




问题现象
管控面上报etcd服务异常告警, 磁盘IO/CPU/内存 很高.
问题分析及界定
进入Ruby用户
cd $GAUSSLOG/cm/etcd
查看对应时间点的etcd_xxx.log日志,告警时间点有如下日志,说明etcd节点负载过重, 磁盘IO、CPU等压力大。
2021-04-09 10:57:40.112936 W | wal: sync duration of 2.00201804s, expected less than 1s ===通常这个表示磁盘IO压力大。
2021-04-09 10:57:40.112993 W | etcdserver: failed to send out heartbeat on time (exceeded the 1s timeout for 2.124414ms, to c8eccd97bed22939)
2021-04-09 10:57:40.112999 W | etcdserver: server is likely overloaded
2021-04-09 10:57:43.126444 W | etcdserver: read-only range request “key:”/Ruby/ignoreNodeNumKey" " with result “error:context canceled” took too long (1.999877971s) to execute
cd $GAUSSLOG/cm/cm_agent
搜索对应时间点的cm_agent-xxx.log, 如果有如下日志,表示当时磁盘io比较高, io util 100 表示磁盘io 达到100%
2021-04-09 11:06:24.047 tid=15822 LOG: device vdb1, tot_ticks 889640579, cputime 1798651342, io util 100
处理步骤
1、在管控面查看该节点当时磁盘IO、CPU、内存监控指标是否很高,
示例1:数据盘写延时在16:00左右升高,影响etcd状态。
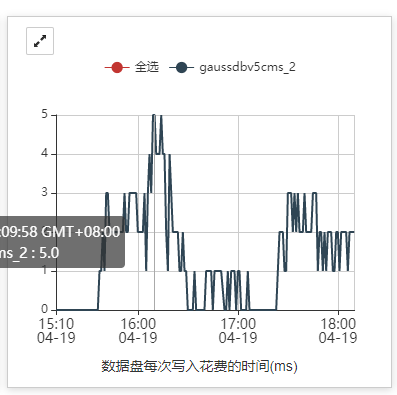
cke_191.png
示例2: etcd故障时刻,cpu、内存、磁盘写延时都有增长,尤其是磁盘写延时很明显,需要分析磁盘写延时升高的原因。
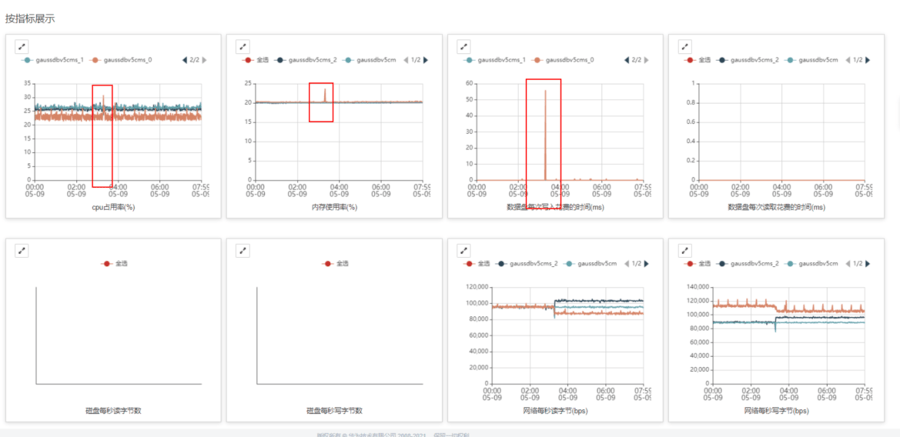
2、如果故障现场还在: iostat -mx 1 查看磁盘IO状态,top和free命令查看cpu、内存使用情况, 分析磁盘IO高、CPU高,内存高的原因。
3、root用户查看该节点的系统日志, cd /var/log, 查看该时间点message日志是否有异常记录。例如:节点内存耗尽了,分析占用内存的原因,是否内存泄漏等。
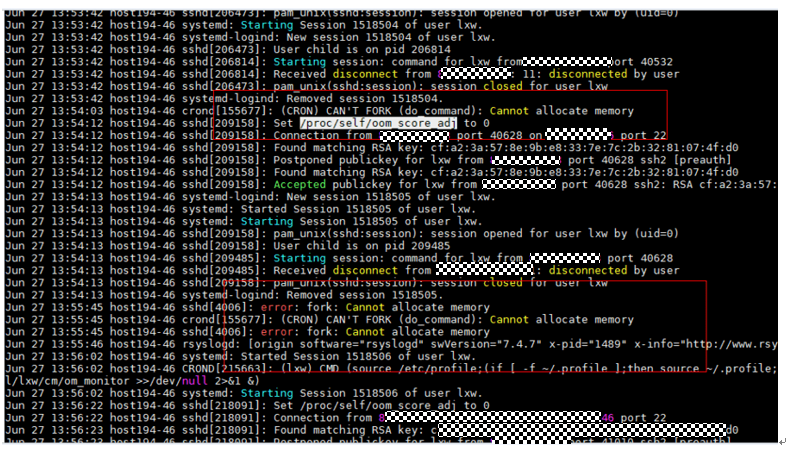 cke_193.png
cke_193.png
如果仍无法确认原因,联系华为工程师。
