




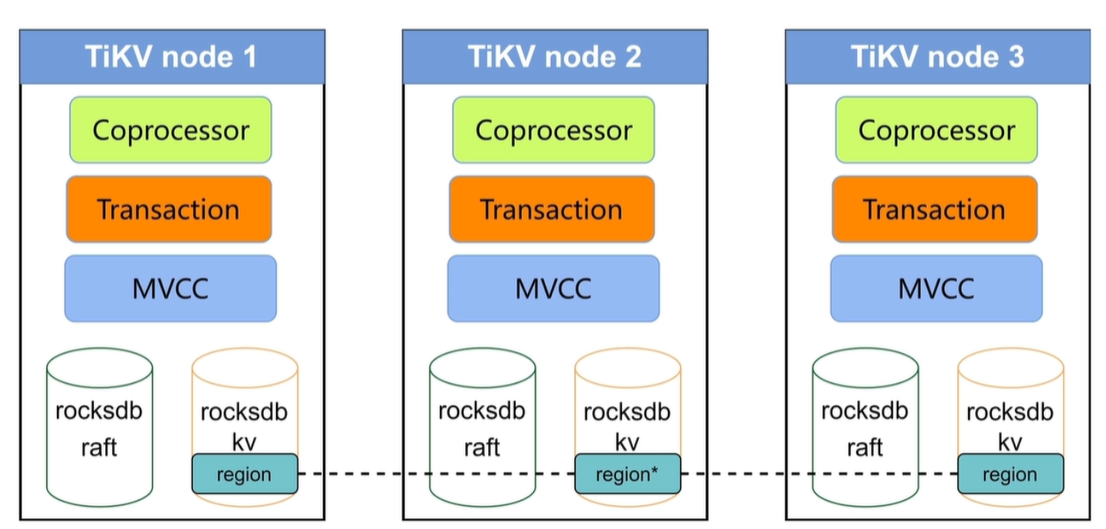
TiKV 架构和作用
RocksDB:
RocksDB 针对 Flash 存储进行优化,延迟极小,使用LSM存储引擎
- 高性能的Key-Value数据库
- 完善的持久化机制,同时保证性能和安全性
- 良好的支持范围查询
- 为需要存储TB级别数据到本地FLASH或者RAM的应用服务器设计
- 针对存储在告诉设备的中小键值进行优化--可以存储在FLASH或者直接存储在内存
- 性能随CPU数量线性提升,对多核系统友好
RocksDB:写入
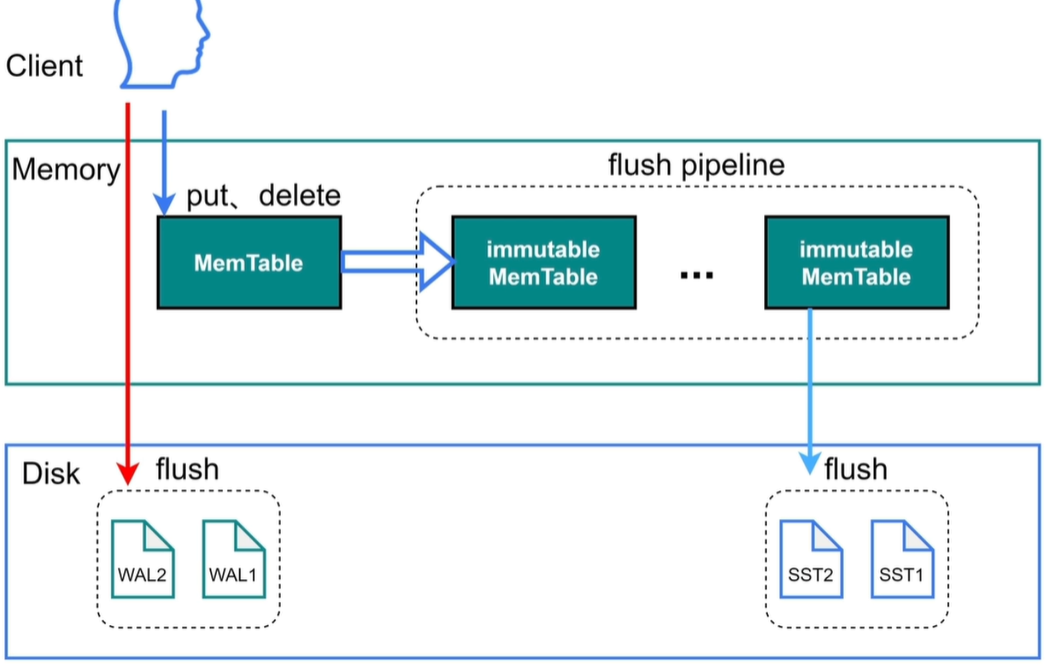
PS:当sync_log=true时日志不会经过操作系统的缓存,直接向磁盘写入。
write_buffer_size —— 达到此参数大小就会将MemTable转存到immutable中,不能修改。
write stall:当immutable有5个时会认为写入过快,会对写限速。

PS:level 0是原文件,默认当原文件有4个时会进行compaction。对SST进行查找会使用二分查找(因为SST是排好序的)
compaction:对文件进行合并、压缩、排序。
当level 1有256M时,继续将level1向下合并排序。
RocksDB查询
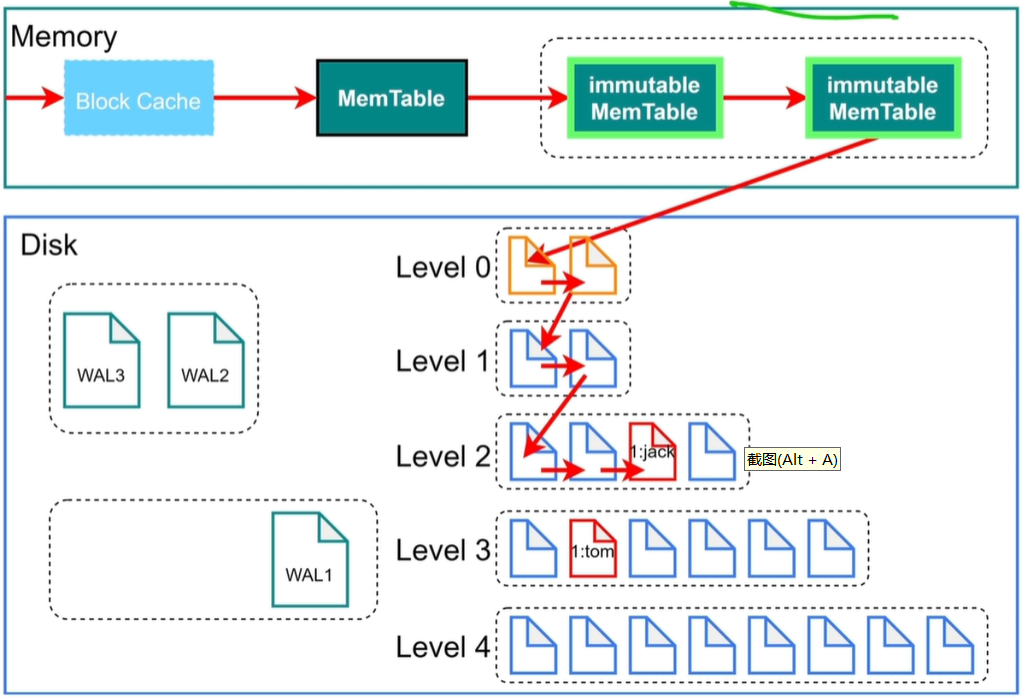
PS:对于范围查找会查看键值,键值,如果键值在里面就使用二分查找法进行查找,如果不在继续向别的文件查找。
bloom filter:布隆过滤器,判断值在不在文件中,不在肯定不在,在也不一定在。
RocksDB:Column Families
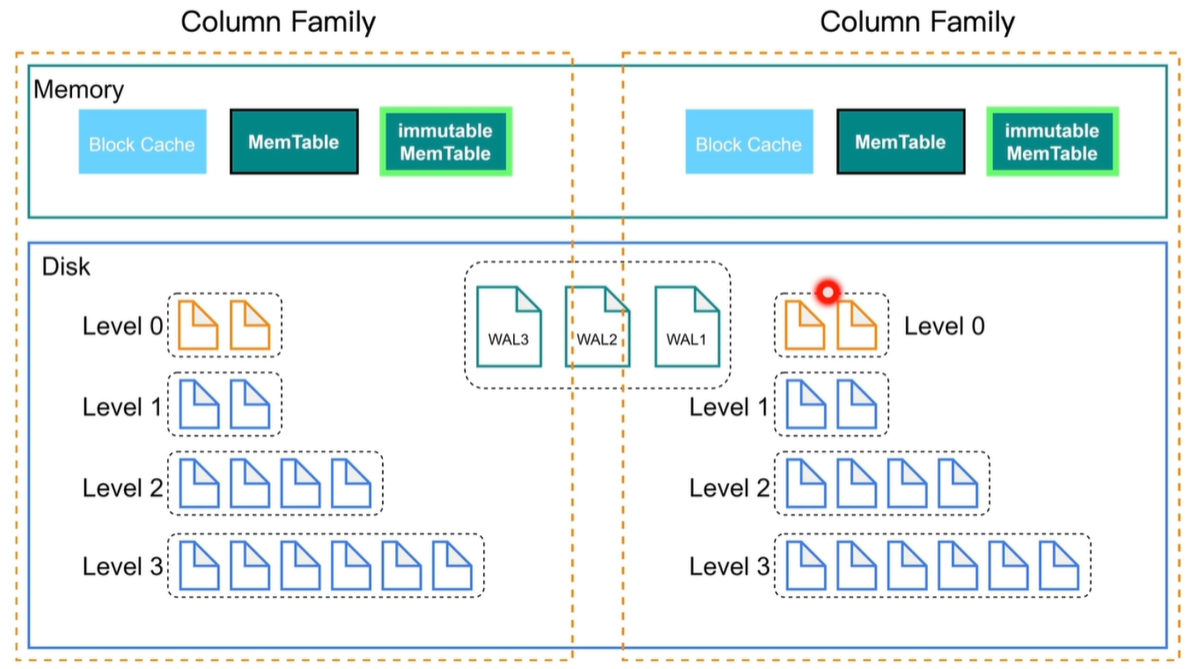
数据分片技术
分布式事务
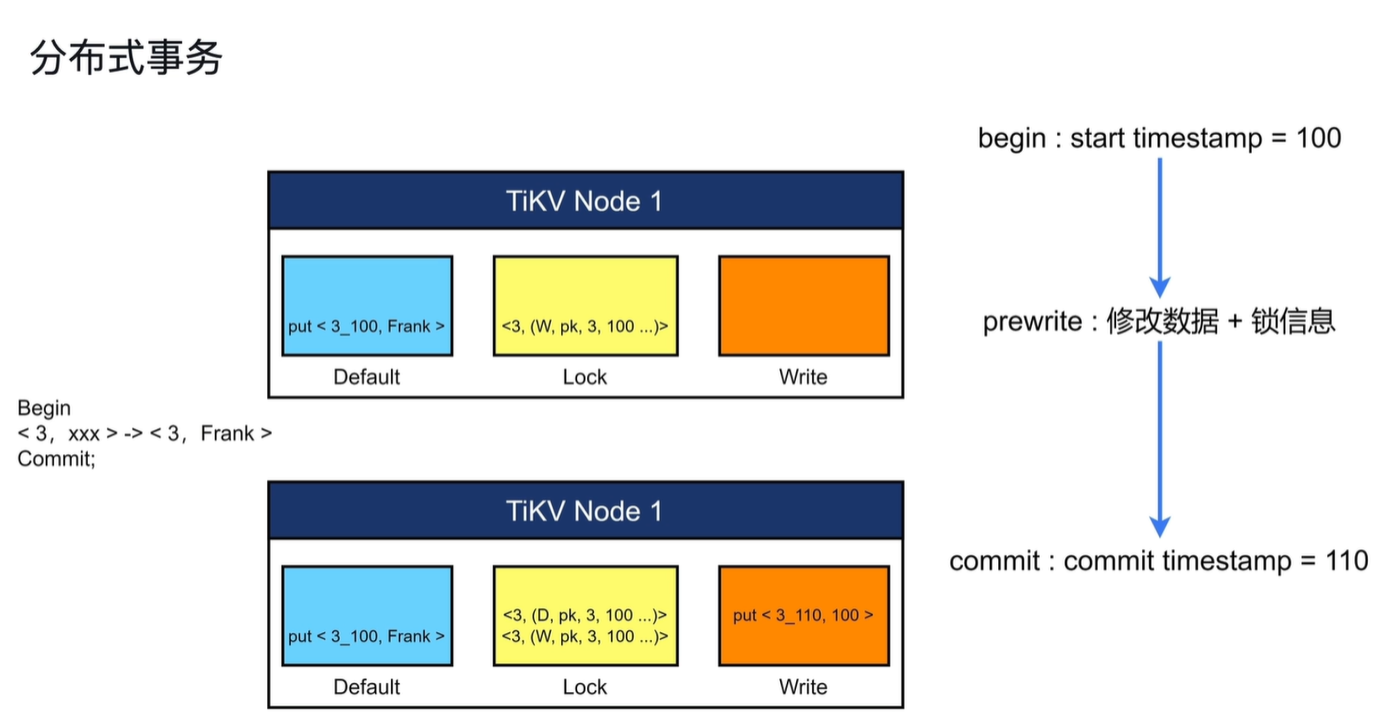
事务提交流程:
首先会获得一个start timestamp = 100(事务开始时间)
其次修改数据(Default)+锁信息(Lock)
最后获得事务结束的版本号,写入write列(提交信息),删除锁
当业务读数据时会先查找write列中的信息,其次查看其锁信息,如果write列有信息并且没有锁就可以读取该数据。
- write列:当用户写入一行数据时,如果改行数据长度小于255字节,那么就会存储在write列中
- Default列:用于存储超过255字节长度的数据
TiKV-Raft
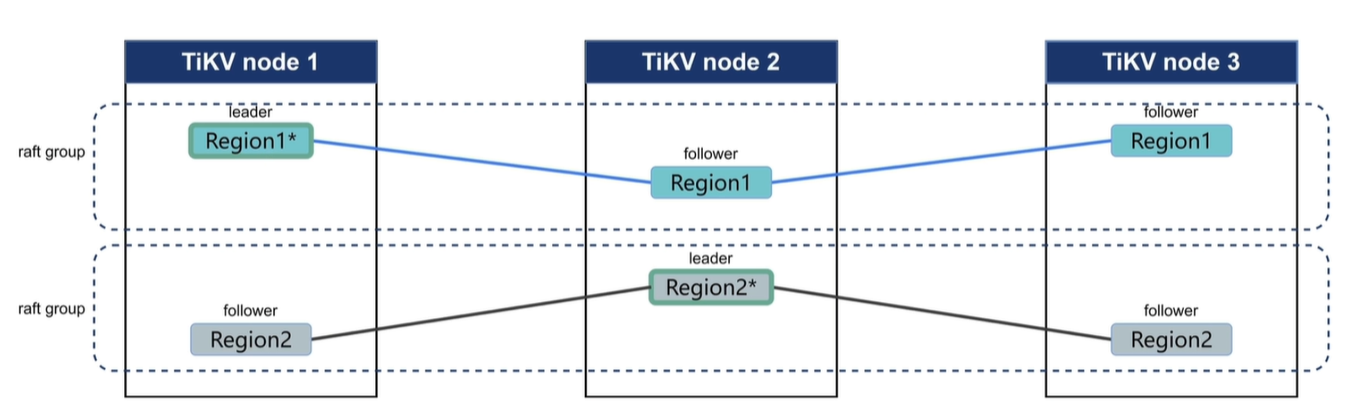
Region在多副本中会有一个leader副本,leader副本是集群中的管理者,读写都走leader,并且会定期给follower发送心跳信息告诉从副本我是leader。leader的修改信息会以日志的方式传输到其他follower上以维持数据库的一致性。
当follower长时间未收到leader的信息是就会将自己转化为candidate,重新投票选举新的leader。
- 当一个Regino的写入信息达到96MB时就会开启下一个Regino继续写入。
- 当一个Region插入信息过多使其达到144MB时就会分裂成两个Region。
- 当一个Region经过太多删除小于设定阈值时会将其合并。
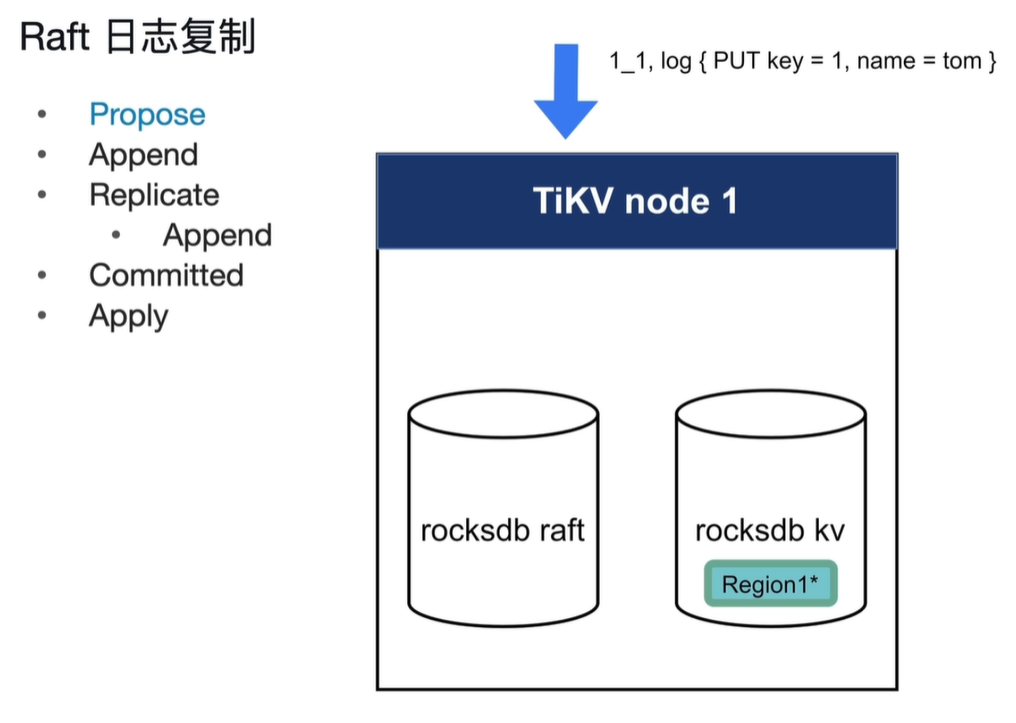
rocksdb raft:持久化日志
rocksdb kv:存放数据
- Propose:客户端写入一条日志
- Append:将日志持久化到raft中,只在leader节点持久化
- Replicate:将主leader的日志复制到其他节点,其中Append在其他节点中进行
- Committed:当其他节点(超过一般以上)持久化之后返回持久化成功后就Committed。此committed与应用程序的意义不一样
- Apply:将数据写入rocksdb kv

当第一个node率先突破election_timeout值时成为candidate,并且将term改为2,发起投票选举新的leader。当其他节点收到投票信息后发现candidate的term值大于自己则投票。满足多数派则成为leader。
heartbeat_time_interval:当上个收到心跳的时间距现在超过此参数值时会打破现在的关系将自己变为candidate,重新发起投票。满足多数派则自己变为leader。
如果当多个节点成为candidate,则重新发起选举。election_timeout可以设置为一个区间,每次在区间内随机取值,这样就可以减少有多个candidate出现的情况。
参数对应:
Election timeout: raft-election-timeout-ticks
Heartbeat time interval: raft_heartbeat-ticks
raft_heartbeat-ticks *raft-base-tick-interval //ticks是个数的意思代表多少个时间
raft-election-timeout-ticks *raft-base-tick-interval
TiKV- 读写与 Coprocessor
此处不包含MVCC和锁的情况
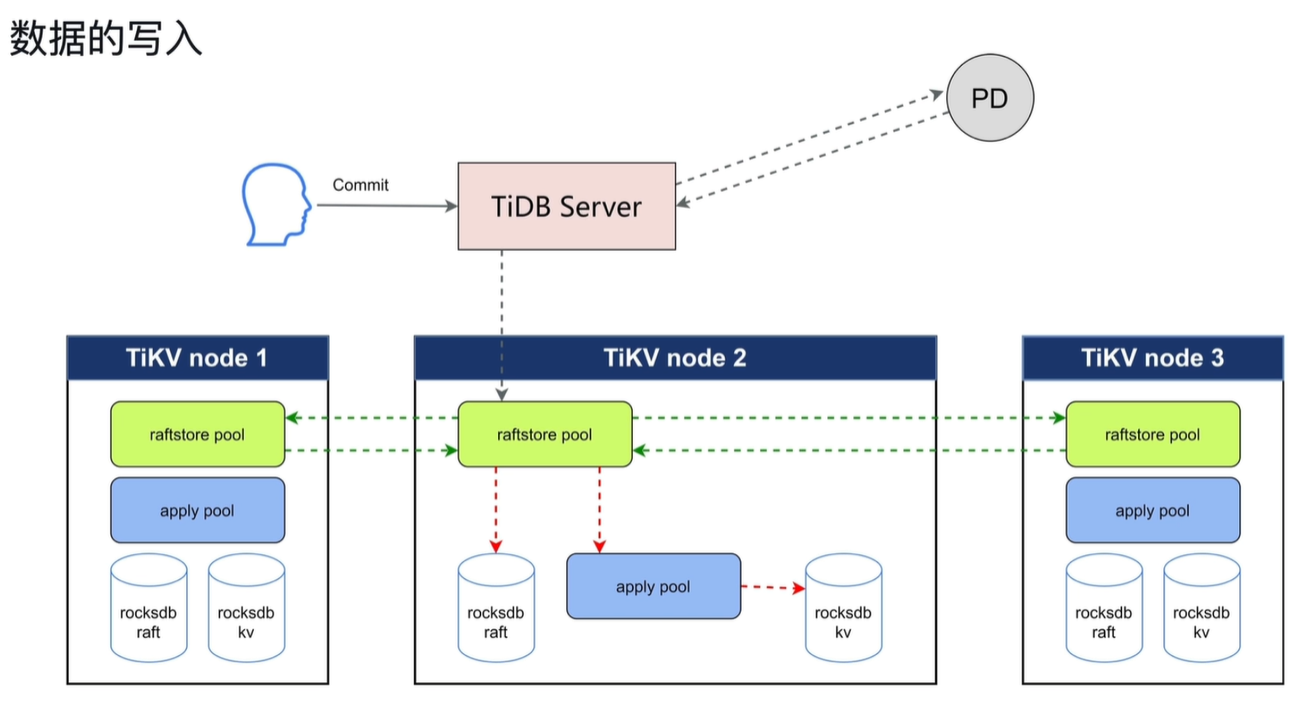
raftstore pool:将写请求转化成raft日志,做持久化。并且同时将日志发送到其他节点的raftstore pool进行持久化。
apply pool:日志持久化后拿着此日志将其写入rocksdb kv中。
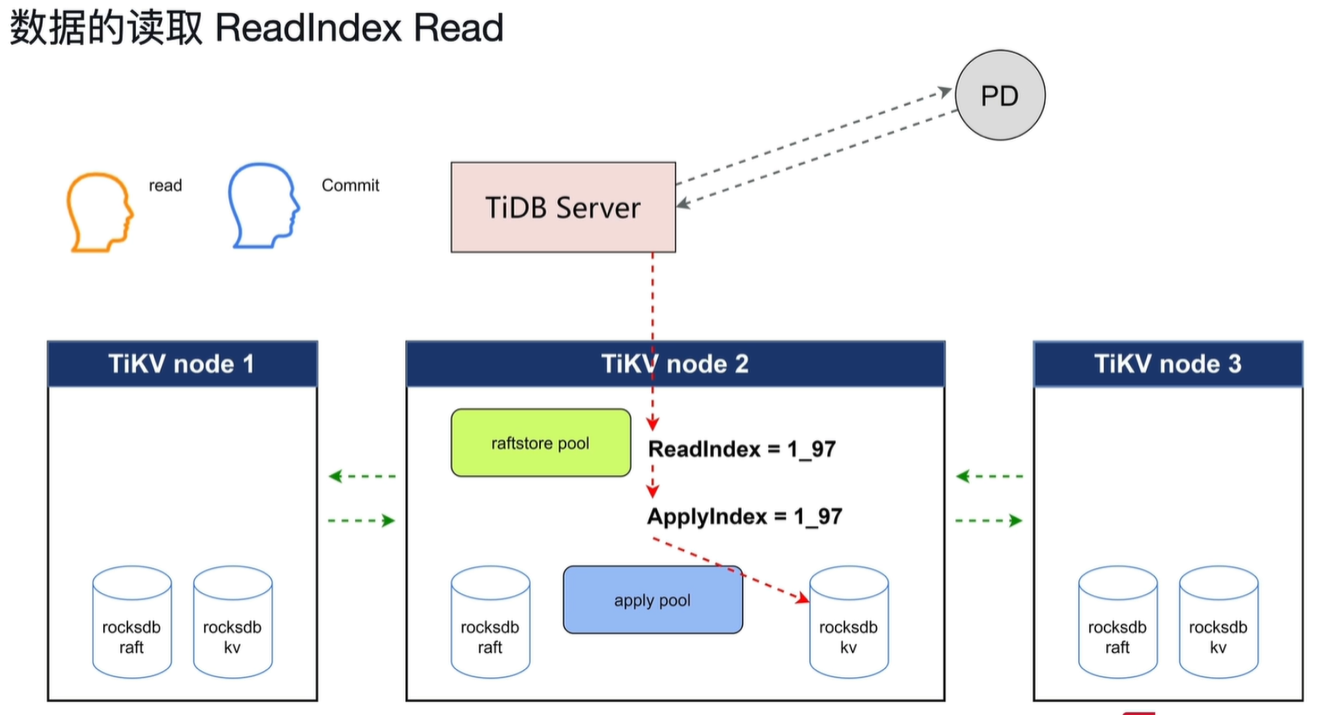
问题一:当读取时会先向PD发送请求确定leader副本在那个node上,收到PD的信息后再开始向leader所在的node中读取。如果当收到PD信息进行读取时发生leader副本切换该怎么办。
答:读取前leader所在的node会向其他node发送心跳信息确定自己是不是leader,之后在开始读取。发送过心跳信息后就不会发生leader切换。
问题二:用户1在10:00提交了数据,用户2在10:05能不能读取到用户1提交的数据。怎么维持线性一致性。
答:
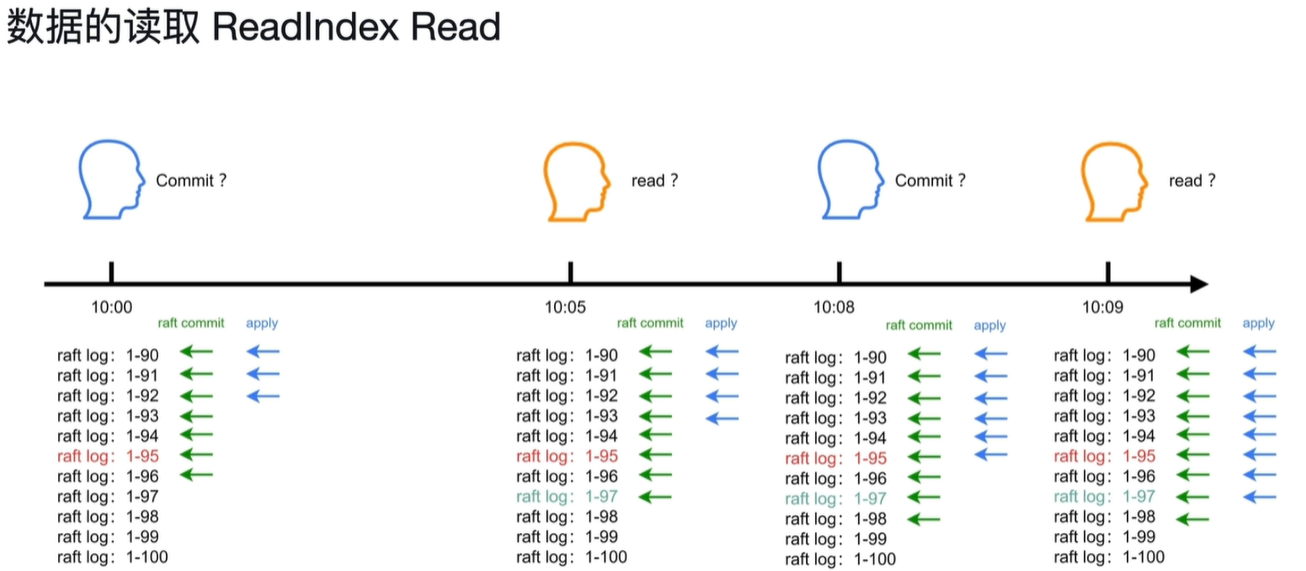
当读取开始时会设置最新raft commit的值为Readindex,当apply到Readindex的值时才开始读取,这样就一定会读到已经提交的数据。
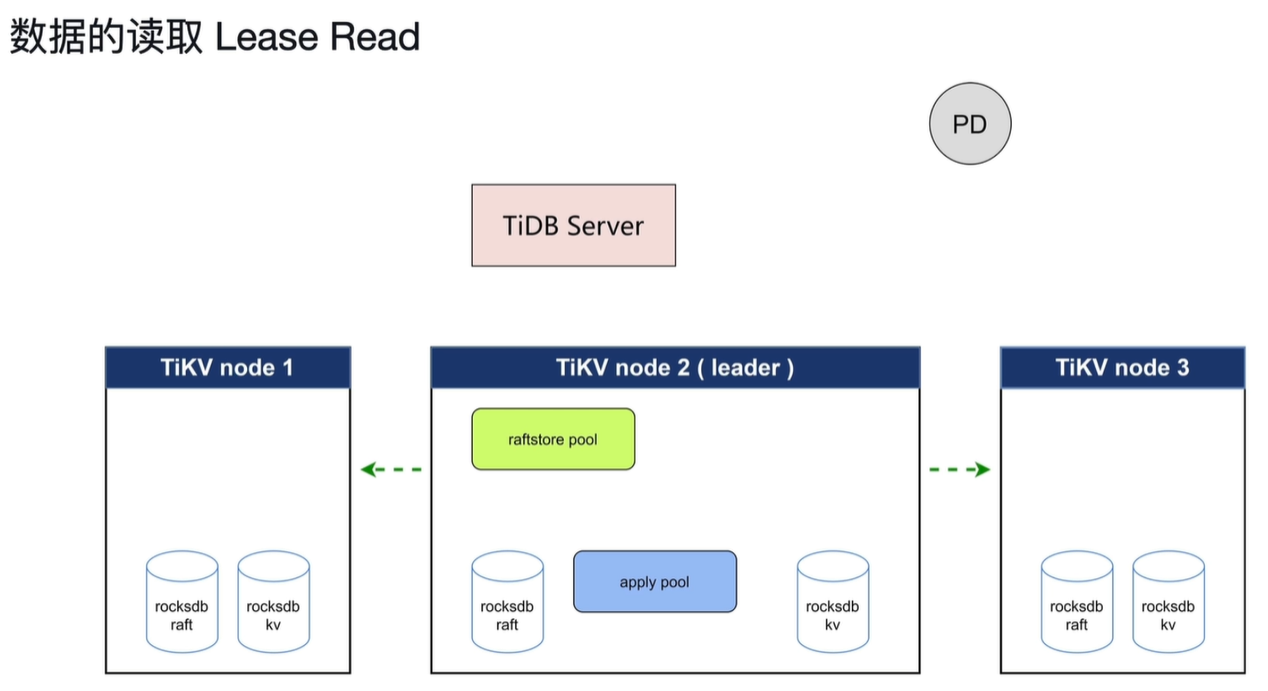
当读取时需先发心跳,有一定的网络延迟,所以会造成一定的读的延迟。
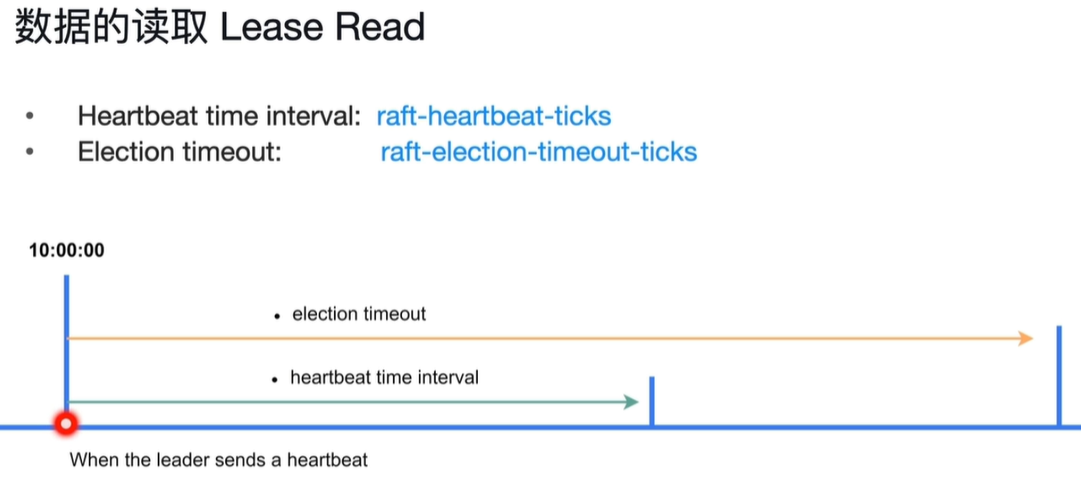
当10:00时会发出心跳数据,在下面那条线期间不会发生选举,并且在这段时间内不用发心跳。只有过了Election timeout这段时间过后才会发生leader选举。
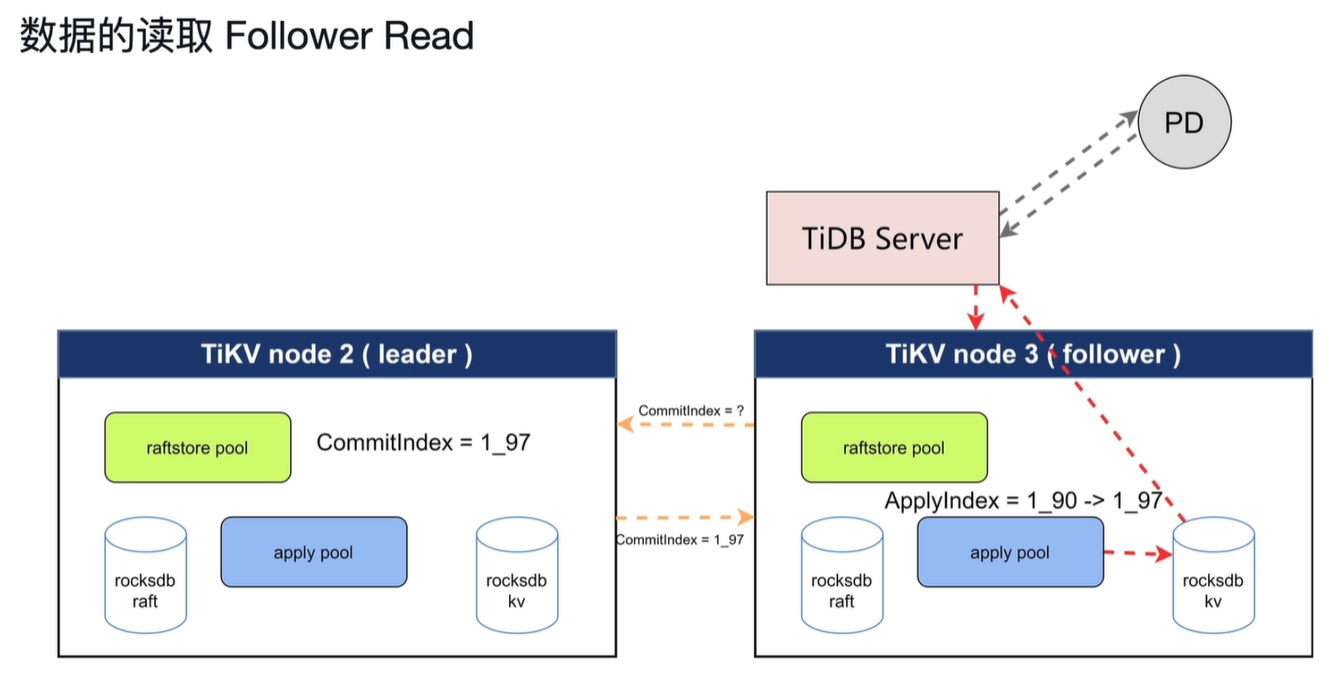
读取follower的数据,减轻leader的压力。但是会产生主从不一定同步apply这样的问题。所以会先从leader获取Commitindex的数据,直到follower的apply到Commitindex的值时开始读取。
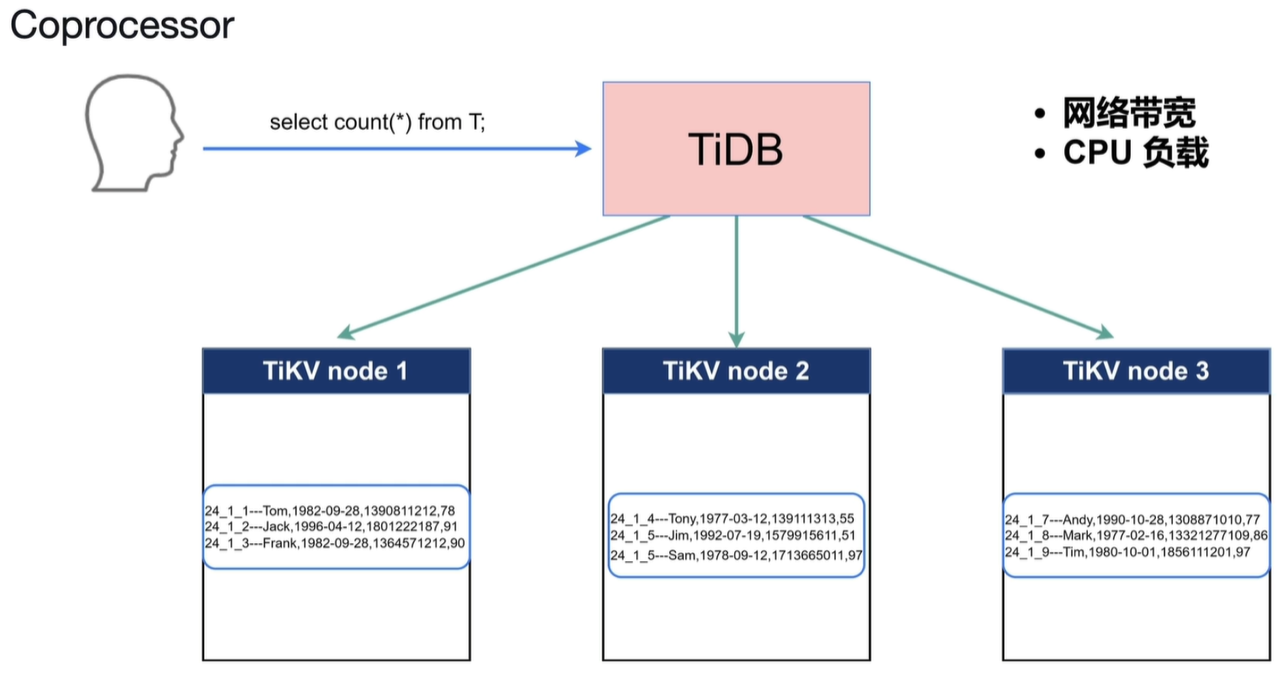
解决当如上情况出现时会有大量数据向TiDB聚合,增大开销。这时候Coprocessor(协同处理器)会在当前节点计算,将计算结果发往TiDB中。TiDB收到数据会进行简单的二次整理,大大减轻了TiDB的计算和网络开销。
表扫,索引扫,过滤,聚合等都会进行算子下推。
TiKV 架构和作用
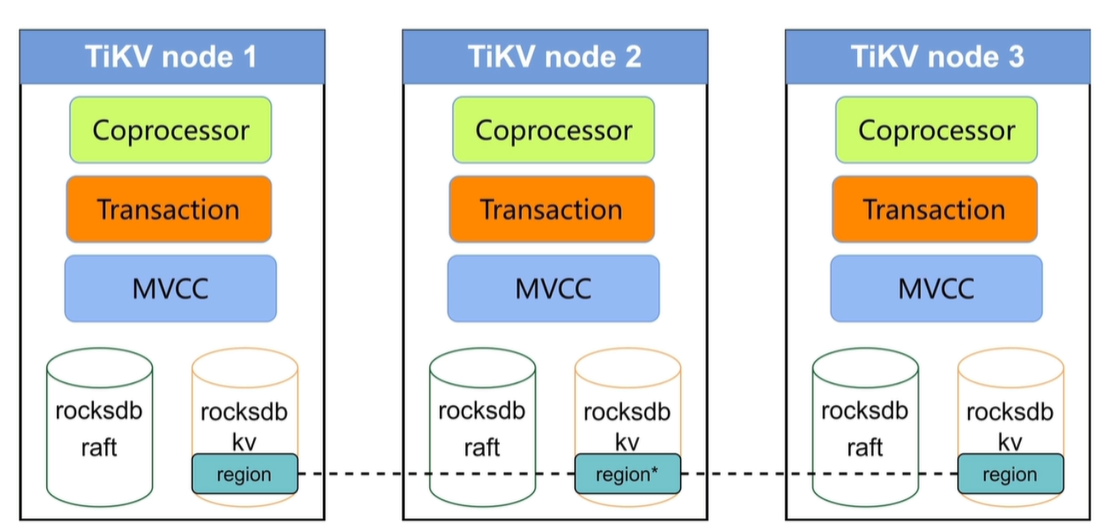
RocksDB:
RocksDB 针对 Flash 存储进行优化,延迟极小,使用LSM存储引擎
- 高性能的Key-Value数据库
- 完善的持久化机制,同时保证性能和安全性
- 良好的支持范围查询
- 为需要存储TB级别数据到本地FLASH或者RAM的应用服务器设计
- 针对存储在告诉设备的中小键值进行优化--可以存储在FLASH或者直接存储在内存
- 性能随CPU数量线性提升,对多核系统友好
RocksDB:写入
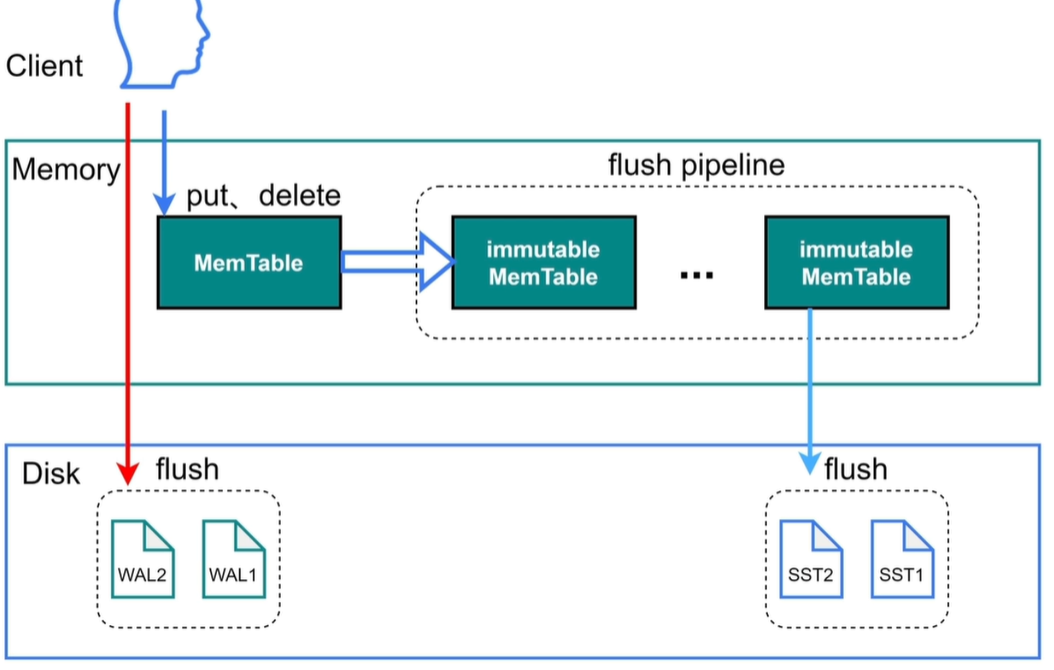
PS:当sync_log=true时日志不会经过操作系统的缓存,直接向磁盘写入。
write_buffer_size —— 达到此参数大小就会将MemTable转存到immutable中,不能修改。
write stall:当immutable有5个时会认为写入过快,会对写限速。
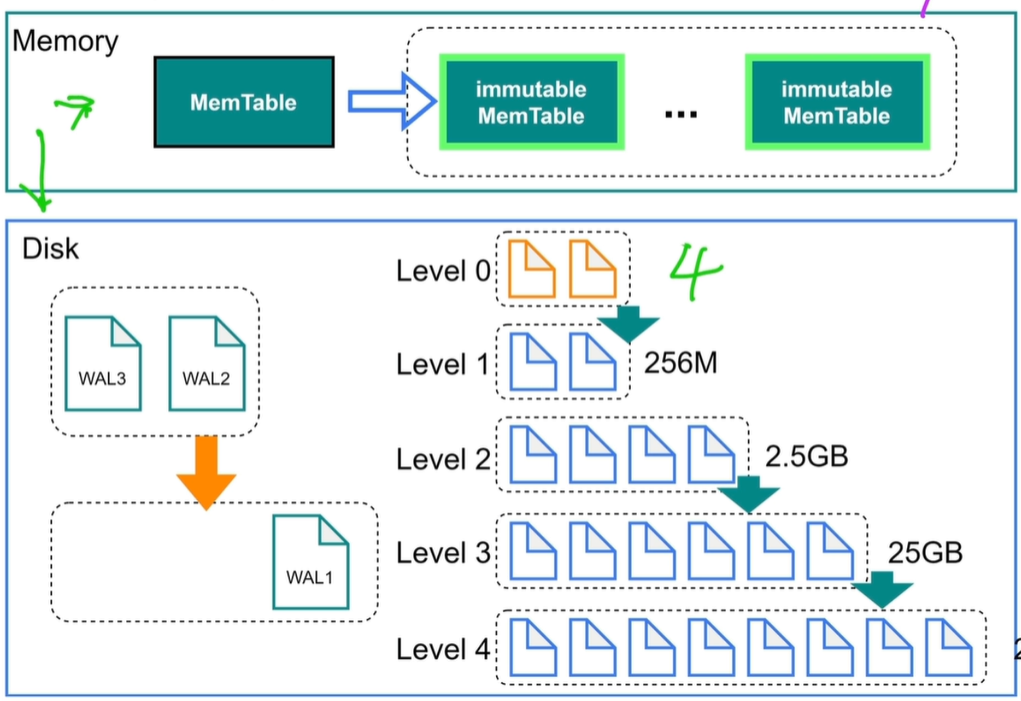
PS:level 0是原文件,默认当原文件有4个时会进行compaction。对SST进行查找会使用二分查找(因为SST是排好序的)
compaction:对文件进行合并、压缩、排序。
当level 1有256M时,继续将level1向下合并排序。
RocksDB查询
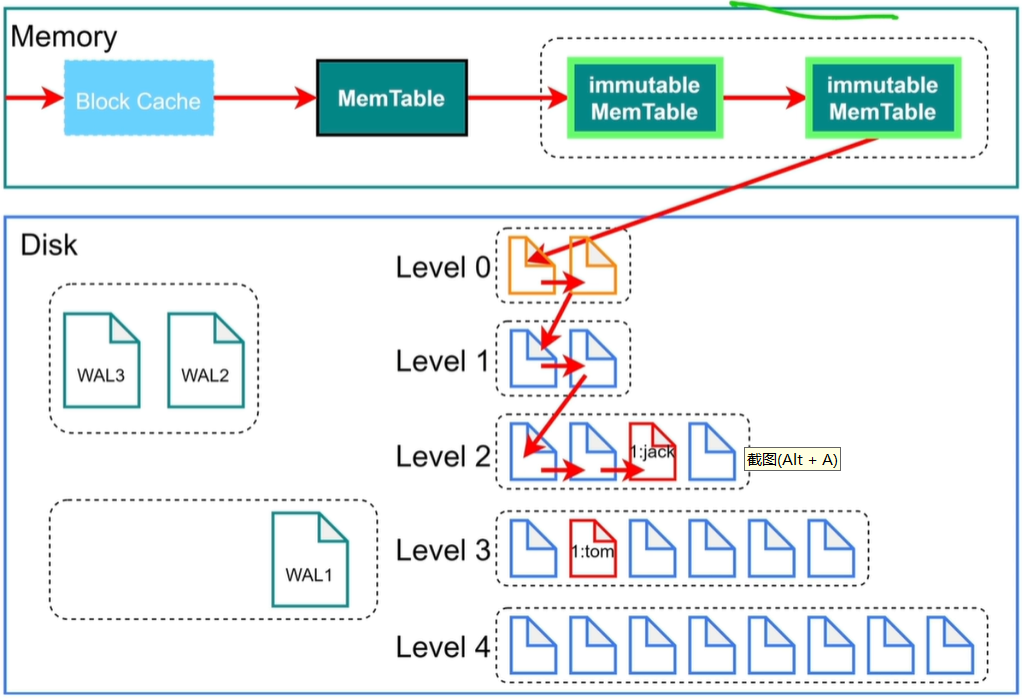
PS:对于范围查找会查看键值,键值,如果键值在里面就使用二分查找法进行查找,如果不在继续向别的文件查找。
bloom filter:布隆过滤器,判断值在不在文件中,不在肯定不在,在也不一定在。
RocksDB:Column Families
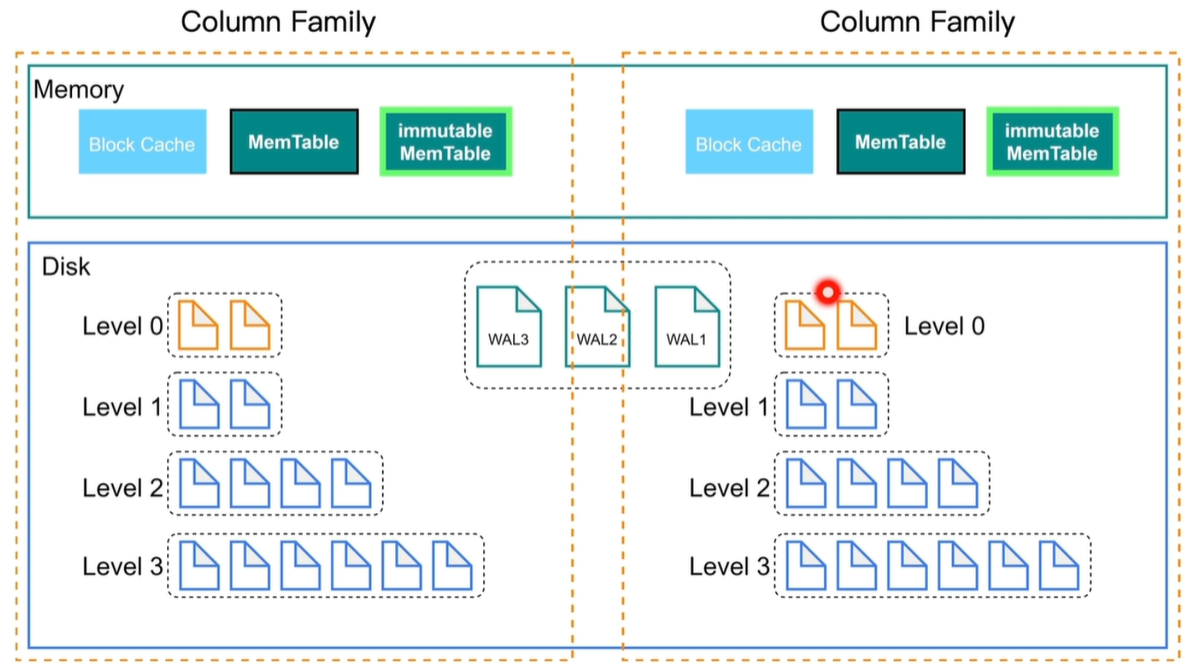
数据分片技术
分布式事务
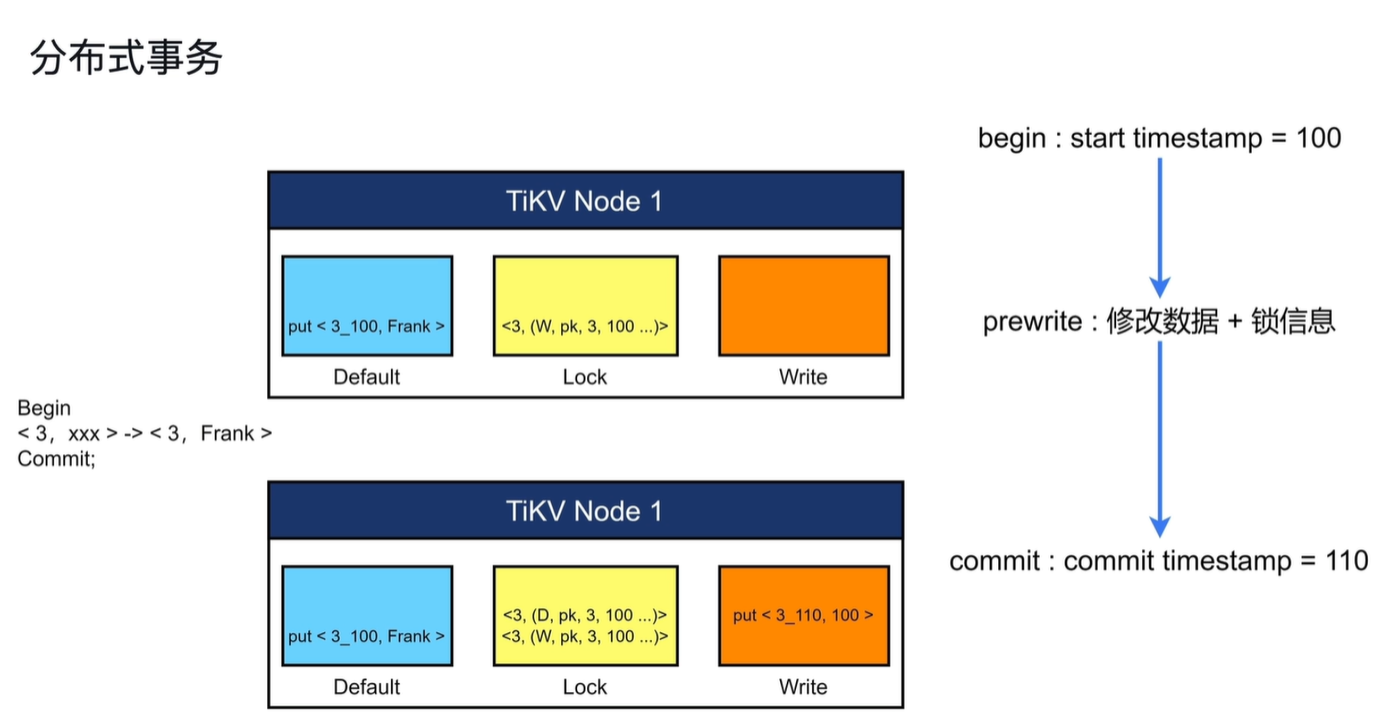
事务提交流程:
首先会获得一个start timestamp = 100(事务开始时间)
其次修改数据(Default)+锁信息(Lock)
最后获得事务结束的版本号,写入write列(提交信息),删除锁
当业务读数据时会先查找write列中的信息,其次查看其锁信息,如果write列有信息并且没有锁就可以读取该数据。
- write列:当用户写入一行数据时,如果改行数据长度小于255字节,那么就会存储在write列中
- Default列:用于存储超过255字节长度的数据
TiKV-Raft
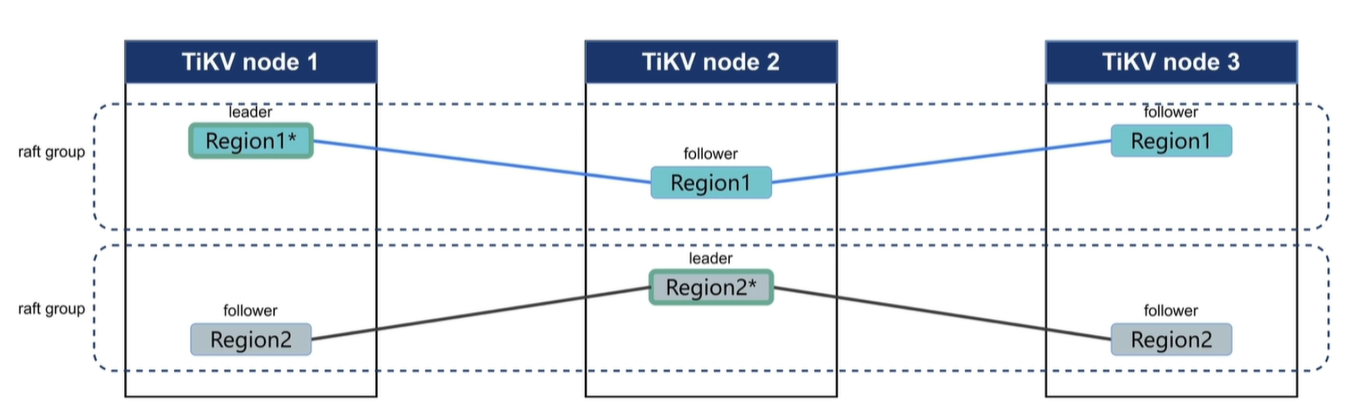
Region在多副本中会有一个leader副本,leader副本是集群中的管理者,读写都走leader,并且会定期给follower发送心跳信息告诉从副本我是leader。leader的修改信息会以日志的方式传输到其他follower上以维持数据库的一致性。
当follower长时间未收到leader的信息是就会将自己转化为candidate,重新投票选举新的leader。
- 当一个Regino的写入信息达到96MB时就会开启下一个Regino继续写入。
- 当一个Region插入信息过多使其达到144MB时就会分裂成两个Region。
- 当一个Region经过太多删除小于设定阈值时会将其合并。
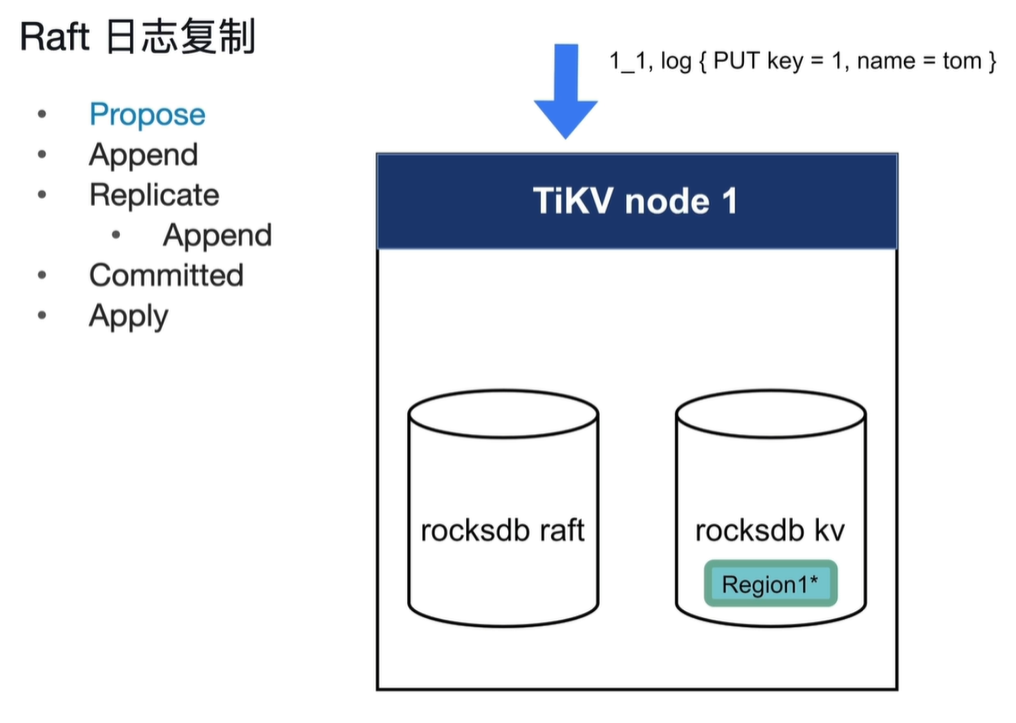
rocksdb raft:持久化日志
rocksdb kv:存放数据
- Propose:客户端写入一条日志
- Append:将日志持久化到raft中,只在leader节点持久化
- Replicate:将主leader的日志复制到其他节点,其中Append在其他节点中进行
- Committed:当其他节点(超过一般以上)持久化之后返回持久化成功后就Committed。此committed与应用程序的意义不一样
- Apply:将数据写入rocksdb kv
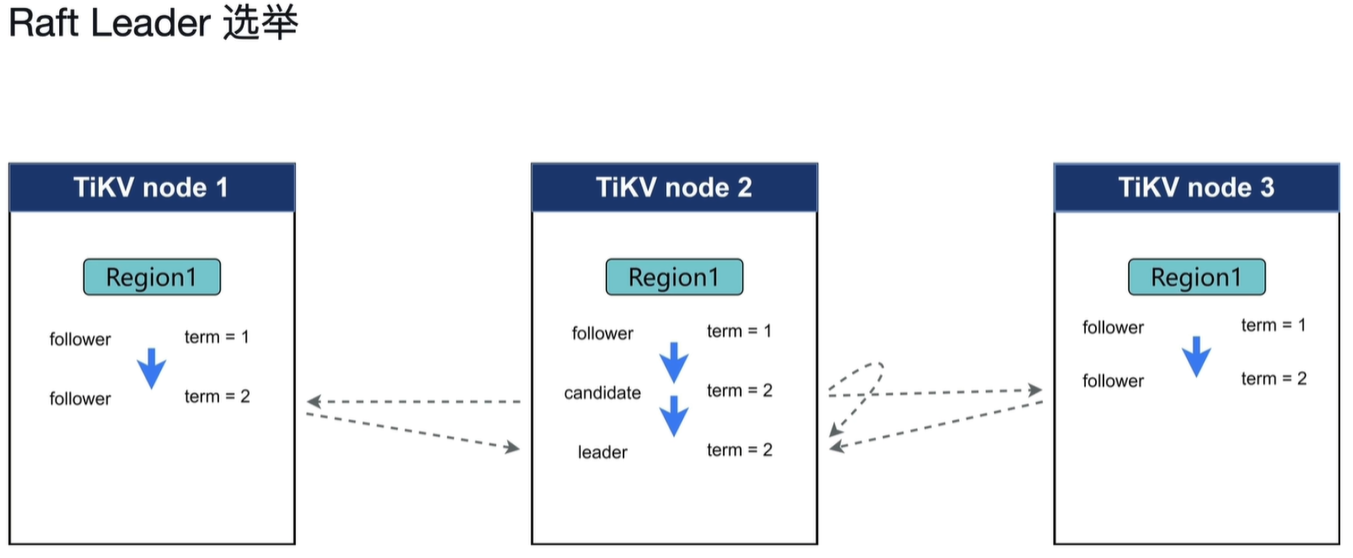
当第一个node率先突破election_timeout值时成为candidate,并且将term改为2,发起投票选举新的leader。当其他节点收到投票信息后发现candidate的term值大于自己则投票。满足多数派则成为leader。
heartbeat_time_interval:当上个收到心跳的时间距现在超过此参数值时会打破现在的关系将自己变为candidate,重新发起投票。满足多数派则自己变为leader。
如果当多个节点成为candidate,则重新发起选举。election_timeout可以设置为一个区间,每次在区间内随机取值,这样就可以减少有多个candidate出现的情况。
参数对应:
Election timeout: raft-election-timeout-ticks
Heartbeat time interval: raft_heartbeat-ticks
raft_heartbeat-ticks *raft-base-tick-interval //ticks是个数的意思代表多少个时间
raft-election-timeout-ticks *raft-base-tick-interval
TiKV- 读写与 Coprocessor
此处不包含MVCC和锁的情况
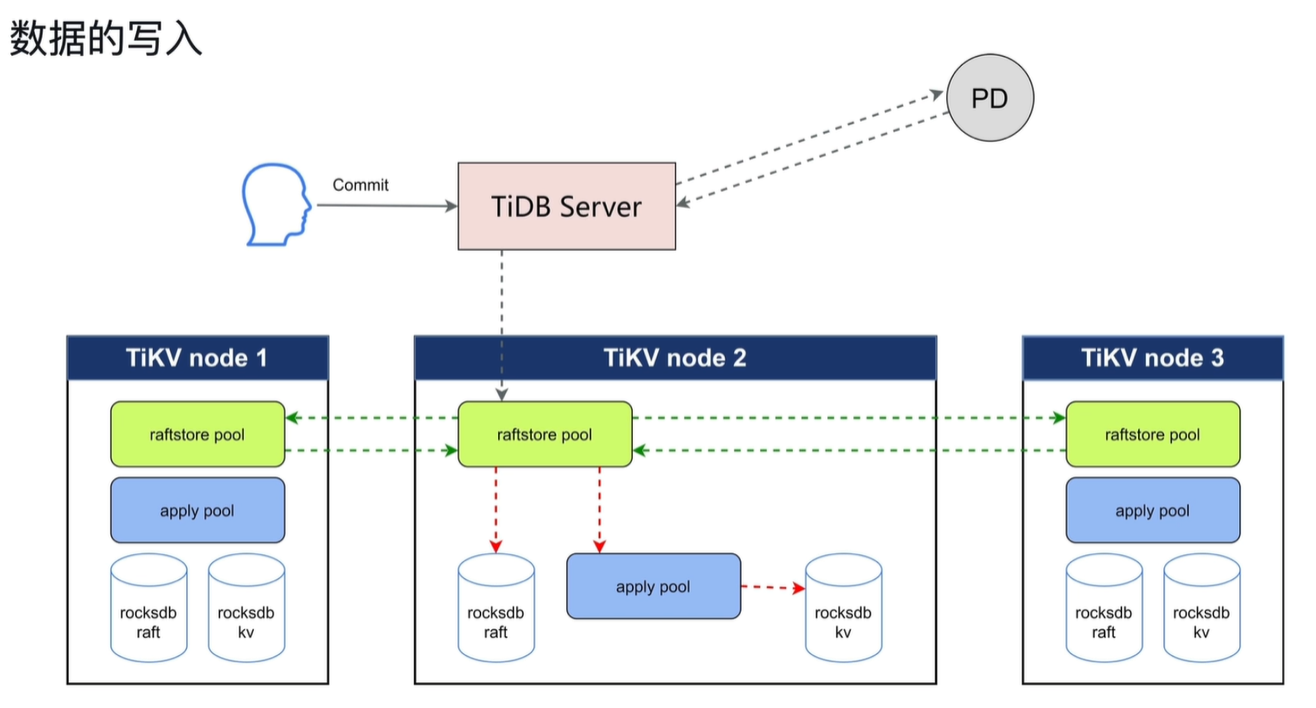
raftstore pool:将写请求转化成raft日志,做持久化。并且同时将日志发送到其他节点的raftstore pool进行持久化。
apply pool:日志持久化后拿着此日志将其写入rocksdb kv中。
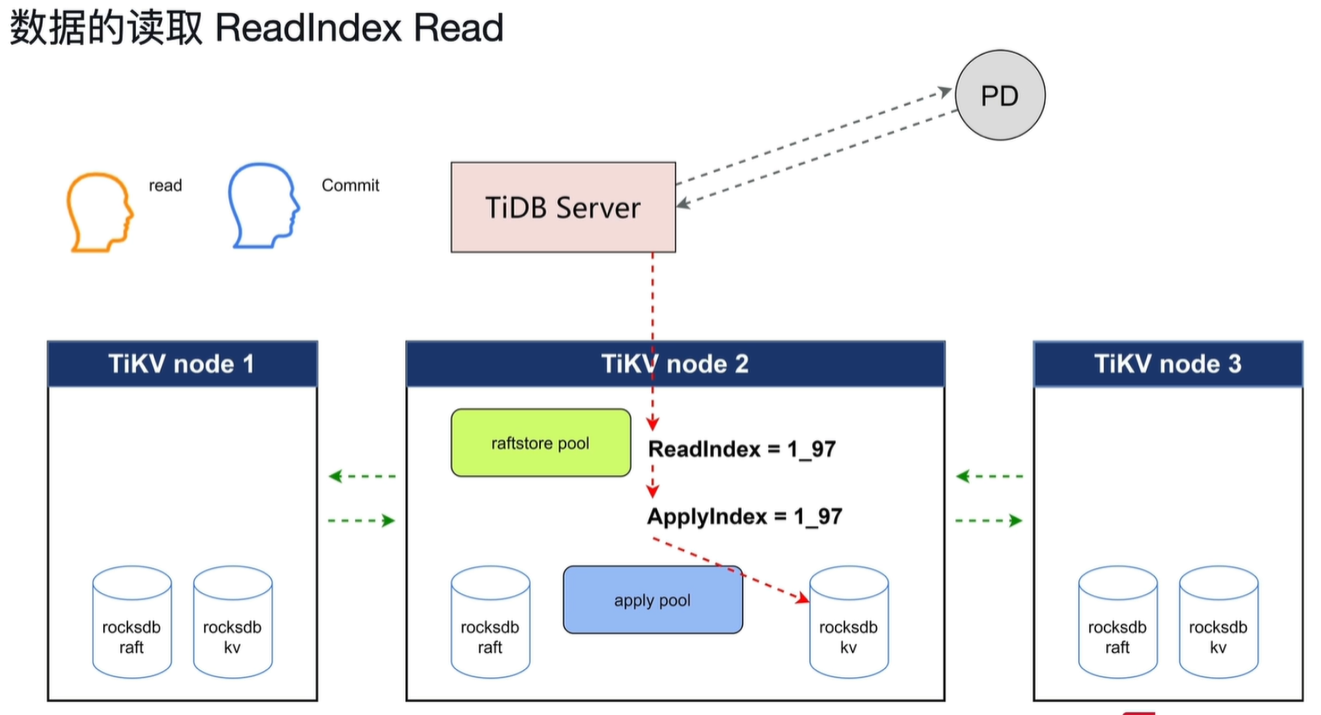
问题一:当读取时会先向PD发送请求确定leader副本在那个node上,收到PD的信息后再开始向leader所在的node中读取。如果当收到PD信息进行读取时发生leader副本切换该怎么办。
答:读取前leader所在的node会向其他node发送心跳信息确定自己是不是leader,之后在开始读取。发送过心跳信息后就不会发生leader切换。
问题二:用户1在10:00提交了数据,用户2在10:05能不能读取到用户1提交的数据。怎么维持线性一致性。
答:
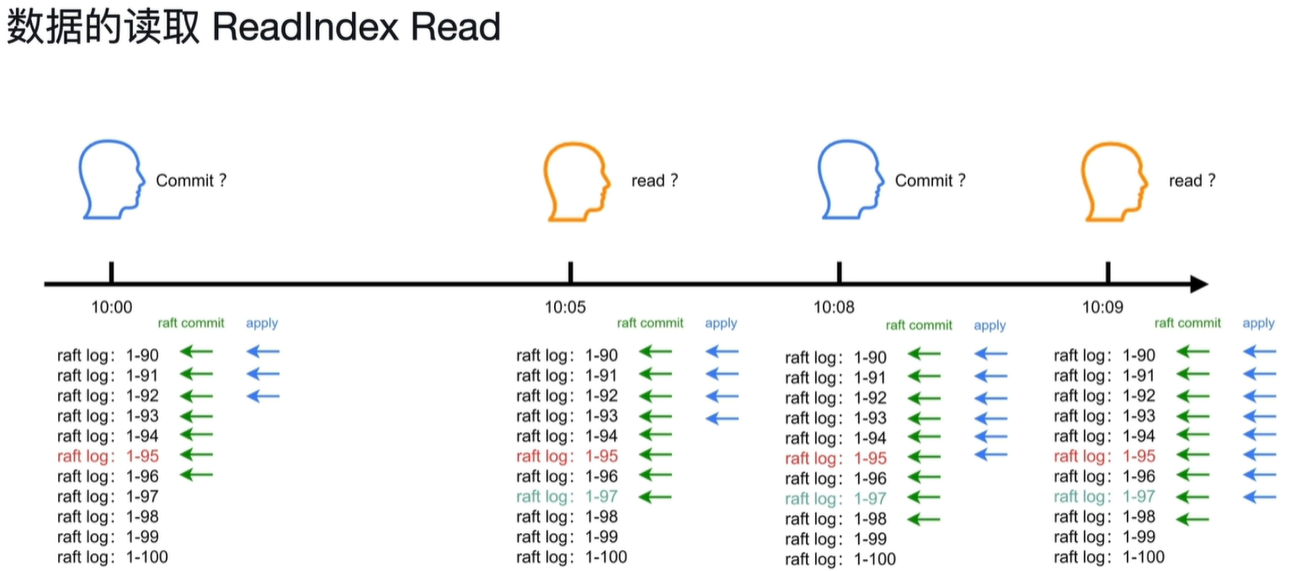
当读取开始时会设置最新raft commit的值为Readindex,当apply到Readindex的值时才开始读取,这样就一定会读到已经提交的数据。
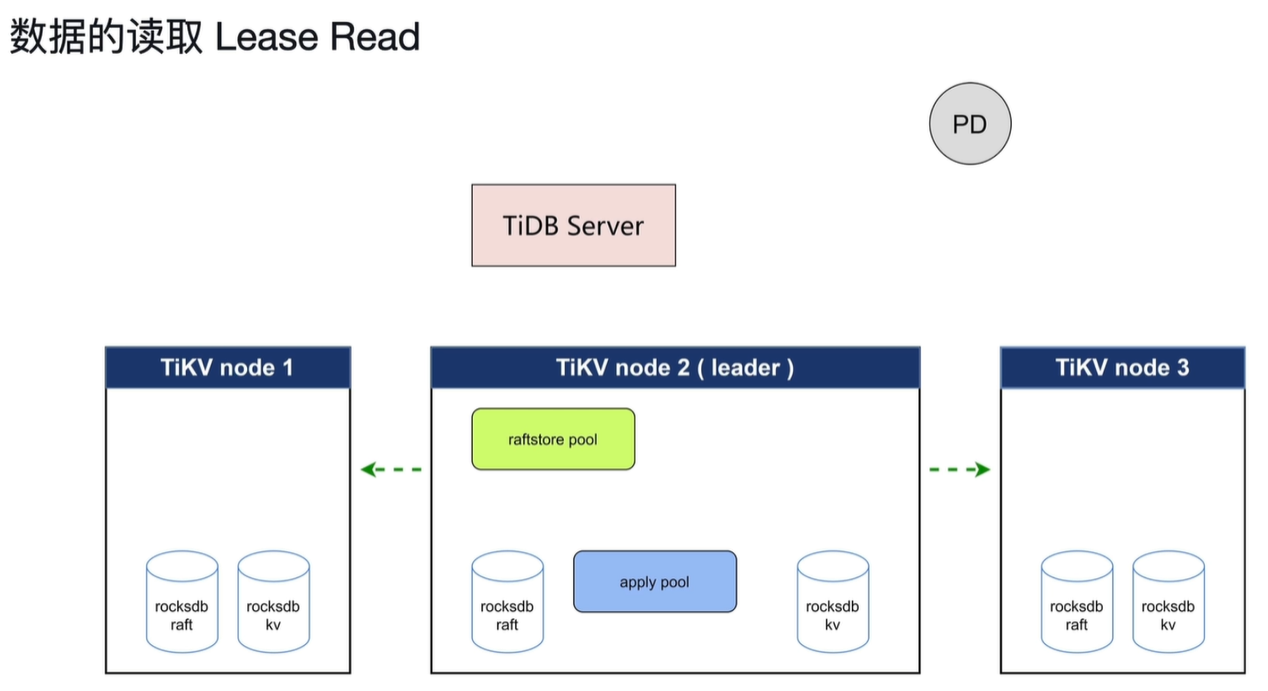
当读取时需先发心跳,有一定的网络延迟,所以会造成一定的读的延迟。
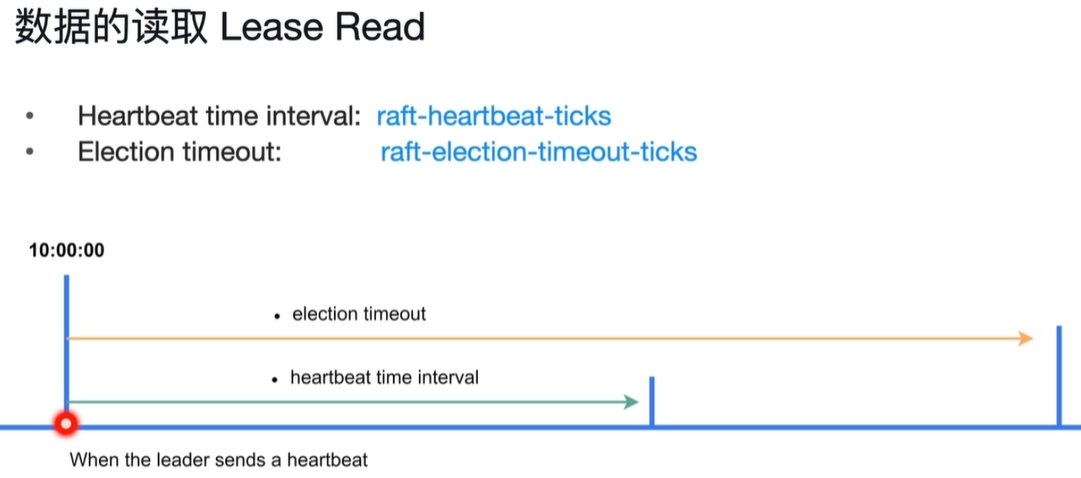
当10:00时会发出心跳数据,在下面那条线期间不会发生选举,并且在这段时间内不用发心跳。只有过了Election timeout这段时间过后才会发生leader选举。
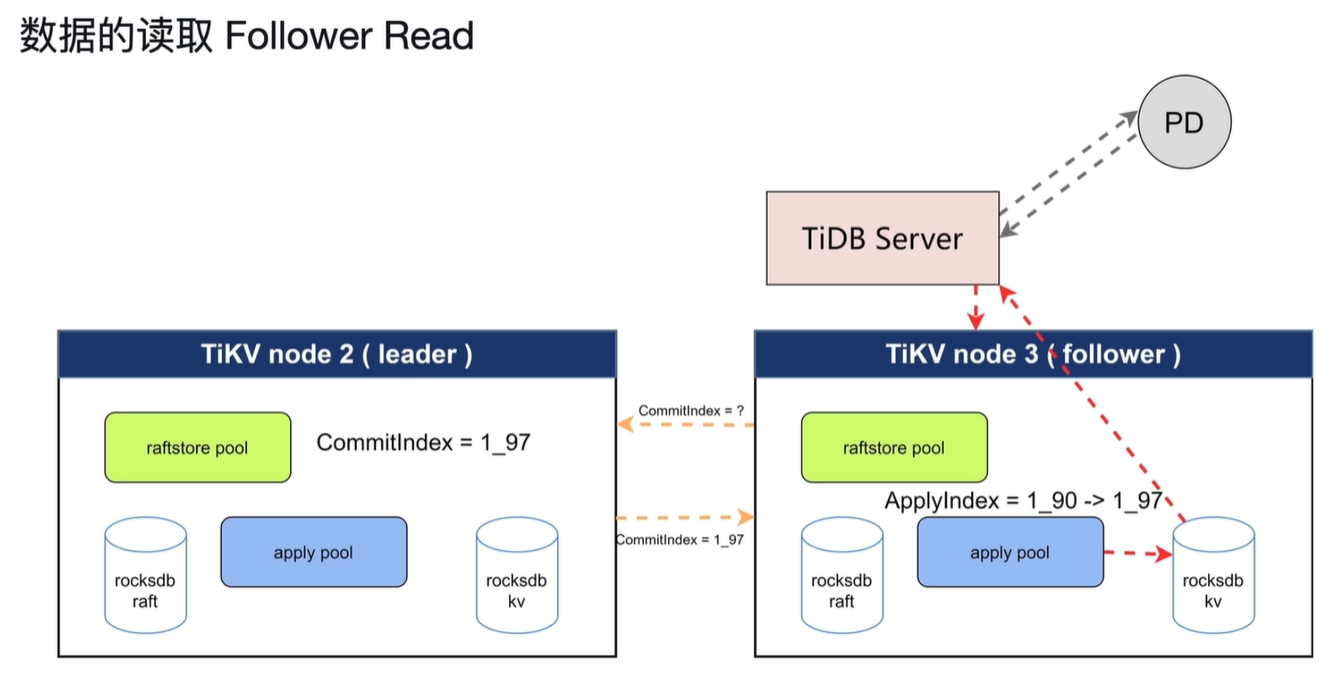
读取follower的数据,减轻leader的压力。但是会产生主从不一定同步apply这样的问题。所以会先从leader获取Commitindex的数据,直到follower的apply到Commitindex的值时开始读取。
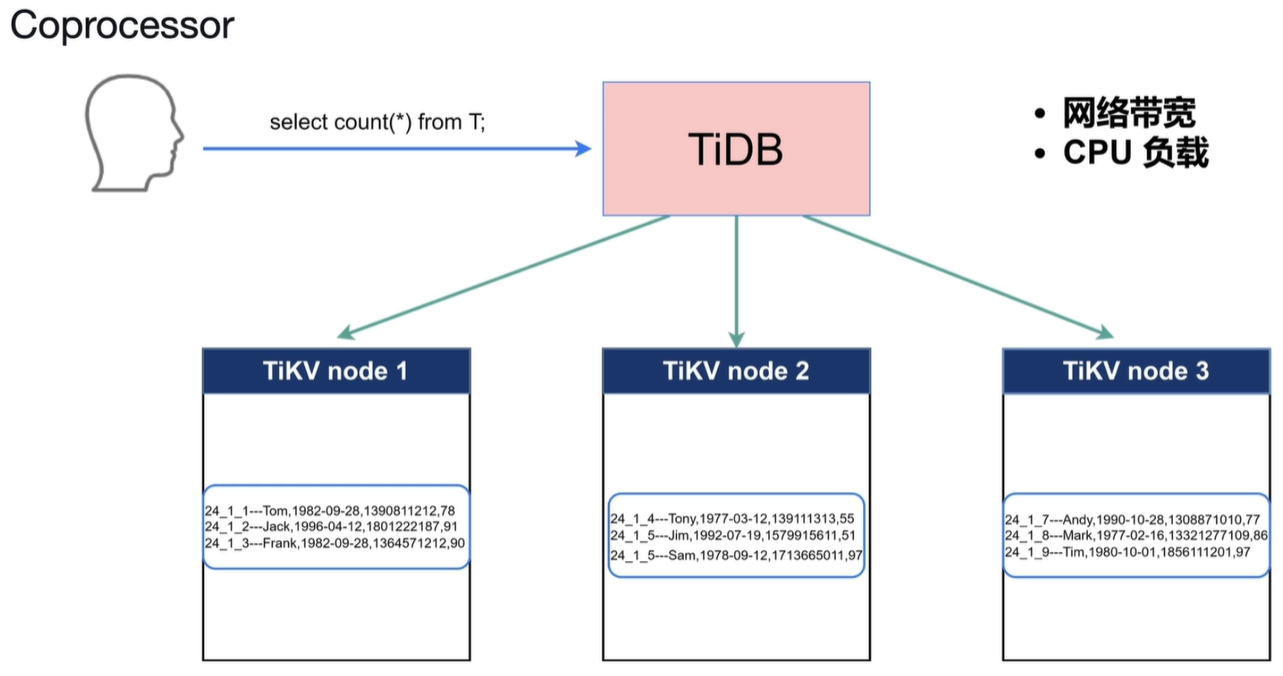
解决当如上情况出现时会有大量数据向TiDB聚合,增大开销。这时候Coprocessor(协同处理器)会在当前节点计算,将计算结果发往TiDB中。TiDB收到数据会进行简单的二次整理,大大减轻了TiDB的计算和网络开销。
表扫,索引扫,过滤,聚合等都会进行算子下推。
