




数据透视表是EXCEL常用的数据汇总工具,它根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中。在Python和pandas中,可以通过groupby功能以及利用层次化索引的重塑运算制作透视表。当然更方便的是使用pivot_table和crosstab方法。

pivot_table
DataFrame有一个pivot_table方法,还有一个顶级的pandas.pivot_table函数。除能为groupby提供便利之外,pivot_table还可以添加分项小计,也叫做margins。
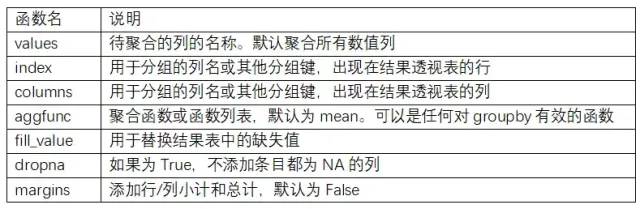
pivot_table的常见参数:
对于一个小费数据集,根据day和smoker计算分组平均数(pivot_table的默认聚合类型),并将day和smoker放到行上:
In [10] : tips = pd.read_csv('tips.csv')tips['tip_pct'] = tips['tip'] / tips['total_bill']In [11] : tips[:6]Out[11]:total_bill tip smoker day time size tip_pct0 16.99 1.01 No Sun Dinner 2 0.0594471 10.34 1.66 No Sun Dinner 3 0.1605422 21.01 3.50 No Sun Dinner 3 0.1665873 23.68 3.31 No Sun Dinner 2 0.1397804 24.59 3.61 No Sun Dinner 4 0.1468085 25.29 4.71 No Sun Dinner 4 0.186240In [12]: tips.pivot_table(index=['day', 'smoker'])Out[12]:size tip tip_pct total_billday smokerFri No 2.250000 2.812500 0.151650 18.420000Yes 2.066667 2.714000 0.174783 16.813333Sat No 2.555556 3.102889 0.158048 19.661778Yes 2.476190 2.875476 0.147906 21.276667Sun No 2.929825 3.167895 0.160113 20.506667Yes 2.578947 3.516842 0.187250 24.120000Thur No 2.488889 2.673778 0.160298 17.113111Yes 2.352941 3.030000 0.163863 19.190588
现在只聚合tip_pct和size,根据time进行分组,将smoker放到列上,把day放到行上:
In [131]: tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],.....: columns='smoker')Out[131]:size tip_pctsmoker No Yes No Yestime dayDinner Fri 2.000000 2.222222 0.139622 0.165347Sat 2.555556 2.476190 0.158048 0.147906Sun 2.929825 2.578947 0.160113 0.187250Thur 2.000000 NaN 0.159744 NaNLunch Fri 3.000000 1.833333 0.187735 0.188937Thur 2.500000 2.352941 0.160311 0.163863
传入margins=True可添加标签为All的行和列,其值对应于单个等级中所有数据的分组统计:
In [132]: tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],.....: columns='smoker', margins=True)Out[132]:size tip_pctsmoker No Yes All No Yes Alltime dayDinner Fri 2.000000 2.222222 2.166667 0.139622 0.165347 0.158916Sat 2.555556 2.476190 2.517241 0.158048 0.147906 0.153152Sun 2.929825 2.578947 2.842105 0.160113 0.187250 0.166897Thur 2.000000 NaN 2.000000 0.159744 NaN 0.159744Lunch Fri 3.000000 1.833333 2.000000 0.187735 0.188937 0.188765Thur 2.500000 2.352941 2.459016 0.160311 0.163863 0.161301All 2.668874 2.408602 2.569672 0.159328 0.163196 0.160803
要使用其他的聚合函数,将其传给aggfunc即可。例如,使用count或len可以得到有关分组的计数或频率:
In [133]: tips.pivot_table('tip_pct', index=['time', 'smoker'], columns='day',.....: aggfunc=len, margins=True)Out[133]:day Fri Sat Sun Thur Alltime smokerDinner No 3.0 45.0 57.0 1.0 106.0Yes 9.0 42.0 19.0 NaN 70.0Lunch No 1.0 NaN NaN 44.0 45.0Yes 6.0 NaN NaN 17.0 23.0All 19.0 87.0 76.0 62.0 244.0
如果存在空的组合(NA),可以设置一个fill_value:
In [134]: tips.pivot_table('tip_pct', index=['time', 'size', 'smoker'],.....: columns='day', aggfunc='mean', fill_value=0)Out[134]:day Fri Sat Sun Thurtime size smokerDinner 1 No 0.000000 0.137931 0.000000 0.000000Yes 0.000000 0.325733 0.000000 0.0000002 No 0.139622 0.162705 0.168859 0.159744Yes 0.171297 0.148668 0.207893 0.0000003 No 0.000000 0.154661 0.152663 0.000000Yes 0.000000 0.144995 0.152660 0.0000004 No 0.000000 0.150096 0.148143 0.000000Yes 0.117750 0.124515 0.193370 0.0000005 No 0.000000 0.000000 0.206928 0.000000Yes 0.000000 0.106572 0.065660 0.000000... ... ... ... ...Lunch 1 No 0.000000 0.000000 0.000000 0.181728Yes 0.223776 0.000000 0.000000 0.0000002 No 0.000000 0.000000 0.000000 0.166005Yes 0.181969 0.000000 0.000000 0.1588433 No 0.187735 0.000000 0.000000 0.084246Yes 0.000000 0.000000 0.000000 0.2049524 No 0.000000 0.000000 0.000000 0.138919Yes 0.000000 0.000000 0.000000 0.1554105 No 0.000000 0.000000 0.000000 0.1213896 No 0.000000 0.000000 0.000000 0.173706[21 rows x 4 columns]
交叉表:crosstab
交叉表(cross-tabulation,简称crosstab)是一种用于计算分组频率的特殊透视表。
有如下数据:
from io import StringIOdata = """\Sample Nationality Handedness1 USA Right-handed2 Japan Left-handed3 USA Right-handed4 Japan Right-handed5 Japan Left-handed6 Japan Right-handed7 USA Right-handed8 USA Left-handed9 Japan Right-handed10 USA Right-handed"""data = pd.read_table(StringIO(data), sep='\s+')In [138]: dataOut[138]:Sample Nationality Handedness0 1 USA Right-handed1 2 Japan Left-handed2 3 USA Right-handed3 4 Japan Right-handed4 5 Japan Left-handed5 6 Japan Right-handed6 7 USA Right-handed7 8 USA Left-handed8 9 Japan Right-handed9 10 USA Right-handed
想要根据国籍和用手习惯对这段数据进行统计汇总,虽然可以用pivot_table实现该功能:
data.pivot_table('Sample', index='Nationality',columns='Handedness', aggfunc='count', margins=True)
但是pandas.crosstab函数会更方便:
In [139]: pd.crosstab(data.Nationality, data.Handedness, margins=True)Out[139]:Handedness Left-handed Right-handed AllNationalityJapan 2 3 5USA 1 4 5All 3 7 10
默认情况下,pandas.crosstab计算频率,除非传递值数组和聚合函数。
crosstab的前两个参数可以是数组或Series,或是数组列表。比如小费数据:
In [140]: pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)Out[140]:smoker No Yes Alltime dayDinner Fri 3 9 12Sat 45 42 87Sun 57 19 76Thur 1 0 1Lunch Fri 1 6 7Thur 44 17 61All 151 93 244
用pivot_table实现,等价于:
tips.pivot_table('tip_pct', index=['time','day'],columns='smoker', aggfunc='count', margins=True)
重命名索引名和列名:
In[51]:pd.crosstab(index=tips.day,rownames=['星期'],columns=[tips.smoker, tips.time],colnames=['是否吸烟', '时间'],values=tips.tip,aggfunc=np.mean, # 计算均值margins=True,margins_name='总计')Out[51]:是否吸烟 No Yes 总计时间 Dinner Lunch Dinner Lunch星期Fri 3.0 1.0 9.0 6.0 19.0Sat 45.0 NaN 42.0 NaN 87.0Sun 57.0 NaN 19.0 NaN 76.0Thur 1.0 44.0 NaN 17.0 62.0总计 106.0 45.0 70.0 23.0 244.0


文章转载自漫谈大数据与数据分析,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
