




StarRocks 于 4 月底正式发布了 3.0 版本,该里程碑版本带来了大家期盼已久的新特性--存算分离。此新功能一推出,即受到社区热情追捧,用户纷纷开始在自己的业务中评估和测试存算分离效果。从芒果TV、聚水潭、网易邮箱、浪潮、天道金科等数十家用户的测试反馈来看,存算分离在查询性能,弹性扩缩容,降低存储成本等方面均有不错的表现!目前多个用户也开始在实际业务中陆续上线使用!
StarRocks 存算分离上线的场景包含电商 ERP 订单分析系统、金融业务数据分析和制造业设备数据分析。由此可见,StarRocks 存算分离已达到生产可用的高标准。
实测结果公开:用户见证 StarRocks 存算分离优异性能!
性能是否强悍依旧?
大家首先关注的点还是存算分离能否继续保持 StarRocks 存算一体模式下强悍的查询性能,下图展示了在 TPC-DS 1TB 数据集规模下存算分离和存算一体的性能测试结果:

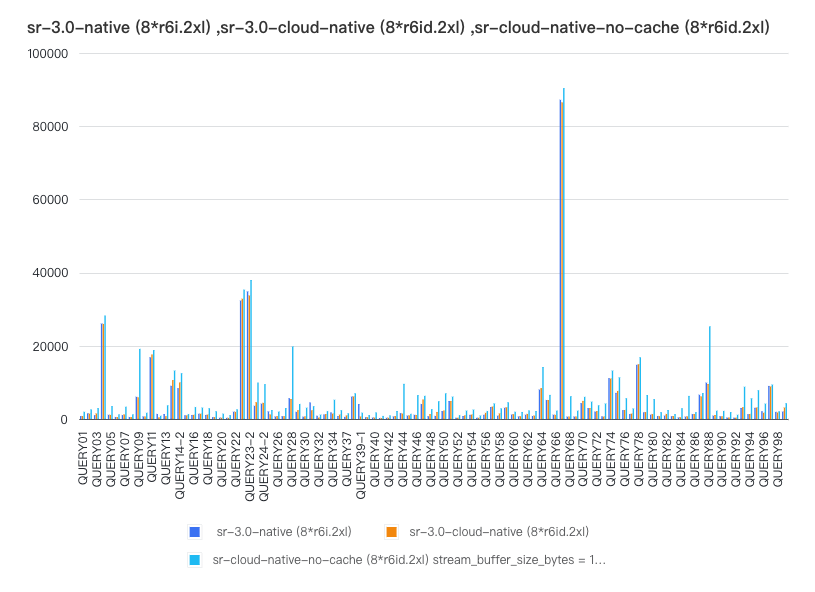
标准数据集结果显示:
在 cache 全命中的条件下,存算分离性能与存算一体查询性能几乎保持一致
即使在 cache 完全 miss 情况下,查询性能下降也在可接受的范围内
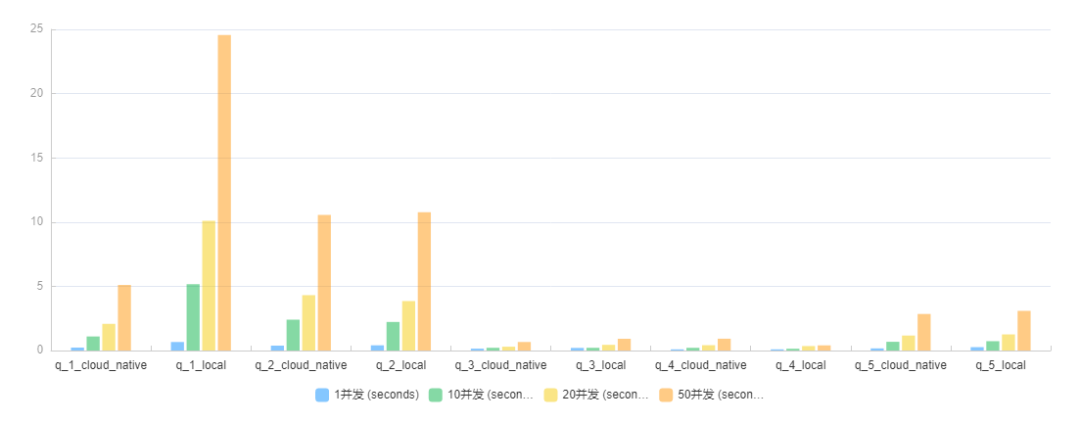
除了标准数据集,社区小伙伴也拿真实业务验证了这一点,社区用户杨荣反馈了真实业务场景中测试的查询结果:
“从下面的对比图可以看出,q2 - q5 四个 sql,local 表与 cloud native 表的查询性能基本持平,q1 在 10 并发以上的场景下 cloud native 表都比 local 表查询性能要好”。
👉🏻 参考报告:https://forum.mirrorship.cn/t/topic/7095
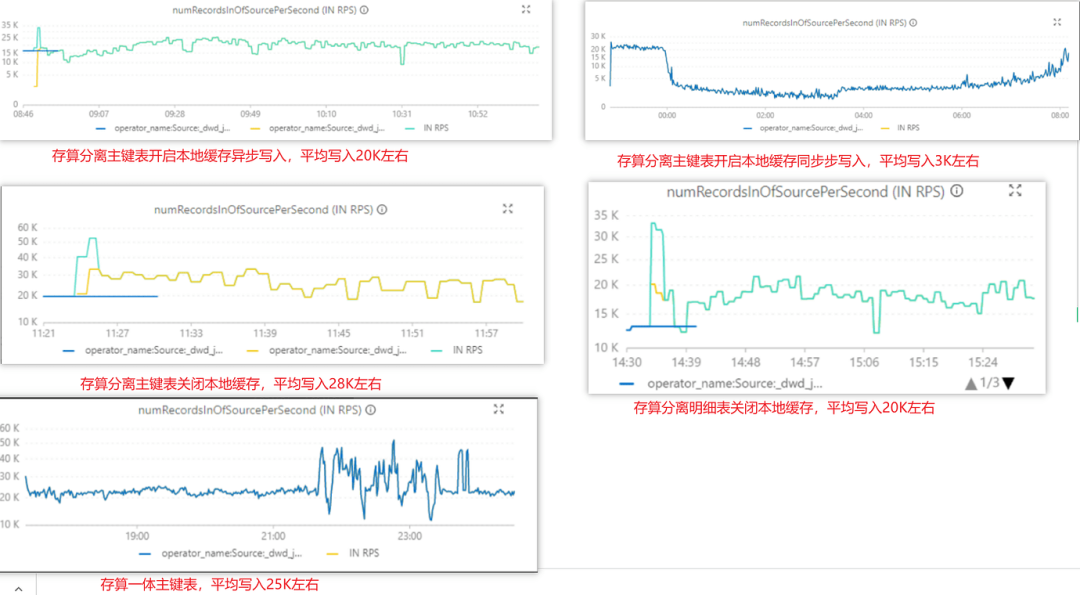
而来自社区用户聚水潭则从导入和高并发查询评估性能:
“对于单 SQL 查询来看,开启本地缓存后有明显优化,查询性能基本和存算一体表持平,根据回放测试表现来看,基本都可以符合在 100 左右的 QPS,对于当前的业务场景基本符合预期”
👉🏻 参考报告:https://forum.mirrorship.cn/t/topic/7038
功能是否完备?
StarRocks 存算分离版本自推出开始就在功能上与存算一体保持同步,存算一体上的各种新功能在存算分离版本上通过快速的版本迭代也能无缝体验。
在 4 月底推出的 3.0 版本中我们支持了明细模型、聚合模型的存储计算分离能力,并且支持了国内外所有主流对象存储系统以及 HDFS 等。在后续的 3.0.x 版本中社区将持续优化内核,保证在各种存储系统上都能完美运行。此外,在 3.0 版本中,我们也推出了基于 Local Disk 的热数据 Cache 能力,保障存算分离下极致的查询性能。
在即将推出的 StarRocks 3.1 版本中,我们将会重点支持主键模型的存算分离,不少社区小伙伴已经通过最近的 RC 版本抢先体验了该能力,基于对象存储,数据依旧可以实时更新!另外,我们还将推出自研的更细粒度 Cache 机制,进一步提升缓存效率。该版本也将成为我们的 LTS 版本,用户就可以在生产环境中大规模使用存算分离。
所以,存算分离和存算一体在功能上不仅保持一致,还有以下优势:
支持公有云、私有化部署模式,随时随地开箱即用
支持基于 S3 协议/HDFS 存储,节省存储空间的同时提升数据的可靠性
支持所有的表模型(明显模型,聚合模型,更新模型,主键模型),用户切换 0 成本
物化视图能力,外表查询等能力与存算一体一致,湖仓加速毫不费力
可否灵活弹性?
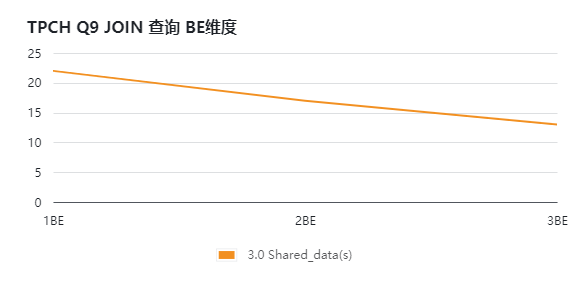
部分社区小伙伴业务有比较明显的峰谷特点,看中了存算分离的弹性能力,验证了在节点扩容时性能也能同步提升:
搭建 StarRocks 3.0 存算分离版本,通过增加 BE 计算节点的方式,对 SSB 和 TPCH 进行压测,得到如下测试结果。通过下面的图表(横坐标为 BE 数量,纵坐标为响应时长,单位 s)可知:
集群整体的查询能力随计算节点数增加而提升

可否真的降本增效?
看完了性能,聊完了弹性。接下来让我们简单算算账,看看存算分离能为用户省多少 money!
以下是某在线教育头部用户的某个集群统计数据,其当前 StarRocks 规模大概如下:
每日新增导入数据量约为 1.6TB(最大,日常大概新增约 500GB),每秒导入次数最大约为 2(15 秒导入20+ 次),Tablet 数量 15
BE 节点数目为 5,集群总节点数量为 6(FE 和 BE 有混部),节点规格为 32core 128G 内存
每年元数据 PutObject 调用产生的次数为 2 * 2 * 15 * 3600 * 24 * 365 = 1892160000
每年 Segment 上传而产生的 PutObject 调用次数为 2 * 15 * 3600 * 24 * 365 = 946080000
总的次数为 2838240000
存储介质成本对比(1 TB 数据年费用)

存算分离稳定了吗?
存算分离怎么用?
StarRocks 的存算分离版本目前已经在 3.0 版本发布,用户可自行前往官网下载体验测试,且存算分离同时支持物理机和 K8S 环境部署。另外,社区也正积极和国内各大云厂商合作,即将在各公有云 EMR 服务上线存算分离版本,用户可以通过各种不同渠道体验存算分离新能力。
👉🏻 下载链接:https://www.mirrorship.cn/zh-CN/download/community
StarRocks 存算分离,立刻行动,即刻上线!
💬 StarRocks Feature Group-存算分离:
对 StarRocks 存算分离功能感兴趣的小伙伴们欢迎加入我们的“StarRocks 存算分离用户小组”。下方扫码添加小助手,回复关键字“存算分离”即可加入,马上开启你的降本增效之路!👇🏻

关于 StarRocks

