




一般熟知 Mysql 数据库的朋友知道,当表的数据量达到千万级时,SQL 查询会逐渐变的缓慢起来,往往会成为一个系统的瓶颈所在。为了提升程序的性能,除了在表字段建立索引(如主键索引、唯一索引、普通索引等)、优化程序代码以及 SQL 语句等常规手段外,利用数据库主从读写分离(Master/Slave)架构,是一个不错的选择。但是在这种分离架构中普遍存在一个共性问题:数据读写一致性问题。
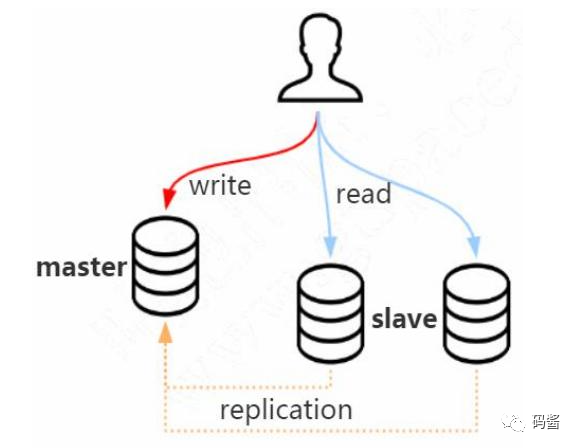
但是这种同步逻辑有一个比较严重的缺陷:数据延时问题。
我们可以想象一下这样的场景:
当一段程序在更新完数据后,需要立即查询更新后的数据,那么真的能查询到更新后的数据吗?
答案是:不一定!
这是因为主从数据同步时是异步操作,主从同步期间会存在数据延时问题,平常主库写数据量比较少的情况下,偶尔会遇到查询不到数据的情况。但是随着时间的推移,当使用系统的用户增多时,会发现这种查询不到数据的情况会变的越来越糟糕。

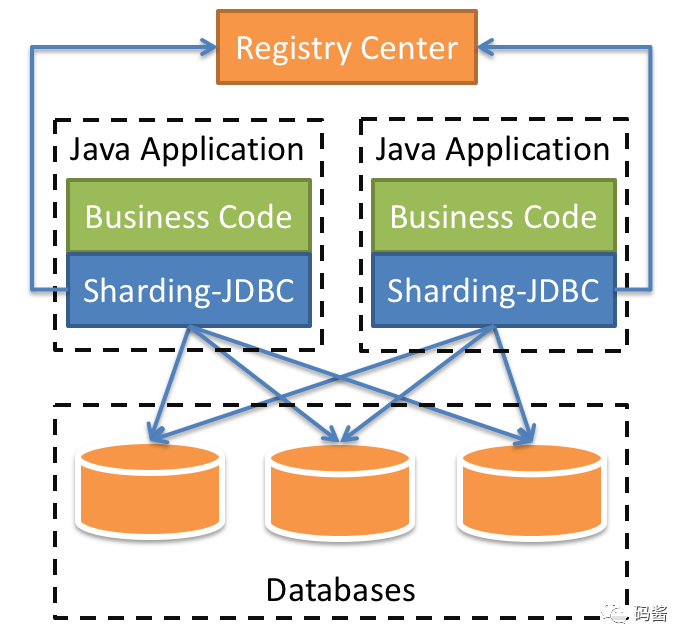
它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
读写分离特性
提供了一主多从的读写分离配置,可独立使用,也可配合分库分表使用。
同个调用线程,执行多条语句,其中一旦发现有非读操作,后续所有读操作均从主库读取。
Spring命名空间。
基于Hint的强制主库路由。
ShardingSphere-JDBC 官方提供 HintManager 分片键值管理器, 通过调用hintManager.setMasterRouteOnly() 强制路由到主库查询,这样就解决了数据延时问题,无论什么时候都能够从主库 Master 查询到最新数据,而不用走从库查询。
HintManager hintManager = HintManager.getInstance();hintManager.setMasterRouteOnly();
1.默认查询:
@Testpublic void getGoodsById() {QueryWrapper<Goods> query = new QueryWrapper<>();query.eq("gid",14L);Goods one = goodsService.getOne(query);System.out.println(one);}
日志可以看出由从库slave查询:

2.强制路由到主库查询:
@Testpublic void getGoodsById() {QueryWrapper<Goods> query = new QueryWrapper<>();query.eq("gid",14L);//强制路由到主库HintManager hintManager = HintManager.getInstance();hintManager.setMasterRouteOnly();Goods one = goodsService.getOne(query);System.out.println(one);}
日志可以看出由主库master查询:

@Testpublic void sleepGetGoodsById() throws ExecutionException, InterruptedException {Callable c = () -> {QueryWrapper<Goods> query = new QueryWrapper<>();query.eq("gid",14L);Goods one = null;try {Thread.sleep(2000);one = goodsService.getOne(query);}catch (InterruptedException e){e.printStackTrace();}Thread.sleep(2000);return one;};FutureTask<Goods> futureTask = new FutureTask<Goods>(c);new Thread(futureTask).start();Goods goods = futureTask.get();System.out.println(goods);}
喜欢就加个关注吧,


往期精选
