




进行数据库设计时,表设计上的一些关键项将严重影响后续整库的查询性能。表设计对数据存储也有影响:好的表设计能够减少I/O操作及最小化内存使用,进而提升查询性能。
表的存储模型选择是表定义的第一步。客户业务属性是表的存储模型的决定性因素,依据下面表格选择适合当前业务的存储模型。
复制表(Replication)方式将表中的全量数据在集群的每一个DN实例上保留一份。主要适用于记录集较小的表。这种存储方式的优点是每个DN上都有该表的全量数据,在join操作中可以避免数据重分布操作,从而减小网络开销,同时减少了plan segment(每个plan segment都会起对应的线程);缺点是每个DN都保留了表的完整数据,造成数据的冗余。一般情况下只有较小的维度表才会定义为Replication表。

哈希(Hash)表将表中某一个或几个字段进行hash运算后,生成对应的hash值,根据DN实例与哈希值的映射关系获得该元组的目标存储位置。对于Hash分布表,在读/写数据时可以利用各个节点的IO资源,大大提升表的读/写速度。一般情况下大表定义为Hash表。
范围(Range)和列表(List)分布是由用户自定义的分布策略,根据分布列的取值落入满足一定范围或者具体值的对应目标DN,这两种分布方式便于用户灵活地进行数据管理,但对用户本身的数据抽象能力有一定的要求。
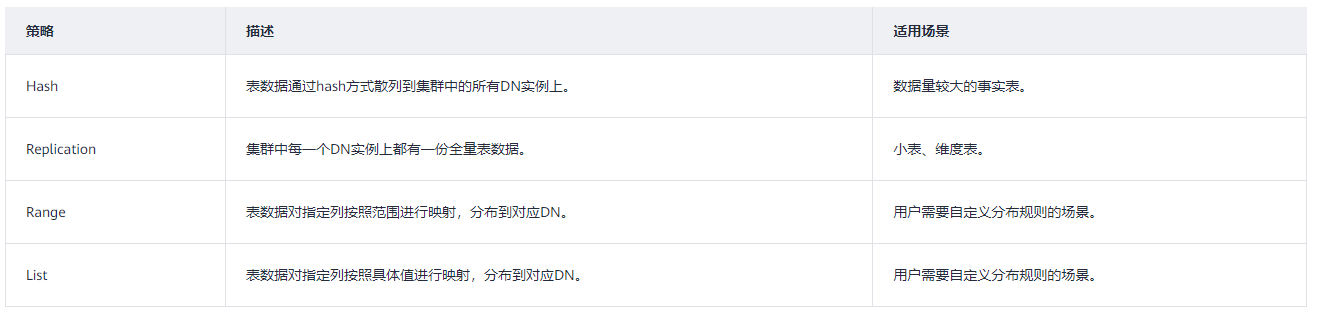
如图1所示,复制表如图中的表T1,哈希表如图中的表T2。
图1 复制表和哈希表 如图1所示,复制表如图中的表T1,哈希表如图中的表T2。
如图1所示,复制表如图中的表T1,哈希表如图中的表T2。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
