




金仓数据库KingbaseES 集群原主自动故障恢复时所需wal日志不存在场景下的手动恢复
关键字
wal日志被清理,sys_rewind失败,故障恢复
问题描述
集群原主故障,由于恢复所需wal日志已被清理导致原主sys_rewind或启动数据库失败。
场景示例:
一主一备集群,原主断网/掉电,备机升主后新的业务持续下发,新的wal日志持续生成。待原主重新断网恢复/上电后,自动恢复到集群时可能会存在sys_rewind过程中或启动数据库过程中因缺少所需wal日志执行失败。
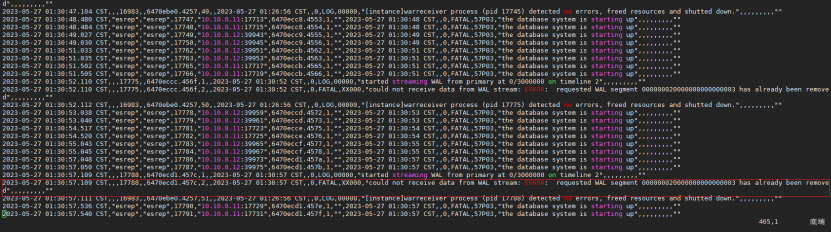
问题分析
原主下电时间过久,新主上的新业务持续生成wal日志,达到wal_keep_segements设定值后,由于新主上无复制槽,新主会清理对于新主来说不再使用的wal日志。
原主断网/掉电恢复后,新主监测到原主可以连接后开始执行恢复操作。新主通过sys_rewind拷贝差异的数据文件和wal日志到本节点,在启动数据库做redo时发现当前的wal日志不完整,redo所需的wal日志存在缺失,数据库无法启动。
解决方案
- 预防性方案
可以调整集群wal_keep_segments参数值为一个较大的值,集群节点下电或断网期间,主机能保留更多的wal日志来支撑之后备机恢复动作。
- 问题解决方案
备机sys_rewind或启动数据因wal日志被清理而失败的场景下,可以通过重做备机来完成备机的恢复。
1)在主库数据库bin目录下执行./repmgr service pause

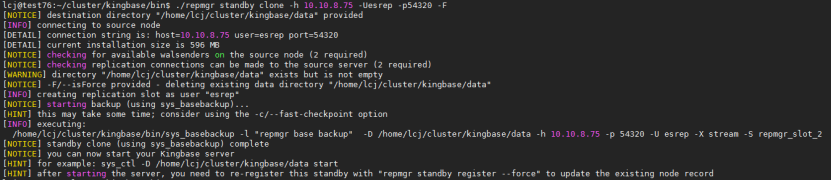
2)在故障的数据库bin目录下执行./repmgr standby clone -h 主库ip -Uesrep -p数据库端口号 –F
3)在故障数据库bin目录下启动数据库
./sys_ctl -D /home/lcj/cluster/kingbase/data/ start

- 在主库数据库bin目录下执行./repmgr service unpause

5)在主句数据库bin目录下执行./repmgr cluster show确认集群状态是否恢复正常

更多信息,参见https://help.kingbase.com.cn/v8/index.html
