




在投研阶段,研究员通常需要通过历史数据批量计算生成因子,一般做法是将每一种因子的计算都封装成自定义函数。但因子类型多种多样,每一名研究员的编程习惯也不尽相同。
选择合适的方式计算各种金融因子,能降低编写复杂度,提高投研效率,同时还能为后续的流批一体交易、团队因子代码提交和管理,以及搭建统一运行的因子计算作业框架,起到至关重要的作用。
面板模式:自定义函数的参数一般为向量,矩阵或表,输出一般为向量,矩阵或表。
SQL 模式:自定义函数的参数一般为向量(列),输出一般为向量。
面板模式
更接近数学公式的直观表达
面板数据
panel data
Alpha#1 因子计算(面板模式)
@statedef alpha1TS(close){return mimax(pow(iif(ratios(close) - 1 < 0, mstd(ratios(close) - 1, 20),close), 2.0), 5)}def alpha1Panel(close){return rowRank(X=alpha1TS(close), percent=true) - 0.5 //rowRank:在每一个时间截面对标的排名}raw_data_alpha1 = select * from loadTable("dfs://k_minute_level","k_minute") where date(tradetime) between 2020.02.01 : 2020.02.28input_panel_alpha1 = exec close from raw_data_alpha1 pivot by tradetime, securityidalpha1_panel_res = alpha1Panel(input_panel_alpha1)
在这段代码中,exec
搭配pivot by
得到了矩阵input_panel_alpha1
,作为函数的入参。
DolphinDB 内置的 rowRank 函数可以在面板数据中的每一个时间截面对各标的进行排名;iif 条件运算可以在标的向量层面直接筛选及计算;mimax 及 mstd 等滑动窗口函数也是在标的层面垂直计算的。
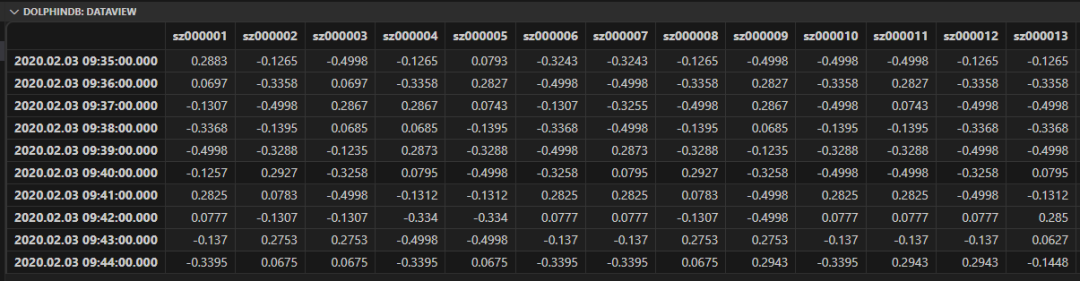
Alpha#98 因子计算(面板模式)
def prepareDataForDDBPanel(raw_data, start_time, end_time){t = select tradetime,securityid, vwap,vol,open from raw_data where date(tradetime) between start_time : end_timereturn dict(`vwap`open`vol, panel(t.tradetime, t.securityid, [t.vwap, t.open, t.vol]))}@statedef alpha98Panel(vwap, open, vol){return rowRank(X=mavg(mcorr(vwap, msum(mavg(vol, 5), 26), 5), 1..7),percent=true) - rowRank(X=mavg(mrank(9 - mimin(mcorr(rowRank(X=open,percent=true), rowRank(X=mavg(vol, 15),percent=true), 21), 9), true, 7), 1..8),percent=true)}raw_data_alpha98 = loadTable("dfs://k_minute_level","k_minute")start_time = 2020.02.01end_time = 2020.02.28input_panel_alpha98 = prepareDataForDDBPanel(raw_data_alpha98, start_time, end_time)alpha98DDBPanel = alpha98Panel(input_panel_alpha98.vwap, input_panel_alpha98.open, input_panel_alpha98.vol)
Alpha#98 因子同时使用了三个面板数据,分别是 vwap, open 和 vol。
各矩阵内部运用了 rowRank 函数进行横向截面运算,以及 m 系列函数进行垂直滑动窗口计算,各矩阵之间也进行了二元运算。最后仅用一行代码就解决了多维度的复杂的嵌套计算逻辑。
我们知道,基于面板数据的因子计算,耗时主要在面板数据准备和因子计算两个阶段。
对于日频等低频数据,我们推荐大家使用面板模式,结合 DolphinDB 的一系列优化函数,实现既直观、又高效的因子计算。
其实,面板模式在 Python、Matlab 等一些专门用于数据分析的工具中也都可以实现,但其计算过程主要基于内存运算。也就是说,随着数据频率上升,数据量增加,面板模式对分钟频、快照、逐笔等中高频数据的处理会变得吃力——为此,掌握 DolphinDB 的 SQL 写法就非常重要。
SQL
先来聊聊 SQL
DolphinDB 对 SQL 的支持,搭配上分布式系统,体现出了以下优势:

易用性
高效查询
横向扩展
容错性
对于分钟频、快照、逐笔等中高频数据,我们推荐大家使用 SQL 模式,结合 DolphinDB 的分区存储方案,高效实现库内并行计算。
SQL模式
高频因子分布式并行计算
def sum_diff(x, y){return (x-y)/(x+y)}ema(1000 * sum_diff(ema(price, 20), ema(price, 40)),10) - ema(1000 * sum_diff(ema(price, 20), ema(price, 40)), 20)
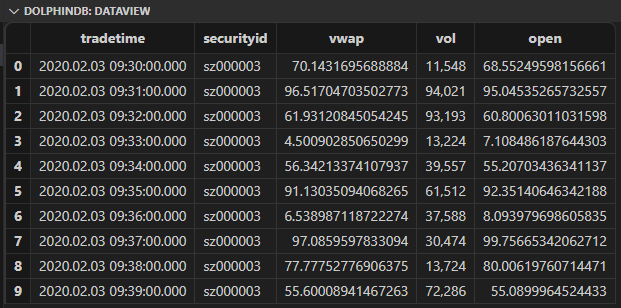
模拟原始数据长下面这样:
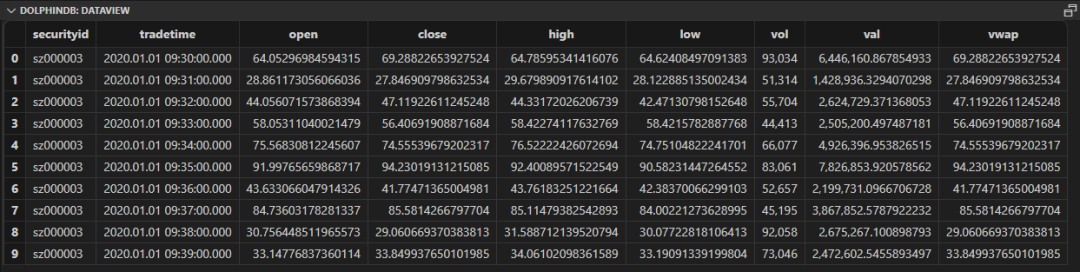
我们可以直接在 SQL 中通过 context by 子句按股票代码分组,然后在 select 中调用 factorDoubleEMA 因子计算函数,来计算每个股票在一段时间里的因子值。
@statedef factorDoubleEMA(price){ema_2 = ema(price, 2) //ema:在给定长度(以元素个数衡量)的滑动窗口内,计算 X 的指数移动平均(Exponential Moving Average)。ema_4 = ema(price, 4)sum_diff_1000 = 1000 * sum_diff(ema_2, ema_4)return ema(sum_diff_1000, 2) - ema(sum_diff_1000, 3)}res = select tradetime, securityid, `doubleEMA as factorname, factorDoubleEMA(close) as val from loadTable("dfs://k_minute_level","k_minute") where date(tradetime) between 2020.02.01 : 2020.02.28 context by securityid
值得注意的是,context by 是 DolphinDB SQL 对 group by 的扩展,是 DolphinDB 特有的 SQL 语句。group by 只适用于聚合计算,也就是说输入长度为n,输出长度是1。context by 适用于向量计算,输入长度是n,输出长度也是n。
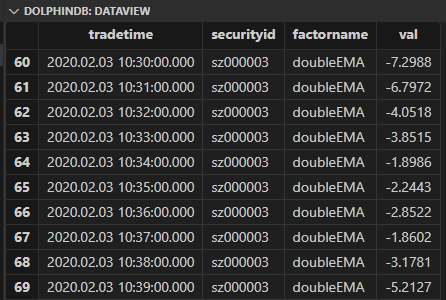
factorDoubleEMA 因子输出结果
复杂因子
更复杂的因子怎么办?
以 Alpha#1 因子的计算逻辑为例:
Step 1
Step 2
Step 3
同样基于前面的模拟原始数据,要计算4000只股票2020年2月份的分钟频 Alpha#1因子值,我们先用 select 语句生成如下数据表:
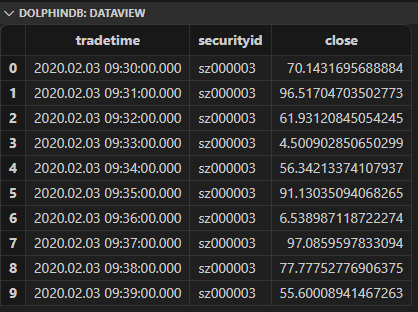
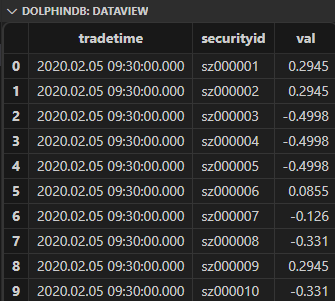
def alpha1SQL(t){res = select tradetime, securityid, mimax(pow(iif(ratios(close) - 1 < 0, mstd(ratios(close) - 1, 20), close), 2.0), 5) as val from t context by securityidreturn select tradetime, securityid, rank(val, percent=true) - 0.5 as val from res context by tradetime}input_alpha1 = select tradetime,securityid,close from loadTable("dfs://k_minute_level","k_minute") where date(tradetime) between 2020.02.01 : 2020.02.28select top 10 * from input_alpha1alpha1DDBSql = alpha1SQL(input_alpha1)
这样就能轻松得到需要的因子值,返回结果也是一个表:
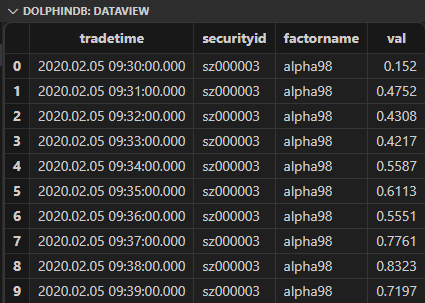
以 Alpha#98 因子的计算逻辑为例:
def alpha98SQL(mutable t){ //mutable:可变参数在函数体中可以被修改update t set adv5 = mavg(vol, 5), adv15 = mavg(vol, 15) context by securityidupdate t set rank_open = rank(X = open,percent=true), rank_adv15 =rank(X=adv15,percent=true) context by date(tradetime)update t set decay7 = mavg(mcorr(vwap, msum(adv5, 26), 5), 1..7), decay8 = mavg(mrank(9 - mimin(mcorr(rank_open, rank_adv15, 21), 9), true, 7), 1..8) context by securityidreturn select tradetime,securityid, `alpha98 as factorname, rank(X =decay7,percent=true)-rank(X =decay8,percent=true) as val from t context by date(tradetime)}input_alpha98 = select tradetime,securityid, vwap,vol,open from loadTable("dfs://k_minute_level","k_minute") where date(tradetime) between 2020.02.01 : 2020.02.28alpha98DDBSql = alpha98SQL(input_alpha98)
可以看到,面板模式与 SQL 模式为大家面对不同的计算场景提供了选择空间。学会灵活运用多种范式的编程,充分利用 DolphinDB 矩阵计算的高效能,结合强大的分布式并行计算框架,将能更轻松地面对各类金融复杂因子计算,开发不同风格的因子。
总结一下——对于日频等低频数据,我们推荐大家使用面板模式,结合 DolphinDB 的一系列优化函数,实现既直观、又高效的因子计算。对于分钟频、快照、逐笔等中高频数据,我们推荐大家使用 SQL 模式,结合 DolphinDB 的分区存储方案,高效实现库内并行计算。
未完待续

