





大家好,今天和大家聊聊去O的迁移工具ORA2PG。
这个工具在国外是十分流行的,像AWS这样的大公司在去O的项目中就广泛的用到了ORA2PG这个工具。
这个工具是功能十分强大和丰富的,个人所在的公司主要用ORA2PG 功能点如下:
1)为开发组提供建表语句的DDL的自动转换
2)DBA迁移数据工具
3)数据迁移后,异构数据库之间数据质量的比对(个人觉得这个功能是免费工具中的亮点)
官方网址: https://ora2pg.darold.net/ 目前最新的版本是 v24
Github 项目的地址: https://github.com/darold/ora2pg
这个项目是的代码主要是 Perl 开发的,所以在安装之前需要安装perl 以及数据库访问模块的各种RPM包:
* Perl (version 5.10 or above)
* Perl DBI (standard database interface module for Perl)
* Oracle instanct client (required by Perl DBD::Oracle module)
* Perl DBD::Oracle module (access Oracle database to export DDL/data)
* Postgres client (psql) when load DDL/dump data file into Postgres database
* Perl Pg::Oracle module (export data from Oracle to Postgres on the fly)
安装ORA2PG 之前的检查:
检查 Perl 5.10 版本以上
INFRA [root@ljzdccapp006 postgres]# perl -v
This is perl 5, version 16, subversion 3 (v5.16.3) built for x86_64-linux-thread-multi
(with 44 registered patches, see perl -V for more detail)
检查 Perl-Devel 模块
INFRA [root@ljzdccapp006 postgres]# rpm -qa |grep perl-devel
perl-devel-5.16.3-299.el7_9.x86_64
INFRA [root@ljzdccapp006 postgres]# rpm -qa |grep perl-DBI
perl-DBIx-Simple-1.35-7.el7.noarch
perl-DBI-1.627-4.el7.x86_64
如果不存在,安装如下:
# yum install perl-devel
# yum install perl-DBI
安装oracle的 instant client: 这些RPM可以从 ORACLE的官网下载到 https://www.oracle.com/au/database/technologies/instant-client/linux-x86-64-downloads.html
yum -y localinstall \ oracle-instantclient19.3-sqlplus-19.3.0.0.0-1.x86_64.rpm \ oracle-instantclient19.3-basic-19.3.0.0.0-1.x86_64.rpm \ oracle-instantclient19.3-devel-19.3.0.0.0-1.x86_64.rpm \ oracle-instantclient19.3-jdbc-19.3.0.0.0-1.x86_64.rpm
配置ORACLE的环境变量: 追加到 /home/postgres/.bash_profile中
export LD_LIBRARY_PATH=/usr/lib/oracle/19.3/client64/lib export ORACLE_HOME=/usr/lib/oracle/19.3/client64 export PATH=$PATH:$ORACLE_HOME/bin
安装 perl 模块: DBD::Oracle
tar -xvf DBD-Oracle-1.76.tar.gz
cd DBD-Oracle-1.76
export LD_LIBRARY_PATH=/usr/lib/oracle/19.3/client64/lib
export ORACLE_HOME=/usr/lib/oracle/19.3/client64
export PATH=$PATH:$ORACLE_HOME/bin
perl Makefile.PL
make
make install
安装 perl 模块: DBD::Pg
yum install "perl(DBD::Pg)"
下载安装ORA2PG:
git clone https://github.com/darold/ora2pg.git
安装:
cd ora2pg-24.0
perl Makefile.PL
make
make install
验证安装版本:
ora2pg -v Ora2Pg v24.0
去O项目的整体流程:

第一步,模拟找一个ORACLE上的schema, 模拟一下迁移评估的项目 cost 难度。
新建一个数据的迁移项目的目录:我们可以看到新建了很多数据库对象相关的子目录
mkdir -p /data/project/payment
INFRA [postgres@ljzdccapp006 data]# ora2pg --project_base /data/project/payment --init_project payment
Creating project payment.
/data/project/payment/payment/
schema/
dblinks/
directories/
functions/
grants/
mviews/
packages/
partitions/
procedures/
sequences/
sequence_values/
synonyms/
tables/
tablespaces/
triggers/
types/
views/
sources/
functions/
mviews/
packages/
partitions/
procedures/
triggers/
types/
views/
data/
config/
reports/
Generating generic configuration file
Creating script export_schema.sh to automate all exports.
Creating script import_all.sh to automate all imports.
我们修改 config/ora2pg.conf 文件:
# Set the Oracle home directory
ORACLE_HOME /usr/lib/oracle/19.3/client64
# Set Oracle database connection (datasource, user, password)
ORACLE_DSN dbi:Oracle:host=xx.xx.xx.xx;port=1521;service_name=<service name>
ORACLE_USER <oracle user>
ORACLE_PWD <oracle user password>
SCHEMA APP_ORA2PG
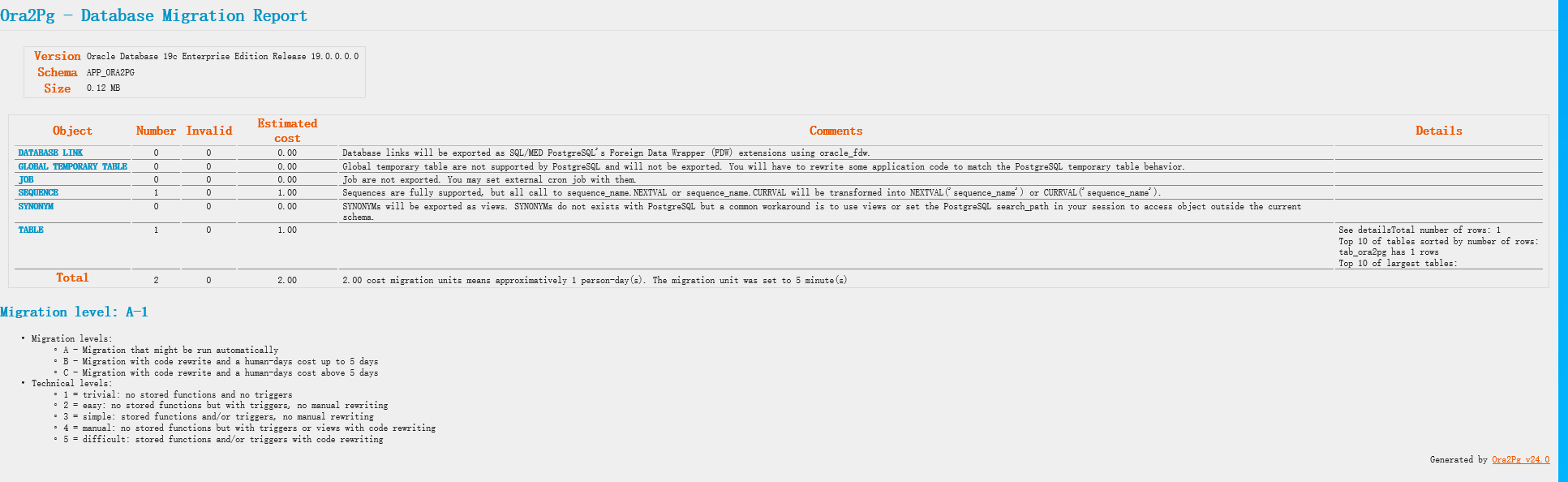
APP_ORA2PG 是我们一个需要迁移的项目所在ORACLE的schema , 我们执行命令 --estimate_cost 来生成一个HTML 版本的数据库改造成本分析
INFRA [postgres@ljzdccapp006 config]# ora2pg -t show_report --estimate_cost -c ./ora2pg.conf --dump_as_html > app_ora2pg.html
[========================>] 1/1 tables (100.0%) end of scanning.
[========================>] 6/6 objects types (100.0%) end of objects auditing.
我们在ORACLE中的schema: APP_ORA2PG , 只有一个表和一个序列, 所以给出的评估改造难度是 A-1级别的(入门级别的)
我们接下来,用ORA2PG生成表的DDL语句:
INFRA [postgres@ljzdccapp006 payment]# ora2pg -p -t TABLE -o table.sql -b ./schema/tables -c ./config/ora2pg.conf
[========================>] 1/1 tables (100.0%) end of scanning.
[========================>] 1/1 tables (100.0%) end of table export.
我们看到索引,表,约束 分别在单独的DDL的文件中:
INFRA [postgres@ljzdccapp006 tables]# ls -lhtr
total 12K
-rw------- 1 postgres postgres 401 Aug 9 15:56 table.sql
-rw------- 1 postgres postgres 315 Aug 9 15:56 INDEXES_table.sql
-rw------- 1 postgres postgres 327 Aug 9 15:56 CONSTRAINTS_table.sql
我们查看一下 table.sql , ORA2PG 在转换ORACLE number 类型的时候,喜欢把number(n) (n>19) 转换成 numeric(n) 类型
如果可以确实是主键这种数字类型,需要手动修改为bigint 类型
SET client_encoding TO 'UTF8';
\set ON_ERROR_STOP ON
CREATE TABLE tab_ora2pg (
id numeric(20) NOT NULL,
name varchar(100),
cdate timestamp(0),
edate timestamp(0)
) ;
我们来生成一下序列的DDL:
INFRA [postgres@ljzdccapp006 payment]# ora2pg -p -t SEQUENCE -o sequences.sql -b ./schema/sequences -c ./config/ora2pg.conf
[========================>] 1/1 sequences (100.0%) end of output
我们来看一下 sequences.sql 这个文件:
这里我们需要注意下 cache 这个值, 在ORACLE里默认是20, PG的sequence cache 是 session 级别的, 会出现跳号增长的情况, 建议修改成1
CREATE SEQUENCE seq_ora2pg INCREMENT 1 MINVALUE 1 NO MAXVALUE START 1 CACHE 20;
我们连接到目标数据库PG中执行ORA2PG为我们生成的语句:
cappcore=# create user app_ora2pg password '12345678';
CREATE ROLE
cappcore=# create schema app_ora2pg authorization app_ora2pg;
CREATE SCHEMA
cappcore=# \c cappcore app_ora2pg
You are now connected to database "cappcore" as user "app_ora2pg".
cappcore=> CREATE TABLE tab_ora2pg (
cappcore(> id BIGINT NOT NULL,
cappcore(> name varchar(100),
cappcore(> cdate timestamp(0),
cappcore(> edate timestamp(0)
cappcore(> ) ;
CREATE TABLE
cappcore=> CREATE SEQUENCE seq_ora2pg INCREMENT 1 MINVALUE 1 NO MAXVALUE START 1 CACHE 1;
CREATE SEQUENCE
我们配置ORA2PG.conf 中 目标端PG数据库的DSN信息:
PG_DSN dbi:Pg:dbname=cappcore;host=localhost;port=6001 PG_USER APP_ORA2PG PG_PWD 12345678
数据迁移:
INFRA [postgres@ljzdccapp006 payment]# ora2pg -t COPY -c config/ora2pg.conf
[========================>] 1/1 tables (100.0%) end of scanning.
[========================>] 1/1 rows (100.0%) Table TAB_ORA2PG (1 recs/sec)
[========================>] 1/1 total rows (100.0%) - (0 sec., avg: 1 recs/sec).
[========================>] 1/1 rows (100.0%) on total estimated data (1 sec., avg: 1 recs/sec)
我们来验证一下数据数量和数据质量:
数据数量比对
INFRA [postgres@ljzdccapp006 payment]# ora2pg -t test_count -c config/ora2pg.conf
[TEST ROWS COUNT]
ORACLEDB:TAB_ORA2PG:1
POSTGRES:tab_ora2pg:1
[ERRORS ROWS COUNT]
OK, Oracle and PostgreSQL have the same number of rows.
数据质量对比 (原表和目标表 必须要有主键或者unique key才行,否则不会进行比对)
cappcore=> alter table tab_ora2pg add constraint pk_id primary key (id);
ALTER TABLE
ora2pg -t test_data -c config/ora2pg.conf --debug
验证的结果会写到文件data_validation.log 中:
INFRA [postgres@ljzdccapp006 payment]# tail -f data_validation.log
[DATA VALIDATION]
Data validation for table TAB_ORA2PG: OK
我们尝试,修改一下目标端的数据,进行2次数据质量比对:
cappcore=> update tab_ora2pg set name = 'invalid value';
UPDATE 1
再次验证查看结果: 可以看到差异的比较结果
INFRA [postgres@ljzdccapp006 payment]# tail -f data_validation.log
[DATA VALIDATION]
Data validation for table TAB_ORA2PG: 1 FAIL
-----------------------------------------------------------------
ORACLEDB:TAB_ORA2PG:1:[1|ora2pg|2023-08-09 15:33:57|2023-08-09 15:33:57]
POSTGRES:TAB_ORA2PG:1:[1|invalid value|2023-08-09 15:33:57|2023-08-09 15:33:57]
-----------------------------------------------------------------
最后我们看看数据增量导入:
我们需要在 ora2pg 的config 文件中 配置一下 参数REPLACE_QUERY 和 TRUNCATE_TABLE
REPLACE_QUERY TAB_ORA2PG[select * from TAB_ORA2PG where edate> sysdate]
TRUNCATE_TABLE 0 ; 表示不truncate table
我们在源端插入数据后,测试一下增量同步:
SYS@CN00C1CU> insert into TAB_ORA2PG select 2,'ora2pg',current_date, sysdate +1 from dual;
1 row created.
SYS@CN00C1CU> commit;
INFRA [postgres@ljzdccapp006 payment]# ora2pg -t COPY -c config/ora2pg.conf
[========================>] 1/1 tables (100.0%) end of scanning.
[> ] 0/1 rows (0.0%) Table TAB_ORA2PG (0 recs/sec)
[> ] 0/1 total rows (0.0%) - (0 sec., avg: 0 recs/sec).
[========================>] 1/1 rows (100.0%) on total estimated data (1 sec., avg: 1 recs/sec)
查看导入结果
cappcore=> select * from tab_ora2pg;
id | name | cdate | edate
----+---------------+---------------------+---------------------
1 | invalid value | 2023-08-09 15:33:57 | 2023-08-09 15:33:57
2 | ora2pg | 2023-08-09 17:19:24 | 2023-08-10 17:19:24
(2 rows)
最后给大家介绍一个ORA2PG的 docker 镜像版:
这个版本会有2个好处: 1.快速部署 2.提供了图形界面版本,开发小伙伴可以通过网页的形式来自助评估项目,生成评估报告,建表语句DDL等
Dockhub 镜像链接: https://hub.docker.com/r/visulate/visulate-ora2pg
拉取镜像:
INFRA [root@wqdcsrv3067 ~]# docker pull visulate/visulate-ora2pg
Using default tag: latest
latest: Pulling from visulate/visulate-ora2pg
Digest: sha256:de40675e2dbda30e18f705c503b222c73c876652b1f41941a6a843da41c1de12
Status: Downloaded newer image for visulate/visulate-ora2pg:latest
docker.io/visulate/visulate-ora2pg:latest
启动镜像:
INFRA [root@wqdcsrv3067 data]# mkdir -p /data/ora2pg-projects
INFRA [root@wqdcsrv3067 data]# docker run -d -p 3000:3000 -v /data/ora2pg-projects:/project visulate/visulate-ora2pg:latest
aeaf504e3e2e5d628c85f9802836669c72593a553961c1c9f9d7ad2a1947ed29
INFRA [root@wqdcsrv3067 data]# docker ps | grep ora2pg
aeaf504e3e2e visulate/visulate-ora2pg:latest "entrypoint.sh /bin/…" 27 seconds ago Up 26 seconds 0.0.0.0:3000->3000/tcp busy_rosalind
访问地址: http://xx.xxx.xx.xxx:3000/ (xx.xxx.xx.xxx 你机器的IP)
创建project :
配置源端数据库信息:

点击保存:
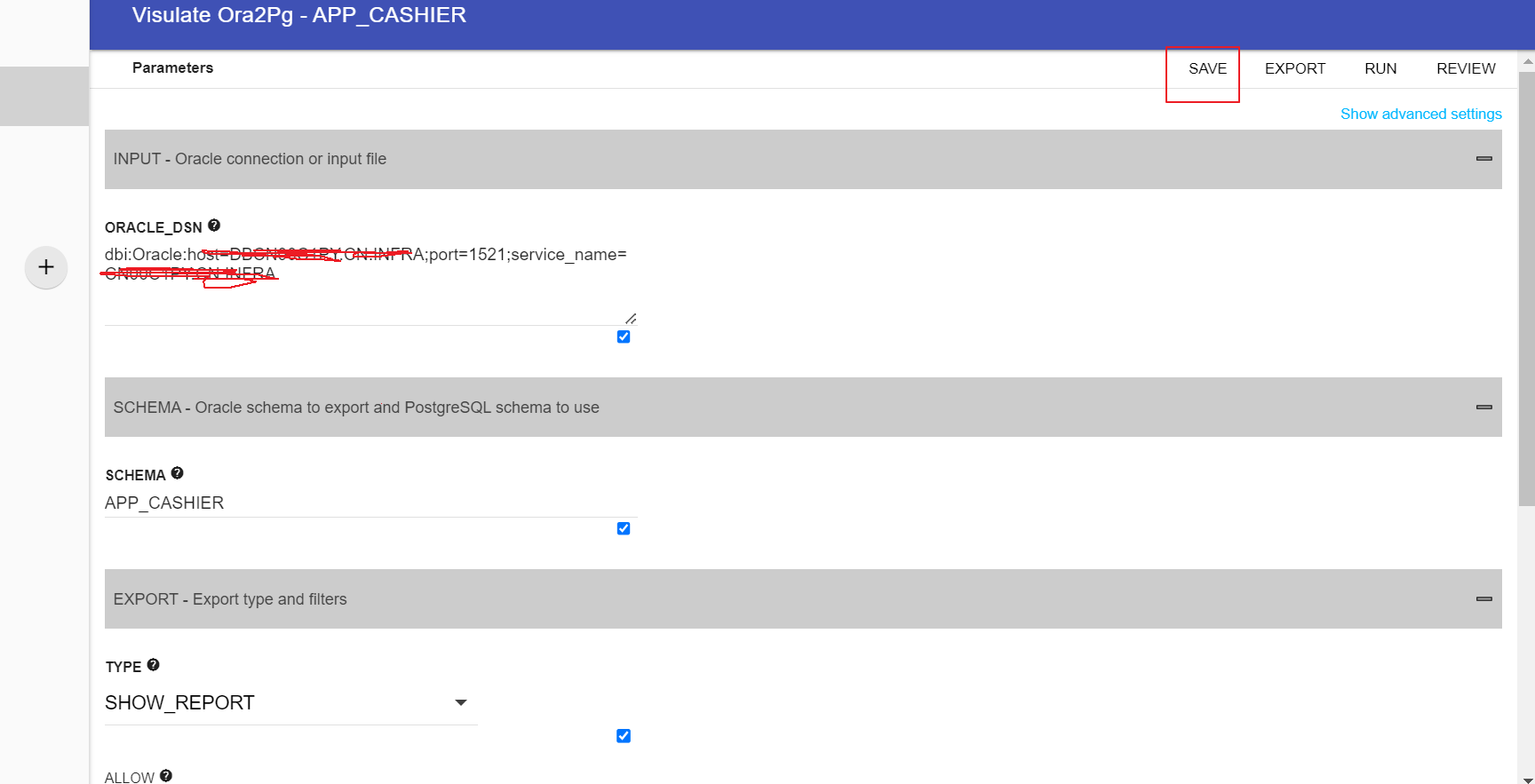
尝试跑一个迁移评估的report:
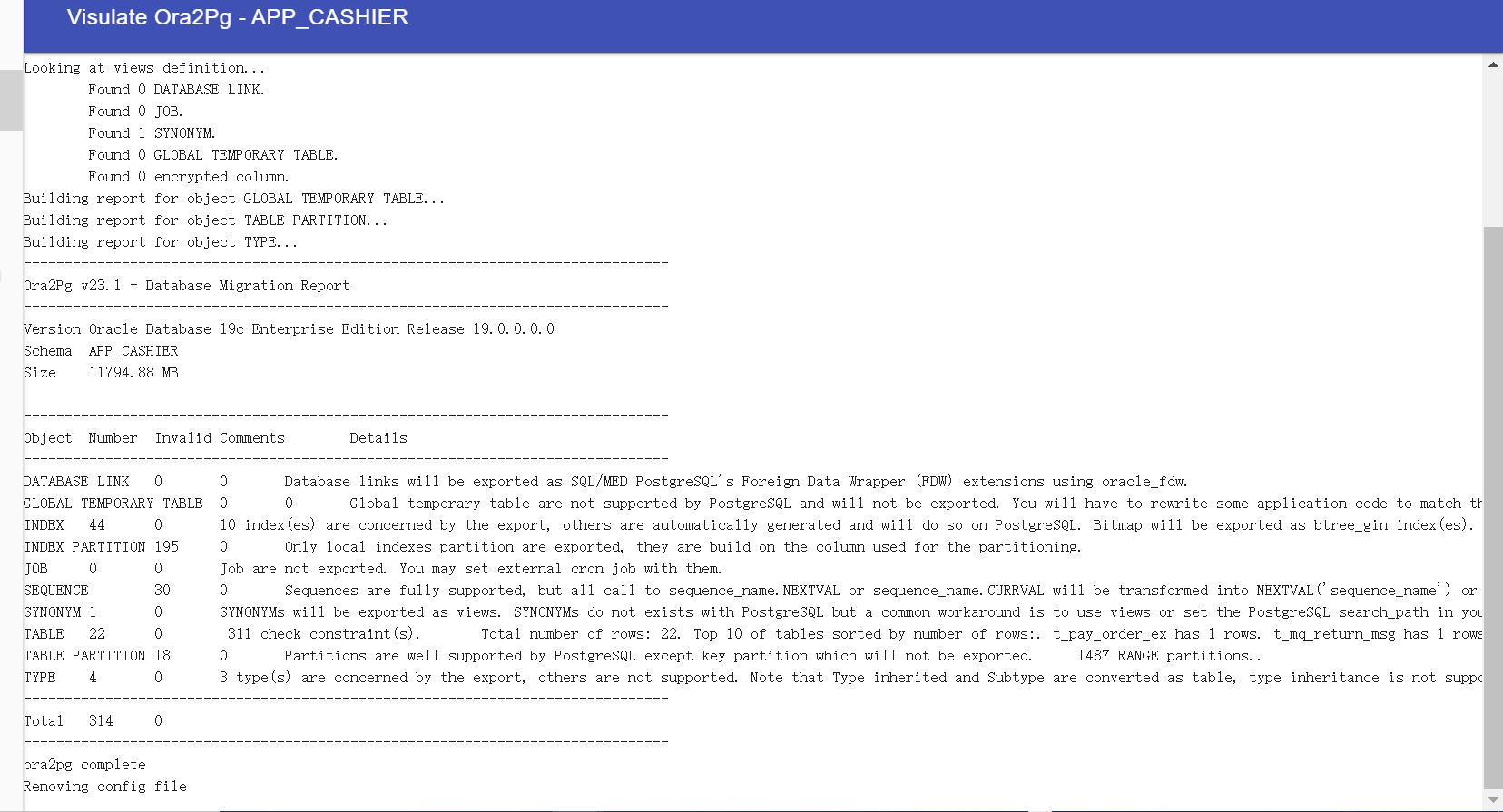
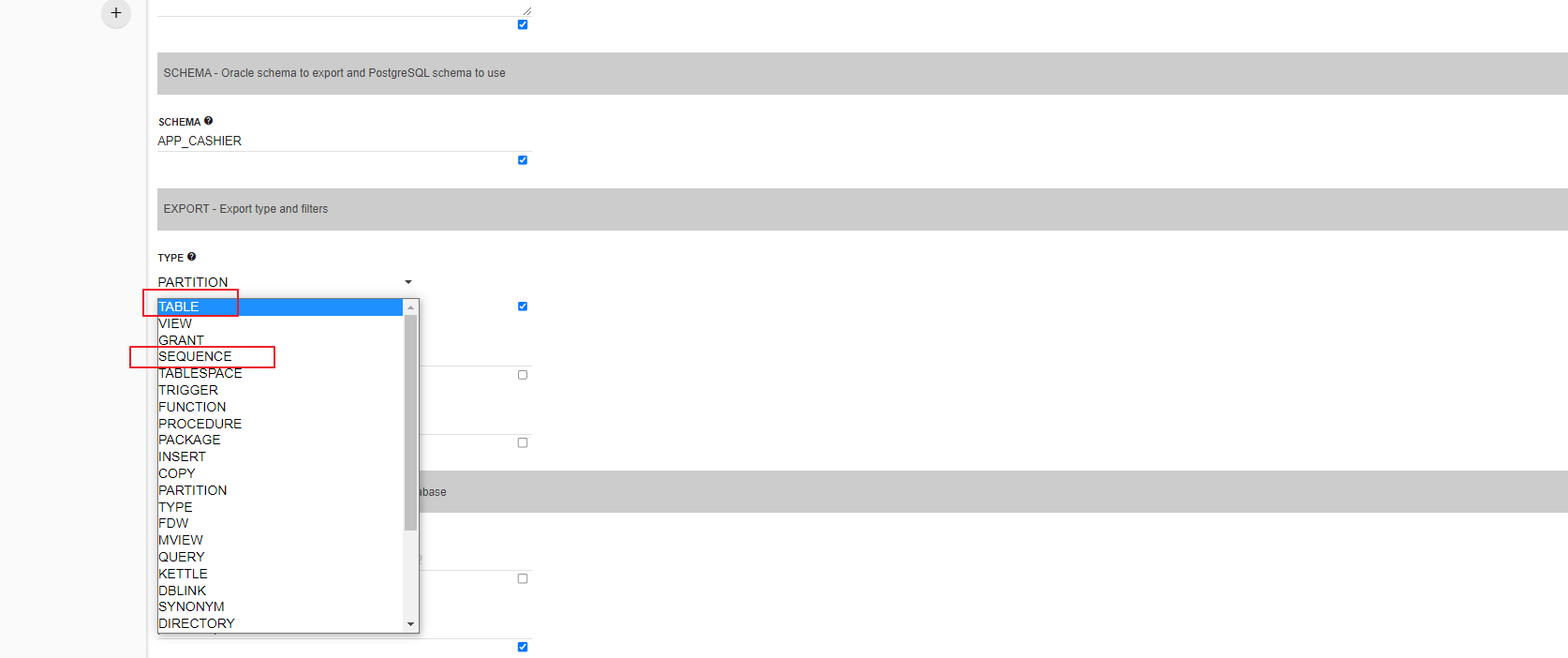
TABLE & INDEX & PARTTION & SEQUENCE 的导出
对于这些常见的ORACLE数据库中的对象,可以从网页上直接导出SQL文件:
在下拉列表中选择 需要转换的对象类型:
点击Run 进行SQL文件的生成:点击 Run
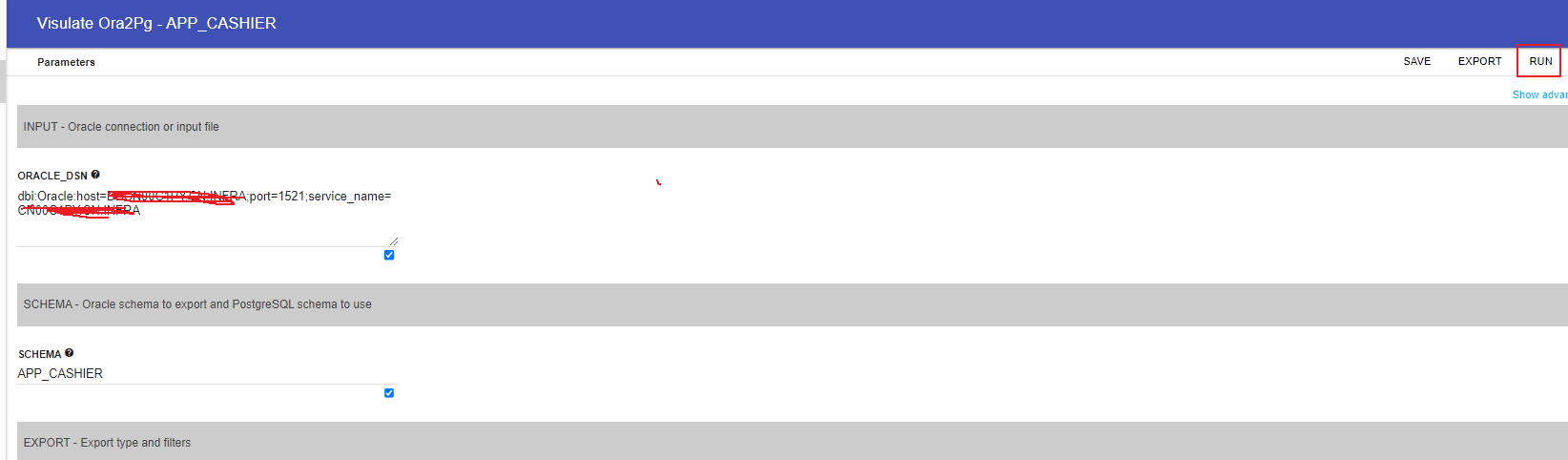
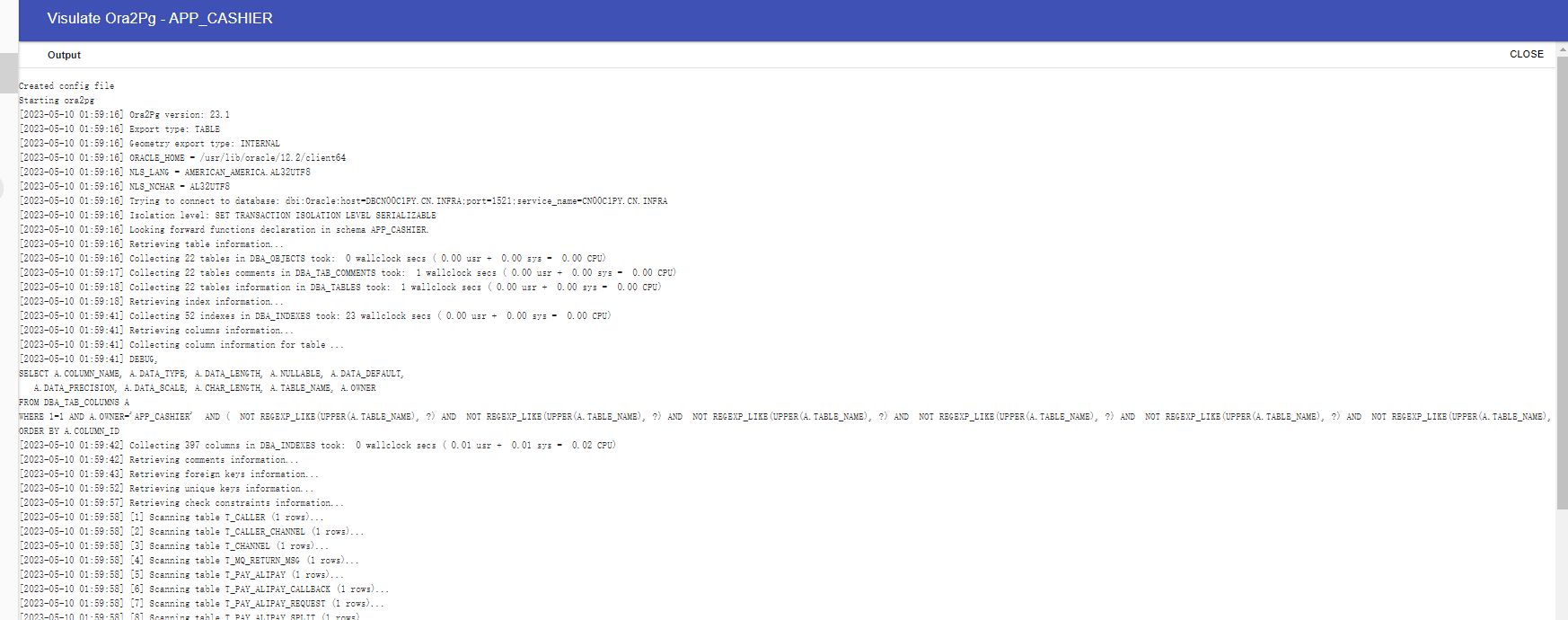
下载并查看生成的文件: 点击 review
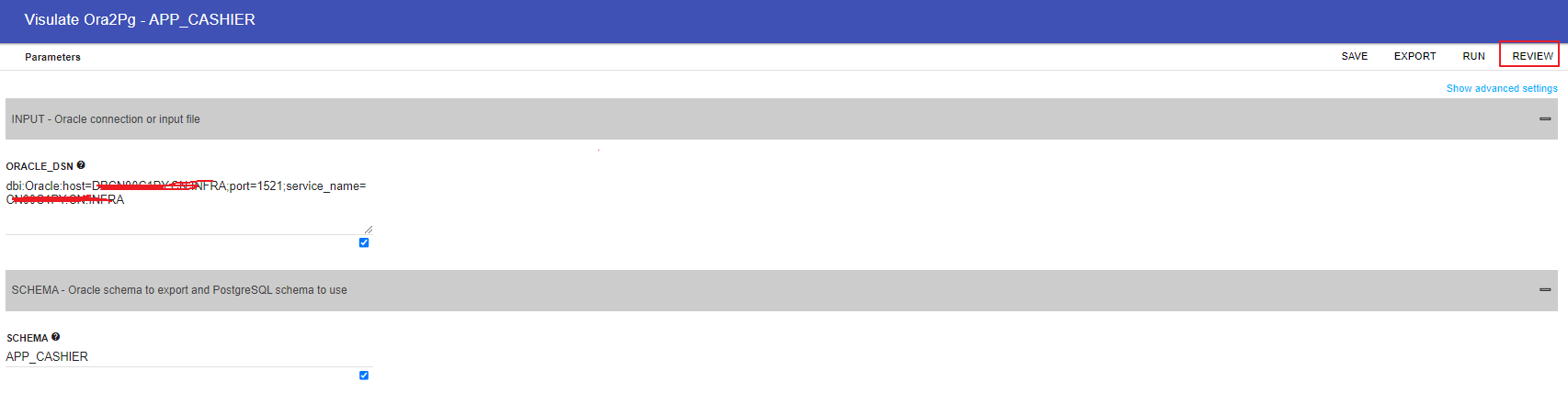
点击压缩包或者文件下载:

Have a fun 😃 !
