1.Spark产生背景
MapReduce局限性
代码繁琐
只能够支持map和reduce方法
执行效率低下
不适合迭代多次、交互式、流式处理
框架多样化,学习、运维成本高
批处理(离线):MapReduce、Hive、Pig
流式处理(实时):Storm、JStorm
交互式计算:Impala
Spark可以解决多框架带来的学习成本高、运维成本高的问题。
2.Spark概述及特点
官网:http://spark.apache.org
Apache Spark™ is a unified analytics engine for large-scale data processing.
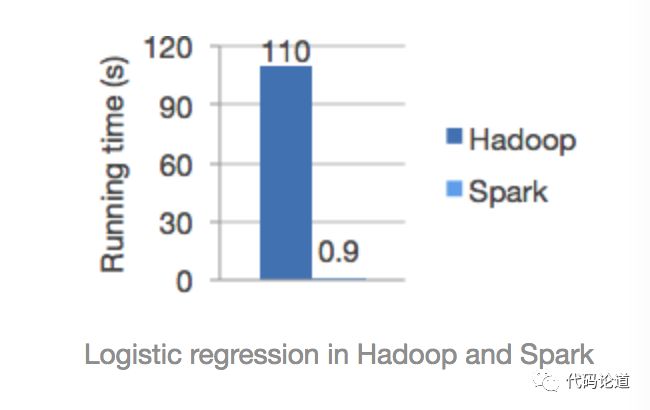
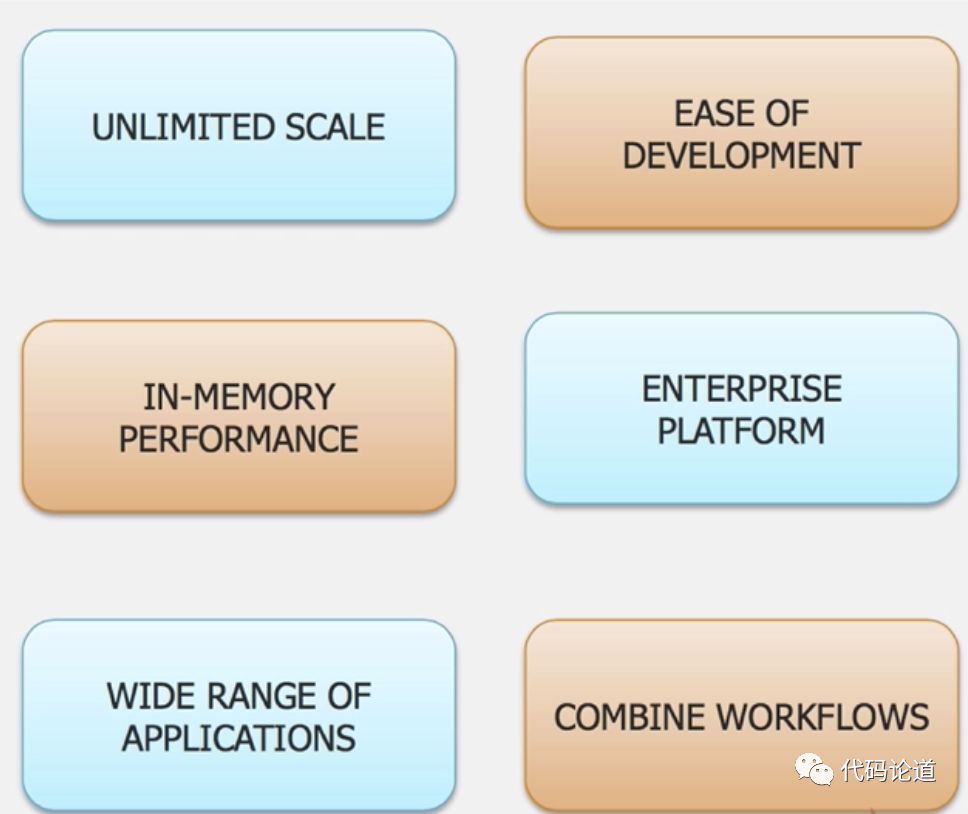
快如闪电的分布式计算框架,特点如下:
speed
Ease of Use
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
wordcount案例spark实现:
df = spark.read.json("logs.json")
df.where("age > 21") .select("name.first").show()
Generality
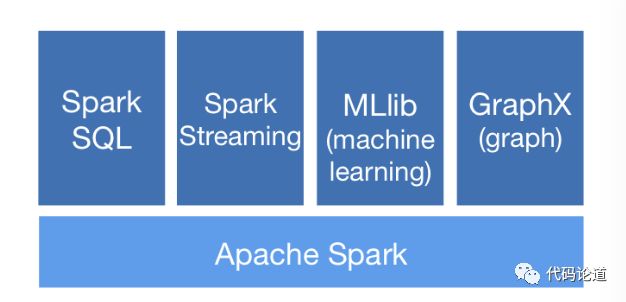
Runs Everywhere
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.

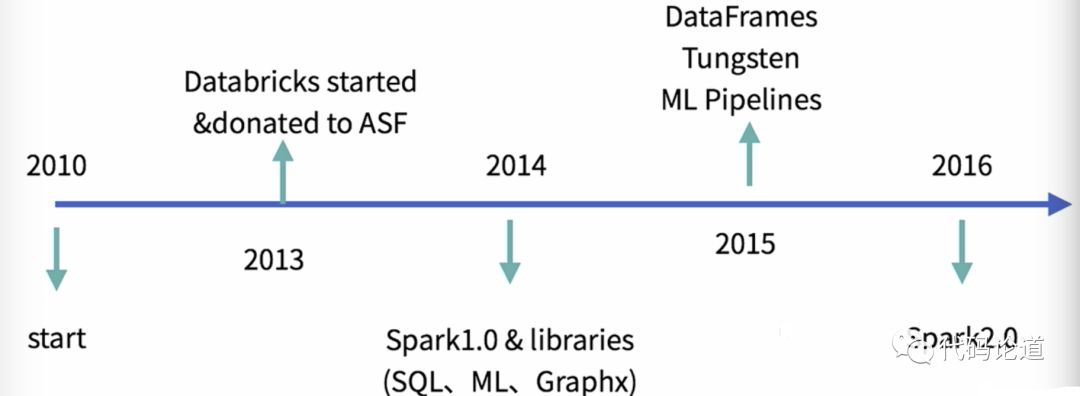
3.Spark发展历史
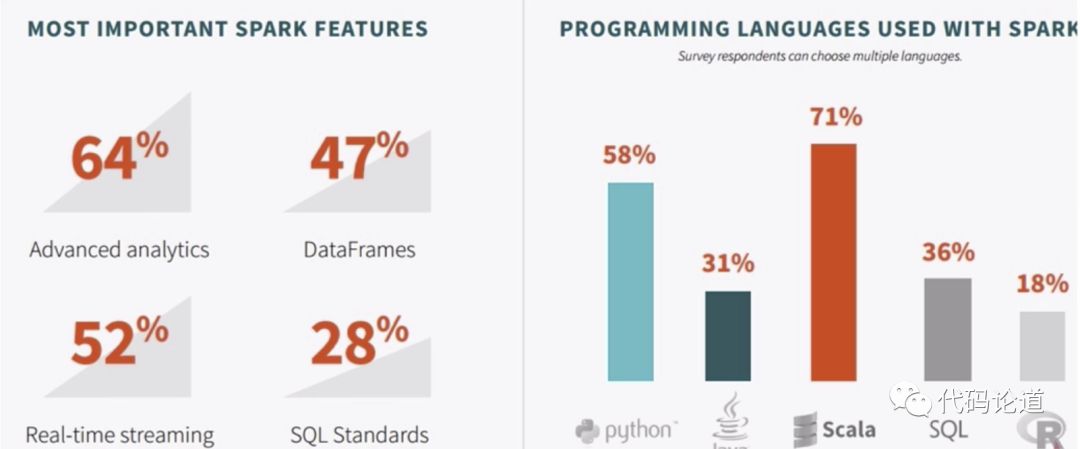
4.Sprk survey
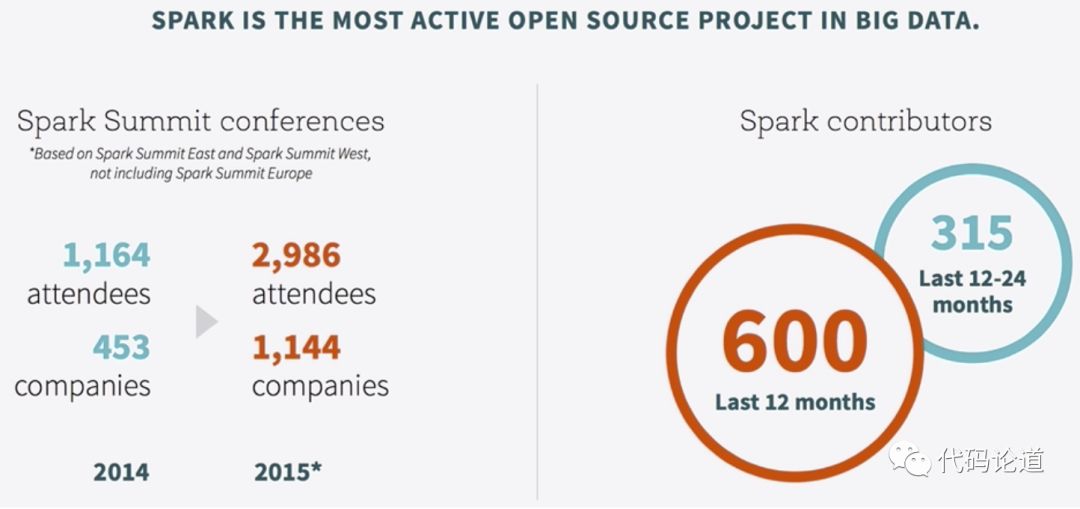

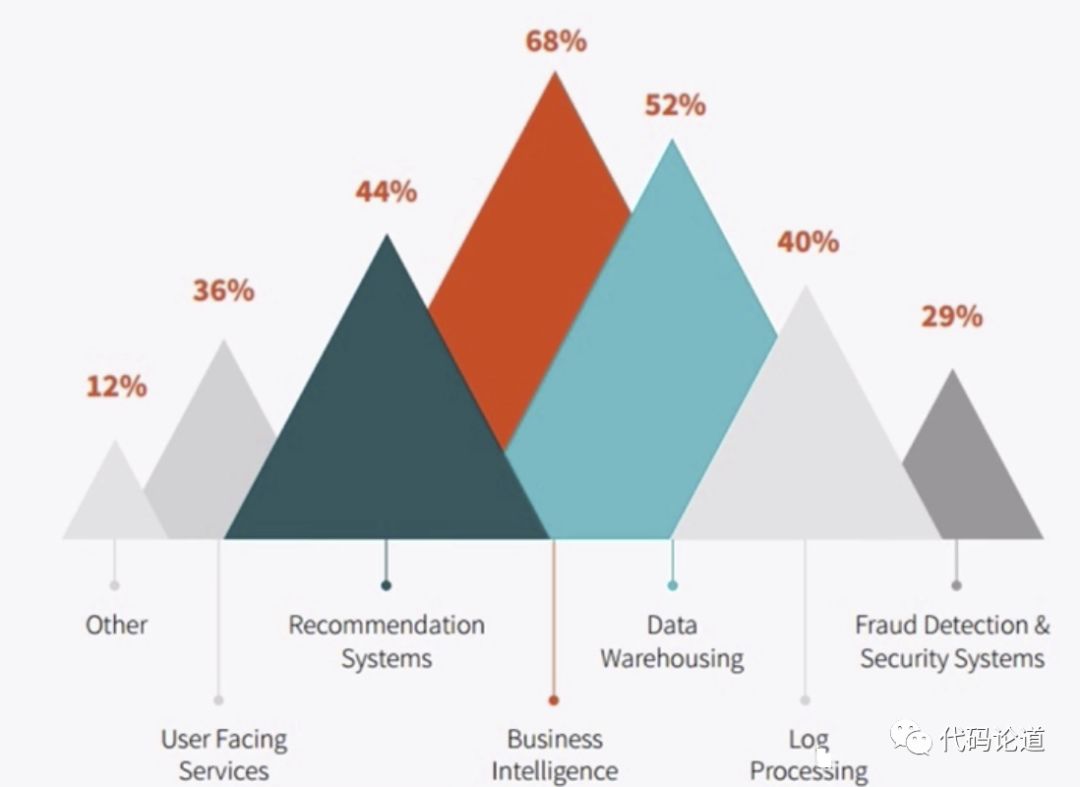
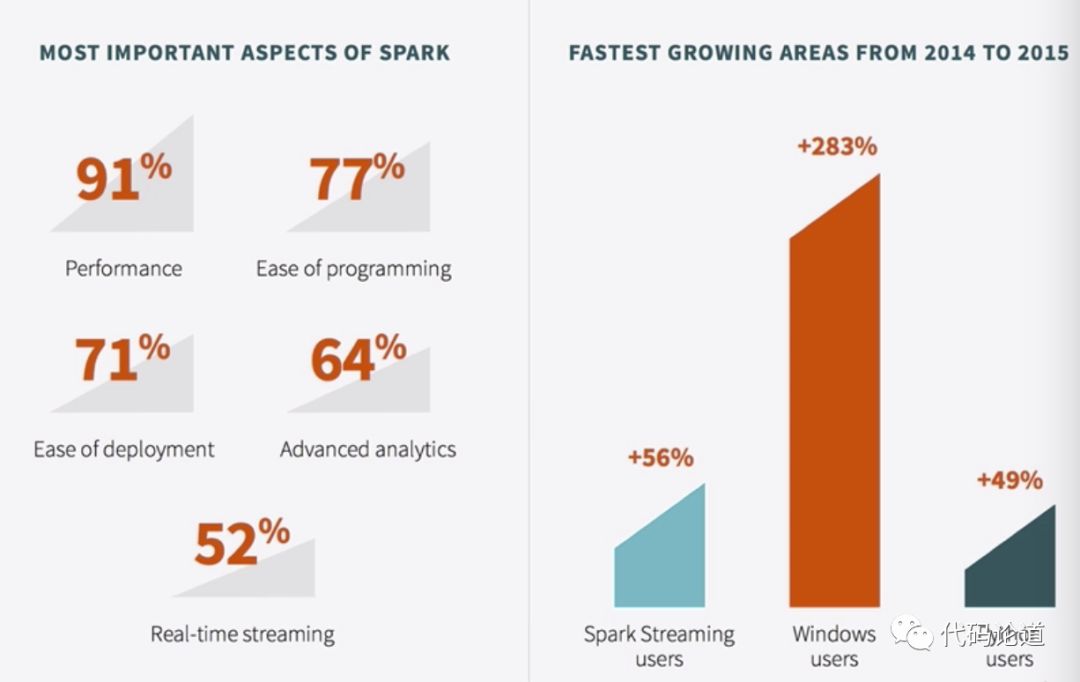
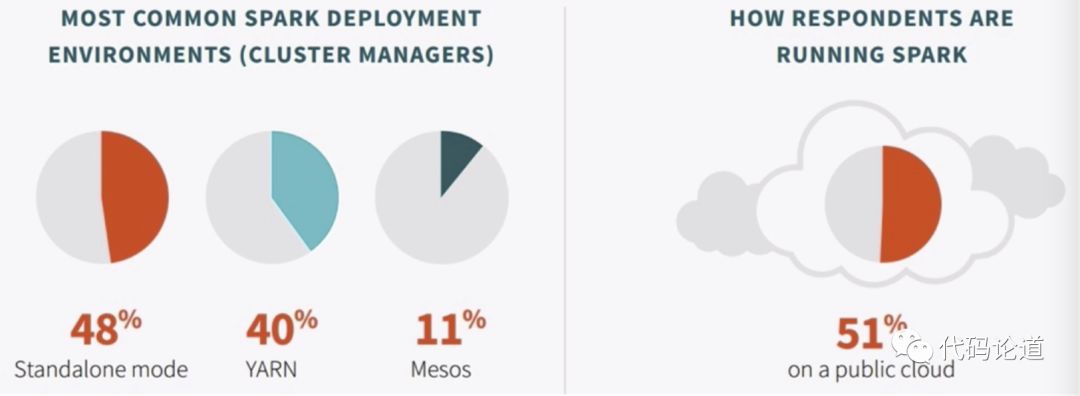


5.Spark对比Hadoop
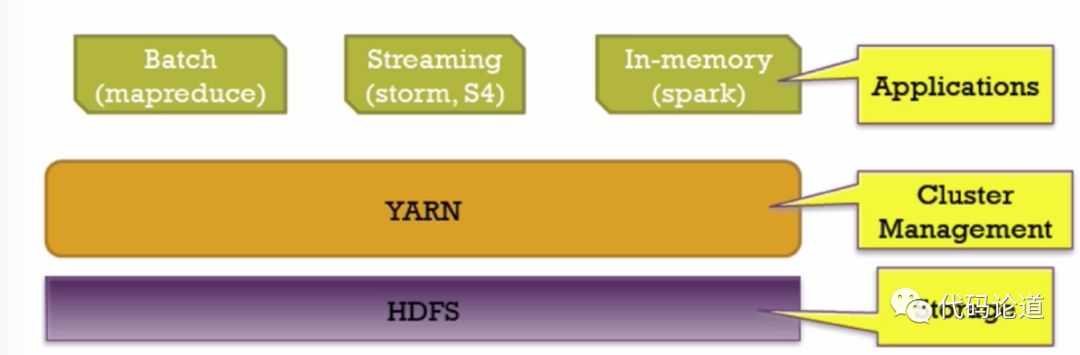
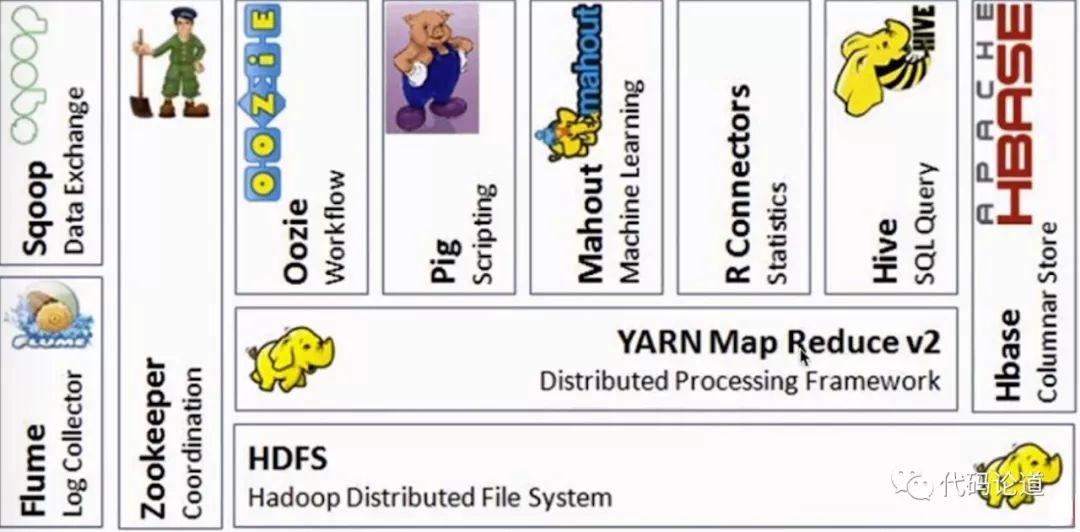
Hadoop生态系统:
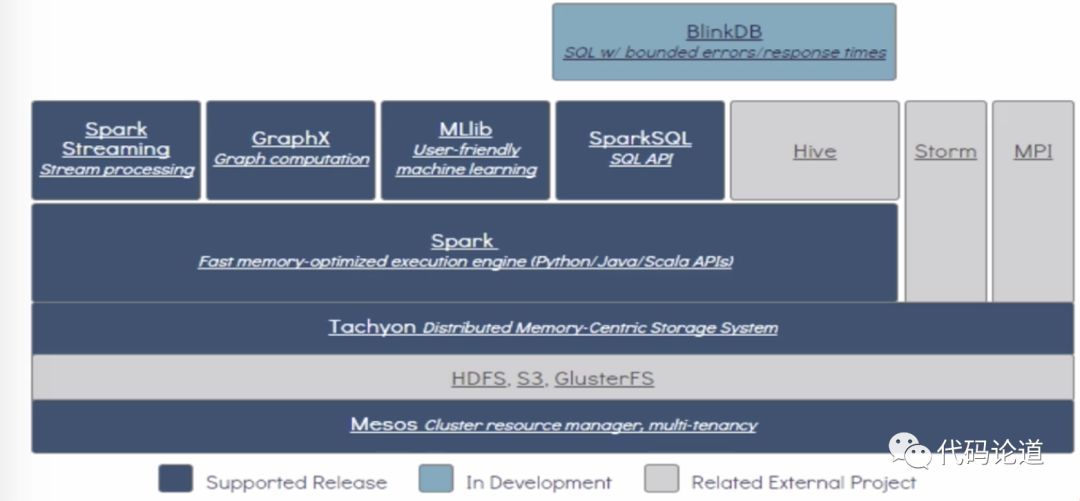
Spark生态系统:
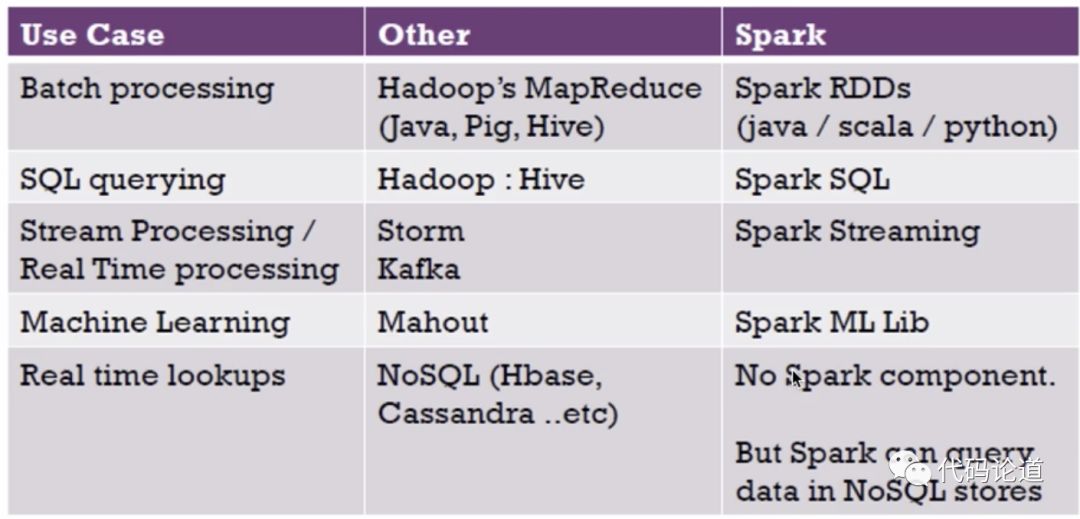
Spark对比Hadoop:
Hadoop对比Spark:
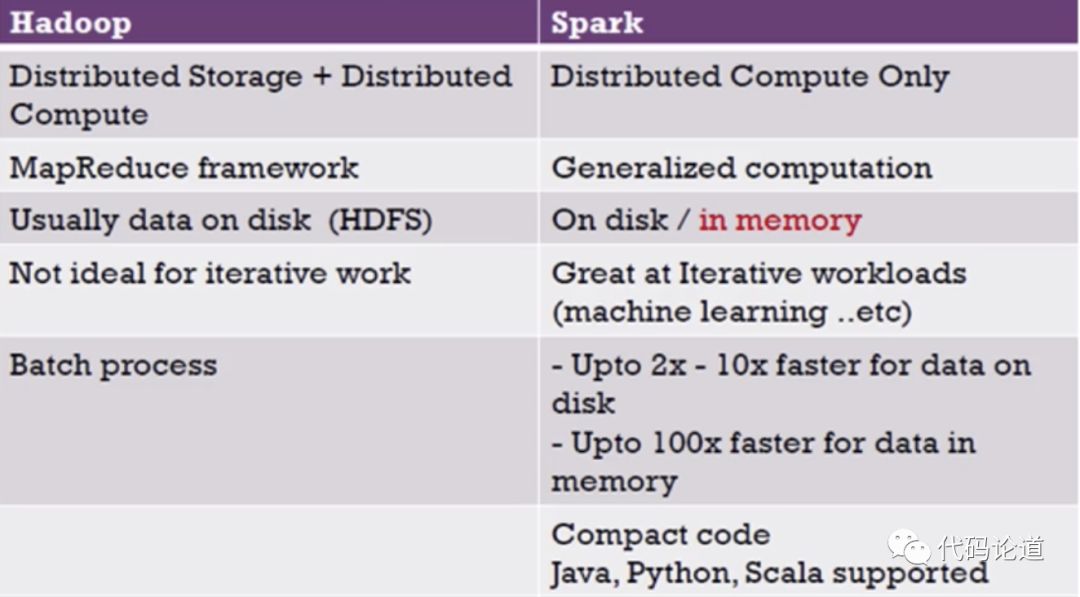
MapReduce对比Spark:
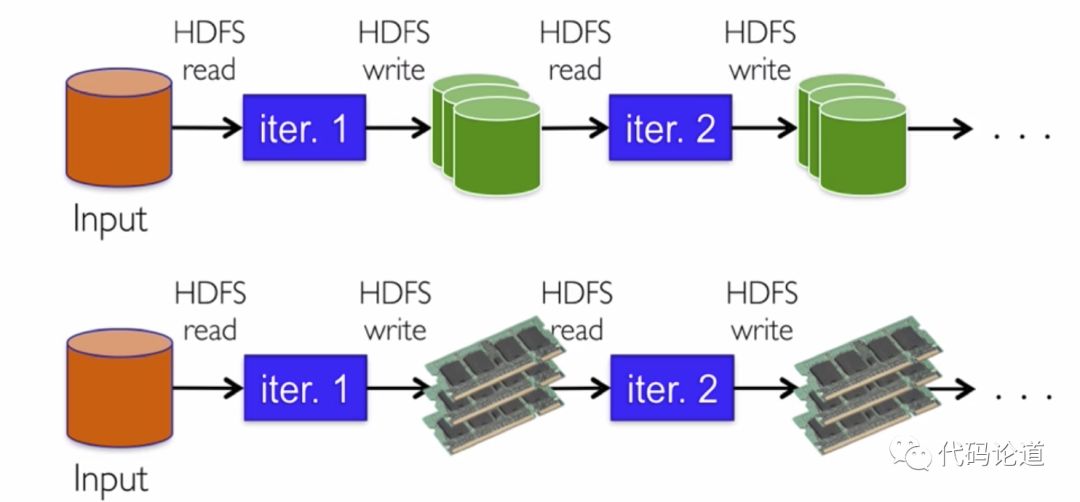
6.Spark和Hadoop的协作性
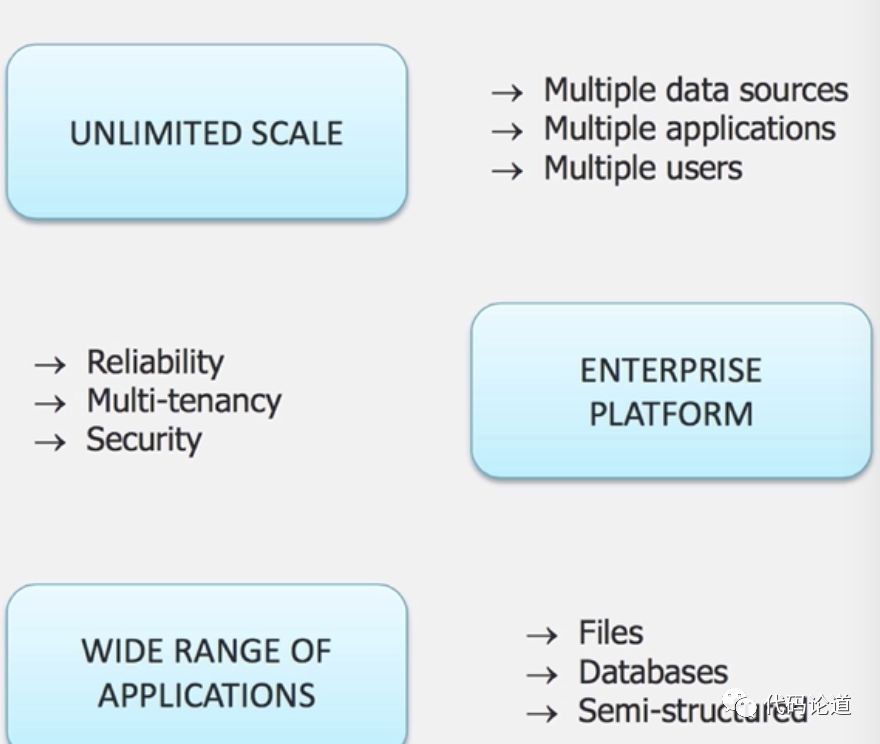
Hadoop的优势
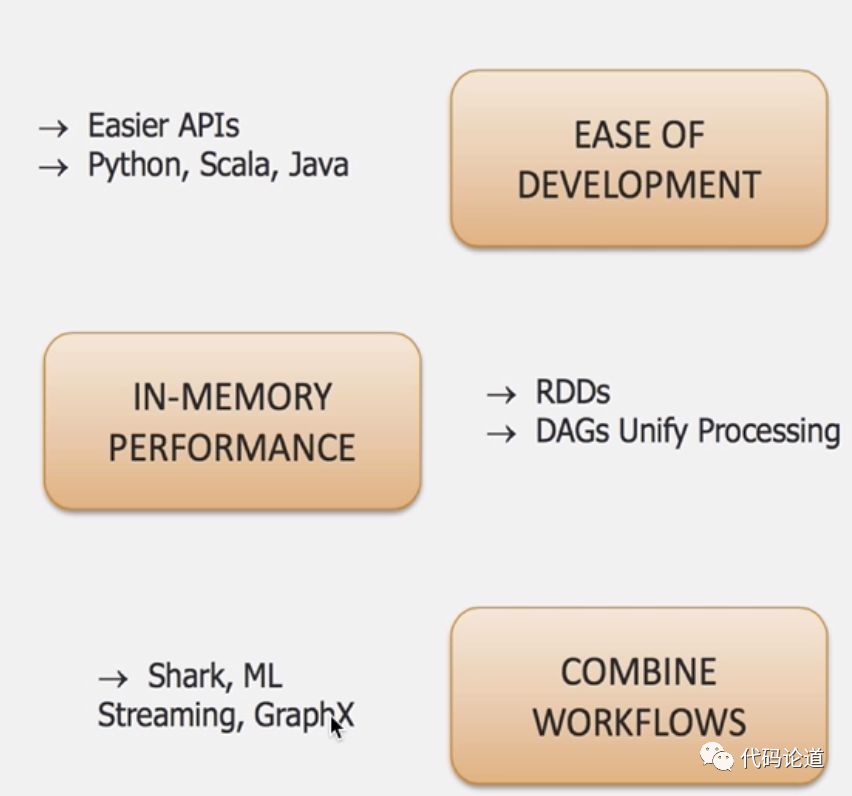
Spark优势
Hadoop+Spark
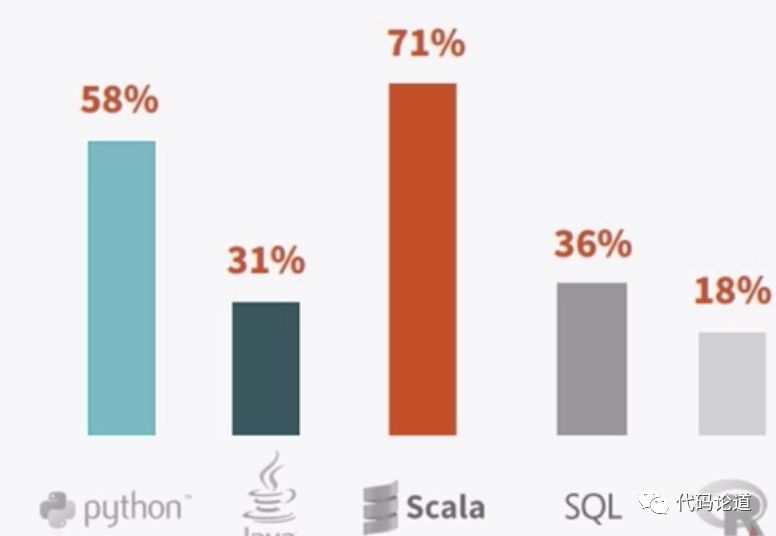
7.Spark开发语言
8.Spark运行模式