




Server Stats in Memory - 内存中的 ObServer 信息
RS/Server manager在内存中将OBServer的信息放在server_manager_.server_statuses_ 里,这是一个 OBServerStatus 数组。每一个 OBServerStatus 都记录了集群中一个 OBServer 的信息。同时,server_manager_.server_statuses_ 也是一个白名单 (whitelist),RS/server manager 只会管理白名单中的 OBServer, 如果有不在白名单内的 OBServer 向 RS/server manager 发来请求,这个请求是不会被处理的。
以下介绍了 OBServerStatus 记录的 OBServer 的信息:
// 这里只展示了一部分
uint64_t id_; // id 会在 ObServer 被加到集群的时候分配
common::ObZone zone_; // 这个 ObServer 所在的zone
char build_version_[common::OB_SERVER_VERSION_LENGTH];
common::ObAddr server_; // ObServer 的ip地址
int64_t sql_port_; // sql listen port
int64_t last_hb_time_; // 上一次收到这个 ObServer 心跳的时刻
int64_t stop_time_; // ObServer 被 stop 的时间
int64_t start_service_time_; // ObServer 初始化后可以对外提供服务的时刻
ServerAdminStatus admin_status_; // Admin Status 下文中会介绍
HeartBeatStatus hb_status_; // Heartbeat Status 下文中会介绍
bool with_rootserver_; // true 则表明RS在这个ObServer上
bool force_stop_hb_; // 置为 true 后 server manager 将不会更新 last_hb_time_
ObServerResourceInfo resource_info_; // cpu, memory, disk, ...
int64_t leader_cnt_; // 这个 ObServer 上 leader 副本的个数
int64_t server_report_status_; // LEASE_REQUEST_NORMAL or
// LEASE_REQUEST_DATA_DISK_ERRORServer Stats in __all_server Table - 持久化的 ObServer 信息
为了保证新 RS 上任的时候可以和旧 RS 掌握尽可能相同的信息,每次更新 server_manager_.server_statuses_ 的时候也会提交异步任务 status_change_callback_->on_server_status_change()或者直接通过st_operator_.update()(st_operator 是操作 __all_server 表的 operator) 更新 __all_server 表。
以下介绍了 __all_server 表记录的 OBServer 的信息:
def_table_schema(
table_name = '__all_server',
table_id = '117',
table_type = 'SYSTEM_TABLE',
gm_columns = ['gmt_create', 'gmt_modified'], #gmt_modified就是last_hb_time_
rowkey_columns = [
('svr_ip', 'varchar:MAX_IP_ADDR_LENGTH'),
('svr_port', 'int'),
],
normal_columns = [
('id', 'int'),
('zone', 'varchar:MAX_ZONE_LENGTH'),
('inner_port', 'int'), # sql_port_
('with_rootserver', 'int'),
('status', 'varchar:OB_SERVER_STATUS_LENGTH'), # Display Status 下文中会介绍
('block_migrate_in_time', 'int'),
('build_version', 'varchar:OB_SERVER_VERSION_LENGTH'),
('stop_time', 'int', 'false', '0'),
('start_service_time', 'int'),
('first_sessid', 'int', 'false', '0'),
('with_partition', 'int', 'false', '0'),
],
)我们可以发现 __all_server 表的信息和内存中的信息并不是完全相同,例如 __all_server 表中的状态是 Display Status,但内存中却是 Admin Status 和 HeartBeat Status, 下文中会介绍它们之间的联系。此外,内存中记录了 OBServer 中的一些资源(磁盘,内存,CPU, ...)信息 resource_info_,也通过server_report_status_标记了磁盘是否有问题, 但 __all_server 表中却没有记录。新 RS 上任的时候会向集群内所有 ObServer 发 RPC 请求心跳,这些信息会随着心跳一起汇报上来。
新旧 RS 信息不一致会出现一些严重问题,如某一个 OBServer 在旧 RS 中已经被删掉了,但由于 __all_server 表没来得及更新, 新 RS 的白名单中还有这个 OBServer 。为了避免这些问题,RS 设计了多重机制确保 server_manager_.server_statuses_ 和 __all_server 表保持一致。
- Bootstrap/新 RS 上任的时候(server_manager_.load_server_manager()):读 __all_server_表,根据读到的信息更新 server_manager_.server_statuses_。
- RS 在服务过程中,每次更新 server_manager_.server_statuses_ 都会提交异步任务status_change_callback_->on_server_status_change()或者直接通过st_operator_.update()更新 __all_server 表。
- RS 中有一个定时任务 CheckAllServerTask ,这个任务每 30 秒执行一次,检测内存中的 OBServer 信息和 __all_server 表中是否有不一致,不一致会提交异步任务更新 __all_server 表。
- 直接的运维操作 ALTER SYSTEM RELOAD SERVER:读 __all_server_表,根据读到的信息更新 server_manager_.server_statuses_。
Server Status - OBServer 的状态
OBServer 有三种状态,分别是 Admin Status, HeartBeat Status 和 Display Status。其中,Admin Status 和 HeartBeat Status 是在内存里的, Display Status 是显示在 __all_server 表里的。内存里的状态和 __all_server 表里的状态可以互相推导。
Admin Status
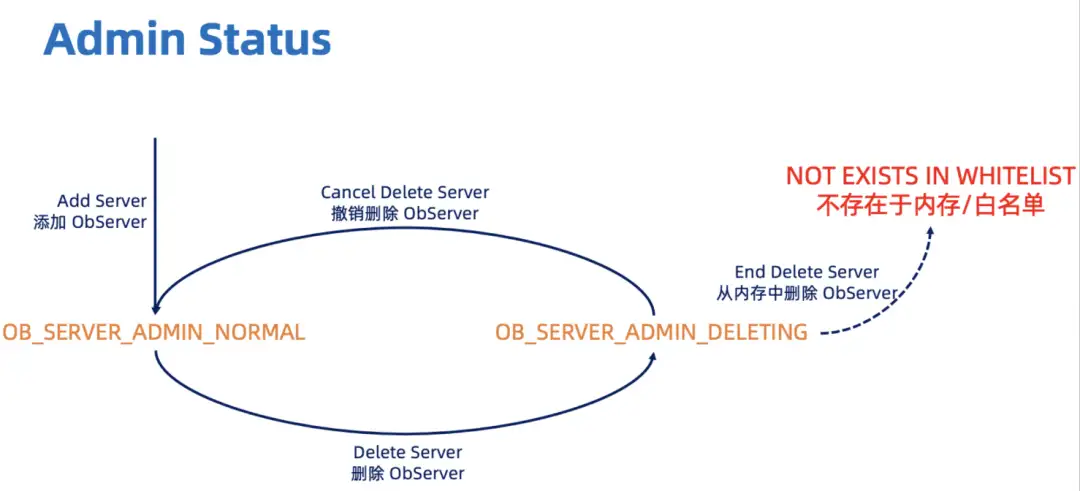
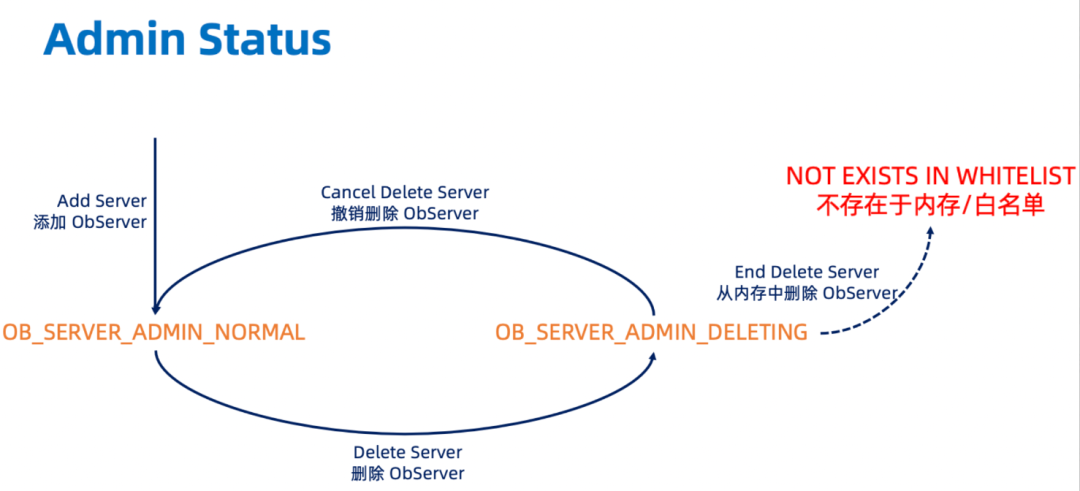
Admin Status 表达了 OBServer 的添加/删除,下图表现了它的状态流转。需要注意的是,Delete Server 返回成功后,只代表在内存中这个 OBServer 的 Admin Status 变成了 OB_SERVER_ADMIN_DELETING。要等这个 OBServer 上的资源被清空之后,它才会被 RS 移出白名单。在被移出白名单之前,可以通过 Cancel Delete Server 撤销删除。
HeartBeat Status
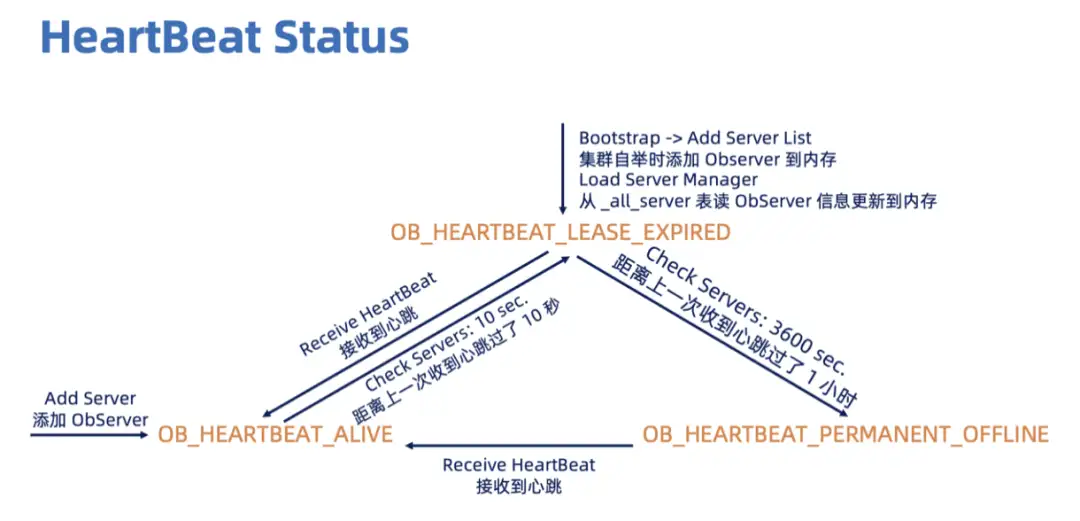
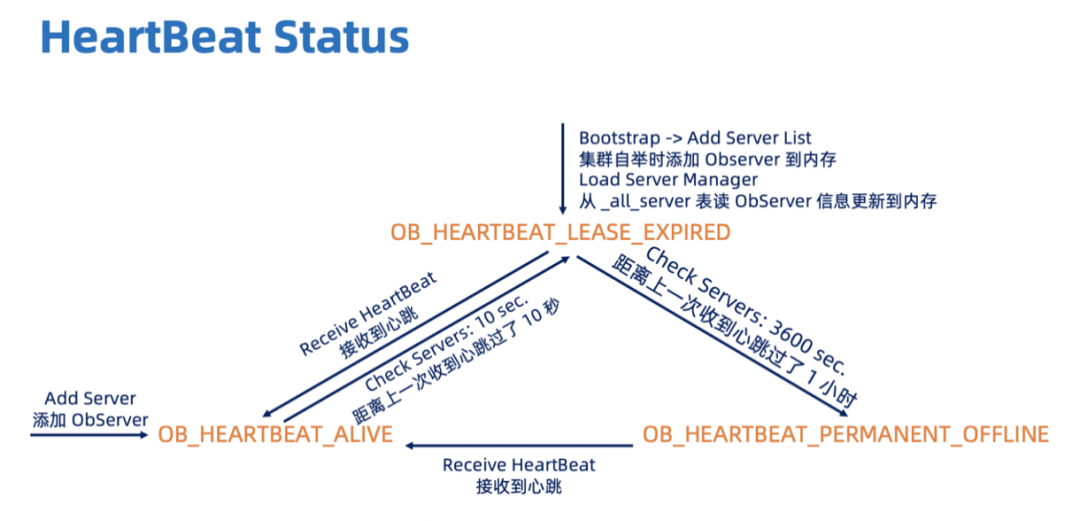
HeartBeat Status 表达了 OBServer 和 RS 保持联系。RS 会定期检查 OBServer 是否发了心跳,如果距离上一次收到这个 OBServer 心跳过了 10 秒,那么这个 OBServer 的 HeartBeat Status 就会被改为OB_HEARTBEAT_LEASE_EXPIRED。如果距离上一次收到这个 OBServer 心跳已经过了1小时 (这个时间在配置项里可以改),那这个 OBServer 的HeartBeat Status就会被改为OB_HEARTBEAT_PERMANENT_OFFLINE。具体的检查和不同HeartBeat Status下的 OBServer 管理逻辑将在 RS->OBServer 中进行讨论。
Display Status
顾名思义,展示在 __all_server 表里的 OBServer 状态。我们也可以通过 Display Status 和 last_hb_time_反推出 Admin Status 和 HeartBeat Status。

需要注意的是,OB_Server_DELETING 不能反推出 HeartBeat Status,但是 Delete Server 的时候会把force_stop_hb_置为true,一小时后就会永久下线。Stop Server 在心跳中同样没有体现,是 Stop Server 返回成功后把这个 OBServer 进程真正 kill 掉,一小时后 RS 就会让这个 OBServer 永久下线。
Bootstrap - 集群自举
这一小节简要概述了 bootstrap,重点是和 server manager 或者心跳有关的部分, 其它部分可能没有提及。
在 OceanBase 中, bootstrap 的运维命令是:
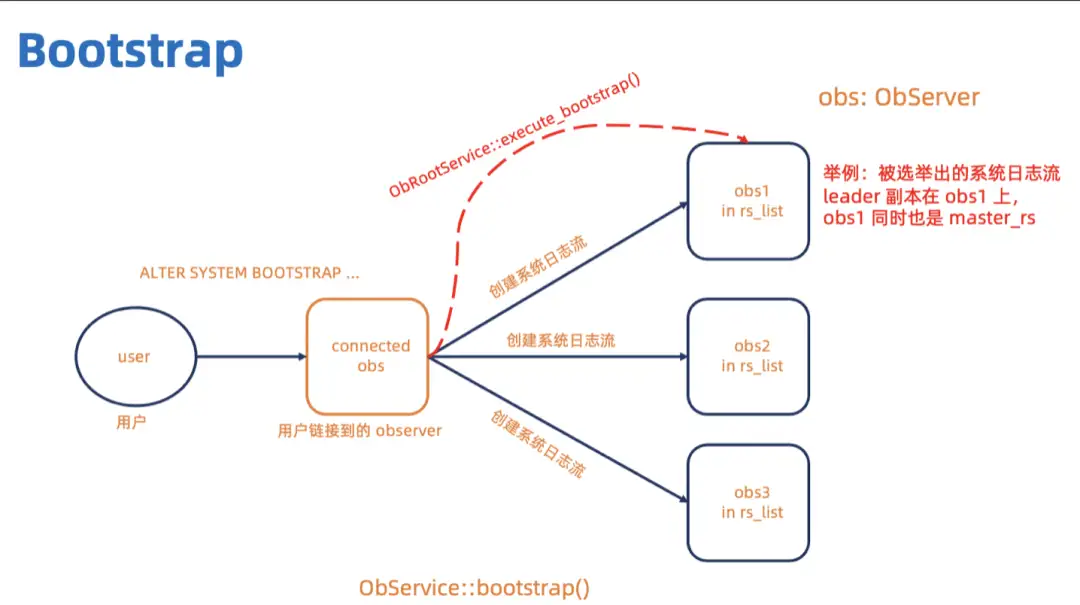
// 举例,三个Zone的情况下ALTER SYSTEM BOOTSTRAP ZONE 'xxxx1' SERVER 'xxx.xxx.xx.xx1:xxxx', ZONE 'xxxx2' SERVER 'xxx.xxx.xx.xx2:xxxx', ZONE 'xxxx3' SERVER 'xxx.xxx.xx.xx3:xxxx'; 这三个 OBServer 会组成一个 rs_list。如下图所示 (图中的箭头只代表参与的情况,不一定是发 RPC), bootstrap 的时候用户的 bootstrap 命令会发到链接串上的 OBServer,这个 OBServer 会执行 OBService::bootstrap()。首先它会在rs_list里的三个 OBServer 上创建系统日志流,等待系统日志流选 leader。系统日志流 leader 所在的 OBServer 就是 master_rs。链接串上的 OBServer 会给 master_rs 发 RPC 执行 OBRootService::execute_bootstrap()。
master_rs 先等 rs_list 上所有的 OBServer 给自己发送心跳,当确认它们都在线 (HeartBeat Status 都为 OB_HEARTBEAT_ALIVE)之后,再创建内部表的 schema。
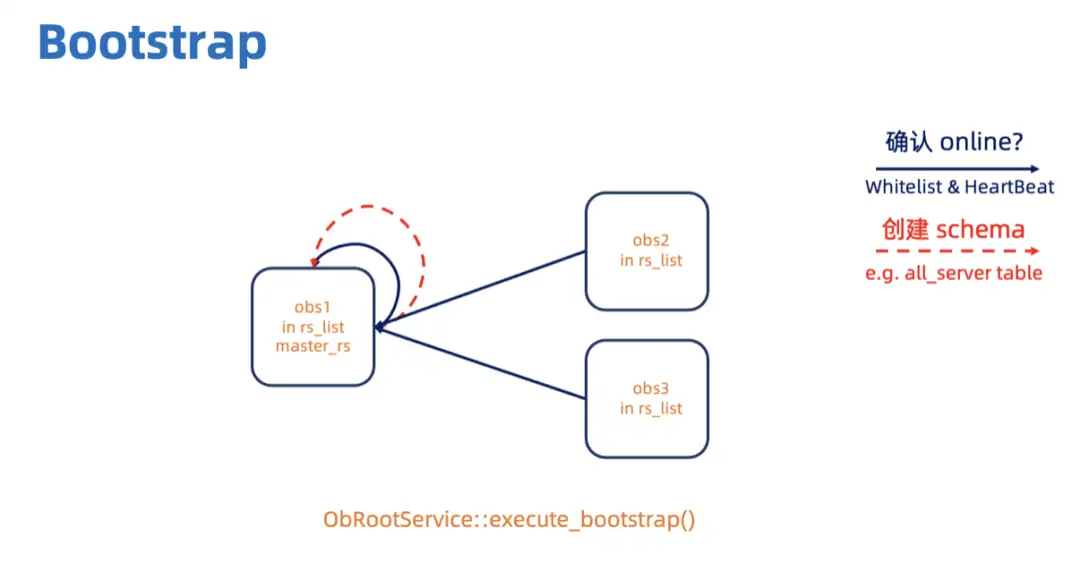
然后 master_rs 会等 rs_list 上所有的 OBServer 都提供服务 (start_service_time_大于 0) 之后,在执行 do_restart(),启动 RS 所提供的服务。
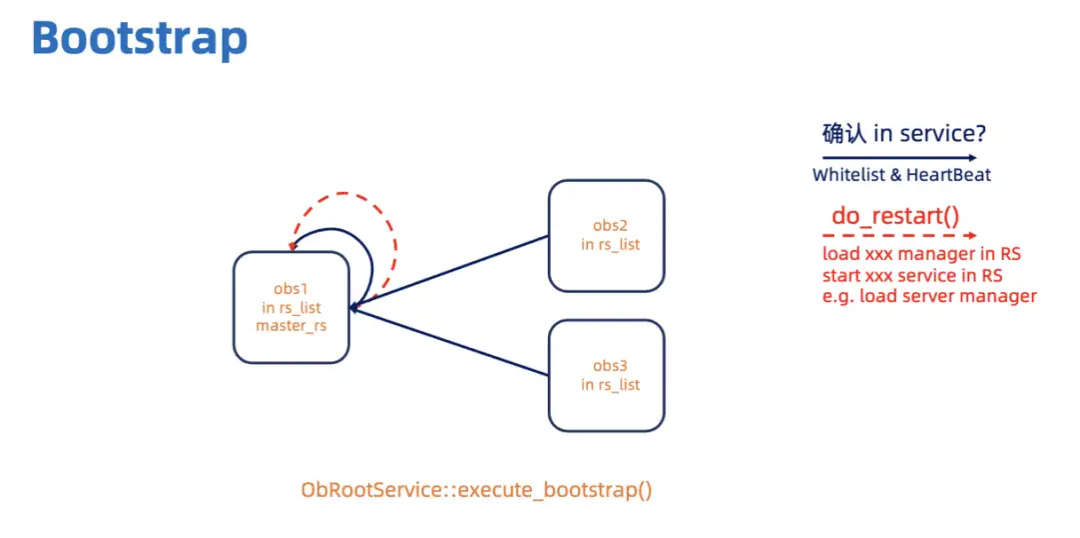
需要注意的是,bootstrap阶段只会将rs_list里的OBServer添加到内存server_manager_.server_statuses_及持久化到 __all_server表里,集群里剩下的 OBServer 需要通过 Add Server 的运维命令手动添加。
int ObRootService::execute_bootstrap(const obrpc::ObBootstrapArg &arg){ // ... bootstrap.execute_bootstrap(); do_restart(); // ...
}int ObBootstrap::execute_bootstrap(){ // ... add_rs_list(); // 将 rs_list 加载到 server_manager 的白名单 server_statuses_ 里 // 此时它们的 heartbeat status 是 OB_HEARTBEAT_LEASE_EXPIRED // 后续的步骤中很多地方都对白名单有依赖 // 如只处理白名单里的 ObServer 发来的心跳 wait_all_rs_online(); // 等待rs_list里的 ObServer 的 heartbeat status 变为 OB_HEARTBEAT_ALIVE // 收到心跳的时候创建异步任务,将 ObServer 信息写入 __all_server 表 // 这个异步任务会一直重试到成功为止 // 此时系统表还未创建,所以需要等到系统表创建完成之后这个任务才会成功 // ... create_all_schema(); // 内部表创建完成,之前的异步任务现在开始可以执行成功了 // ... wait_all_rs_in_service(); // 等待 rs_list 里的 ObServer 开始提供服务 // 即内存里的 start_service_time_ 变得大于 0 // ...}int ObRootService::do_restart() { // ... update_rs_list() // 配置项同步逻辑 // 修改 server config 里的 rootservice_list // 并更新到内部表 __all_sys_parameter 里 // 之后讨论心跳会用到这里 refresh_server(); // 这里会 load_server_manager() // 即将创建系统表后写到 __all_server 表里的信息再读回到内存里 // ...}在ObBootstrap::execute_bootstrap()中,wait_all_rs_online()是等待 rs_list 里的 OBServer 的heartbeat status变成OB_HEARTBEAT_ALIVE;wait_all_rs_in_service()是等待 rs_list 里的 OBServer 的start_service_time_变得大于 0。以下代码展示了 OBServer 从发心跳到开启服务中间的历程。
新RS上任
RS 是在系统日志流 leader 所在 OBServer 上的一组服务,当系统日志流的 leader 位置改变时, RS 也会跟着改变。RS 新 leader 上任的时候会 load server manager。首先是通过ObRootServiceMonitor::monitor_root_service()发现自己现在变成了 leader,然后将 RS 的状态改为 IN_SERVICE 并添加异步任务 ObRestartTask。这个异步任务执行的时候会调用 ObRootService::do_restart() 打开 RS 的各种服务并将 RS 状态置为FULL_SERVICE。
HeartBeat - 心跳
本章首先介绍了我们为什么需要心跳,然后讨论了心跳的发送和 server manager 通过心跳对 OBServer 进行管理。RS 在需要的时候通过 ObRootService::request_heartbeats() 向 ObServer 发 RPC 请求汇报。OBServer 定时通过 ObLeaseStateMgr::renew_lease() 主动向 RS 发送心跳进行汇报。RS也会通过 ObHeartbeatChecker::run3() 定时检查 OBServer 是否离线以及向离线的 OBServer 广播自己。
RS 需要 OBServer 汇报的信息都存在ObLeaseRequest里,server manager 将根据汇报的信息通过ObServerManager::receive_hb()更新到内存server_manager.server_statuses_里并提交异步任务持久化到 __all_server 表中。OBServer想要向 RS 请求的信息会被存放在ObLeaseResponse里。
我们为什么需要心跳?
首先,心跳最朴素的愿望就是如果 RS 发现某一个 OBServer 联系不上了,就不给它发请求 (e.g. 创建日志流)。
其次,OBServer 可以通过心跳及时给 RS 汇报自己的最新信息,便于 RS 及时做出决策。如 RS 通过汇报的 server_report_status_发现 OBServer 的磁盘出了问题,可以直接提交异步任务 Stop Server。
此外,如果 RS 发现某一个 OBServer 已经一个小时没有发过心跳了,就将这个 OBServer 的 HeartBeat Status 改为 OB_HEARTBEAT_PERMANENT_OFFLINE。为了保证高可用,负载均衡线程会将永久下线的 OBServer 上的资源迁移到其他地方。心跳在很多地方都发挥了重要的作用,此处就不一一列举了。
RS 请求 ObServer 发心跳汇报信息
RS会在两个时候向 OBServer 发 RPC 请求汇报。
- Cancel Delete Server 的时候,要发RPC看一下这个 OBServer 还在集群里而且还活着。但 OBServer 不发心跳也不影响取消删除,只会有一个LOG_WARN。
- RS 上任 (无论是 bootstrap 还是 new master_rs )的时候调用ObRootServerce::refresh_server()。
在发RPC的时候会发一个空的ObLeaseRequest到对应 OBServer,OBServer 将信息填入ObLeaseRequest中,server manager 根据收到ObLeaseRequest的时间和其携带的信息更新内存 server_statuses_和异步更新 __all_server 表,有的特殊变化也会有特殊处理。
int ObRootService::request_heartbeats(){ ObLeaseRequest lease_request; rpc_proxy_.to(status->server_).timeout(rpc_timeout). request_heartbeat(lease_request); server_manager_.receive_hb(lease_request, server_id, ...);}int ObService::request_heartbeat(ObLeaseRequest &lease_request){ heartbeat_process_.init_lease_request(lease_request); // 这个函数会将要汇报的信息装在 lease_request 里 // 如ip, zone, build_version_, resource_info_, server_status_ // start_service_time_, tenant_config_version, ...}int ObServerManager::receive_hb( const ObLeaseRequest &lease_request, uint64_t &server_id, bool &to_alive, bool &update_delay_time_flag){ // 只会处理白名单(server_manager.server_statuses_) // 内的 ObServer 发来的 lease_request // 更新 hb_status_ 为 OB_HEARTBEAT_ALIVE 和 last_hb_time_ // 根据 lease_request 更新内存的 server_statuses_ 和异步更新 __all_server表 // 特殊变化分情况处理 // 1 心跳重新变成 ALIVE,打开负载均衡 // 2 start_service_time 改变了,打开负载均衡 // 3 server_status_ 改变了, // LEASE_REQUEST_DATA_DISK_ERROR -> LEASE_REQUEST_NORMAL // 提交异步任务,Start Server // LEASE_REQUEST_NORMAL -> LEASE_REQUEST_DATA_DISK_ERROR // 提交异步任务, Stop Server} OBServer -> RS - OBServer 主动给 RS 发心跳
在 OBServer 刚启动的时候,它会在 ob_service_.start()通过 lease_state_mgr_.register_self_busy_wait()向 RS 发心跳,如果发不成功会刷新 RS 然后继续发心跳。第一次收到 RS 回复后,会加一个异步任务 hb_timer_.schedule(hb_, DELAY_TIME, repeat) 两秒后再向 RS 发心跳。这个异步任务执行的时候也会再往异步队列里扔一个任务,两秒后调用自己,所以 OBServer 每两秒向 RS 发一次心跳。
RS -> OBServer - RS 给 OBServer 发心跳
RS 每 100ms 通过ObHeartbeatChecker::run3()检查掉线的 OBServer,然后修改它们的 Heartbeat Status 并打开负载均衡。负载均衡的时候会将永久下线的 OBServer 的 Unit 重新分配到其它 OBServer 上。
Server 运维操作
除了通过心跳维护 OBServer 的一些信息以外,server manager 中最重要的还是对 Oberver 的运维操作。如Add,Delete,Cancel Delete,Stop,Isolate, Start。其中,因为 Delete 只是改掉 OBServer 的 Admin Status 而不是真正删除,所以还可以通过 Cancel Delete 来撤销 Delete 操作。Stop 和 Isolate 在 RS 中调用的是同样的接口ObRootService::stop_server(const obrpc::ObAdminServerArg &arg),区别是 Stop是 ObAdminServerArg::STOP,Isolate 是ObAdminServerArg::ISOLATE,Stop 的前置检查条件强于 Isolate。需要注意的是无论是 Stop 还是 Isolate,OBServer 都可以正常提供服务, 副本也还在这个 OBServer 上,只是 leader 被切走了。
Add Server - 添加 OBServer
顾名思义,就是将 OBServer 添加到集群中。启动二进制的时候可以在配置项里写rs_list,这样 OBServer 就可以及时找到 RS 并向其发心跳。
Delete Server - 删除 OBServer
这里的删掉并不是真正的删掉,而是将 OBServer 的 Admin Status 改为OB_ADMIN_DELETING,然后打开负载均衡 ObRootBalancer 线程,负载均衡线程检查到 OB_ADMIN_DELETING 状态或 OB_HEARTBEAT_PERMANENT_OFFLINE 状态的 OBServer 之后会将 Unit 迁走。随后,容灾模块会检测到副本当前所在 OBServer 和 Unit 所在 OBServer 不一致,就会触发迁移任务,把副本迁移到 Unit 所在 OBServer 上。ObEmptyServerChecker 线程检查到 OBServer 上没有 Unit 且 __all_ls_meta_table 没有这个 OBServer 上的日志流副本之后就把这个 OBServer 移出白名单。
这个时候可能会有一些特殊情况使得 __all_ls_meta_table 中的相关行删不干净,进而导致想要删掉的 OBServer 虽然状态已经是 OB_ADMIN_DELETING 了,但一直待在白名单里。
那什么叫没有删干净呢?在 OceanBase 4.0 中 __all_ls_meta_table 这张内部表记录了日志流的元信息,如果有兴趣的话可以查阅 ob_inner_table_scheme_def.py,这里面定义了所有内部表的 schema。在 __all_ls_meta_table 里,每一行都记录了某个租户下某一个日志流的某一个副本在哪一个 OBServer 上。所以如果可以从 __all_ls_meta_table 查到在这个 OBServer 上还有日志流副本,就说明没有删干净,在表里还有冗余信息。在 OceanBase 4.0 中,很多操作都依赖于查 __all_ls_meta_table,所以这里主要是为了保证后续的操作不要查错了。
为什么会导致没有删干净呢?有两种可能的原因:
- 清理 __all_ls_meta_table 里有关这个 OBServer 的行失败
- 发生永久下线之前,副本没有被迁移。__all_ls_meta_table 都是 OBServer 自己汇报上去的,永久下线之后再迁移无法汇报
在 OceanBase 4.0 中,有一个保证 __all_ls_meta_table 上的冗余信息一定会被删掉的机制,具体可以查看 ObLostReplicaChecker 这个线程。这个线程会清理 __all_ls_meta_table 里永久下线的 OBServer 对应的行,具体的逻辑可以看代码框里详细的描述。需要注意的是,由于 ObEmptyServerChecker 这个线程会把 Admin Status 为 OB_ADMIN_DELETING 且 Unit 迁移完成的 OBServer 的 force_stop_hb_ 置为 true,所以永久下线一定会发生。
// ALTER SYSTEM DELETE SERVERint ObRootService::delete_server(const obrpc::ObAdminServerArg &arg){ check_server_have_enough_resource_for_delete_server(); // 计算如果删掉这个 ObServer,它所在的 Zone 能不能装下它所有的 Unit check_all_ls_has_leader_(); // 通过查表检查是否所有的 ls 都有 leader,如果有的没有可能是虚表没有查到,也可能是无主, // 因为要有 leader 才可以 replica 迁移 // 要等一下,也可能 timeout server_manager_.delete_server(arg.servers_, arg.zone_); // 更新 __all_server 表里的状态为 OB_SERVER_DELETING // 更新内存里状态为 OB_SERVER_ADMIN_DELETING // 更新 __all_server 表,这里不是异步更新 // 但并没有在内存 server_statuses_ 里删掉 root_balancer_.wakeup(); // 这里会把状态为 OB_HEARTBEAT_PERMENENT_OFFLINE 或者 OB_SERVER_ADMIN_DELETING // 的 ObServer 上的 Unit 迁走 // 随后,容灾模块会检测到副本当前所在 ObServer 和 Unit 所在 ObServer 不一致, // 就会触发迁移任务,把副本迁移到 Unit 所在 ObServer 上。 empty_server_checker_.wakeup(); // 把状态为 OB_SERVER_ADMIN_DELETING 且没有 Unit 的 ObServer 添加到 empty_servers // empty_servers 里面装了即将被删除的 ObServer // 并将 force_stop_hb_ 设置为 true。 // 遍历每一个租户的每一个日志流副本对应的ls_info(查 __all_ls_meta_table) // 如果有日志流没有leader副本,那此时所有 ObServer 都不能被删掉 // 检查日志流是否清空 // 如果有日志流的 leader 副本 的 memberlist 存在于一个 empty_server 上 // 那这个 ObServer 就不能被删掉, 即从 empty_servers 里移除 // 如果有日志流的某一个副本存在于一个 empty_server 上 // 那这个 ObServer 就不能被删掉 // 真正删掉 empty_servers(end_delete_server()) // delete server working dir, 并不需要去ObServer上删掉 // 而是删掉 __all_space_usage 里这个 ObServer 上所有租户对应的行即可。 // 然后在 __all_server表里和内存里删掉这个 ObServer // 提交异步任务 server_change_callback_->on_server_change(); // 这个异步任务修改的是另一个内部表 lost_replica_checker_.wakeup(); // 发生永久下线之前,副本可能都已经迁移,对应内部表记录也被清理。但可能存在异常: // 内部表记录清理失败 // 发生永久下线之前,副本没有被迁移, // __all_ls_meta_table 都是 ObServer 自己汇报上去的,永久下线之后再删掉机器无法汇报 // 此时需要 RS 主动删除 __all_ls_meta_table 里的信息 // 判断一个日志流副本是否需要删除。前提都是该副本所在的 ObServer 已经处于永久下线 // 由于被删掉的 ObServer 的 force_stop_hb_ 一定会被置为 true, // 所以它一定会永久下线 // 遍历每一个租户的每一个日志流副本对应的ls_info(查 __all_ls_meta_table) // check_lost_replica_by_ls_(ls_info) // 如果这个日志流副本是 lost 的,那就在 __all_ls_meta_table 中删掉对应行 // lost = true 有以下两种情况 // 这个 replica 没有 in_service 且不是 paxos 副本 // 这个 replica 是in_service 且是 paxos 副本,但没有在 __all_ls_status 表上, // 如果还在 __all_ls_status 表上,会交给 remove_member 处理} Cancel Delete Server - 撤销删除 OBServer
Delete Server 之后可以 Cancel Delete。这个时候 OBServer 的force_stop_hb_会被置为false,Admin Status 会从 OB_SERVER_ADMIN_DELETING 变成了 OB_SERVER_ADMIN_NORMAL。
那什么时候可能会想要 Cancel Delete Server 呢?可能有这些情况:
- 删掉某一个 OBServer 的时候,负载均衡线程发现 Zone 内资源不够了(检查的时候还够,但负载均衡的时候发现不够了),这个时候就只能撤销删除。撤销删除的时候会停止 Unit 迁移。
- 操作失误,误删了机器
- ...
// ALTER SYSTEM CANCEL DELETE SERVERint ObRootService::cancel_delete_server(const obrpc::ObAdminServerArg &arg){ // ... server_manager_.set_force_stop_hb(arg.servers_[i], false); request_heartbeats(); // 这里请求 ObServer 发送心跳,不成功也没有关系,只是会多一个 LOG_WARN server_manager_.end_delete_server(arg.servers_[i], arg.zone_, false); // OB_SERVER_ADMIN_DELETING -> OB_SERVER_ADMIN_NORMAL // 更新 __all_server 表和内存 // 取消这个 ObServer 上的 Unit 迁移 root_balancer_.wakeup(); // 打开负载均衡
}
Stop Server - 停止 OBServerStop Server 这个操作意味什么呢?
- OBServer 被 Stop 后,所有 leader 在它上面的日志流副本都会发生切主,副本还在,只是从 leader 变成 follower
- OBProxy 不会给被已经 Stop 的 OBServer 转发读写请求
- 一个 OBServer 被成功 Stop 之后,我们可以安全地把它 kill 掉 -> 前置检查的条件很强,需要检查多数派和日志同步
这个操作一般什么时候需要呢?
- 硬件维修/更换/升级
- RS 发现磁盘出了故障主动提交异步任务
- 机器故障
- ...
在实际生产环境中,很有可能机器故障时运维人员想要 Stop 掉这个机器上的 OBServer,但因为故障导致所有工作线程卡死,日志无法同步,或者因为别的原因也无法达到多数派。但我们依然需要这个 OBServer 不再参与正常工作 (存在日志流 leader 副本 & 接收读写请求),那我们就需要另一个运维操作 Isolate Server。
Stop Server 的语义是 Stop 成功后我们可以安全 kill 掉这个 OBServer;Isolate Server 的语义是将 OBServer 上面的 ls leader 切换到其他机器上,但是不可以安全杀机器。它们在内部的表达都是 stop_time_不为 0,但前置检查条件不一样。
// ALTER SYSTEM STOP SERVER ...;
// 处理心跳时发现 server_status_ 从
// LEASE_REQUEST_NORMAL 变为 LEASE_REQUEST_DATA_DISK_ERROR
int ObRootService::stop_server(const obrpc::ObAdminServerArg &arg){ check_zone_and_server(); // arg里的 servers 都在同一个 Zone 而且存在没有被 Stop 掉的 ObServer 才能继续往下走 have_other_stop_task(); // 这里会检查其他 Zone 内是否有 stopped 的 ObServer或有不是 active 状态的其他 Zone // 如果有的话那就不可以 Stop // 只支持一个 Zone 内有多台 ObServer Stop // 不支持多个 Zone 内有 ObServer stop check_majority_and_log_in_sync_(); // 检查多数派和日志同步 // 这个不成功会一直重试,所以可能会 Timeout server_manager_.stop_server_list(); // 如果内存里 ObServer 的 stop_time_ 大于 0 了就什么都不做 // 否则更新 __all_server 表和内存里的 stop_time_ 为现在}需要注意的是, stop_time_不为 0 之后不代表 Stop 成功,我们可以安全 kill 掉这个 ObServer。在 SQL 层,还要检查到这个 ObServer 上的日志流 leader 副本数量为 0 之后才会返回用户成功。Isolate Server - 隔离 ObServer
Isolate Server 这个操作意味什么呢?
- OBServer 被 Isolate 后,所有 leader 在它上面的日志流副本都会发生切主,副本还在,只是从 leader 变成 follower
- OBProxy 不会给被 Isolate 的 OBServer 转发读写请求
其它的一些特点已经在上文中讨论过了。
// ALTER SYSTEM ISOLATE SERVER ...;int ObRootService::stop_server(const obrpc::ObAdminServerArg &arg){ check_zone_and_server(); // arg里的 ObServers 都在同一个 Zone // 而且存在没有被 Stop 掉的 ObServer 才能继续往下走 check_can_stop(); // 不能因为 Isolate 让 leader 迁移到非 Primary Zone 里 // leader 不在 Primary Zone 可能会导致网络开销过大 server_manager_.stop_server_list(); // 如果内存里 ObServer 的 stop_time_ 大于 0 了就什么都不做 // 否则更新 __all_server 表和内存里的 stop_time_ 为现在}Start Server - 启动 OBServer
Start Server 这个操作意味什么呢?
- OBServer 被 Start 后,可以有日志流的 leader 副本。
- OBProxy 可以给 OBServer 转发读写请求
那这个操作一般什么时候需要呢?
- OBServer 被 Stop / Isolate ,检查维修,问题解决之后可以再 Start
- RS 发现磁盘出了故障又恢复了主动提交异步任务
Server Stats in Memory - 内存中的 ObServer 信息
RS/Server manager在内存中将OBServer的信息放在server_manager_.server_statuses_ 里,这是一个 OBServerStatus 数组。每一个 OBServerStatus 都记录了集群中一个 OBServer 的信息。同时,server_manager_.server_statuses_ 也是一个白名单 (whitelist),RS/server manager 只会管理白名单中的 OBServer, 如果有不在白名单内的 OBServer 向 RS/server manager 发来请求,这个请求是不会被处理的。
以下介绍了 OBServerStatus 记录的 OBServer 的信息:
// 这里只展示了一部分 uint64_t id_; // id 会在 ObServer 被加到集群的时候分配 common::ObZone zone_; // 这个 ObServer 所在的zone char build_version_[common::OB_SERVER_VERSION_LENGTH]; common::ObAddr server_; // ObServer 的ip地址 int64_t sql_port_; // sql listen port int64_t last_hb_time_; // 上一次收到这个 ObServer 心跳的时刻 int64_t stop_time_; // ObServer 被 stop 的时间 int64_t start_service_time_; // ObServer 初始化后可以对外提供服务的时刻 ServerAdminStatus admin_status_; // Admin Status 下文中会介绍 HeartBeatStatus hb_status_; // Heartbeat Status 下文中会介绍 bool with_rootserver_; // true 则表明RS在这个ObServer上 bool force_stop_hb_; // 置为 true 后 server manager 将不会更新 last_hb_time_ ObServerResourceInfo resource_info_; // cpu, memory, disk, ... int64_t leader_cnt_; // 这个 ObServer 上 leader 副本的个数 int64_t server_report_status_; // LEASE_REQUEST_NORMAL or // LEASE_REQUEST_DATA_DISK_ERRORServer Stats in __all_server Table - 持久化的 ObServer 信息
为了保证新 RS 上任的时候可以和旧 RS 掌握尽可能相同的信息,每次更新 server_manager_.server_statuses_ 的时候也会提交异步任务 status_change_callback_->on_server_status_change()或者直接通过st_operator_.update()(st_operator 是操作 __all_server 表的 operator) 更新 __all_server 表。
以下介绍了 __all_server 表记录的 OBServer 的信息:
def_table_schema( table_name = '__all_server', table_id = '117', table_type = 'SYSTEM_TABLE', gm_columns = ['gmt_create', 'gmt_modified'], #gmt_modified就是last_hb_time_ rowkey_columns = [ ('svr_ip', 'varchar:MAX_IP_ADDR_LENGTH'), ('svr_port', 'int'), ], normal_columns = [ ('id', 'int'), ('zone', 'varchar:MAX_ZONE_LENGTH'), ('inner_port', 'int'), # sql_port_ ('with_rootserver', 'int'), ('status', 'varchar:OB_SERVER_STATUS_LENGTH'), # Display Status 下文中会介绍 ('block_migrate_in_time', 'int'), ('build_version', 'varchar:OB_SERVER_VERSION_LENGTH'), ('stop_time', 'int', 'false', '0'), ('start_service_time', 'int'), ('first_sessid', 'int', 'false', '0'), ('with_partition', 'int', 'false', '0'), ], )我们可以发现 __all_server 表的信息和内存中的信息并不是完全相同,例如 __all_server 表中的状态是 Display Status,但内存中却是 Admin Status 和 HeartBeat Status, 下文中会介绍它们之间的联系。此外,内存中记录了 OBServer 中的一些资源(磁盘,内存,CPU, ...)信息 resource_info_,也通过server_report_status_标记了磁盘是否有问题, 但 __all_server 表中却没有记录。新 RS 上任的时候会向集群内所有 ObServer 发 RPC 请求心跳,这些信息会随着心跳一起汇报上来。
新旧 RS 信息不一致会出现一些严重问题,如某一个 OBServer 在旧 RS 中已经被删掉了,但由于 __all_server 表没来得及更新, 新 RS 的白名单中还有这个 OBServer 。为了避免这些问题,RS 设计了多重机制确保 server_manager_.server_statuses_ 和 __all_server 表保持一致。
- Bootstrap/新 RS 上任的时候(server_manager_.load_server_manager()):读 __all_server_表,根据读到的信息更新 server_manager_.server_statuses_。
- RS 在服务过程中,每次更新 server_manager_.server_statuses_ 都会提交异步任务status_change_callback_->on_server_status_change()或者直接通过st_operator_.update()更新 __all_server 表。
- RS 中有一个定时任务 CheckAllServerTask ,这个任务每 30 秒执行一次,检测内存中的 OBServer 信息和 __all_server 表中是否有不一致,不一致会提交异步任务更新 __all_server 表。
- 直接的运维操作 ALTER SYSTEM RELOAD SERVER:读 __all_server_表,根据读到的信息更新 server_manager_.server_statuses_。
Server Status - OBServer 的状态
OBServer 有三种状态,分别是 Admin Status, HeartBeat Status 和 Display Status。其中,Admin Status 和 HeartBeat Status 是在内存里的, Display Status 是显示在 __all_server 表里的。内存里的状态和 __all_server 表里的状态可以互相推导。
Admin Status
Admin Status 表达了 OBServer 的添加/删除,下图表现了它的状态流转。需要注意的是,Delete Server 返回成功后,只代表在内存中这个 OBServer 的 Admin Status 变成了 OB_SERVER_ADMIN_DELETING。要等这个 OBServer 上的资源被清空之后,它才会被 RS 移出白名单。在被移出白名单之前,可以通过 Cancel Delete Server 撤销删除。
HeartBeat Status
HeartBeat Status 表达了 OBServer 和 RS 保持联系。RS 会定期检查 OBServer 是否发了心跳,如果距离上一次收到这个 OBServer 心跳过了 10 秒,那么这个 OBServer 的 HeartBeat Status 就会被改为OB_HEARTBEAT_LEASE_EXPIRED。如果距离上一次收到这个 OBServer 心跳已经过了1小时 (这个时间在配置项里可以改),那这个 OBServer 的HeartBeat Status就会被改为OB_HEARTBEAT_PERMANENT_OFFLINE。具体的检查和不同HeartBeat Status下的 OBServer 管理逻辑将在 RS->OBServer 中进行讨论。
Display Status
顾名思义,展示在 __all_server 表里的 OBServer 状态。我们也可以通过 Display Status 和 last_hb_time_反推出 Admin Status 和 HeartBeat Status。

需要注意的是,OB_Server_DELETING 不能反推出 HeartBeat Status,但是 Delete Server 的时候会把force_stop_hb_置为true,一小时后就会永久下线。Stop Server 在心跳中同样没有体现,是 Stop Server 返回成功后把这个 OBServer 进程真正 kill 掉,一小时后 RS 就会让这个 OBServer 永久下线。
Bootstrap - 集群自举
这一小节简要概述了 bootstrap,重点是和 server manager 或者心跳有关的部分, 其它部分可能没有提及。
在 OceanBase 中, bootstrap 的运维命令是:
// 举例,三个Zone的情况下ALTER SYSTEM BOOTSTRAP ZONE 'xxxx1' SERVER 'xxx.xxx.xx.xx1:xxxx', ZONE 'xxxx2' SERVER 'xxx.xxx.xx.xx2:xxxx', ZONE 'xxxx3' SERVER 'xxx.xxx.xx.xx3:xxxx'; 这三个 OBServer 会组成一个 rs_list。如下图所示 (图中的箭头只代表参与的情况,不一定是发 RPC), bootstrap 的时候用户的 bootstrap 命令会发到链接串上的 OBServer,这个 OBServer 会执行 OBService::bootstrap()。首先它会在rs_list里的三个 OBServer 上创建系统日志流,等待系统日志流选 leader。系统日志流 leader 所在的 OBServer 就是 master_rs。链接串上的 OBServer 会给 master_rs 发 RPC 执行 OBRootService::execute_bootstrap()。
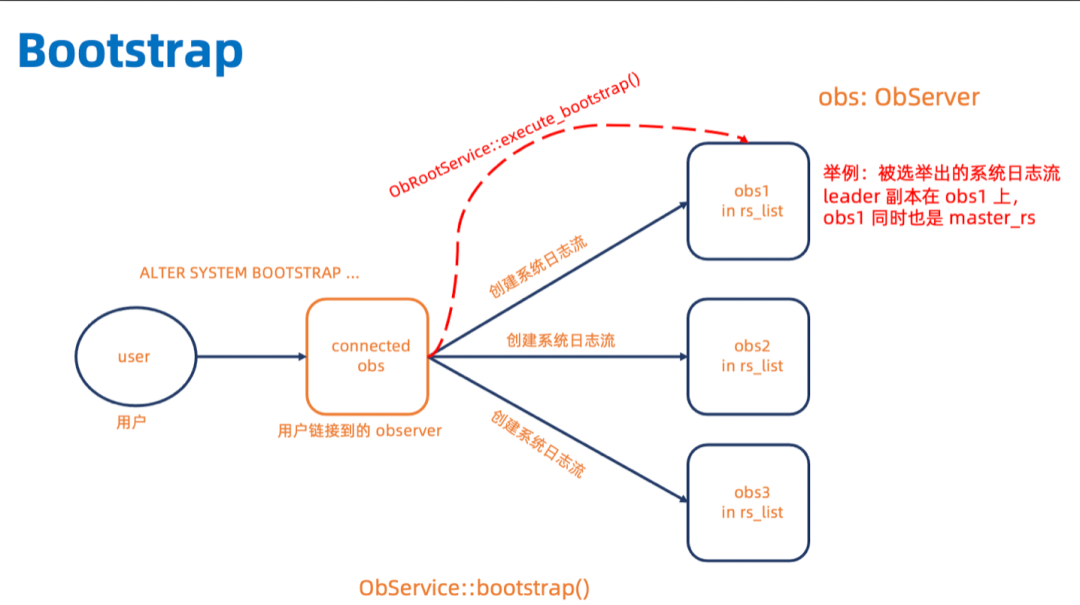
master_rs 先等 rs_list 上所有的 OBServer 给自己发送心跳,当确认它们都在线 (HeartBeat Status 都为 OB_HEARTBEAT_ALIVE)之后,再创建内部表的 schema。
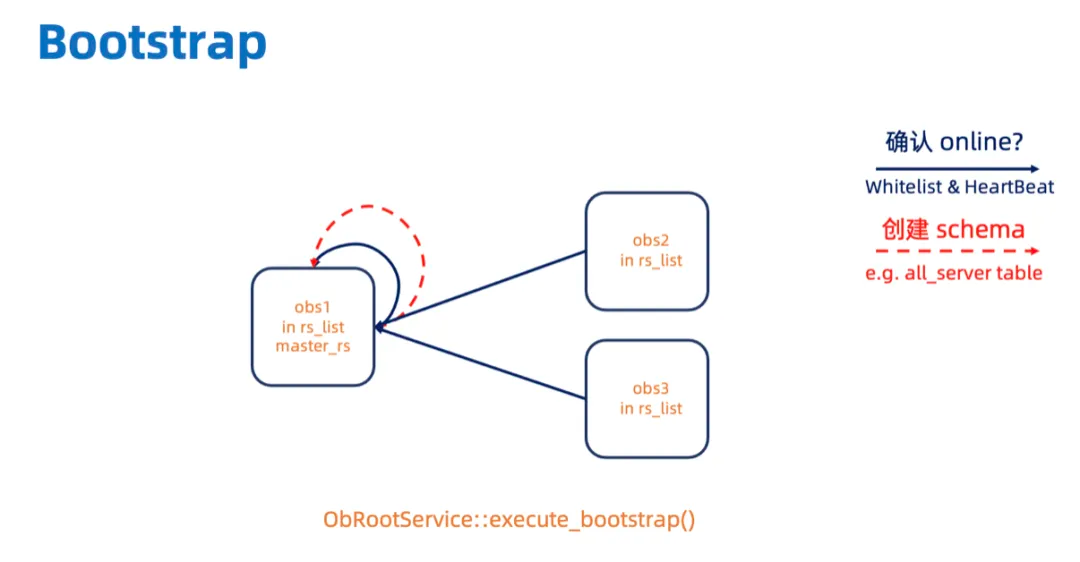
然后 master_rs 会等 rs_list 上所有的 OBServer 都提供服务 (start_service_time_大于 0) 之后,在执行 do_restart(),启动 RS 所提供的服务。
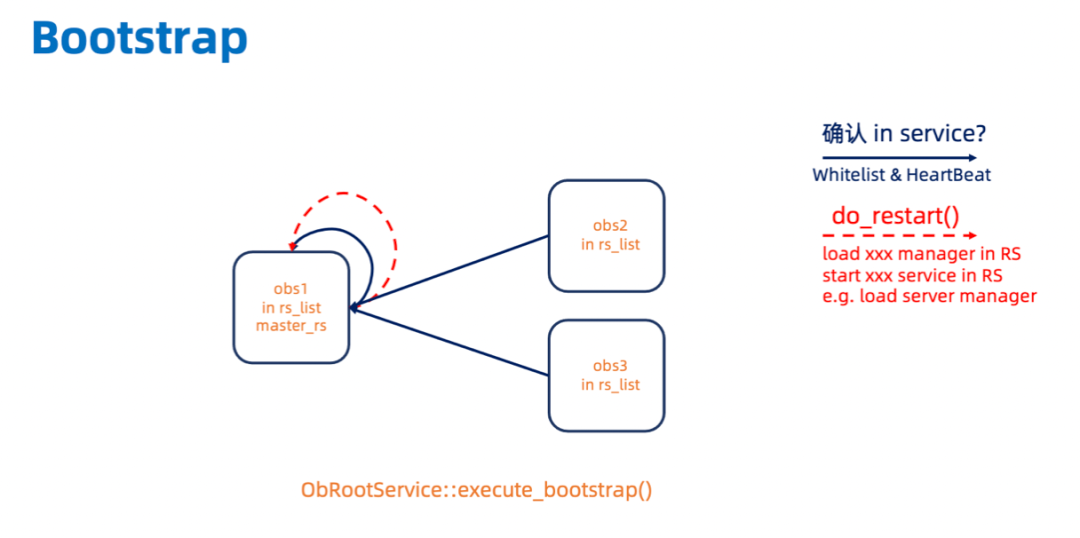
需要注意的是,bootstrap阶段只会将rs_list里的OBServer添加到内存server_manager_.server_statuses_及持久化到 __all_server表里,集群里剩下的 OBServer 需要通过 Add Server 的运维命令手动添加。
int ObRootService::execute_bootstrap(const obrpc::ObBootstrapArg &arg){ // ... bootstrap.execute_bootstrap(); do_restart(); // ...
}int ObBootstrap::execute_bootstrap(){ // ... add_rs_list(); // 将 rs_list 加载到 server_manager 的白名单 server_statuses_ 里 // 此时它们的 heartbeat status 是 OB_HEARTBEAT_LEASE_EXPIRED // 后续的步骤中很多地方都对白名单有依赖 // 如只处理白名单里的 ObServer 发来的心跳 wait_all_rs_online(); // 等待rs_list里的 ObServer 的 heartbeat status 变为 OB_HEARTBEAT_ALIVE // 收到心跳的时候创建异步任务,将 ObServer 信息写入 __all_server 表 // 这个异步任务会一直重试到成功为止 // 此时系统表还未创建,所以需要等到系统表创建完成之后这个任务才会成功 // ... create_all_schema(); // 内部表创建完成,之前的异步任务现在开始可以执行成功了 // ... wait_all_rs_in_service(); // 等待 rs_list 里的 ObServer 开始提供服务 // 即内存里的 start_service_time_ 变得大于 0 // ...}int ObRootService::do_restart() { // ... update_rs_list() // 配置项同步逻辑 // 修改 server config 里的 rootservice_list // 并更新到内部表 __all_sys_parameter 里 // 之后讨论心跳会用到这里 refresh_server(); // 这里会 load_server_manager() // 即将创建系统表后写到 __all_server 表里的信息再读回到内存里 // ...}在ObBootstrap::execute_bootstrap()中,wait_all_rs_online()是等待 rs_list 里的 OBServer 的heartbeat status变成OB_HEARTBEAT_ALIVE;wait_all_rs_in_service()是等待 rs_list 里的 OBServer 的start_service_time_变得大于 0。以下代码展示了 OBServer 从发心跳到开启服务中间的历程。
新RS上任
RS 是在系统日志流 leader 所在 OBServer 上的一组服务,当系统日志流的 leader 位置改变时, RS 也会跟着改变。RS 新 leader 上任的时候会 load server manager。首先是通过ObRootServiceMonitor::monitor_root_service()发现自己现在变成了 leader,然后将 RS 的状态改为 IN_SERVICE 并添加异步任务 ObRestartTask。这个异步任务执行的时候会调用 ObRootService::do_restart() 打开 RS 的各种服务并将 RS 状态置为FULL_SERVICE。
HeartBeat - 心跳
本章首先介绍了我们为什么需要心跳,然后讨论了心跳的发送和 server manager 通过心跳对 OBServer 进行管理。RS 在需要的时候通过 ObRootService::request_heartbeats() 向 ObServer 发 RPC 请求汇报。OBServer 定时通过 ObLeaseStateMgr::renew_lease() 主动向 RS 发送心跳进行汇报。RS也会通过 ObHeartbeatChecker::run3() 定时检查 OBServer 是否离线以及向离线的 OBServer 广播自己。
RS 需要 OBServer 汇报的信息都存在ObLeaseRequest里,server manager 将根据汇报的信息通过ObServerManager::receive_hb()更新到内存server_manager.server_statuses_里并提交异步任务持久化到 __all_server 表中。OBServer想要向 RS 请求的信息会被存放在ObLeaseResponse里。
我们为什么需要心跳?
首先,心跳最朴素的愿望就是如果 RS 发现某一个 OBServer 联系不上了,就不给它发请求 (e.g. 创建日志流)。
其次,OBServer 可以通过心跳及时给 RS 汇报自己的最新信息,便于 RS 及时做出决策。如 RS 通过汇报的 server_report_status_发现 OBServer 的磁盘出了问题,可以直接提交异步任务 Stop Server。
此外,如果 RS 发现某一个 OBServer 已经一个小时没有发过心跳了,就将这个 OBServer 的 HeartBeat Status 改为 OB_HEARTBEAT_PERMANENT_OFFLINE。为了保证高可用,负载均衡线程会将永久下线的 OBServer 上的资源迁移到其他地方。心跳在很多地方都发挥了重要的作用,此处就不一一列举了。
RS 请求 ObServer 发心跳汇报信息
RS会在两个时候向 OBServer 发 RPC 请求汇报。
- Cancel Delete Server 的时候,要发RPC看一下这个 OBServer 还在集群里而且还活着。但 OBServer 不发心跳也不影响取消删除,只会有一个LOG_WARN。
- RS 上任 (无论是 bootstrap 还是 new master_rs )的时候调用ObRootServerce::refresh_server()。
在发RPC的时候会发一个空的ObLeaseRequest到对应 OBServer,OBServer 将信息填入ObLeaseRequest中,server manager 根据收到ObLeaseRequest的时间和其携带的信息更新内存 server_statuses_和异步更新 __all_server 表,有的特殊变化也会有特殊处理。
int ObRootService::request_heartbeats(){ ObLeaseRequest lease_request; rpc_proxy_.to(status->server_).timeout(rpc_timeout). request_heartbeat(lease_request); server_manager_.receive_hb(lease_request, server_id, ...);}int ObService::request_heartbeat(ObLeaseRequest &lease_request){ heartbeat_process_.init_lease_request(lease_request); // 这个函数会将要汇报的信息装在 lease_request 里 // 如ip, zone, build_version_, resource_info_, server_status_ // start_service_time_, tenant_config_version, ...}int ObServerManager::receive_hb( const ObLeaseRequest &lease_request, uint64_t &server_id, bool &to_alive, bool &update_delay_time_flag){ // 只会处理白名单(server_manager.server_statuses_) // 内的 ObServer 发来的 lease_request // 更新 hb_status_ 为 OB_HEARTBEAT_ALIVE 和 last_hb_time_ // 根据 lease_request 更新内存的 server_statuses_ 和异步更新 __all_server表 // 特殊变化分情况处理 // 1 心跳重新变成 ALIVE,打开负载均衡 // 2 start_service_time 改变了,打开负载均衡 // 3 server_status_ 改变了, // LEASE_REQUEST_DATA_DISK_ERROR -> LEASE_REQUEST_NORMAL // 提交异步任务,Start Server // LEASE_REQUEST_NORMAL -> LEASE_REQUEST_DATA_DISK_ERROR // 提交异步任务, Stop Server} OBServer -> RS - OBServer 主动给 RS 发心跳
在 OBServer 刚启动的时候,它会在 ob_service_.start()通过 lease_state_mgr_.register_self_busy_wait()向 RS 发心跳,如果发不成功会刷新 RS 然后继续发心跳。第一次收到 RS 回复后,会加一个异步任务 hb_timer_.schedule(hb_, DELAY_TIME, repeat) 两秒后再向 RS 发心跳。这个异步任务执行的时候也会再往异步队列里扔一个任务,两秒后调用自己,所以 OBServer 每两秒向 RS 发一次心跳。
RS -> OBServer - RS 给 OBServer 发心跳
RS 每 100ms 通过ObHeartbeatChecker::run3()检查掉线的 OBServer,然后修改它们的 Heartbeat Status 并打开负载均衡。负载均衡的时候会将永久下线的 OBServer 的 Unit 重新分配到其它 OBServer 上。
Server 运维操作
除了通过心跳维护 OBServer 的一些信息以外,server manager 中最重要的还是对 Oberver 的运维操作。如Add,Delete,Cancel Delete,Stop,Isolate, Start。其中,因为 Delete 只是改掉 OBServer 的 Admin Status 而不是真正删除,所以还可以通过 Cancel Delete 来撤销 Delete 操作。Stop 和 Isolate 在 RS 中调用的是同样的接口ObRootService::stop_server(const obrpc::ObAdminServerArg &arg),区别是 Stop是 ObAdminServerArg::STOP,Isolate 是ObAdminServerArg::ISOLATE,Stop 的前置检查条件强于 Isolate。需要注意的是无论是 Stop 还是 Isolate,OBServer 都可以正常提供服务, 副本也还在这个 OBServer 上,只是 leader 被切走了。
Add Server - 添加 OBServer
顾名思义,就是将 OBServer 添加到集群中。启动二进制的时候可以在配置项里写rs_list,这样 OBServer 就可以及时找到 RS 并向其发心跳。
Delete Server - 删除 OBServer
这里的删掉并不是真正的删掉,而是将 OBServer 的 Admin Status 改为OB_ADMIN_DELETING,然后打开负载均衡 ObRootBalancer 线程,负载均衡线程检查到 OB_ADMIN_DELETING 状态或 OB_HEARTBEAT_PERMANENT_OFFLINE 状态的 OBServer 之后会将 Unit 迁走。随后,容灾模块会检测到副本当前所在 OBServer 和 Unit 所在 OBServer 不一致,就会触发迁移任务,把副本迁移到 Unit 所在 OBServer 上。ObEmptyServerChecker 线程检查到 OBServer 上没有 Unit 且 __all_ls_meta_table 没有这个 OBServer 上的日志流副本之后就把这个 OBServer 移出白名单。
这个时候可能会有一些特殊情况使得 __all_ls_meta_table 中的相关行删不干净,进而导致想要删掉的 OBServer 虽然状态已经是 OB_ADMIN_DELETING 了,但一直待在白名单里。
那什么叫没有删干净呢?在 OceanBase 4.0 中 __all_ls_meta_table 这张内部表记录了日志流的元信息,如果有兴趣的话可以查阅 ob_inner_table_scheme_def.py,这里面定义了所有内部表的 schema。在 __all_ls_meta_table 里,每一行都记录了某个租户下某一个日志流的某一个副本在哪一个 OBServer 上。所以如果可以从 __all_ls_meta_table 查到在这个 OBServer 上还有日志流副本,就说明没有删干净,在表里还有冗余信息。在 OceanBase 4.0 中,很多操作都依赖于查 __all_ls_meta_table,所以这里主要是为了保证后续的操作不要查错了。
为什么会导致没有删干净呢?有两种可能的原因:
- 清理 __all_ls_meta_table 里有关这个 OBServer 的行失败
- 发生永久下线之前,副本没有被迁移。__all_ls_meta_table 都是 OBServer 自己汇报上去的,永久下线之后再迁移无法汇报
在 OceanBase 4.0 中,有一个保证 __all_ls_meta_table 上的冗余信息一定会被删掉的机制,具体可以查看 ObLostReplicaChecker 这个线程。这个线程会清理 __all_ls_meta_table 里永久下线的 OBServer 对应的行,具体的逻辑可以看代码框里详细的描述。需要注意的是,由于 ObEmptyServerChecker 这个线程会把 Admin Status 为 OB_ADMIN_DELETING 且 Unit 迁移完成的 OBServer 的 force_stop_hb_ 置为 true,所以永久下线一定会发生。
// ALTER SYSTEM DELETE SERVERint ObRootService::delete_server(const obrpc::ObAdminServerArg &arg){ check_server_have_enough_resource_for_delete_server(); // 计算如果删掉这个 ObServer,它所在的 Zone 能不能装下它所有的 Unit check_all_ls_has_leader_(); // 通过查表检查是否所有的 ls 都有 leader,如果有的没有可能是虚表没有查到,也可能是无主, // 因为要有 leader 才可以 replica 迁移 // 要等一下,也可能 timeout server_manager_.delete_server(arg.servers_, arg.zone_); // 更新 __all_server 表里的状态为 OB_SERVER_DELETING // 更新内存里状态为 OB_SERVER_ADMIN_DELETING // 更新 __all_server 表,这里不是异步更新 // 但并没有在内存 server_statuses_ 里删掉 root_balancer_.wakeup(); // 这里会把状态为 OB_HEARTBEAT_PERMENENT_OFFLINE 或者 OB_SERVER_ADMIN_DELETING // 的 ObServer 上的 Unit 迁走 // 随后,容灾模块会检测到副本当前所在 ObServer 和 Unit 所在 ObServer 不一致, // 就会触发迁移任务,把副本迁移到 Unit 所在 ObServer 上。 empty_server_checker_.wakeup(); // 把状态为 OB_SERVER_ADMIN_DELETING 且没有 Unit 的 ObServer 添加到 empty_servers // empty_servers 里面装了即将被删除的 ObServer // 并将 force_stop_hb_ 设置为 true。 // 遍历每一个租户的每一个日志流副本对应的ls_info(查 __all_ls_meta_table) // 如果有日志流没有leader副本,那此时所有 ObServer 都不能被删掉 // 检查日志流是否清空 // 如果有日志流的 leader 副本 的 memberlist 存在于一个 empty_server 上 // 那这个 ObServer 就不能被删掉, 即从 empty_servers 里移除 // 如果有日志流的某一个副本存在于一个 empty_server 上 // 那这个 ObServer 就不能被删掉 // 真正删掉 empty_servers(end_delete_server()) // delete server working dir, 并不需要去ObServer上删掉 // 而是删掉 __all_space_usage 里这个 ObServer 上所有租户对应的行即可。 // 然后在 __all_server表里和内存里删掉这个 ObServer // 提交异步任务 server_change_callback_->on_server_change(); // 这个异步任务修改的是另一个内部表 lost_replica_checker_.wakeup(); // 发生永久下线之前,副本可能都已经迁移,对应内部表记录也被清理。但可能存在异常: // 内部表记录清理失败 // 发生永久下线之前,副本没有被迁移, // __all_ls_meta_table 都是 ObServer 自己汇报上去的,永久下线之后再删掉机器无法汇报 // 此时需要 RS 主动删除 __all_ls_meta_table 里的信息 // 判断一个日志流副本是否需要删除。前提都是该副本所在的 ObServer 已经处于永久下线 // 由于被删掉的 ObServer 的 force_stop_hb_ 一定会被置为 true, // 所以它一定会永久下线 // 遍历每一个租户的每一个日志流副本对应的ls_info(查 __all_ls_meta_table) // check_lost_replica_by_ls_(ls_info) // 如果这个日志流副本是 lost 的,那就在 __all_ls_meta_table 中删掉对应行 // lost = true 有以下两种情况 // 这个 replica 没有 in_service 且不是 paxos 副本 // 这个 replica 是in_service 且是 paxos 副本,但没有在 __all_ls_status 表上, // 如果还在 __all_ls_status 表上,会交给 remove_member 处理} Cancel Delete Server - 撤销删除 OBServer
Delete Server 之后可以 Cancel Delete。这个时候 OBServer 的force_stop_hb_会被置为false,Admin Status 会从 OB_SERVER_ADMIN_DELETING 变成了 OB_SERVER_ADMIN_NORMAL。
那什么时候可能会想要 Cancel Delete Server 呢?可能有这些情况:
- 删掉某一个 OBServer 的时候,负载均衡线程发现 Zone 内资源不够了(检查的时候还够,但负载均衡的时候发现不够了),这个时候就只能撤销删除。撤销删除的时候会停止 Unit 迁移。
- 操作失误,误删了机器
- ...
// ALTER SYSTEM CANCEL DELETE SERVERint ObRootService::cancel_delete_server(const obrpc::ObAdminServerArg &arg){ // ... server_manager_.set_force_stop_hb(arg.servers_[i], false); request_heartbeats(); // 这里请求 ObServer 发送心跳,不成功也没有关系,只是会多一个 LOG_WARN server_manager_.end_delete_server(arg.servers_[i], arg.zone_, false); // OB_SERVER_ADMIN_DELETING -> OB_SERVER_ADMIN_NORMAL // 更新 __all_server 表和内存 // 取消这个 ObServer 上的 Unit 迁移 root_balancer_.wakeup(); // 打开负载均衡
}
Stop Server - 停止 OBServerStop Server 这个操作意味什么呢?
- OBServer 被 Stop 后,所有 leader 在它上面的日志流副本都会发生切主,副本还在,只是从 leader 变成 follower
- OBProxy 不会给被已经 Stop 的 OBServer 转发读写请求
- 一个 OBServer 被成功 Stop 之后,我们可以安全地把它 kill 掉 -> 前置检查的条件很强,需要检查多数派和日志同步
这个操作一般什么时候需要呢?
- 硬件维修/更换/升级
- RS 发现磁盘出了故障主动提交异步任务
- 机器故障
- ...
在实际生产环境中,很有可能机器故障时运维人员想要 Stop 掉这个机器上的 OBServer,但因为故障导致所有工作线程卡死,日志无法同步,或者因为别的原因也无法达到多数派。但我们依然需要这个 OBServer 不再参与正常工作 (存在日志流 leader 副本 & 接收读写请求),那我们就需要另一个运维操作 Isolate Server。
Stop Server 的语义是 Stop 成功后我们可以安全 kill 掉这个 OBServer;Isolate Server 的语义是将 OBServer 上面的 ls leader 切换到其他机器上,但是不可以安全杀机器。它们在内部的表达都是 stop_time_不为 0,但前置检查条件不一样。
// ALTER SYSTEM STOP SERVER ...;
// 处理心跳时发现 server_status_ 从
// LEASE_REQUEST_NORMAL 变为 LEASE_REQUEST_DATA_DISK_ERROR
int ObRootService::stop_server(const obrpc::ObAdminServerArg &arg){ check_zone_and_server(); // arg里的 servers 都在同一个 Zone 而且存在没有被 Stop 掉的 ObServer 才能继续往下走 have_other_stop_task(); // 这里会检查其他 Zone 内是否有 stopped 的 ObServer或有不是 active 状态的其他 Zone // 如果有的话那就不可以 Stop // 只支持一个 Zone 内有多台 ObServer Stop // 不支持多个 Zone 内有 ObServer stop check_majority_and_log_in_sync_(); // 检查多数派和日志同步 // 这个不成功会一直重试,所以可能会 Timeout server_manager_.stop_server_list(); // 如果内存里 ObServer 的 stop_time_ 大于 0 了就什么都不做 // 否则更新 __all_server 表和内存里的 stop_time_ 为现在}需要注意的是, stop_time_不为 0 之后不代表 Stop 成功,我们可以安全 kill 掉这个 ObServer。在 SQL 层,还要检查到这个 ObServer 上的日志流 leader 副本数量为 0 之后才会返回用户成功。Isolate Server - 隔离 ObServer
Isolate Server 这个操作意味什么呢?
- OBServer 被 Isolate 后,所有 leader 在它上面的日志流副本都会发生切主,副本还在,只是从 leader 变成 follower
- OBProxy 不会给被 Isolate 的 OBServer 转发读写请求
其它的一些特点已经在上文中讨论过了。
// ALTER SYSTEM ISOLATE SERVER ...;int ObRootService::stop_server(const obrpc::ObAdminServerArg &arg){ check_zone_and_server(); // arg里的 ObServers 都在同一个 Zone // 而且存在没有被 Stop 掉的 ObServer 才能继续往下走 check_can_stop(); // 不能因为 Isolate 让 leader 迁移到非 Primary Zone 里 // leader 不在 Primary Zone 可能会导致网络开销过大 server_manager_.stop_server_list(); // 如果内存里 ObServer 的 stop_time_ 大于 0 了就什么都不做 // 否则更新 __all_server 表和内存里的 stop_time_ 为现在}Start Server - 启动 OBServer
Start Server 这个操作意味什么呢?
- OBServer 被 Start 后,可以有日志流的 leader 副本。
- OBProxy 可以给 OBServer 转发读写请求
那这个操作一般什么时候需要呢?
- OBServer 被 Stop / Isolate ,检查维修,问题解决之后可以再 Start
- RS 发现磁盘出了故障又恢复了主动提交异步任务
// ALTER SYSTEM START SERVER ...;
// 处理心跳时发现 server_status_ 从
// LEASE_REQUEST_DATA_DISK_ERROR 变为 LEASE_REQUEST_NORMAL
int ObRootService::start_server(const obrpc::ObAdminServerArg &arg)
{
server_manager_.start_server_list(arg.servers_, arg.zone_);
// start_server(*server, zone)
// 如果内存里 ObServer 的 stop_time_ 已经是 0 了就什么都不做
// 否则更新 __all_server 表和内存里的 stop_time_ 为 0
}// ALTER SYSTEM START SERVER ...;
// 处理心跳时发现 server_status_ 从
// LEASE_REQUEST_DATA_DISK_ERROR 变为 LEASE_REQUEST_NORMAL
int ObRootService::start_server(const obrpc::ObAdminServerArg &arg)
{
server_manager_.start_server_list(arg.servers_, arg.zone_);
// start_server(*server, zone)
// 如果内存里 ObServer 的 stop_time_ 已经是 0 了就什么都不做
// 否则更新 __all_server 表和内存里的 stop_time_ 为 0
}