




在上一篇《以 Alpha 101 为例:量化因子的多范式计算方法》一文中,我们以 Alpha#1 和 Alpha#98 两个因子为例,为大家展示了 SQL 和面板两种便捷开发因子的模式,我们建议:
对于日频等低频数据,推荐使用面板模式,结合 DolphinDB 的一系列优化函数,实现既直观、又高效的因子计算。 对于分钟频、快照、逐笔等中高频数据,推荐使用 SQL 模式,结合 DolphinDB 的分区存储方案,高效实现库内并行计算。
对于日频数据,通常是涉及多个截面的复杂计算,我们已经为大家展示了如何用更直观、方便的面板模式计算Alpha#1 和 Alpha#98因子。

👆点击查看《以 Alpha 101 为例:量化因子的多范式计算方法》
数据集展示
在 DolphinDB 中更推荐的做法是,将多档数据存储为 array vector。DolphinDB 中的数组向量 (array vector) 是一种特殊的向量,用于存储可变长度的二维数组,可将数据表中数据类型相同且含义相近的多列存为一列。这样做的好处是,计算代码中可以使用原来的自定义函数,同时提高数据压缩比,提升查询速度。
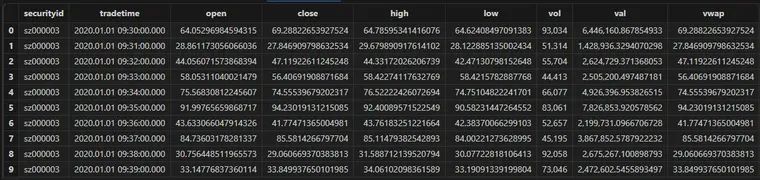
分钟频数据

快照行情数据

用 Array Vector 存储的快照数据
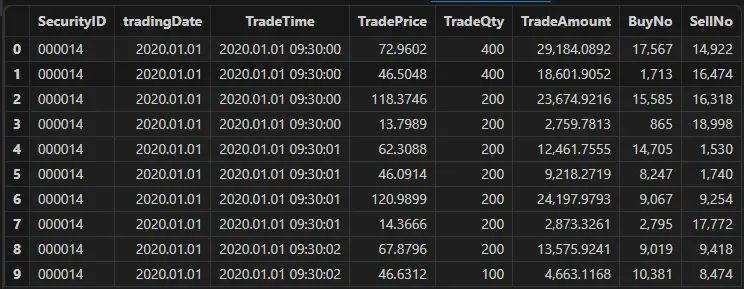
tick 逐笔数据
分钟频数据
defg dayReturnSkew(close){return skew(ratios(close))}minReturn = select `dayReturnSkew as factorname, dayReturnSkew(close) as val from loadTable("dfs://k_minute_level", "k_minute") where date(tradetime) between 2020.01.02 : 2020.01.31 group by date(tradetime) as tradetime, securityid
结果如下所示:
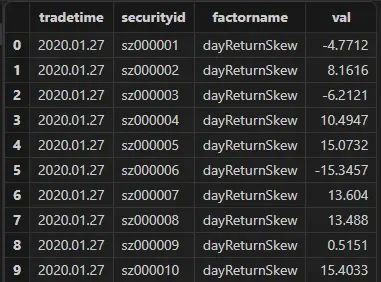
基于快照数据的有状态因子计算
下例 flow 这个自定义函数中,参数为四个列字段,运用 mavg 滑动平均函数以及 iif 条件运算函数,可以直接在 SQL 中得到因子结果:
@statedef flow(buy_vol, sell_vol, askPrice1, bidPrice1){buy_vol_ma = round(mavg(buy_vol, 5*60), 5)sell_vol_ma = round(mavg(sell_vol, 5*60), 5)buy_prop = iif(abs(buy_vol_ma+sell_vol_ma) < 0, 0.5 , buy_vol_ma/ (buy_vol_ma+sell_vol_ma))spd = askPrice1 - bidPrice1spd = iif(spd < 0, 0, spd)spd_ma = round(mavg(spd, 5*60), 5)return iif(spd_ma == 0, 0, buy_prop spd_ma)}res_flow = select TradeTime, SecurityID, `flow as factorname, flow(BidOrderQty[1],OfferOrderQty[1], OfferPrice[1], BidPrice[1]) as val from loadTable("dfs://LEVEL2_Snapshot_ArrayVector","Snap") where date(TradeTime) <= 2020.01.30 and date(TradeTime) >= 2020.01.01 context by SecurityID
结果如下所示:
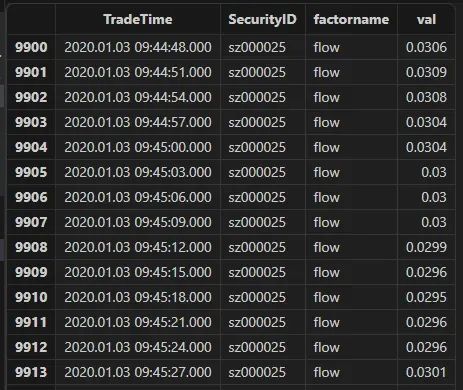
快照数据的
多档赋权无状态因子计算
def mathWghtCovar(x, y, w){v = (x - rowWavg(x, w)) * (y - rowWavg(y, w))return rowWavg(v, w)}@statedef mathWghtSkew(x, w){x_var = mathWghtCovar(x, x, w)x_std = sqrt(x_var)x_1 = x - rowWavg(x, w)x_2 = x_1*x_1len = size(w)adj = sqrt((len - 1) * len) \ (len - 2)skew = rowWsum(x_2, x_1) \ (x_var * x_std) * adj \ lenreturn iif(x_std==0, 0, skew)}//weights:w = 10 9 8 7 6 5 4 3 2 1//权重偏度因子:resWeight = select TradeTime, SecurityID, `mathWghtSkew as factorname, mathWghtSkew(BidPrice, w) as val from loadTable("dfs://LEVEL2_Snapshot_ArrayVector","Snap") where date(TradeTime) = 2020.01.02 mapresWeight1 = select TradeTime, SecurityID, `mathWghtSkew as factorname, mathWghtSkew(matrix(BidPrice0,BidPrice1,BidPrice2,BidPrice3,BidPrice4,BidPrice5,BidPrice6,BidPrice7,BidPrice8,BidPrice9), w) as val from loadTable("dfs://snapshot_SH_L2_TSDB", "snapshot_SH_L2_TSDB") where date(TradeTime) = 2020.01.02 map
输出的因子如下所示:
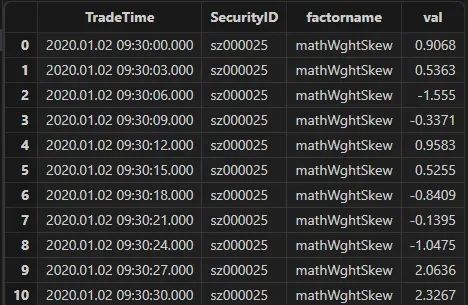
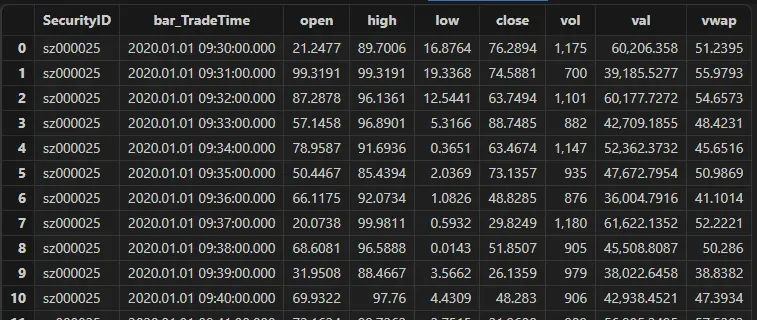
基于快照数据的分钟聚合
//基于快照因子的分钟聚合OHLC,vwaptick_aggr = select first(LastPx) as open, max(LastPx) as high, min(LastPx) as low, last(LastPx) as close, sum(totalvolumetrade) as vol,sum(lastpx*totalvolumetrade) as val,wavg(lastpx, totalvolumetrade) as vwap from loadTable("dfs://LEVEL2_Snapshot_ArrayVector","Snap") where date(TradeTime) <= 2020.01.30 and date(TradeTime) >= 2020.01.01 group by SecurityID, bar(TradeTime,1m)
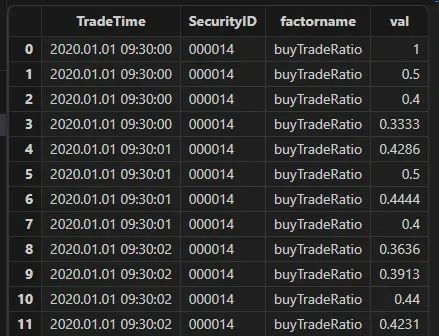
逐笔数据
@statedef buyTradeRatio(buyNo, sellNo, tradeQty){return cumsum(iif(buyNo>sellNo, tradeQty, 0))\cumsum(tradeQty)}factor = select TradeTime, SecurityID, `buyTradeRatio as factorname, buyTradeRatio(BuyNo, SellNo, TradeQty) as val from loadTable("dfs://tick_SH_L2_TSDB","tick_SH_L2_TSDB") where date(TradeTime)<2020.01.31 and time(TradeTime)>=09:30:00.000 context by SecurityID, date(TradeTime) csort TradeTime
结果展示:
下期预告
主买成交量占比因子、大小单、复杂因子Alpha #1……这些因子的实时计算方法将在下一篇中介绍,欢迎关注~
扫码获取因子开发方案👇👇

点击阅读原文,获取因子开发方案!
文章转载自DolphinDB智臾科技,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
