




使用人工智能(AI)和机器学习(ML)的核心目的是通过建立训练有素的模型来理解大量数据。就像运动员在即将到来的比赛中需要训练以获得极佳表现一样,ML模型也必须经过训练才能在部署到生产中时获得非常好的表现。训练有素的模型可以在计算基础设施上快速、经济高效地提供准确结果,并对失败有较小的容忍度。
大型语言模型(LLM)使用海量数据,例如在互联网上部署的数年数据。它从这些信息中学习,以各种方式帮助我们,包括总结文本、检测犯罪、编写软件以及以下示例用例:
与目前市场上广泛使用的聊天机器人相比,能够更有效地回答复杂的客户问题并解决客户疑问的聊天机器人
人工智能助手,可帮助研究人员发现新的见解。例如,生物学家可以从发表的材料和公共卫生记录中获取数据,帮助发现新的疗法
专业助理,可帮助律师准备和分析案情,帮助营销人员优化文案和细分客户,帮助销售经理确定新的增长点,帮助开发人员编写软件,等等。
以ChatGPT为例
ChatGPT由人工智能研发实验室Open AI开发,是一种流行的人工智能,可以对一般问题生成人类可读的回答。由于它的多功能性,ChatGPT可以发展当今的搜索引擎,为搜索结果补充更有洞察力的答案。
Superclusters以及在大预言模型训练中的角色
使用大型语言模型训练人工智能应用(如ChatGPT)需要能够处理海量数据的强大计算基础设施集群。这些Superclusters包含数百或数千个由高性能网络结构连接的裸机计算实例。这些计算实例共同提供了大规模处理训练数据集的能力。Meta AI估计,随着模型变得越来越大、越来越复杂、适应性越来越强,这些Superclusters必须能够每秒执行五万亿次操作。
甲骨文云基础架构(OCI)的人工智能基础架构已经能够帮助Adept和SoundHound等客户处理大量数据,以训练大型语言模型。我们对OCI的集群网络进行了优化,以使用RDMA over converged ethernet (RoCE)支持超低延迟。您可以通过我们的Oracle网站解更多有关我们的大规模Superclusters网络以及使其成为可能的工程创新的信息。
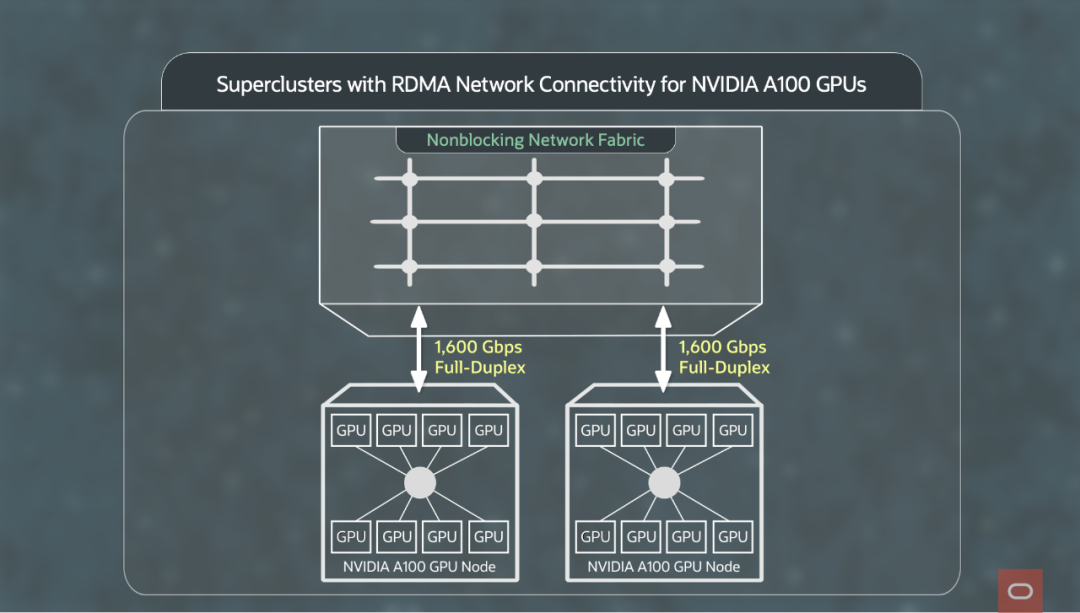
下图展示了具有RDMA网络连接的Superclusters。每个GPU节点有8个NVIDIA A100 Tensor Core GPU,与网络结构的全双工连接总计1.6Tbps(1600Gbps)。网络结构被设计为无阻塞,并为所有主机提供全分段带宽。(分段带宽是指网络任意两部分之间可用的minimum带宽)。
OCI与AWS以及谷歌云平台(GCP)的比较
训练大型语言模型是极其耗费网络资源的。训练这些模型需要在成百上千台独立服务器之间协调和共享信息。OCI GPU通过使用RDMA的简单、高性能以太网连接。OCI提供的带宽是AWS和GCP的4-16倍,这反过来又减少了ML训练的时间和成本。三家供应商公布的带宽分别为
OCI 的BM.GPU.GM4.8 实例: 1600 Gbps
AWS 的P4D 实例: 400 Gbps
GCP 的A2 实例: 100 Gbps
OCI的集群网络技术得到了Adept、MosaicML和SoundHound等尖端AI/ML创新企业的验证。在发布时,AWS和谷歌云平台使用的互连技术类型并不完全透明:Infiniband、以太网或其他技术。与OCI的简单性相比,AWS EFA等增强功能在配置和软件方面造成了复杂性,在用于ML训练之前必须进行彻底测试。通过保持互连的简单和快速,OCI为训练大型语言模型提供了非常好的环境。
想要了解更多?
OCI提供云工程师支持,用于训练大型语言模型和大规模部署人工智能。要了解有关Oracle云基础架构功能的更多信息,请联系我们或查看以下资源:
AI基础架构(https://www.oracle.com/cn/ai-infrastructure/)
OCI计算: GPU 实例(https://www.oracle.com/cloud/compute/gpu/)
编辑:殷海英

