




一、问题背景
上个月将生产环境的某个库迁移到新的节点后,经常会在凌晨出现CPU偏高的告警。查看监控图表如图一所示。

图一、问题时间段的数据库资源使用指标曲线
根据告警日志排查,发现源头的数据库实例是一个从库,供业务系统大数据报表使用的,作为大数据ETL的数据源。
进一步,通过性能诊断工具查看,发生问题的时间段发现有密集的慢SQL。

图二、问题时间段的慢SQL
二、问题分析过程
2.1 资源负载和业务流量分析
在图一展示的各条SQL语句中,排名第一的Select语句最大执行时间16s。
首先查看与这条语句相关的资源负载和业务流量情况。如图三所示,在问题事件段,活跃会话数(AAS)最高一度达到了80,远超CPU核数,说明并发也很高,执行期间引起了cpu100%以及网络IO的明显增长(纵向对比同时间段的Utils和Bytes IN/OUT曲线的可以看到)。
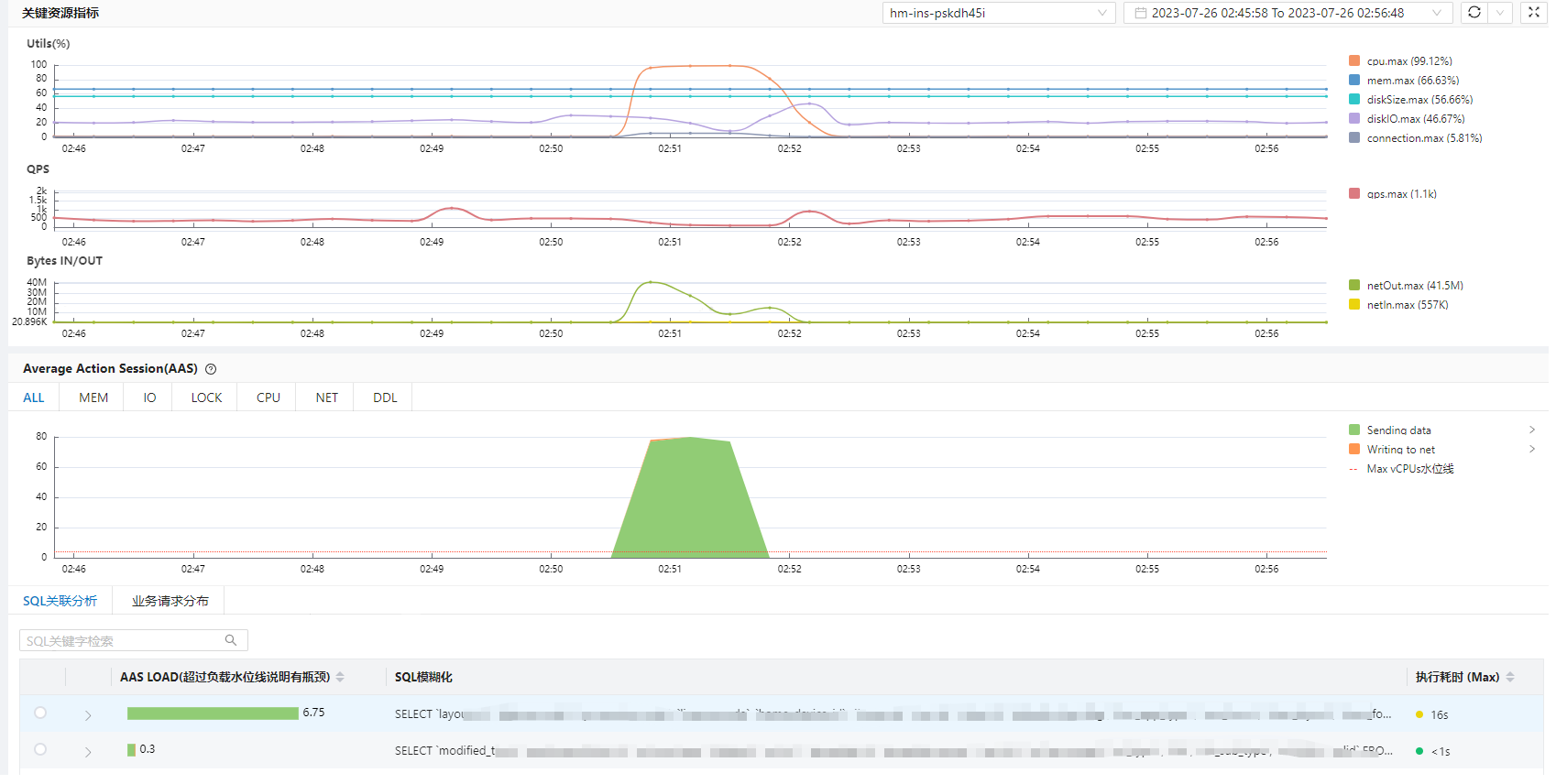
图三、SQL关联分析
2.2 慢查询分析

图四、慢查询分析
捕获的样例SQL:
SELECT `layout_id`,... FROM channel_layout_api WHERE layout_id%100 >= 431494 AND layout_id%100 < 433160- 如图四所示,选中问题SQL,点击“查询执行计划”,发现查询类型为ALL,即全表扫描,扫描行数接近35w。
- 查看样例SQL的查询条件,发现有使用%100取模运算。
- 取模后的条件比较也有问题,100取模后必定<486472,即该条件无过滤效果,结果集也是全表,没达到取模的效果。
- 查询数据库表结构与索引情况,结果如下,查询字段layout_id为主键索引。
channel_layout_api | CREATE TABLE `channel_layout_api` (
`layout_id` bigint(20) NOT NULL AUTO_INCREMENT,
`create_time` bigint(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
......省略无关字段
PRIMARY KEY (`layout_id`),
.......省略无关索引
)
三、问题根因定位
原因1:虽然layout_id为主键索引,但是由于查询条件里使用了取模运算,导致索引失效。
原因2:取模操作后的比较条件有问题,导致查询的返回结果不是预期的1/100的数据,而是全表的数据,进一步恶化SQL执行效率。
知识扩展:
(1)该场景索引失效的原因:
Innodb索引采用B+tree模型,按照【索引值】有序排列存储,而不是按照取模计算后的值存储,取模计算后的值无法与索引值进行比较,所以无法走索引,只能通过把索引字段的取值都取出来,然后依次进行表达式的计算来进行条件判断,因此采用的就是全表扫描的方式。
(2)其他常见索引失效场景:
- 联合索引不遵循最左前缀原则
- 对索引字段进行函数计算
- 对索引字段进行运算符计算
- 对索引字段进行左、左右模糊匹配
- 对索引进行类型转换,包括隐式转换
- OR前后存在非索引列
- 数据倾斜,符合索引条件的数据占比很高
四、优化建议
开发优化建议:
- 考虑是否必须使用取模操作,能否修改ETL取数规则,比如按照id或者时间范围切分查询。
- 修复错误的无过滤效果的比较条件。
最后修改时间:2023-08-08 17:24:26
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
