




引言:
因某项目需要从PostgreSQL 15数据库迁移到OpenGauss数据库,迁移过程中需要处理二者之间的差异,于是在迁移完成后对涉及到的语法差异进行了整理,供有类似需求场景的同仁参考。
迁移过程:
数据库迁移有两种方式,在线迁移和离线迁移。其中在线迁移多为新增或者扩容同一款数据库时使用。而本例中是从易构的PostgreSQL迁移到OpenGauss,所以采用离线方式,先把数据导出到中间存储服务器(本例为个人办公电脑),在存储服务器对数据和脚本(主要是脚本)进行适配修改,然后导入到目标数据库。当前较为典型的此类场景是从ORACLE\MySql\Postgre等切换至GaussDB等国产数据库,如本课程所讲的OpenGauss。
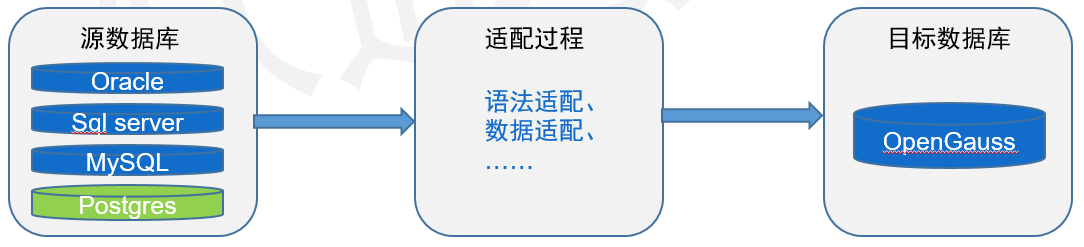
由于该迁移数据库的项目还处于开发阶段,并没有商用,所以迁移可以采取离线方式,期间可能会经过多次回归和修改,这个过程如下图。
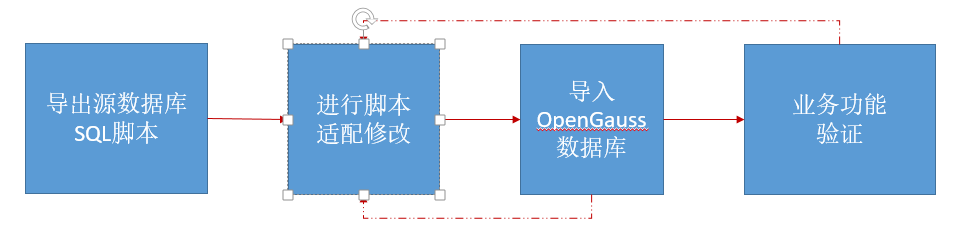
1. 可行性分析
OpenGauss已经演进到5.0.0版本,功能丰富,具备高性能,高可用,高安全,支持AI4DB和DB4AI,数据库周边生态也逐步鉴权,在多个行业如金融,电信等核心业务进行部署,因此OpenGauss是可以支持该项目迁移的。此外OpenGauss兼容性好,特别是对PostgreSQL的语法兼容达到95%以上。实际上相较而言从PostgreSQL迁移到OpenGauss,比从MySQL迁移要轻松很多。
2. PostgreSQL数据库脚本导出
通过客户端工具或者PG_DUMP命令,导出数据库脚本。
pg_dump -d testdb -U zhaofengtest -h 127.0.0.1 > testdb.sql3. 脚本进行语法适配修改
针对分析出来的语法和数据差别等,对导出的SQL脚本进行修改,多数是对关键字进行全文replace,少数是对特定应用进行单点修改。
4. 导入OpenGauss
修改完成后的SQL文件,通过OpenGauss支持的逻辑恢复功能导入到OpenGauss数据库中。可以在GSQL客户端,或者DATASTUDIO客户端执行SQL脚本。
5. 业务验证
对项目涉及的业务进行全部功能的测试验证,期间发现的问题,再回退到第3和第4步进行循环操作,直至迁移前后系统功能及性能等一致或优于切换前的系统。
差异小集:
数据迁移首先是创建数据库,然后创建表,视图等数据库对象,再进行数据的迁移,功能验证。因此遇到的第一个问题就是创建数据库方面的区别。
1.
建库语句
PG建库语句:
create database
testdb owner testuser encoding UTF8;
(PG的utf8也可以用单引号引起来,不会报错)
OpenGauss建库语句:
首先:PG建库语句直接在opengauss数据库运行是会报错的,如下:

根据OpenGauss建库语法做修改如下:
create database test2 owner = testuser encoding
'utf8' ;
说明:其中的等号“=”可以忽略,也可以加上,二者的差别只是'utf8'在openGauss的建库脚本中要用单引号引起来,需要注意双引号引起来也会报错,utf不区分大小写。

owner说明所创建数据库的所属者,owner缺省时新数据库的所有者是当前用户;encoding说明数据库的字符集,不指定时默认使用模版数据库的编码。
2.
建表语句
项目中涉及到的建表语句的区别主要有两点,1是由于OpenGauss支持行存和列存,所以建表时支持指定存储方式(不指定时默认为行存,可显式指定为列存),列存储适合大量查询表中的部分列的场景。脚本如下所示:
CREATE TABLE
t_orientation_column ( column_id
uuid, column_name varchar(255) NOT
NULL)WITH (orientation=column);
2是OpenGauss列存储支持压缩,建表语句增加配置compression参数即可。
CREATE TABLE t_compression_yes ( column_id int NOT NULL, column_name varchar(255) NOT NULL)WITH
(orientation=column, compression='yes');
说明:行存表不支持压缩,列存表对表数据压缩可选值有:no,yes,low(默认),middle,high,一般来讲,压缩级别越高,压缩比越大,压缩时间越长,当然也会越节约空间,反之亦然。
3.
数据类型
PostgreSQL数据库相对于OpenGauss来说数据类型比较简略,而OpenGauss由于要兼容O记及MySQL等数据库的语法,所以给一些数据类型增加了别名,因此数据类型较多。
该项目数据库迁移过程涉及到的数据类型差异如下表:
|
数据类型 |
PG |
OpenGauss |
|
VARCHAR(n) |
N指字节长度 |
N指字符长度 |
|
VARCHAR2(n) |
无 |
兼容oracle,是varchar(n)的别名 |
|
NVARCHAR2(n) |
无 |
变长字符串。n是指字符长度,等同于PostgreSql的VARCHAR(n) |
|
TINYINT |
无 |
微整数,别名为INT1。1字节【 0 ~ 255】 |
|
BINARY_IN TEGER |
无 |
常用的整数INTEGER的别名,为兼容Oracle 类型。 |
4.
函数
项目迁移主要涉及到判断为空和日期函数的区别。
4.1
判断为空opengauss用nvl函数,举例如下:
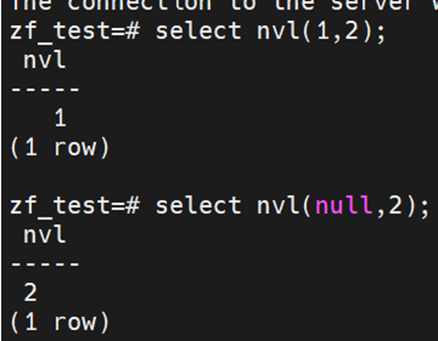
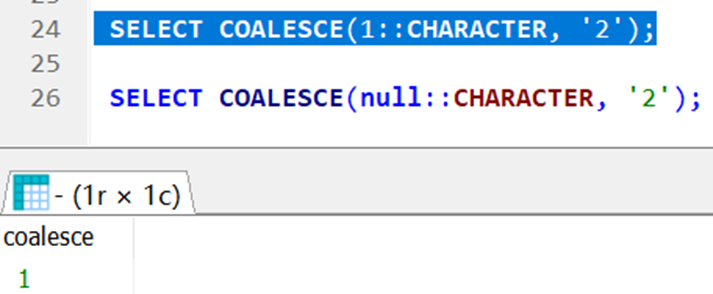
而PG不支持NVL函数,要判断是否为空返回,用的是COALESCE函数。
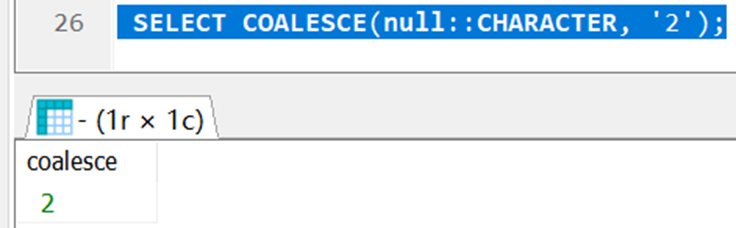
4.2
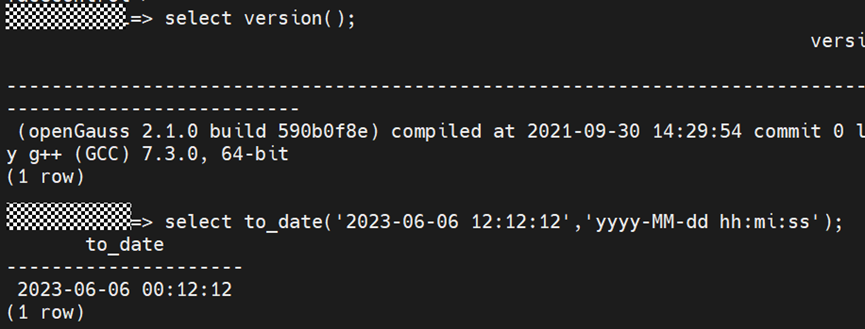
关于日期函数,OpenGauss在2.1.0版本中to_date()函数包含时分秒,但是5.0.0版本和PG一样去掉了时分秒。如下:
OpenGauss 5.0.0版本:

OpenGauss 2.1.0版本
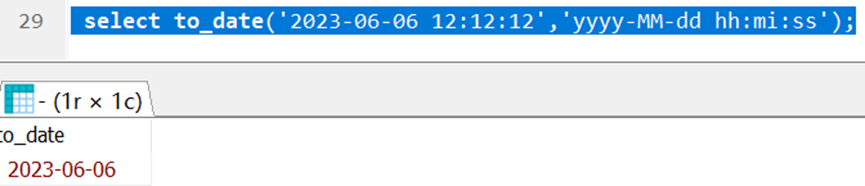
PG库的处理和OpenGauss 5.0.0版本一致:
顺便多说一句,个人觉得高版本应兼容低版本的功能,当然如果PG往5.0.0版本迁移,则不需要做额外处理,OpenGauss可能有这方面的考虑才做的改动。
5.
关于插入相同主键数据的处理:
经常遇到的场景,插入某数据,如果存在则更新。比如员工的下班打卡,第一次打卡新增一条记录,如果再次打卡,则对打卡时间进行update即可,不用再新增记录。
这个功能PG和OpenGauss的处理有区别。
PG用关键字conflict:
INSERT INTO zf_test VALUES (1,'zhaofeng') ON CONFLICT(stu_id) DO UPDATE SET stu_name = 'zhaofeng2';
或者:
INSERT INTO zf_test VALUES (1,'zhaofeng') ON CONFLICT ON CONSTRAINT zf_test_pkey DO UPDATE SET stu_name = 'zhaofeng3';
说明:zf_test_pkey为约束名称。
OpenGauss用关键字duplict,且update后面不能带set:
insert into zf_test(stu_id,stu_name) values
(1,'zhaofeng') ON
duplicate key update
stu_name = 'zhaofeng5';
以上只是整理了迁移过程中遇到的点,难免挂一漏万,还请方家提出宝贵意见。
