





湖仓一体作为数据智能领域的一项前沿技术,一直备受业界关注。尽管湖仓一体拥有较高的技术门槛,但据Gartner《2023年中国数据、分析与人工智能技术成熟度曲线报告》显示,湖仓一体在未来5-10年将迎来长足发展。
本文将重点介绍湖仓一体的必要性,以及柏睿数据在湖仓一体方面的探索、实践和未来展望。
见名知义,湖仓(Lakehouse)是数据湖(Data Lake)和数据仓库(Data Warehouse)的结合。数据仓库和数据湖各自存在一些不足,而湖仓则相应地弥补了它们的不足,并具备了二者的优势。
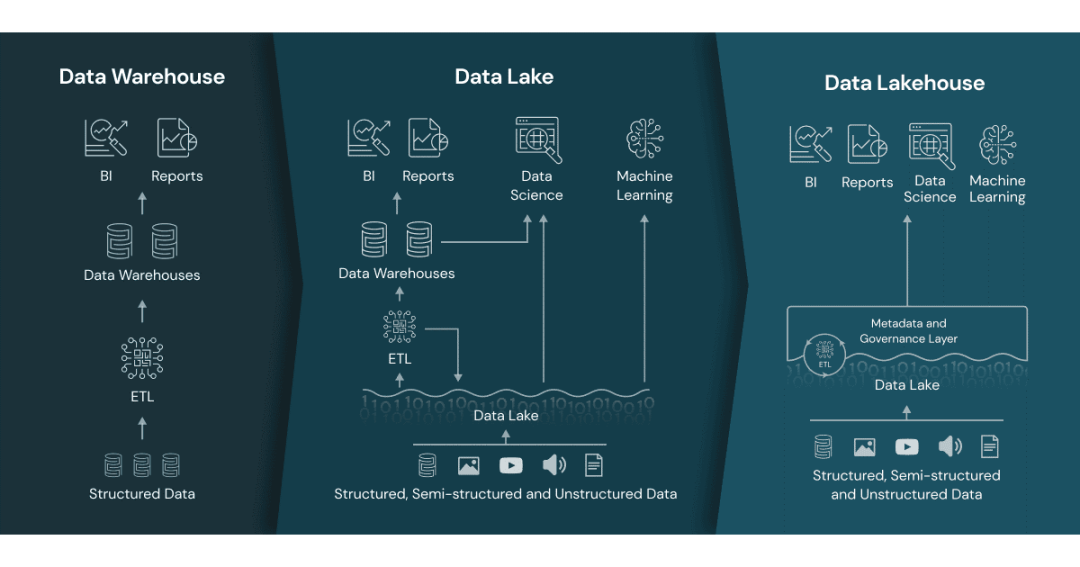
数据仓库被定义为“集成来自一个或多个不同数据源的中央数据存储库”,用来分析来自BI系统和报表系统等一线业务应用的关系型数据。它是一种按主题区域组织的业务抽象表现,通过预先定义数据模式和结构,优化和加速SQL查询,结构化的数据在被清理、丰富、转换后成为可信的来源。
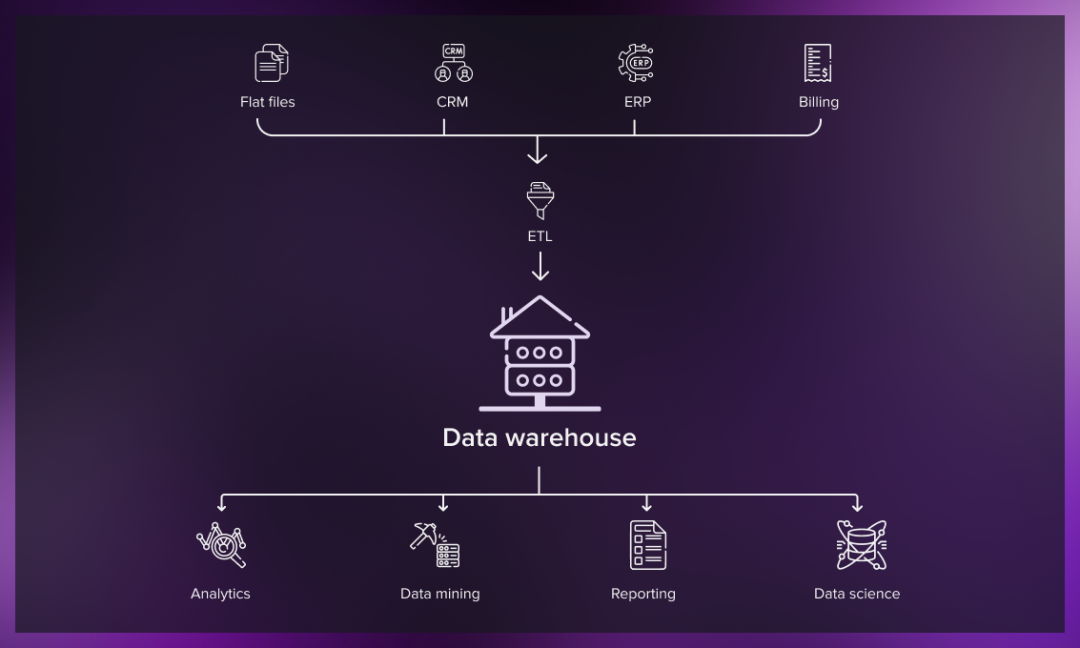
然而,随着数字时代的到来,企业不仅需要处理结构化数据,还需要处理半结构化、非结构化数据,也需要更高效灵活的数据处理方式和更深入的数据挖掘,以满足复杂多样的数据应用需求,并提高数据库资源利用率。传统的数据仓库模式逐渐显现出一些局限性,这促使数据湖的出现。
数据湖的概念由Pentaho公司的首席技术官James Dixon提出。形象地说,数据湖好比自然状态下的水流,数据从各种源系统中流入数据湖,用户可以对数据湖中的数据进行检查、采样,并进行更深入和全面的研究。
数据湖容纳了来自业务线应用程序的关系型数据,以及来自移动终端、IoT设备和社交媒体等方面的非关系型数据,而无需事先构建数据结构。这些多源异构的原始数据以几乎未经转换的状态存储,并在需要数据时再进行提取和分析;能够支持多种应用,如SQL查询、大数据分析、文本搜索、实时分析和机器学习等。
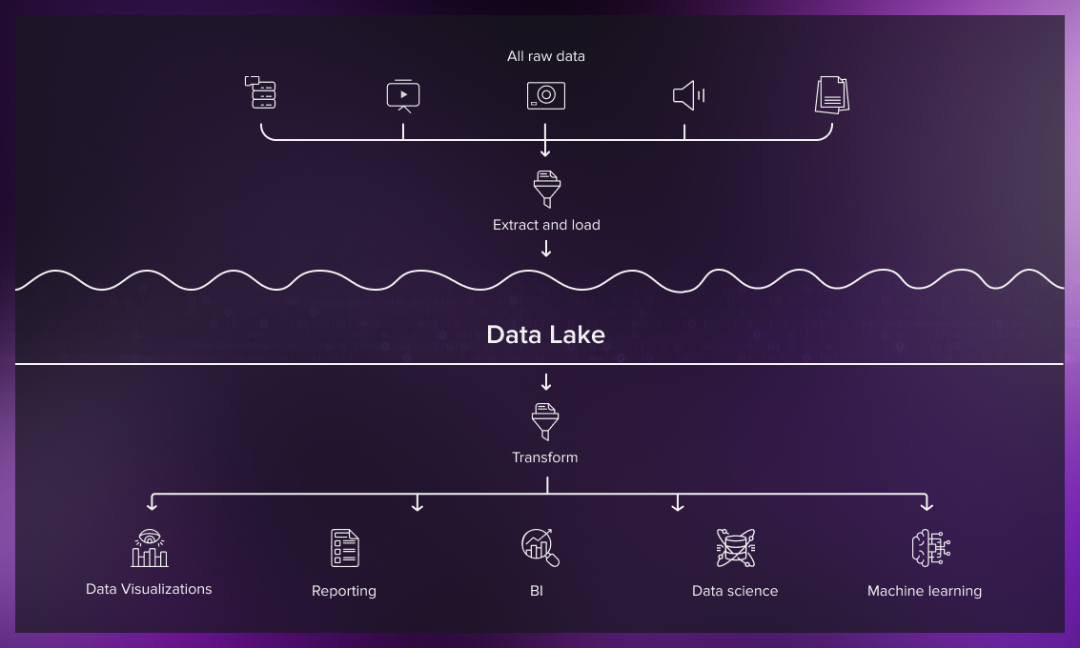
但是,数据湖在数据存储过程中缺乏明确的结构和定义,导致数据质量难以保障,需要进行数据治理以保障一致性和可靠性;同时数据湖的查询实时性也受到影响。因此,融合数仓与数据湖于一体的湖仓产生,以实现数据湖的对象存储功能,并构建数据仓库的数据管控能力。但湖仓一体的完全实现并不简单,目前关键技术迭代快,成熟的产品和系统少。
我们认为以下四个核心技术点对于构建具有卓越性能的数据湖仓不可或缺。
首先是元数据层与数据模式,二者是将多样的原始数据升级为统一模式的基础,对数据质量、数据模式和治理的控制,都要基于明确定义的元数据层。
次之是优化查询性能,传统数据仓库以高性能著称,而数据湖的查询性能受限,数据湖仓要做到通过优化查询来保障性能。
第三是ACID事务支持,数据更新至数据湖仓须保持一致性,这需要通过构建统一的处理引擎来实现数据批量与实时分析。
第四是时间旅行功能,让用户可以回顾历史数据,从而在不同的时点更好地分析数据。
此外,数据治理、一致性和血缘追踪也至关重要,确保数据来源、转换等历程清晰透明。
基于自研全内存分布式计算引擎的优势,以及对上述关键技术点的综合应用,柏睿数据给出了自己的答案——柏睿一体化流湖仓Rapids Lakehouse。
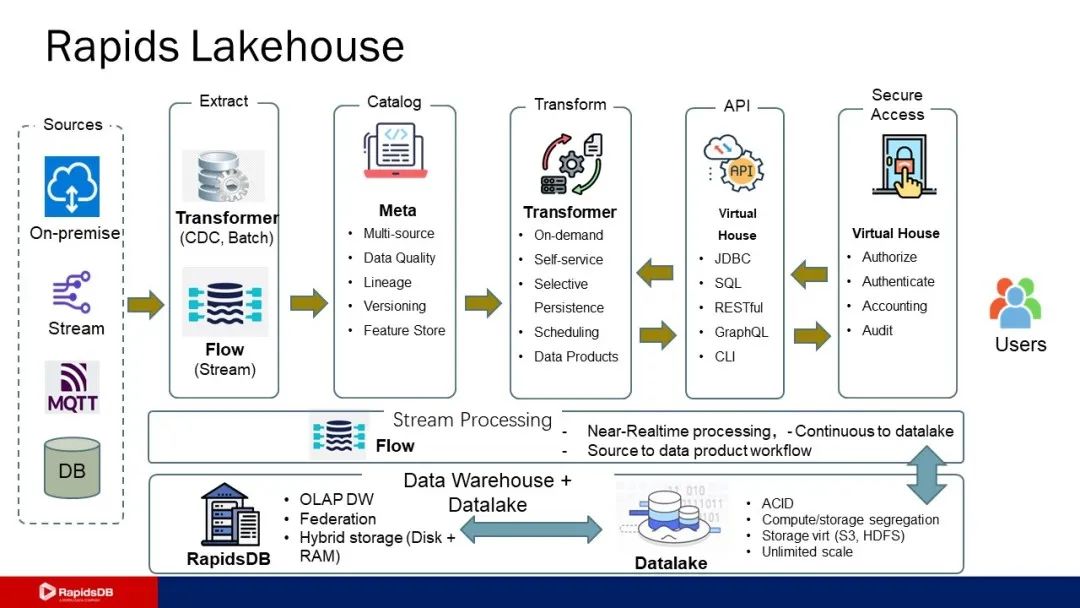
面对商业智能、数据科学等领域的数据发掘和应用需求,柏睿数据采用简单灵活的架构,打造融合数据集成、数据湖、数据仓库的统一数据管理平台,结合人工智能和机器学习技术,助力企业实现即时数据洞察,全面发掘数据价值,提升业务能力和行业领导力。
柏睿一体化流湖仓的数仓部分由全内存分布式数据库RapidsDB构成,数据湖部分由Rapids Datalake构成,并提供一套强大的分布式智能安装程序。
柏睿一体化流湖仓的底层存储层基于网络文件系统构建,支持在本地、云端或多云环境中部署,支持HDFS、S3等分布式文件系统的对象存储;支持各类型的数据文件格式,如ORC、AVRO、Paquet、JSON、PMML等结构化、半结构化、非结构化、标准机器学习模型等开放数据文件格式。
计算层支持Spark、Flink等可插拔的多引擎,提供从数据转换、报表生成,到将结构化数据转换为机器学习工具可用特征的完善功能。
应用层支持不同的应用和工具以SQL、JDBC等标准化方式访问湖仓功能,覆盖数据建模与开发、离线分析、实时计算、交互式分析、机器学习和算法等应用场景。
柏睿一体化流湖仓的功能实现基于四个关键组件。
支持快速的实时数据处理,使用户能够迅速排列和配置实时数据流处理管线,提高工作效率。
具备完整的自助式能力,用户可以利用SQL、Java、Python等在Flow框架内灵活实现业务规则,包括AI功能操作。
支持自定义工具包(SDK),允许用户将自己的程序嵌入到数据流管线中,从而对各种格式数据(如二进制和多媒体数据)进行处理。
原生支持非结构化数据格式,包括MQTT、日志格式、JSON/XML等,确保无缝集成和处理各种数据源。
提供广泛的应用连接器集合,增强整体数据生态系统,实现在多个系统间的无缝数据共享和利用。
Rapids Transformer支持强大、高效、灵活的数据集成和实时同步。连接20+同构和异构数据源,通过变更数据捕获(CDC)或批处理方法提取数据。
CDC可实现从源到目标数据库的实时同步,用户还可以在同步过程中灵活执行高级自定义操作。
高性能的批处理同步功能用来解决CDC同步的挑战,实现了高吞吐量和低延迟之间的平衡;允许用户批量从数据源中提取变更数据,并在用户定义的间隔内将其加载到目标平台上,同时确保过程中数据的一致性和准确性。
Rapids Meta可实现对全量底层数据来龙去脉、演变规矩和数据质量等数据治理目标的统一管理与把控。
支持从多样化数据源中获取与管理元数据。
具备全面的数据治理功能,包括数据目录、数据质量管理、标签管理、数据血缘分析、版本管理和共享、模型解释等。
提供各种增强用户体验和有效数据治理实践的可用性功能,如自由语言搜索、业务术语建立、协作和共享等。
Rapids VirtualHouse为下游分析应用程序和用户提供高性能、统一安全的访问服务,确保与湖仓环境的高效可靠交互。
内置异构数据源管理功能,实现了多样数据源的集成。
创建数据统一视图,用户通过统一的工具即可高效、流畅地访问异构、分散的数据源。
提供用户友好的管理界面,无需深度编码知识,即可轻松导航和操作柏睿一体化流湖仓的各项功能。
同时支持电信服务4A级安全解决方案、企业元数据服务解决方案、多租户支持等,确保数据的完整性、准确性、安全性和私密性。
柏睿一体化流湖仓基于上述架构进行长期探索与实践,具备以下优势特性。
海量实时数据处理
PB级规模多模数据存储,T+0实时在线分析,数据长期归档和复用。
流批兼顾
流处理吞吐量超Spark 40%,延迟低28% ,离线同步速率超20万TPS,CDC平均时延低于4s。
智能场景应用
基于AI算法集成、机器学习、深度学习等10余种算法,满足离线、流式、交互式分析等多场景应用。
高扩展性
计算与存储采用分布式架构,可实现数百节点的横向扩展,支持在线扩容和节点替换,业务不中断。
开放兼容
集群、虚拟化、容器化多种部署模式,兼容多种软硬件与开源数据生态,支持多语言Open API,更易集成。
组装化
在提供一体化湖仓方案的同时,提供组装化产品解决方案,保护客户即有投资、成本控制、支持同行业生态合作。
湖内治理
在提供全保真、可管理、可追溯的数据基础上,为用户提供湖内数据治理以及特征库建设,满足客户数据分析准备与具有行业特征的机器学习训练需求。
在未来,Rapids Lakehouse将聚焦于以下方向演进。
首先,与公司核心产品RapidsDB深度整合。通过与性能领先、应用广泛的分布式全内存数仓紧密融合,柏睿一体化流湖仓将为用户带来更高效、更强大的实时数据处理和分析能力。
支持更多的开放数据格式,以及更广泛的结构化、半结构化数据源,包括多模式数据存储。同时优化数据湖内的数据转换功能,确保数据从源头到湖内的转化过程更加无缝高效。
增强人工智能应用。实现针对大型语言模型的优化功能,如向量存储、嵌入式索引、向量相似搜索及数据集成支持等。
除此之外,还将着重提升数据治理和数据安全能力,确保数据的隐私性和合规性;并实现更高的可扩展性和可管理性,以应对不断增长、日趋复杂的数据处理和应用需求。
推荐阅读



你的 在看 为智能数据算力点赞
