




1.Hadoop概述


Hadoop包含以下子项目:
Hadoop Common,hadoop生态系统中通用的组件
Hadoop Distributed File Sytem(HDFS)
Hadoop YARN :作业调度和集群资源管理
Hadoop MapReduce:大数据计算框架,基于YARN
Hadoop能做什么
搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务。
2.Hadoop核心组件
分布式文件系统HDFS
源自于Google的GFS论文,该论文发表于2003年10月。
HDFS是GFS的克隆版
HDFS特点:扩展性&容错性&海量数量存储
扩展性:
假设Hadoop集群中有100个节点,如果数据存储不了,可以通过添加机器的方式扩大容量。
容错性:
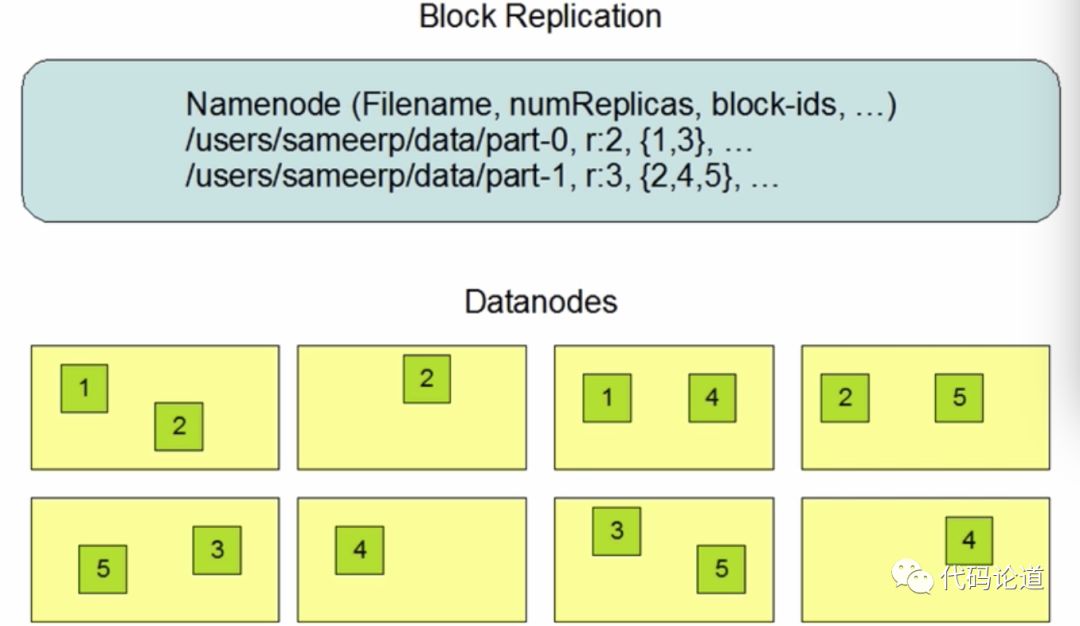
在HDFS文件系统上存储的数据,以多副本的方式存储在各个节点之上。假设一个文件有100MB,在HDFS上加入设置的一个数据块的大小为128MB,那么这一个文件就会存在一个数据块中。由于HDFS支持容错,因此会将一个块的数据会多存几份,默认存储3份,会在3台机器上都存这个100MB的文件。如果某台机器挂了,并不会影响文件的使用,因为同样的文件在其他两台机器上有副本。
海量数据存储:因为是集群,比单机存储要大很多。
将文件切分成指定大小的数据块并以多副本的存储在多个机器上
数据切分、多副本、容错等操作对用户是透明的
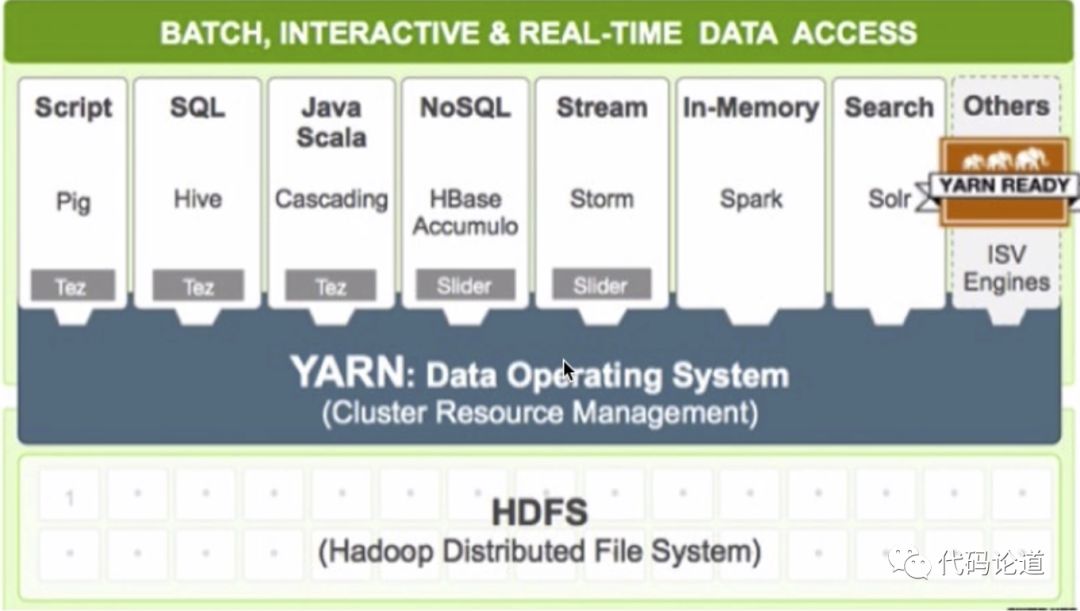
资源调度系统YARN
YARN:Yet Another Resource Negotiator
负责整个集群资源的管理和调度
YARN特点:扩展性&容错性&多框架资源统一调度
分布式计算框架MapReduce
源自于Google的MapReduce论文,论文发表于2004年12月
MapReduce是Google MapReduce的克隆版
MapReduce特点:扩展性&容错性&海量数据离线处理
MapReduce分成两部分,Mpa和Reduce
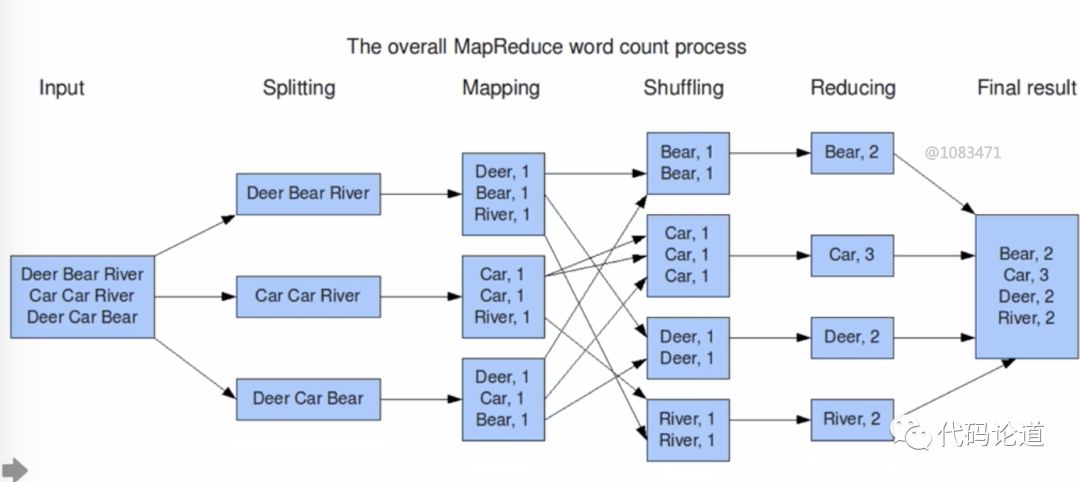
案例:词频统计WordCount
处理流程如下
3.Hadoop优势
可靠性
数据存储:数据块多副本
数据计算:重新调度作业计算
扩展性
存储/计算资源不够时,可以横向的线性扩展机器
一个集群中可以包含数以千计的节点
其他优势
存储在廉价的机器上,降低成本
成熟的生态圈
4.Hadoop发展史
http://www.kuqin.com/shuoit/20160323/351314.html
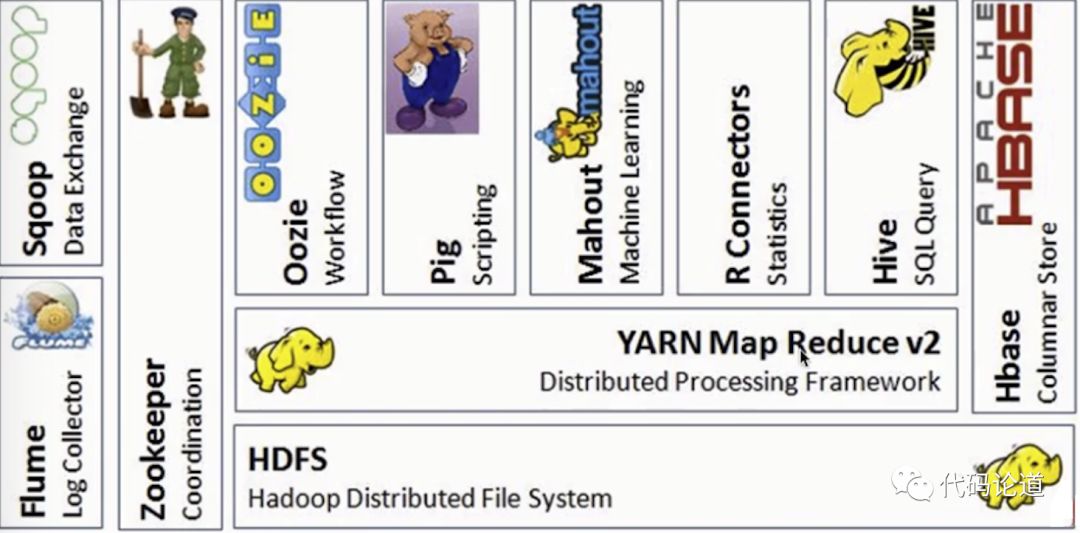
5.Hadoop生态系统
狭义Hadoop VS 广义Hadoop
狭义的Hadoop:是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台;
广义的Hadoop:指定是Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,hadoop是其中最重要最基础的一个部分;生态系统中的每一个子系统只解决某一个特定的问题域,不同统一型的一个全能系统,而是小儿精的多个子系统。
6.Hadoop发行版选择
Hadoop常用发行版及选型
Apache Hadoop
CDH:Cloudera Distributed Hadoop
下载地址:http://archive.cloudera.com/cdh5/cdh/5/
HDP:Hortonworks Data Platform
7.Hadoop企业应用案例
消费大数据----预测试发货
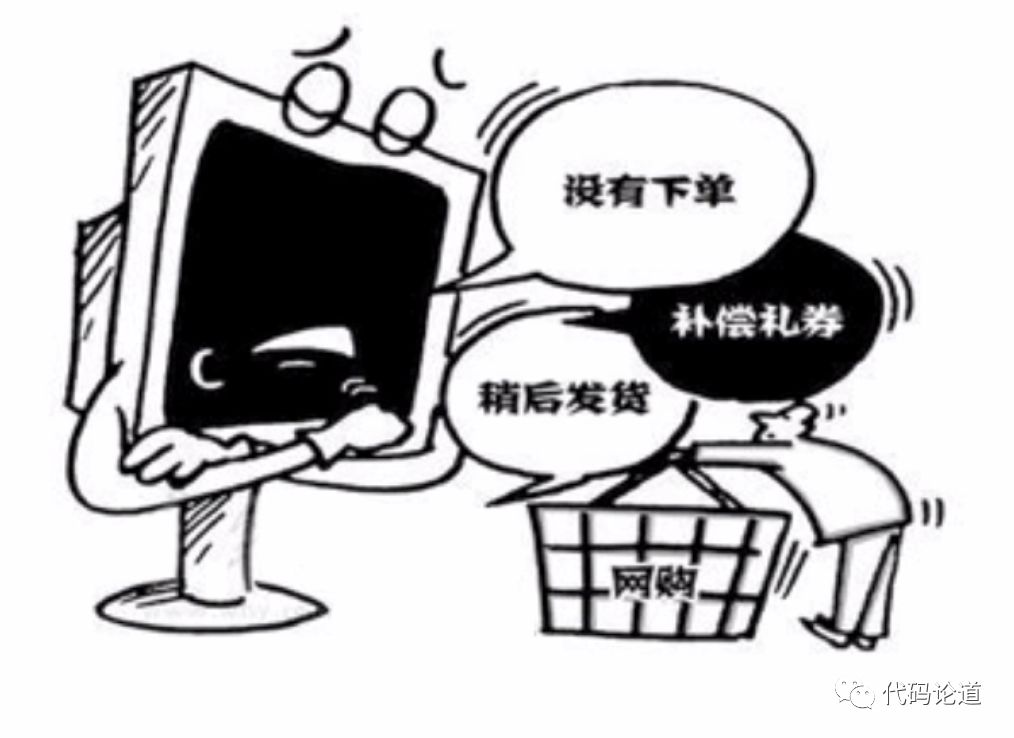
零售大数据

