Pandas中的窗口函数,包括移动窗口函数rolling,扩展窗口函数expanding,指数加权移动窗口函数ewm。
rolling:指定移动窗口的大小,每个窗口都是指定的固定大小。对于时间序列的索引,则可以传入特定的时间字符串,每个窗口是指定时间范围(详细可见前面时间序列方面的文章)。
每个窗口的范围从当前位置向前移动窗口大小的位置开始到当前位置。
示例:
df = pd.DataFrame({'B': [0, 1, 2, np.nan, 4]})dfB0 0.01 1.02 2.03 NaN4 4.0
不足指定窗口大小的窗口最终值为NaN:
df.rolling(2).sum()B0 NaN1 1.02 3.03 NaN4 NaN
对于索引0,3,4三个窗口内窗口大小仅为1,小于设定的窗口2,所以为NaN。
但可以通过min_periods定义每个窗口的最小大小,窗口大小大于min_periods的都可以:
df.rolling(2, min_periods=1).sum()B0 0.01 1.02 3.03 2.04 4.0
对于时间序列,可以传入特定格式的字符串作为窗口大小:
df = pd.DataFrame({'B': [0, 1, 2, np.nan, 4]},index = [pd.Timestamp('20130101 09:00:00'),pd.Timestamp('20130101 09:00:02'),pd.Timestamp('20130101 09:00:03'),pd.Timestamp('20130101 09:00:05'),pd.Timestamp('20130101 09:00:06')])dfB2013-01-01 09:00:00 0.02013-01-01 09:00:02 1.02013-01-01 09:00:03 2.02013-01-01 09:00:05 NaN2013-01-01 09:00:06 4.0df.rolling('2s').sum()B2013-01-01 09:00:00 0.02013-01-01 09:00:02 1.02013-01-01 09:00:03 3.02013-01-01 09:00:05 NaN2013-01-01 09:00:06 4.0
expanding:每个窗口的范围都是从序列起始处开始到当前位置。可以指定min_periods参数,默认为1:
df = pd.DataFrame({'B': [0, 1, 2, np.nan, 4]})B0 0.01 1.02 2.03 NaN4 4.0df.expanding().sum()B0 0.01 1.02 3.03 3.04 7.0df.expanding(2).sum()B0 NaN1 1.02 3.03 3.04 7.0
ewm:参数较为复杂,具体请参考官方文档:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.ewm.html
https://pandas.pydata.org/pandas-docs/stable/user_guide/computation.html#exponentially-weighted-windows
文末对ewm有简单的演示。
现在通过一个股票金融数据演示窗口函数。

移动窗口函数rolling
首先加载一些时间序列数据,将其重采样为工作日频率:
In [234]: close_px_all = pd.read_csv('examples/stock_px_2.csv',.....: parse_dates=True, index_col=0)In [235]: close_px = close_px_all[['AAPL', 'MSFT', 'XOM']]In [236]: close_px = close_px.resample('B').ffill()In [237]: close_px.head(10)Out [237]:AAPL MSFT XOM2003-01-02 7.40 21.11 29.222003-01-03 7.45 21.14 29.242003-01-06 7.45 21.52 29.962003-01-07 7.43 21.93 28.952003-01-08 7.28 21.31 28.832003-01-09 7.34 21.93 29.442003-01-10 7.36 21.97 29.032003-01-13 7.32 22.16 28.912003-01-14 7.30 22.39 29.172003-01-15 7.22 22.11 28.77
rolling运算符类似于resample和groupby,可以在TimeSeries/DataFrame/window上调用它,下面通过rolling绘制苹果公司股价的250日均线图:
In [238]: close_px.AAPL.plot()Out[238]:<matplotlib.axes._subplots.AxesSubplot at 0x7f2f2570cf98>In [239]: close_px.AAPL.rolling(250).mean().plot()
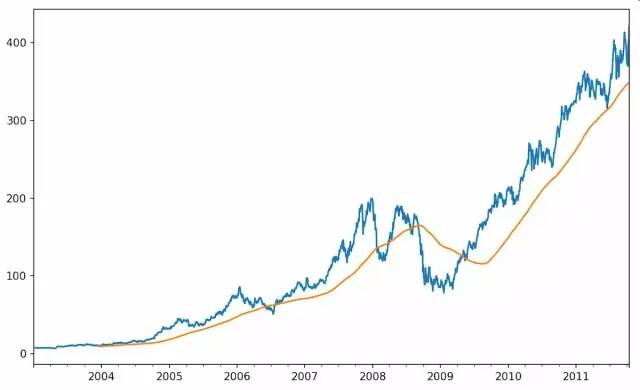
表达式rolling(250)创建一个按照250天分组的滑动窗口对象。
默认情况下,rolling函数在时间序列开始处不足窗口期的那些数据值为NA,传递min_periods可以保证高于指定期数的窗口不为NA:
In [241]: appl_std250 = close_px.AAPL.rolling(250, min_periods=10).std()In [242]: appl_std250[5:12]Out[242]:2003-01-09 NaN2003-01-10 NaN2003-01-13 NaN2003-01-14 NaN2003-01-15 0.0774962003-01-16 0.0747602003-01-17 0.112368Freq: B, Name: AAPL, dtype: float64
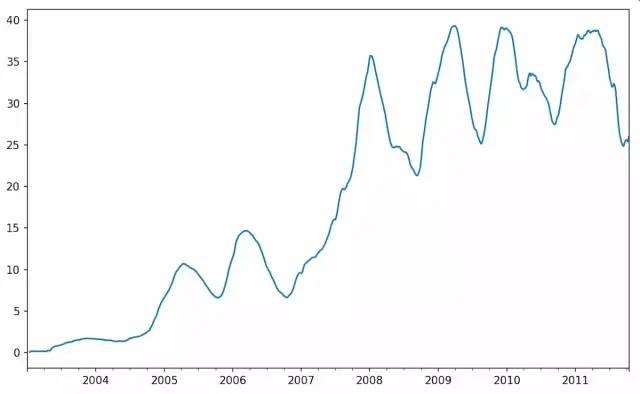
下面绘制了苹果公司250日每日回报标准差:
In [243]: appl_std250.plot()
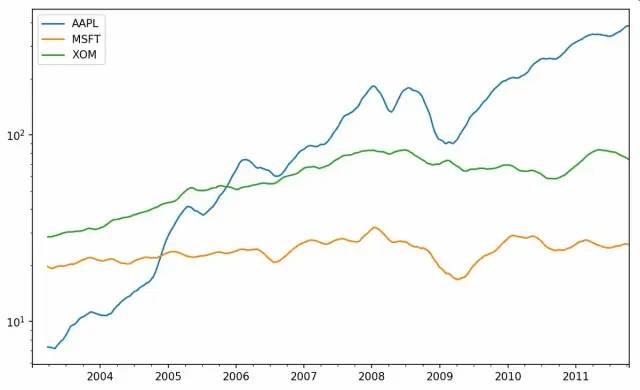
对DataFrame调用rolling_xxx会将转换应用到所有的列上,下面以对数Y轴绘制各股价60日均线:
In [246]: close_px.rolling(60).mean().plot(logy=True)
rolling函数也可以接受一个指定固定大小的时间字符串,可以很方便的处理不规律的时间序列。例如,计算20天的滚动均值:
In [247]: close_px.rolling('20D').mean()Out[247]:AAPL MSFT XOM2003-01-02 7.400000 21.110000 29.2200002003-01-03 7.425000 21.125000 29.2300002003-01-06 7.433333 21.256667 29.4733332003-01-07 7.432500 21.425000 29.3425002003-01-08 7.402000 21.402000 29.2400002003-01-09 7.391667 21.490000 29.2733332003-01-10 7.387143 21.558571 29.2385712003-01-13 7.378750 21.633750 29.1975002003-01-14 7.370000 21.717778 29.1944442003-01-15 7.355000 21.757000 29.152000... ... ... ...2011-10-03 398.002143 25.890714 72.4135712011-10-04 396.802143 25.807857 72.4271432011-10-05 395.751429 25.729286 72.4228572011-10-06 394.099286 25.673571 72.3757142011-10-07 392.479333 25.712000 72.4546672011-10-10 389.351429 25.602143 72.5278572011-10-11 388.505000 25.674286 72.8350002011-10-12 388.531429 25.810000 73.4007142011-10-13 388.826429 25.961429 73.9050002011-10-14 391.038000 26.048667 74.185333[2292 rows x 3 columns]
rolling二元移动窗口函数
有些统计运算(如相关系数和协方差)需要在两个时间序列上执行。例如,金融分析师常常对某只股票对某个参考指数(如标准普尔500指数)的相关系数感兴趣。
先计算准普尔500指数和感兴趣的股票的时间序列的百分数变化:
In [256]: spx_px = close_px_all['SPX']In [257]: spx_rets = spx_px.pct_change()In [258]: returns = close_px.pct_change()
调用rolling之后,corr聚合函数开始计算与spx_rets滚动相关系数,苹果股价 6个月的回报与标准普尔500指数的相关系数:
In [259]: corr = returns.AAPL.rolling(125, min_periods=100).corr(spx_rets)In [260]: corr.plot()
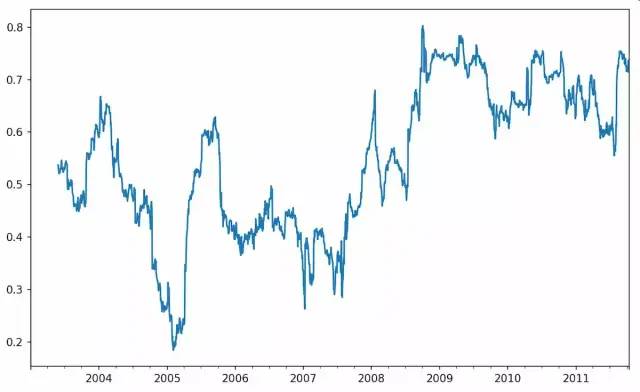
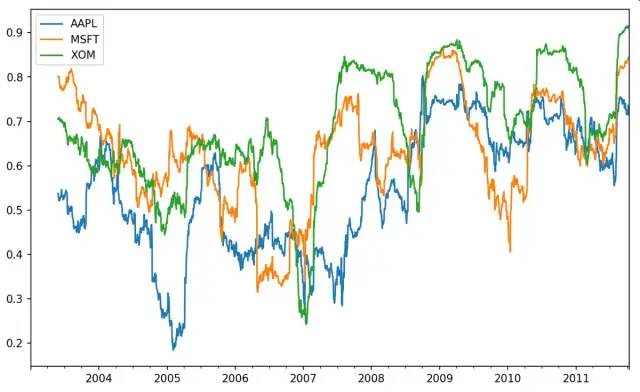
也可以一次性计算多只股票与标准普尔500指数的相关系数,rolling_corr会自动计算TimeSeries(spx_rets)与DataFrame各列的相关系数:
In [262]: corr = returns.rolling(125, min_periods=100).corr(spx_rets)In [263]: corr.plot()
3只股票6个月的回报与标准普尔500指数的相关系数:
rolling用户自定义的移动窗口函数
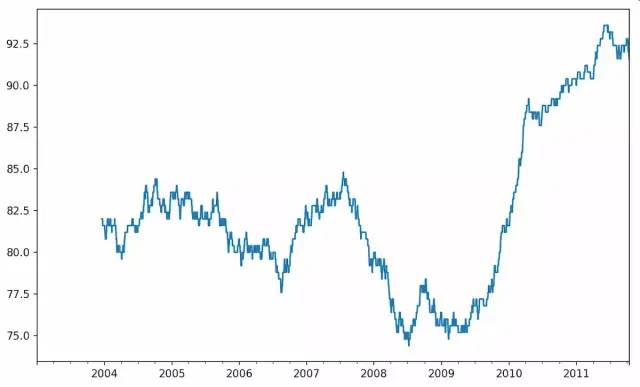
rolling_apply函数能够在移动窗口上应用自己编写的数组函数,只要该函数能从数组的各个片段中产生单个标量值即可。
下面计算250日窗口内,2%回报率的百分等级:
In [265]: from scipy.stats import percentileofscoreIn [266]: score_at_2percent = lambda x: percentileofscore(x, 0.02)In [267]: result = returns.AAPL.rolling(250).apply(score_at_2percent)In [268]: result.plot()
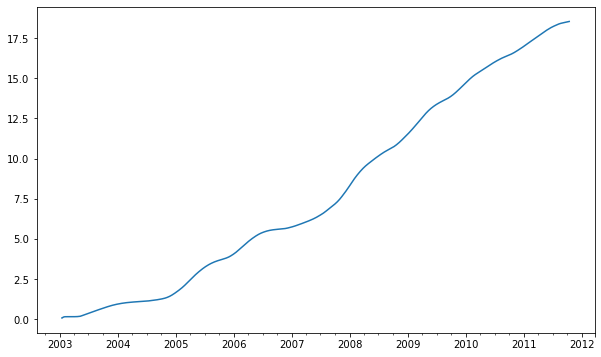
扩展窗口平均expanding
扩展窗口平均(expanding window mean),从时间序列的起始处开始窗口,增加窗口直到它达到当前的序列。apple_std250时间序列的扩展窗口平均如下所示:
In [244]: expanding_mean = appl_std250.expanding().mean()In [245]: expanding_mean.plot()
指数加权窗口函数ewm
指数加权窗口函数,定义了一个衰减因子(decay factor)常量,使近期的观测值拥有更大的权重。衰减因子的定义方式有很多,常见的是使用时间间隔(span),它可以使结果兼容于窗口大小等于时间间隔的简单移动窗口函数。
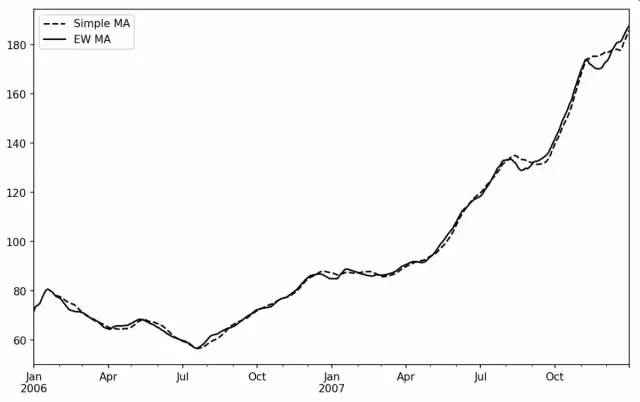
Pandas提供了ewm运算符计算指数加权窗口函数,下面的代码对比了苹果公司股价的30日移动平均和span=30的指数加权移动平均:
In [249]: aapl_px = close_px.AAPL['2006':'2007']In [250]: ma60 = aapl_px.rolling(30, min_periods=20).mean()In [251]: ewma60 = aapl_px.ewm(span=30).mean()In [252]: ma60.plot(style='k--', label='Simple MA')Out[252]: <matplotlib.axes._subplots.AxesSubplot at 0x7f2f252161d0>In [253]: ewma60.plot(style='k-', label='EW MA')Out[253]: <matplotlib.axes._subplots.AxesSubplot at 0x7f2f252161d0>In [254]: plt.legend()