




什么是原子提交?
原子提交在分布式系统中是指,对于不同单元上的资源管理器,根据其对应的状态与建议会建立一个"合约",保证所有资源管理器无论是否发生过失败都统一认为事务提交或事务失败[1],从而保证所有资源管理器间的最终状态一致。而两阶段提交通过在数据库不同分片间建立协商(Prepare)和决策(Commit)两个阶段,在分布式数据库中实现了原子提交。
在研究分布式数据库两阶段提交的过程中,我们认为影响原子性的重要因素在于原子提交延时[2](返回用户的延时)、资源回收延时[3]和事务资源消耗[4],因此,《事务原子提交》专题的文章以这三方面来分析原子提交的优化方向,并通过消息数和日志数,更好地量化原子提交不同算法的优劣。本文先介绍原子提交延时方面的优化。
传统两阶段提交
首先,我们主要介绍一下传统两阶段提交如何维护分布式事务的原子性、数据一致性以及它们的开销。图1演示了传统两阶段提交的执行流程。
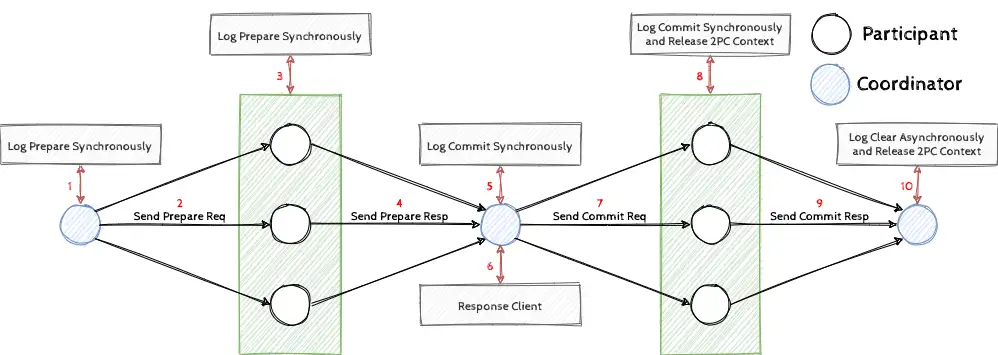
可以看到,在两阶段协议中存在协调者和参与者两个角色。协调者会协调所有参与者完成两阶段提交,第一阶段通过协调者协商事务状态,称为协商阶段;第二阶段由协调者分发决策消息,称为决策阶段。在协商阶段一开始,协调者需要同步[5]写下 Prepare 日志[6],然后发出 Prepare 请求,参与者收到后会同步写出 Prepare 日志并返回 Prepare 回应。当协调者收到所有 Prepare 请求后即可进入决策阶段,协调者若收到所有 Prepare 回应则进入提交阶段,同步写下 Commit 日志后,即可返回用户两阶段提交的决策(请注意此时就是原子提交的延时),然后发出 Commit 请求。参与者收到后会同步写出 Commit 日志并返回 Commit 回应,此时参与者就可以释放自身的资源了(请注意此时就是参与者事务资源释放的延时)。协调者若收到所有 Commit 回应即可异步[5]写出 Clear 日志[7], 并释放自身的资源了(请注意此时就是协调者事务资源释放的延时)。
在这里,我们可以简单[8]地理解下正确性。首先,原子提交的正确性需要保证所有参与者进入一致状态;其次,要保证最终可以安全地释放资源。因此,我们可以根据提交点和回收点来理解,提交点(Commit Point)是指存在全局的某一个点,这个点以后两阶段提交的决策就已经确定无法改变了;回收点(Reclaim Point)是指存全局的某一个点,这个点以后参与者/协调者不再被其余的参与者/协调者依赖。其中传统两阶段提交的提交点是协调者的 Commit 同步成功,参与者的回收点是其 Commit 日志同步成功,协调者的回收点是所有参与者都同步 Commit 日志成功。聪明的你可以想到,返回用户结果和资源回收的最早时间点实际上就是提交点和回收点。在传统两阶段提交中,其返回用户结果与参与者资源回收的实现就是提交点与回收点,皆为最优实现。而协调者由于没有上帝视角,只能在收到所有 Commit 回应之后回收资源。
总结来说,整个传统两阶段提交算法统计如下(假设事务正常提交且其中 N 为参与者数量)。
- 原子提交延时:2 次消息传输(协调者的 Prepare 请求和参与者的 Prepare 回应)和 3 次同步日志(协调者的Prepare,Commit日志及参与者的 Prepare 日志)。
- 资源释放延时:3 次消息传输(协调者的 Prepare、Commit 请求,以及参与者的 Prepare 回应)和 4 次同步日志(协调者的 Prepare、Commit 日志,以及参与者的 Prepare、Commit 日志)。
- 事务资源消耗:4N 条消息传输(协调者的 Prepare、Commit 请求,以及参与者的 Prepare、Commit 回应)以及 2N+2 同步条日志(协调者的 Prepare、Commit 日志,以及参与者的 Prepare、Commit 日志)以及 1 条异步日志(协调者的 Clear 日志)
OceanBase v3.1 两阶段提交
对于传统两阶段提交的事务延时,我们发现了很多可以优化的空间(一想到有趣的优化点就很兴奋≧ω≦)。
考虑到最重要的优化点是原子提交延迟,这也是用户能够感知到的最明显的一点,我们从两方面入手优化。一方面,协调者的 Prepare 日志可以异步提交,参与者列表可以由所有参与者携带以解除对其的依赖;另一方面,两阶段提交的提交点完全是可以提前的,一个事务是否提交除了可以由单个协调者来决定,还可以由所有参与者分布式地决定,即提交点可以提前为所有参与者将 Prepare 日志同步成功来决定。相对地,在这种优化下,协调者就需要通过收集所有参与者的 Prepare 回应来分布式地决定事务的最终状态。但这样一来,我们就能节省掉协调者的 Commit 日志耗时,从而极大地缩短原子提交延时。
基于上述两个思路,我们产生了一个很有趣的想法,即协调者可以不写日志,协调者的状态完全由参与者们来恢复。根据提交点的提前,我们需要重新考虑回收点:由于参与者现在不能依赖协调者的状态(协调者的状态现在不再持久化)来得出自身的状态,而是依赖所有的参与者。因此,参与者是否可以回收就需要依赖所有参与者的状态推进,这需要保证不同参与者的状态在所有参与者可以独立决定事务状态前都无法释放资源,不然各个参与者的事务状态可能会进入不一致的状态。在实现上,我们通过为所有参与者新增一条 Clear 日志来解决这个问题,因为新阶段保证了所有参与者都已经进入了可以独立决定事务状态,不再依赖其他参与者的状态。OceanBase v3.1 两阶段提交就以此来优化,大致优化结果如图2所示。
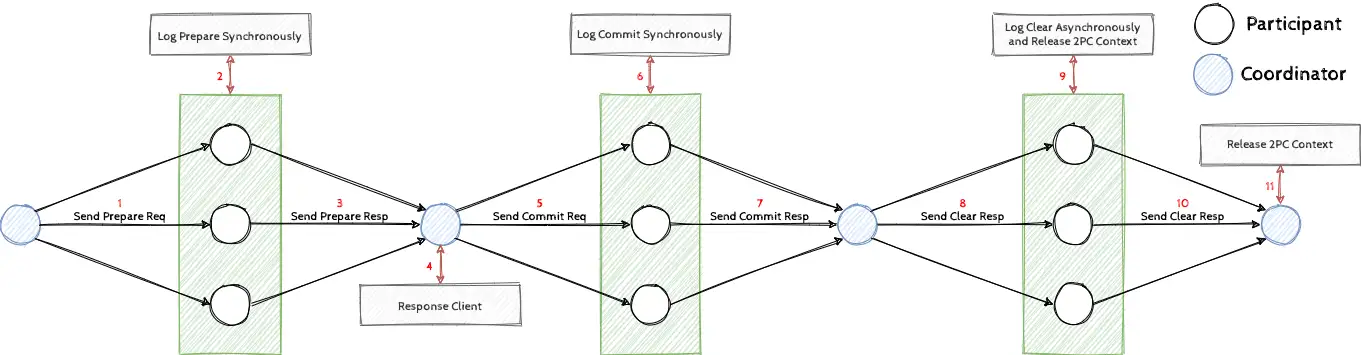
我们为两阶段提交新增了一个阶段,即释放阶段。首先在协商阶段,协调者需要直接发出 Prepare 请求,参与者收到后会同步地写出 Prepare 日志,并返回 Prepare 回应。当协调者收到所有 Prepare 回应后即可进入决策阶段,若收到所有 Prepare 回应,则进入提交阶段,直接可以返回用户两阶段提交的决策(请注意此时就是原子提交的延时),然后发出 Commit 请求。参与者收到后会同步地写出 Commit 日志,并返回 Commit 回应,(注意此时参与者不可以简单地释放自身的资源了)。当协调者收集所有 Commit 回应后即可释放资源,发出 Clear 请求,若此时参与者收到,就会异步地写出 Clear 日志,并释放自身的资源(请注意此时就是事务资源释放的延时)。
让我们通过图3的一些异常情况来具体学习一下 OceanBase v3.1 的两阶段提交实现。
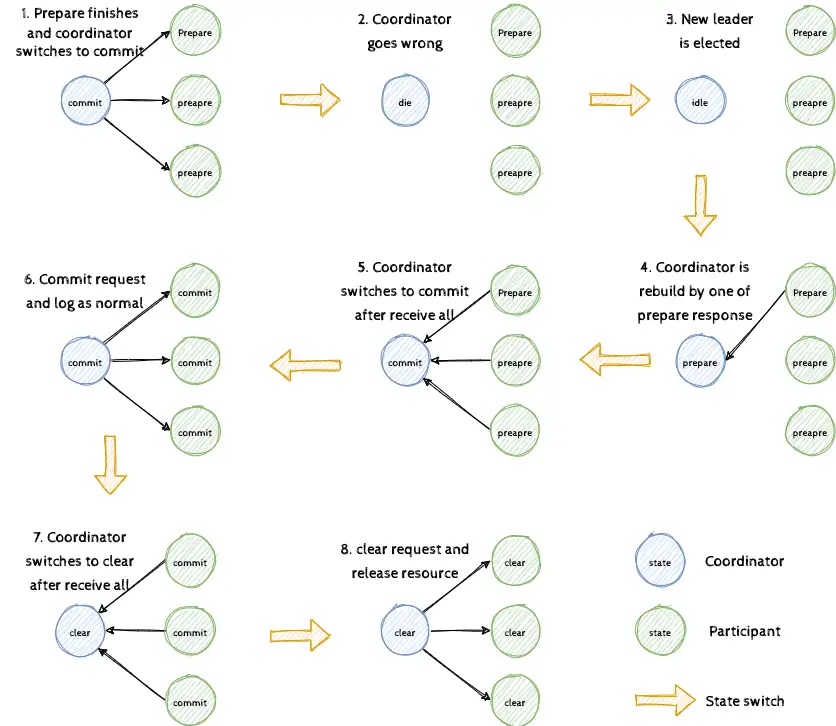
我们可以看到,在第1步到第3步中,当协调者通过正常流程集齐所有参与者的 Prepare 回应进入提交状态(注意此时已经进入提交点)后,协调者由于异常丢失状态,之后其通过分布式的容错能力继续提供服务(因不写日志丢失了全部状态)。接着在第4步中,会由其中任意参与者的 Prepare 回应下恢复协调者至 Prepare 状态,并在第5步到第6步中,根据正常的协议集齐 Prepare 回应推进到 Commit 阶段。最终在第7步和第8步中,推进到 Clear 阶段直至释放资源。在这个实现过程中我们可以看出,就算协调者在 Commit 状态下丢失状态,也可以通过所有参与者来恢复。
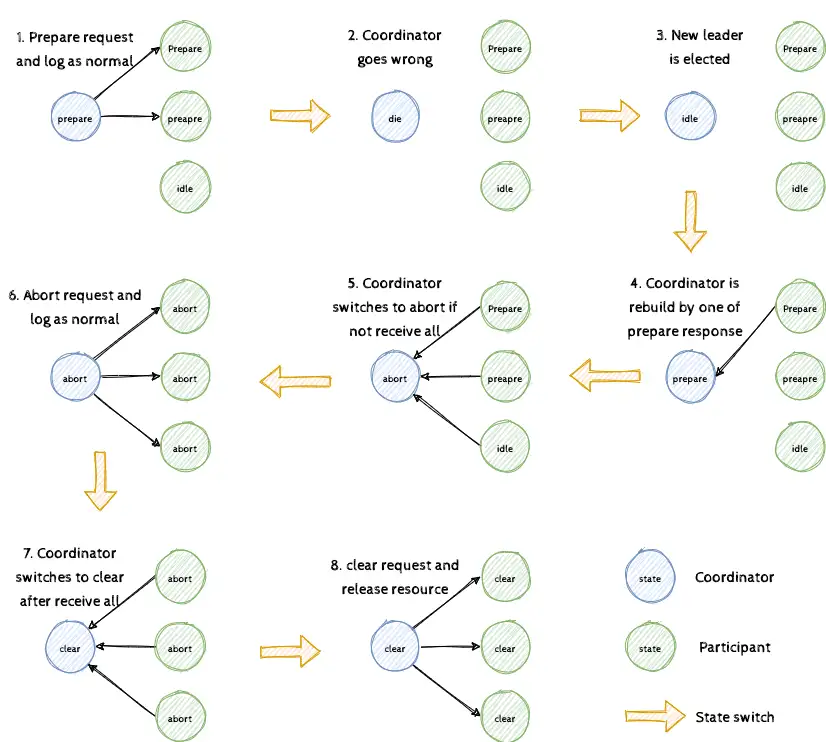
我们再思考下状态未恢复成功的情况,如图4所示。从第1步到底3步,参与者因为异常丢失状态(此刻一定未进入提交点),协调者也因为异常丢失状态,之后其通过分布式的容错能力继续提供服务。在第4步,由其中任意参与者的 Prepare 回应,恢复协调者至 Prepare 状态。在第5步到第6步中,因为发现了参与者的异常,会推进到 Abort 阶段,之后和原先一致推进到 Clear 阶段直至释放资源。从中我们可以看出,如果参与者丢失状态,最终协调者也会在恢复后回滚事务。聪明的你肯定因此分析出了 Clear 的作用,若不存在这个状态,我们将无法分辨出第5步与正常流程下存在一个参与者先释放资源而其余参与者还处于 Prepare 的状态。你可以自己画图来验证自己的猜测,在社区「问答」区留言探讨 (◍•ᴗ•◍)
我们不正式[8]地理解 OceanBase 两阶段提交的正确性,重新思考下两阶段提交的提交点和回收点。我们的提交点是所有参与者的 Prepare 日志同步成功(恢复因此通过依赖所有参与者的状态,保证状态不会因此撒谎); 回收点是所有参与者 Commit 日志同步成功(恢复此时不再依赖其余参与者,保证任意参与者不会因此撒谎)。由于分布式的状态推进,返回用户结果的实现就是协调者收到所有参与者的 Prepare 回应,而其资源回收的实现就是参与者收到 Clear 请求的时间点。由于分布式的架构,各个节点都不存在上帝视角,无法做到最优。
总结来说, 整个OceanBase 两阶段提交统计如下(假设事务正常提交且其中 N 为参与者数量)。
- 事务延时:2 次消息传输(协调者的 Prepare 请求和参与者的 Prepare 回应)和 1 次日志同步(参与者的 Prepare 日志)。
- 资源释放延时:5 次消息传输(协调者的 Prepare、Commit、Clear请求,参与者的 Prepare、Commit 回应)和 2 次日志同步(参与者的 Prepare 日志和 Commit 日志)。
- 事务资源消耗:6N 条消息传输(协调者的 Prepare、Commit、Clear请求,以及参与者的 Prepare、Commit、Clear 回应),以及 2N 条同步日志(参与者的 Prepare、Commit 日志)和 N 条异步日志(参与者的 Clear 日志)。
关注 OceanBase 的朋友肯定注意到了,本文没有涉及 Pre Commit 消息,因为本文希望集中讨论原子提交,所以本文假设不存在Pre Commit的优化。
什么是原子提交?
原子提交在分布式系统中是指,对于不同单元上的资源管理器,根据其对应的状态与建议会建立一个"合约",保证所有资源管理器无论是否发生过失败都统一认为事务提交或事务失败[1],从而保证所有资源管理器间的最终状态一致。而两阶段提交通过在数据库不同分片间建立协商(Prepare)和决策(Commit)两个阶段,在分布式数据库中实现了原子提交。
在研究分布式数据库两阶段提交的过程中,我们认为影响原子性的重要因素在于原子提交延时[2](返回用户的延时)、资源回收延时[3]和事务资源消耗[4],因此,《事务原子提交》专题的文章以这三方面来分析原子提交的优化方向,并通过消息数和日志数,更好地量化原子提交不同算法的优劣。本文先介绍原子提交延时方面的优化。
传统两阶段提交
首先,我们主要介绍一下传统两阶段提交如何维护分布式事务的原子性、数据一致性以及它们的开销。图1演示了传统两阶段提交的执行流程。
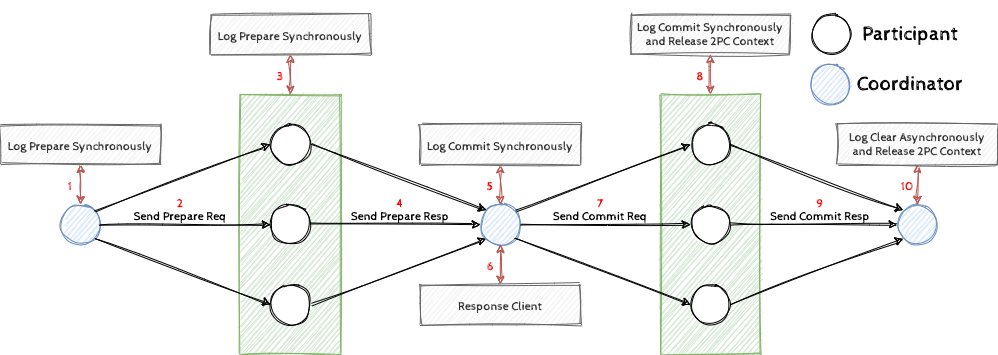
可以看到,在两阶段协议中存在协调者和参与者两个角色。协调者会协调所有参与者完成两阶段提交,第一阶段通过协调者协商事务状态,称为协商阶段;第二阶段由协调者分发决策消息,称为决策阶段。在协商阶段一开始,协调者需要同步[5]写下 Prepare 日志[6],然后发出 Prepare 请求,参与者收到后会同步写出 Prepare 日志并返回 Prepare 回应。当协调者收到所有 Prepare 请求后即可进入决策阶段,协调者若收到所有 Prepare 回应则进入提交阶段,同步写下 Commit 日志后,即可返回用户两阶段提交的决策(请注意此时就是原子提交的延时),然后发出 Commit 请求。参与者收到后会同步写出 Commit 日志并返回 Commit 回应,此时参与者就可以释放自身的资源了(请注意此时就是参与者事务资源释放的延时)。协调者若收到所有 Commit 回应即可异步[5]写出 Clear 日志[7], 并释放自身的资源了(请注意此时就是协调者事务资源释放的延时)。
在这里,我们可以简单[8]地理解下正确性。首先,原子提交的正确性需要保证所有参与者进入一致状态;其次,要保证最终可以安全地释放资源。因此,我们可以根据提交点和回收点来理解,提交点(Commit Point)是指存在全局的某一个点,这个点以后两阶段提交的决策就已经确定无法改变了;回收点(Reclaim Point)是指存全局的某一个点,这个点以后参与者/协调者不再被其余的参与者/协调者依赖。其中传统两阶段提交的提交点是协调者的 Commit 同步成功,参与者的回收点是其 Commit 日志同步成功,协调者的回收点是所有参与者都同步 Commit 日志成功。聪明的你可以想到,返回用户结果和资源回收的最早时间点实际上就是提交点和回收点。在传统两阶段提交中,其返回用户结果与参与者资源回收的实现就是提交点与回收点,皆为最优实现。而协调者由于没有上帝视角,只能在收到所有 Commit 回应之后回收资源。
总结来说,整个传统两阶段提交算法统计如下(假设事务正常提交且其中 N 为参与者数量)。
- 原子提交延时:2 次消息传输(协调者的 Prepare 请求和参与者的 Prepare 回应)和 3 次同步日志(协调者的Prepare,Commit日志及参与者的 Prepare 日志)。
- 资源释放延时:3 次消息传输(协调者的 Prepare、Commit 请求,以及参与者的 Prepare 回应)和 4 次同步日志(协调者的 Prepare、Commit 日志,以及参与者的 Prepare、Commit 日志)。
- 事务资源消耗:4N 条消息传输(协调者的 Prepare、Commit 请求,以及参与者的 Prepare、Commit 回应)以及 2N+2 同步条日志(协调者的 Prepare、Commit 日志,以及参与者的 Prepare、Commit 日志)以及 1 条异步日志(协调者的 Clear 日志)
OceanBase v3.1 两阶段提交
对于传统两阶段提交的事务延时,我们发现了很多可以优化的空间(一想到有趣的优化点就很兴奋≧ω≦)。
考虑到最重要的优化点是原子提交延迟,这也是用户能够感知到的最明显的一点,我们从两方面入手优化。一方面,协调者的 Prepare 日志可以异步提交,参与者列表可以由所有参与者携带以解除对其的依赖;另一方面,两阶段提交的提交点完全是可以提前的,一个事务是否提交除了可以由单个协调者来决定,还可以由所有参与者分布式地决定,即提交点可以提前为所有参与者将 Prepare 日志同步成功来决定。相对地,在这种优化下,协调者就需要通过收集所有参与者的 Prepare 回应来分布式地决定事务的最终状态。但这样一来,我们就能节省掉协调者的 Commit 日志耗时,从而极大地缩短原子提交延时。
基于上述两个思路,我们产生了一个很有趣的想法,即协调者可以不写日志,协调者的状态完全由参与者们来恢复。根据提交点的提前,我们需要重新考虑回收点:由于参与者现在不能依赖协调者的状态(协调者的状态现在不再持久化)来得出自身的状态,而是依赖所有的参与者。因此,参与者是否可以回收就需要依赖所有参与者的状态推进,这需要保证不同参与者的状态在所有参与者可以独立决定事务状态前都无法释放资源,不然各个参与者的事务状态可能会进入不一致的状态。在实现上,我们通过为所有参与者新增一条 Clear 日志来解决这个问题,因为新阶段保证了所有参与者都已经进入了可以独立决定事务状态,不再依赖其他参与者的状态。OceanBase v3.1 两阶段提交就以此来优化,大致优化结果如图2所示。
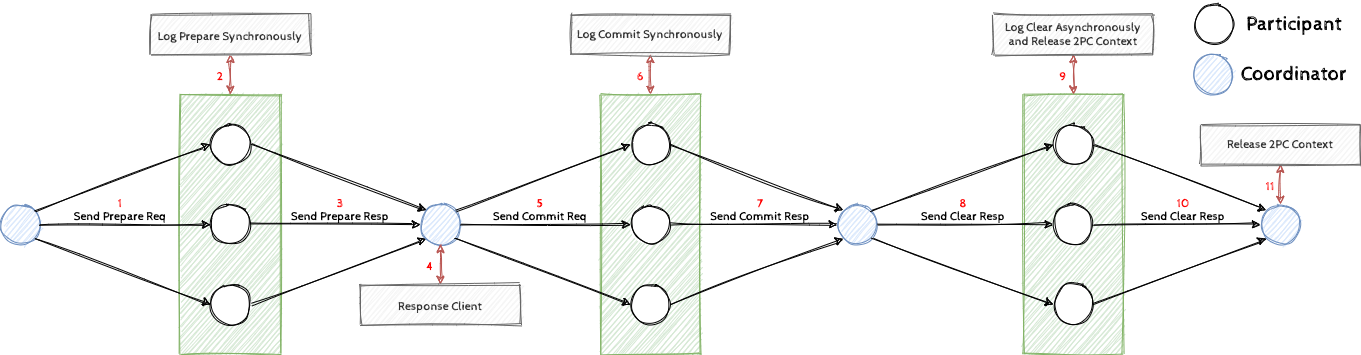
我们为两阶段提交新增了一个阶段,即释放阶段。首先在协商阶段,协调者需要直接发出 Prepare 请求,参与者收到后会同步地写出 Prepare 日志,并返回 Prepare 回应。当协调者收到所有 Prepare 回应后即可进入决策阶段,若收到所有 Prepare 回应,则进入提交阶段,直接可以返回用户两阶段提交的决策(请注意此时就是原子提交的延时),然后发出 Commit 请求。参与者收到后会同步地写出 Commit 日志,并返回 Commit 回应,(注意此时参与者不可以简单地释放自身的资源了)。当协调者收集所有 Commit 回应后即可释放资源,发出 Clear 请求,若此时参与者收到,就会异步地写出 Clear 日志,并释放自身的资源(请注意此时就是事务资源释放的延时)。
让我们通过图3的一些异常情况来具体学习一下 OceanBase v3.1 的两阶段提交实现。
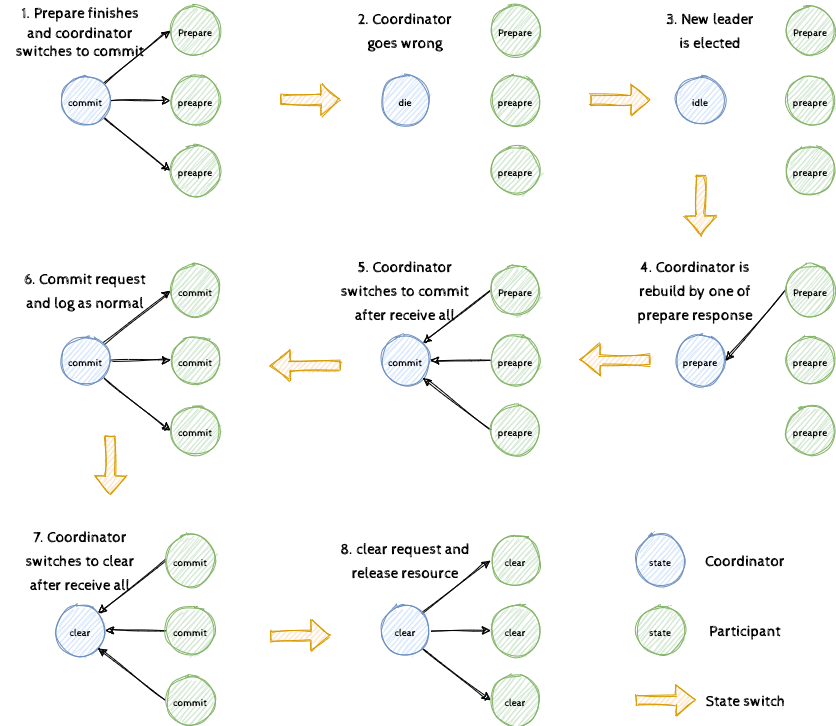
我们可以看到,在第1步到第3步中,当协调者通过正常流程集齐所有参与者的 Prepare 回应进入提交状态(注意此时已经进入提交点)后,协调者由于异常丢失状态,之后其通过分布式的容错能力继续提供服务(因不写日志丢失了全部状态)。接着在第4步中,会由其中任意参与者的 Prepare 回应下恢复协调者至 Prepare 状态,并在第5步到第6步中,根据正常的协议集齐 Prepare 回应推进到 Commit 阶段。最终在第7步和第8步中,推进到 Clear 阶段直至释放资源。在这个实现过程中我们可以看出,就算协调者在 Commit 状态下丢失状态,也可以通过所有参与者来恢复。
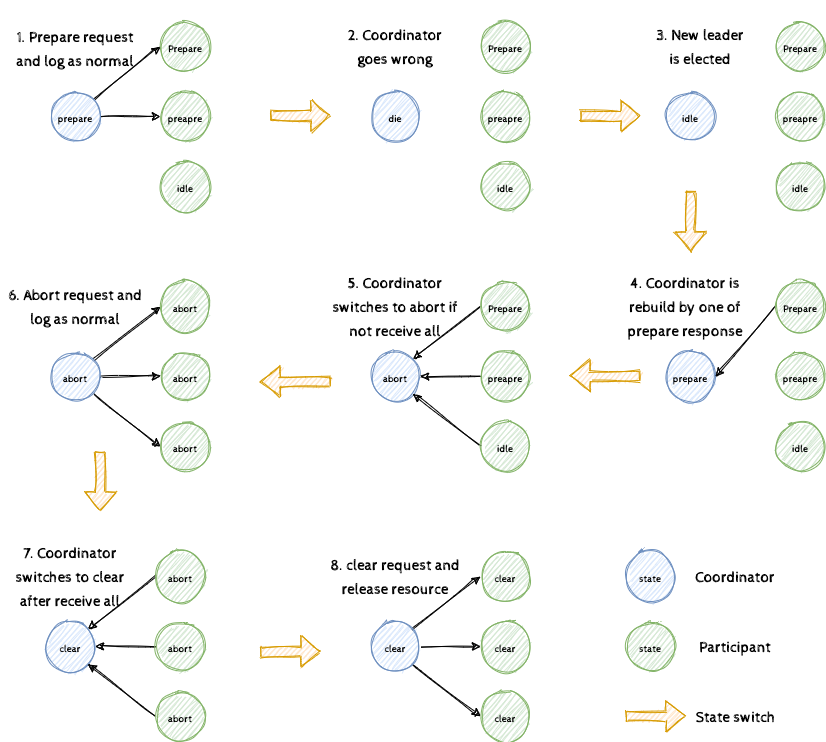
我们再思考下状态未恢复成功的情况,如图4所示。从第1步到底3步,参与者因为异常丢失状态(此刻一定未进入提交点),协调者也因为异常丢失状态,之后其通过分布式的容错能力继续提供服务。在第4步,由其中任意参与者的 Prepare 回应,恢复协调者至 Prepare 状态。在第5步到第6步中,因为发现了参与者的异常,会推进到 Abort 阶段,之后和原先一致推进到 Clear 阶段直至释放资源。从中我们可以看出,如果参与者丢失状态,最终协调者也会在恢复后回滚事务。聪明的你肯定因此分析出了 Clear 的作用,若不存在这个状态,我们将无法分辨出第5步与正常流程下存在一个参与者先释放资源而其余参与者还处于 Prepare 的状态。你可以自己画图来验证自己的猜测,在社区「问答」区留言探讨 (◍•ᴗ•◍)
我们不正式[8]地理解 OceanBase 两阶段提交的正确性,重新思考下两阶段提交的提交点和回收点。我们的提交点是所有参与者的 Prepare 日志同步成功(恢复因此通过依赖所有参与者的状态,保证状态不会因此撒谎); 回收点是所有参与者 Commit 日志同步成功(恢复此时不再依赖其余参与者,保证任意参与者不会因此撒谎)。由于分布式的状态推进,返回用户结果的实现就是协调者收到所有参与者的 Prepare 回应,而其资源回收的实现就是参与者收到 Clear 请求的时间点。由于分布式的架构,各个节点都不存在上帝视角,无法做到最优。
总结来说, 整个OceanBase 两阶段提交统计如下(假设事务正常提交且其中 N 为参与者数量)。
- 事务延时:2 次消息传输(协调者的 Prepare 请求和参与者的 Prepare 回应)和 1 次日志同步(参与者的 Prepare 日志)。
- 资源释放延时:5 次消息传输(协调者的 Prepare、Commit、Clear请求,参与者的 Prepare、Commit 回应)和 2 次日志同步(参与者的 Prepare 日志和 Commit 日志)。
- 事务资源消耗:6N 条消息传输(协调者的 Prepare、Commit、Clear请求,以及参与者的 Prepare、Commit、Clear 回应),以及 2N 条同步日志(参与者的 Prepare、Commit 日志)和 N 条异步日志(参与者的 Clear 日志)。
关注 OceanBase 的朋友肯定注意到了,本文没有涉及 Pre Commit 消息,因为本文希望集中讨论原子提交,所以本文假设不存在Pre Commit的优化。
