务如下图所示,自上而下可以概括为:(1)数据获取,(2)指标计算,(3)数据存储,和(4)数据分发。
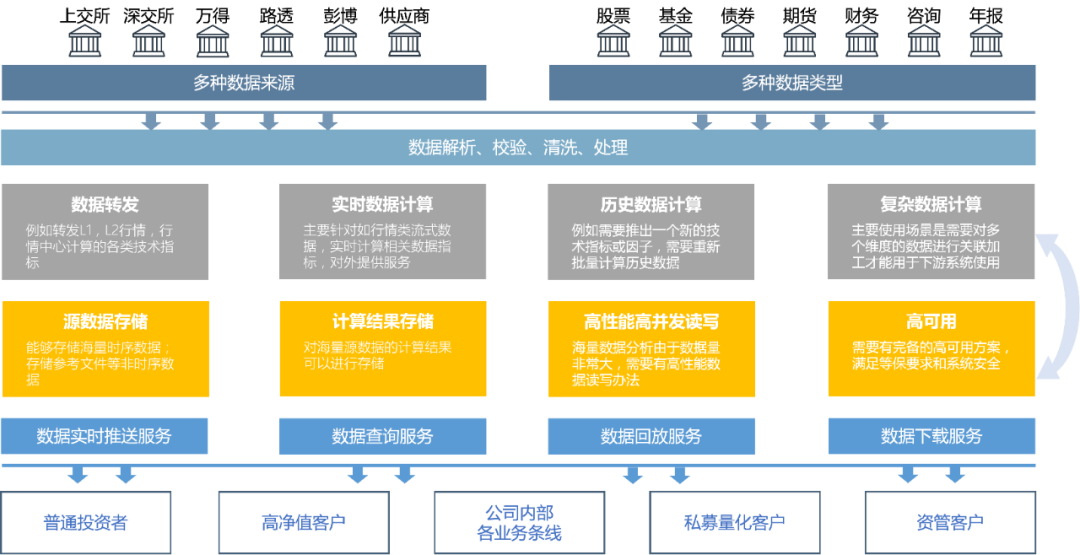
在业务层面上,行情中心正从简单地为下游系统提供行情原始数据的查询和下载服务,向交易和投研系统提供更多数据衍生服务演进。
03
行情中心的金融细分领域特点
行情数据的存取是一个行情中心最基本的需求。行情中心的大部分数据是典型的时间序列数据,时序数据库是最典型的存储解决方案。但是与物联网、APM 等时序应用场景相比,行情中心具有明显的金融的细分领域特点。
存储层
行情数据的不唯一性导致需要寻找适合金融数据存储的解决方案。多档报价数据的存储需要支持数组类型,以更高效地表示多档数据。为了支持面板数据分析,数据库需要提供宽表存储,允许按照多个标的的关系进行查询。委托和成交数据的关联需要考虑分布式表的关联性能。在技术建模方面,除了使用时序建模,部分基础数据和计算结果还需要关系建模的支持,为复杂的查询提供便利。
计算层
04
基于 DolphinDB 的行情中心
作为一个基于高性能时序数据库,支持复杂分析与流处理的事实计算平台,DolphinDB 在服务众多券商、私募、公募、资管和交易所客户的过程中,持续总结和吸收行情中心项目建设的经验,归纳形成了一套新型行情中心解决方案。通过针对金融行业的大量功能优化,DolphinDB 以其强大的存储和计算核心能力赋能行情中心技术建设。
灵活的存储能力
同一时间戳存储(交易数据的不唯一性)

交易数据不唯一
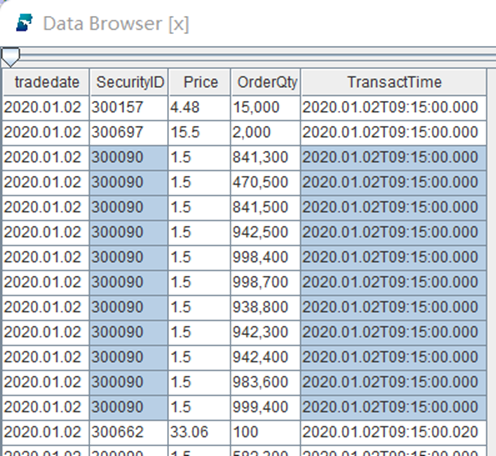
DolphinDB 原生支持不唯一数据存储
DolphinDB 区别于其他类型数据库,在底层架构上原生支持不唯一数据存储,同时 TSDB 存储引擎还能保证计算低延时。
数组存储(多档报价数据的存储)

10档行情数据示例

Array Vector 10 档行情存储
DolphinDB 支持数组(array)类型的列,在 array vector 中可以同时存10档数据。如上表所示,只需要 OfrPXs、BidPXs、OfrSizes 和 BidSizes 4列即可存储10档行情。数据压缩比可从4倍提高至10倍,间接提高了查询速度。另外,array vector 支持不定长存储,可以用于原始行情和因子存储。
宽表存储
横截面计算在时序数据处理中极为常见,交易中经常需要存储多个标的甚至全部标的在同一横截面上的因子,并且需要对横截面进行面板数据分析。宽表存储天然适合面板数据,并能减少数据冗余,提高查询速度。
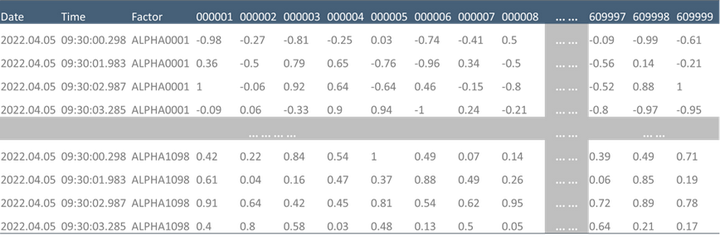
DolphinDB 宽表存储
co-location存储(委托和成交的关联)
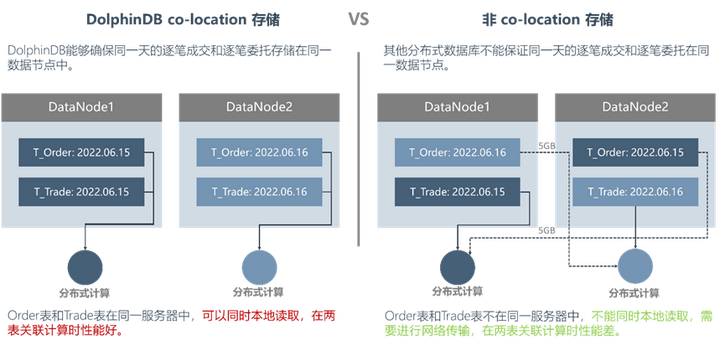
co-location 与非co-location 存储方案对比
在量化交易中,需要关联逐笔委托和逐笔成交用于微观结构分析、因子生成和交易策略。DolphinDB 的 co-location 存储架构会强行将同一交易日的订单表和成交表存储在同一数据节点中,在关联计算时只需要读取同一节点数据,如上图左侧所示。这样的存储架构可以避免节点间的数据传输,大幅提高计算速度。
多模数据库(时序建模+关系建模)
除需支持时序模型外,金融业务还需要支持关系模型。时序模型主要存储如行情、订单、委托和指标因子等具有时序特征的大数据;在实际业务中,如计算期权面值需要用到合约乘数,又比如对组合需要根据行业分类进行估值、因子、归因和风险计算,这些场景都是典型的关系模型。
DolphinDB 是一个多模数据库,同时支持时序数据模型和关系数据模型。支持 as of join, window join, cross join, equal join, full join, inner join, left join 和 prefix join 等多种数据关联方式。时序模型支持非同步关联,关系模型支持等值关联。
高可用
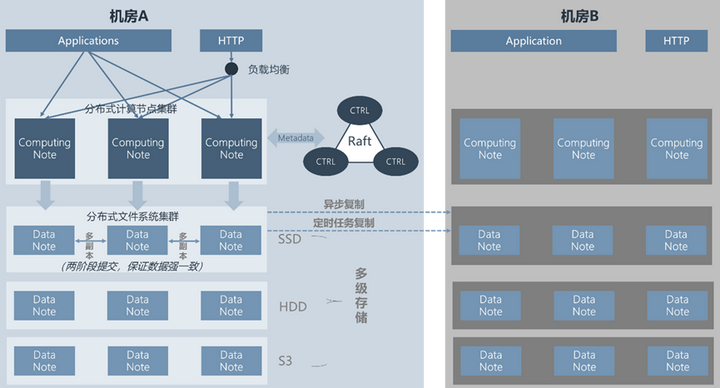
DolphinDB 高可用架构
应用层高可用
计算节点高可用
元数据高可用
数据节点高可用
多级存储
多集群数据同步
强大的复杂计算能力
除了数据存储,行情中心的计算同样极为重要。大多数时序数据库更侧重于数据存储和较为简单的计算,DolphinDB 在设计理念上将计算置于了和存储同等重要的位置。通过以下这些计算能力,DolphinDB 可以很好地应用在行情中心建设上,拓展更丰富的数据衍生服务。
数据透视和面板数据
DolphinDB 特有的 pivot by 数据透视功能,能够把原始数据转化成矩阵(数据面板)。下面以 IOPV(基金净值)计算为例。
1.timeSeriesValue = select tradetime, SecurityID, price * portfolio[SecurityID]/1000 as constituentValue from loadTable("dfs://LEVEL2_SZ","Trade") where SecurityID in portfolio.keys(), tradedate = 2020.12.01, price > 02.// 利用Pivot by数据透视汇总(rowSum)所有成分券在某一时刻的价值,即IOPV;如果当前时刻没有成交价格,利用ffill函数使用前一笔成交价格。3.iopvHist = select rowSum(ffill(constituentValue)) as IOPV from timeSeriesValue pivot by tradetime, SecurityID
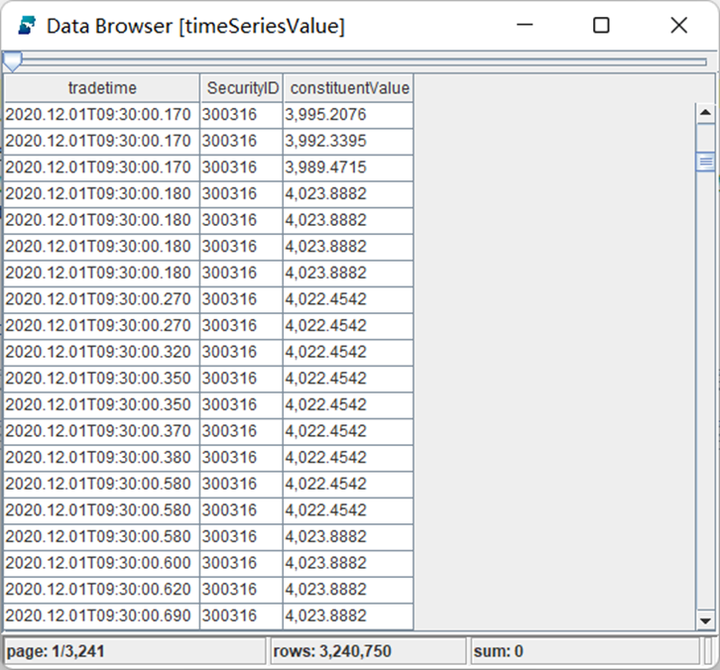
股票在时间序列上的价值
计算一只 ETF 的 IOPV,则需要把篮子中所有股票当前时刻的价值进行汇总,在这种场景下,可以使用 pivot by 生成矩阵(面板数据)。执行以下代码可以看到 pivot by 后的面板数据。
tmp = selectconstituentValue from timeSeriesValue pivot by tradetime, SecurityID
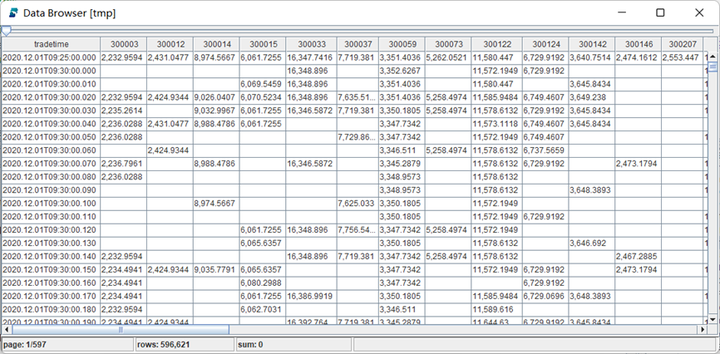
pivot by生成的股票价值矩阵(面板数据)
窗口函数

DolphinDB 窗口函数
DolphinDB 支持数十种复杂的滑动、滚动和累计窗口计算函数。支持均值、最大、最小、中间值等较为简单的窗口计算;也支持最小二乘数估计、person 相关性、协方差、标准差、移动加权平均等较为复杂的函数。满足技术指标中的各类复杂计算。
非同步关联
asof join
asojTable = select * from aj(trades, orders,`Symbol`Time)
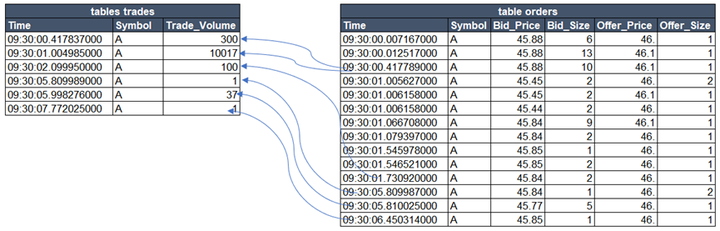
asof join 非同步关联逻辑
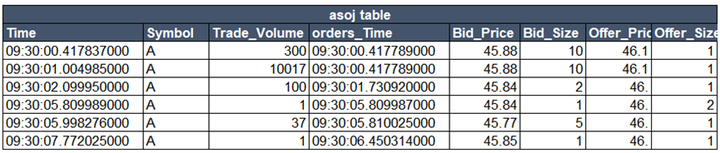
asof join 关联结果
window join
Window join 可以对某一段时间范围的数据进行聚合,例如计算100毫秒内的均价。
winjTable = select * from pwj(trades, orders, - 100000000:0, <[avg(Bid_Price) as Avg_Bid_Price, avg(Offer_Price) as Avg_Offer_Price]> ,`Symbol`Time)
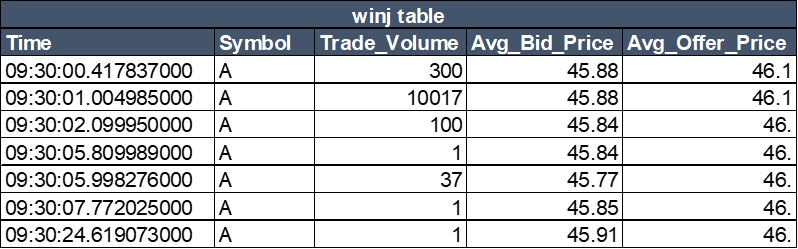
window join 关联结果
大家可以点击下方链接跳转查看更多实时关联分析操作指南:成交、委托、报价……实时关联分析操作指南
流式计算和流批一体
八种流计算引擎
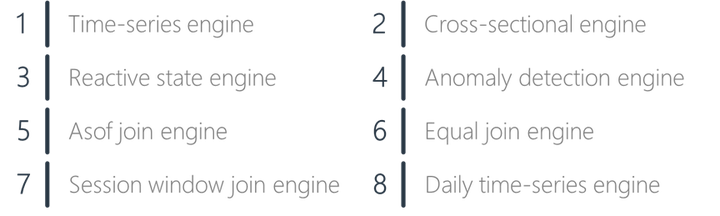
DolphinDB 流计算引擎
增量计算
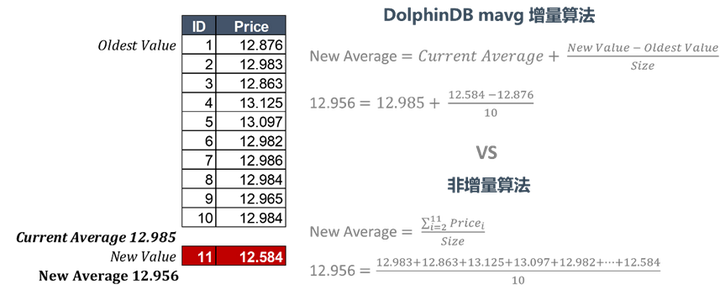
DolphinDB 增量算法
流批一体

DolphinDB 实现了流批一体架构
流批一体是指历史批量数据建模分析使用的代码和实时流式计算使用的代码一致,并保证流式计算和批量计算的结果完全一致,被称之为“流批一体”。批流一体的优势在于只需要写一套投研阶段使用的代码就能在实时生产中复用,可以大幅减少开发工作量,并确保两个环境计算结果的一致性。
多表数据回放
DolphinDB 支持历史数据回放。交易所提供的 Level 2行情有3大类数据,分别是快照类数据、逐笔成交类数据和逐笔委托类数据。在回测中,我们常需要将这三种不同类型的数据关联回放,使回测过程尽量模拟生产。
1.orderDS = replayDS(sqlObj=<select * from loadTable("dfs://order", "order") where Date = 2020.12.31>, dateColumn=`Date, timeColumn=`Time)2.tradeDS = replayDS(sqlObj=<select * from loadTable("dfs://trade", "trade") where Date = 2020.12.31>, dateColumn=`Date, timeColumn=`Time)3.snapshotDS = replayDS(sqlObj=<select * from loadTable("dfs://snapshot", "snapshot") where Date =2020.12.31>, dateColumn=`Date, timeColumn=`Time)4.inputDict = dict(["order", "trade", "snapshot"], [orderDS, tradeDS, snapshotDS])replay(inputTables=inputDict, outputTables=messageStream, dateColumn=`Date, timeColumn=`Time, replayRate=10000, absoluteRate=true)
多编程范式
SQL和脚本语言融合
在 DolphinDB 中,脚本语言与 SQL 语言是无缝融合在一起的。这种融合主要体现在几个方面:(1)SQL语句是 DolphinDB 语言的一个子集,一种表达式。SQL 语句可以直接赋给一个变量或作为一个函数的参数;(2)SQL 语句中可以使用上下文创建的变量和函数。如果 SQL 语句涉及到分布式表,这些变量和函数会自动序列化到相应的节点;(3)SQL 语句不再是一个简单的字符串,而是可以动态生成的代码;(4)SQL 语句不仅可以对数据表(table)进行操作,也可对其它数据结构如 scalar, vector, matrix, set, dictionary 进行操作。
向量化编程
向量化编程是 DolphinDB 中最基本的编程范式。DolphinDB 中绝大部分函数支持向量作为函数的入参。函数返回值一般为两种,一种是标量(scalar),这类函数称为聚合函数(aggregated function)。另一种返回与输入向量等长的向量,称之为向量函数。向量化操作有三个主要优点:(1)代码简洁;(2)降低脚本语言的解释成本;(3)可对算法优化,提升性能。
函数化编程
DolphinDB 支持函数式编程,包括纯函数(pure function)、自定义函数(user-defined function)、匿名函数(lambda function)、高阶函数(higher order function)、部分应用(partial application)和闭包(closure)。
即时编译(JIT)
欲了解更多 DolphinDB 详情,可扫描下方二维码添加小助手,获取咨询服务的同时,还能加入因子挖掘交流群,与众多量化技术咖互动~

