




小 T 导读:伴随工业物联网的热度,涉足云组态的企业越来越多。云组态是工业物联网平台的数据展示终端形式之一,是可以一站式完成终端设备数据采集、实时控制、报警推送、分组管理、组态设计等功能的物联网系统。一个强大的云组态平台,必须具备强大的数据处理能力,上海繁易是一家设备智能化产品及服务提供商,在其工业物联网云组态的数据库选型中,先后对比测试了4种方案,最终选择了TDengine。
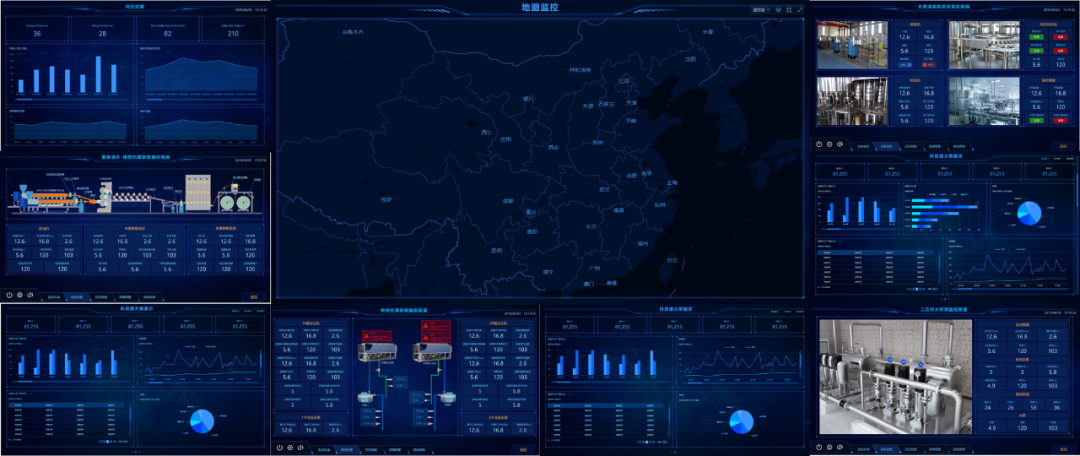
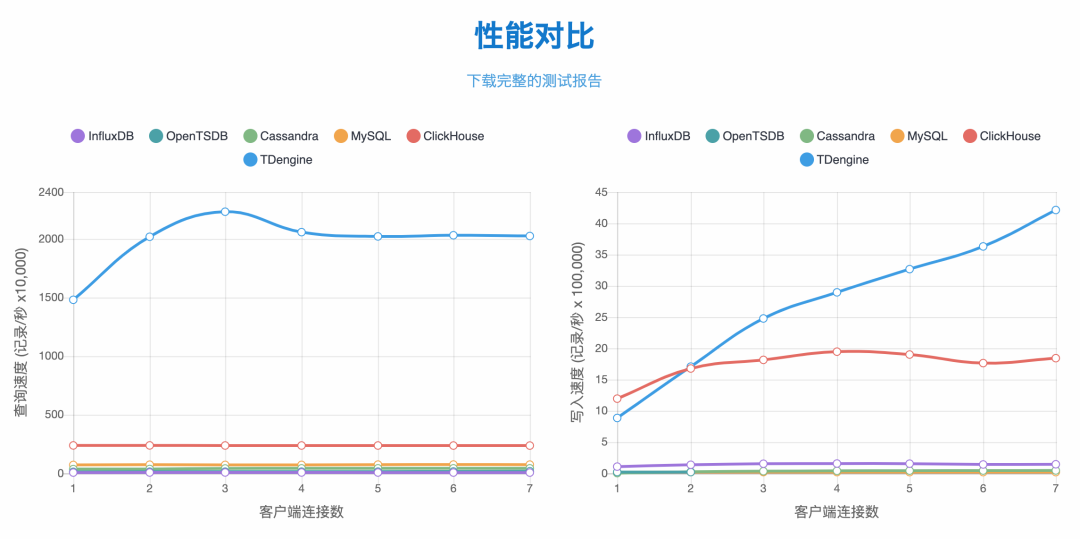
数据库方案选型
1)比较耗费服务器资源,Kudu数据落盘后也存在Compaction策略,导致cpu会比较高。
2)写入速度比较慢(3节点2C8G配置目前每秒写入条目不到2万)。
3)数据要先从kudu读取到impala中再做计算,一旦数据过多,查询缓慢,用户无法忍受。
1)HBase集群配置要求高,需要很好的调优。
2)OpenTSDB默认的compaction策略每到整点都会对上一小时的数据查询出来compact成一行,写入到HBase,删除原始数据,这个相当耗费cpu。即使关闭compaction,修改tsd.storage.enable_appends = true 启用append的方式低配机器 cpu也是相当高。
Cassandra是一套开源分布式NoSQL数据库系统。从其他团队使用的情况来看,cassandra比较适合查询小部分连续原始数据,不太适合做分析,没有降采样等功能,要出统计表只能取一部分少量数据数据查询出来后再在内存处理出结果。这样用户只能看短时间内的数据曲线,实用性不高。
1)安装简单。下载rpm包,一个命令安装完毕即可运行。
数据采集和查询方案设计
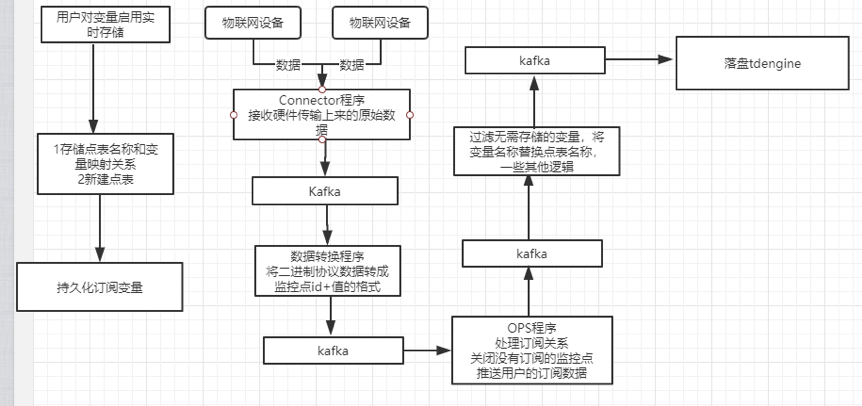
遵循TDengine一个数据源一张表的设计思路,我们认为每个变量就是一个数据源,因此对每个变量会建立一张表。没有采用一个设备一张表的原因是由于工控行业中同一个采集设备内的变量采集周期不一定会一致,另外一个设备的变量也很多,超过100个是很普遍的现象,列过多,有些列又没有数据,会浪费空间。因此这里考虑使用一个变量一张表,会灵活得多。由于TDengine表名不能包含中文,需要在写入前的预处理环节中,将变量名称映射成TDengine表名。具体做法是使用雪花算法,每个设备id+变量名称(云组态中这样才能唯一确定变量)换一个雪花算法id,缓存在内存中,持久化存储到mongodb。这样做就确保了变量id唯一、TDengine表名唯一,映射关系简单。
我们使用TDengine时,需求暂时没有涉及到过多的标签查询,因此表的设计比较简单,1张超级表和多张子表即可满足。建立超级表的原因是方便后续多变量组合查询。具体建表思路是:
1. 首选创建超级表:
CREATE TABLE IF NOT EXISTS {_tsdbSettings.DbName}.variables (ts timestamp, val float) TAGS (vkey binary(200));
2. 创建子表:
CREATE TABLE IF NOT EXISTS {tableName} USING {_tsdbSettings.DbName}.variables TAGS ('{tag}');
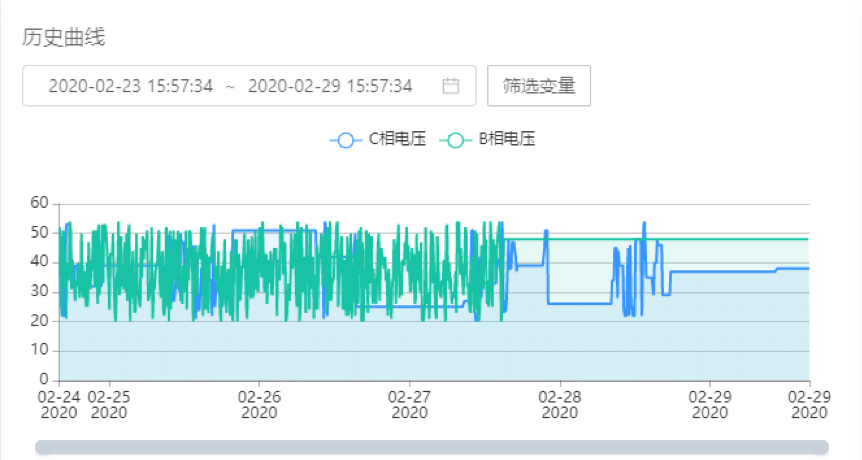
一个变量一张表,这样做的优势是非常明显的。每张表里面只存一个变量的数据即使每秒写入一次,1个月也只有260万条,对其作指定时间范围的查询,不用考虑其他变量的数据,直接从时间戳索引得到想要时间范围的数据,效率很高。云组态的需求正是短时间内有很多变量按秒存储,保存半年左右,并且在此情况下,用户想查询任意一个变量的历史情况都能够快速得到响应。比如一开始截图中展示的电压变化曲线就是一个很好的例子,这在之前的解决方案中是没有实现的。由于有超级表,变量名映射出来的表名也无需特意维护,只需从超级表中查询时,通过标签列对所感兴趣的变量进行筛选过滤即可。
总结
繁易云组态采用了TDengine后,节省了其他方案搭建集群的费用,并且在写入速度和查询性能方面完全满足了业务的需求,运维也是相当简单,没有像HBase之类相当多的调优参数,cpu内存相当稳定。对比市面上其他开源方案,我们认为TDengine虽然开源不到一年,但是在同类产品中名列前茅。希望在今后还能看到RESTful接口写入速度进一步提高,文档进一步丰富。
作者介绍
公司介绍
 点击阅读原文,体验TDengine!
点击阅读原文,体验TDengine!
