




GaussDB:华为数据库品牌名称
DWS:在GaussDB这一品牌下数据仓库名称
一、版本号介绍
GaussDB(DWS)版本号分为集群版本号、数据库内核版本号
目前最新的内核版本号:8.2.0 (8.2.0.106)、最稳定的内核版本号:
8.1.3版本(8.1.3.322)
发展历程:
2019年08月08日 R8C10(1.5.200)
2020年03月20日 8.0.0(1.7.1、1.7.2)
2020年07月31日 8.0.1
2021年05月15日 8.1.0
2022年04月15日 8.1.3
2022年11月28日 8.2.0
8.1.3版本:发布开始时间:2022年04月15日,目前最新版本:8.1.3.322
对应的发布时间2023年08月04日
8.2.0版本:发布开始时间:2022年11月28日,目前最新版本8.2.0.106
对应的发布时间2023年7月17日
二、DWS 架构
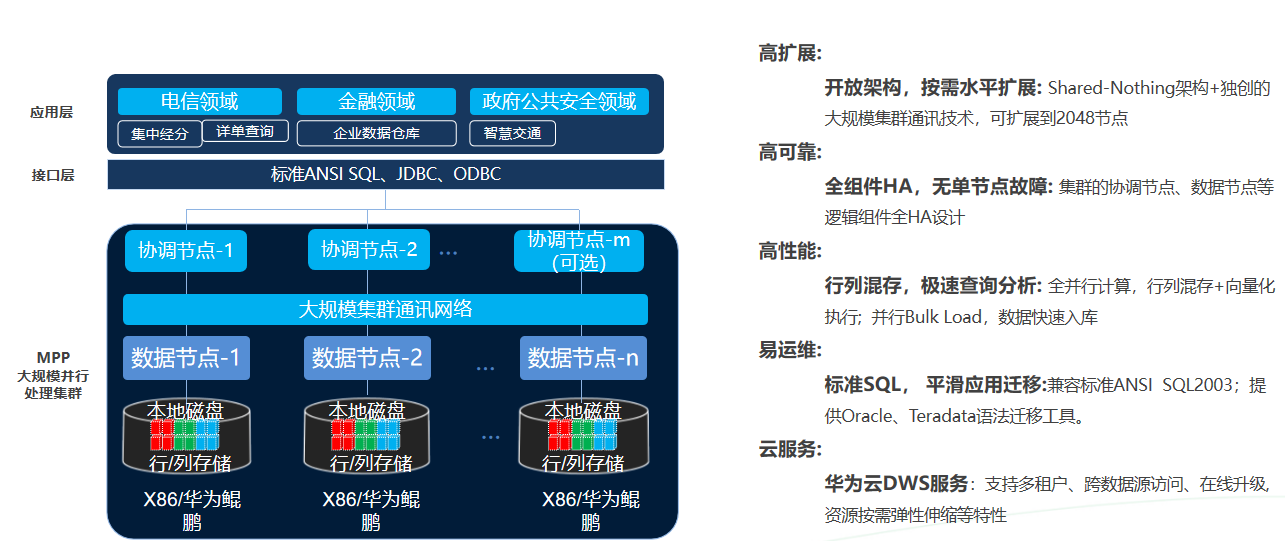
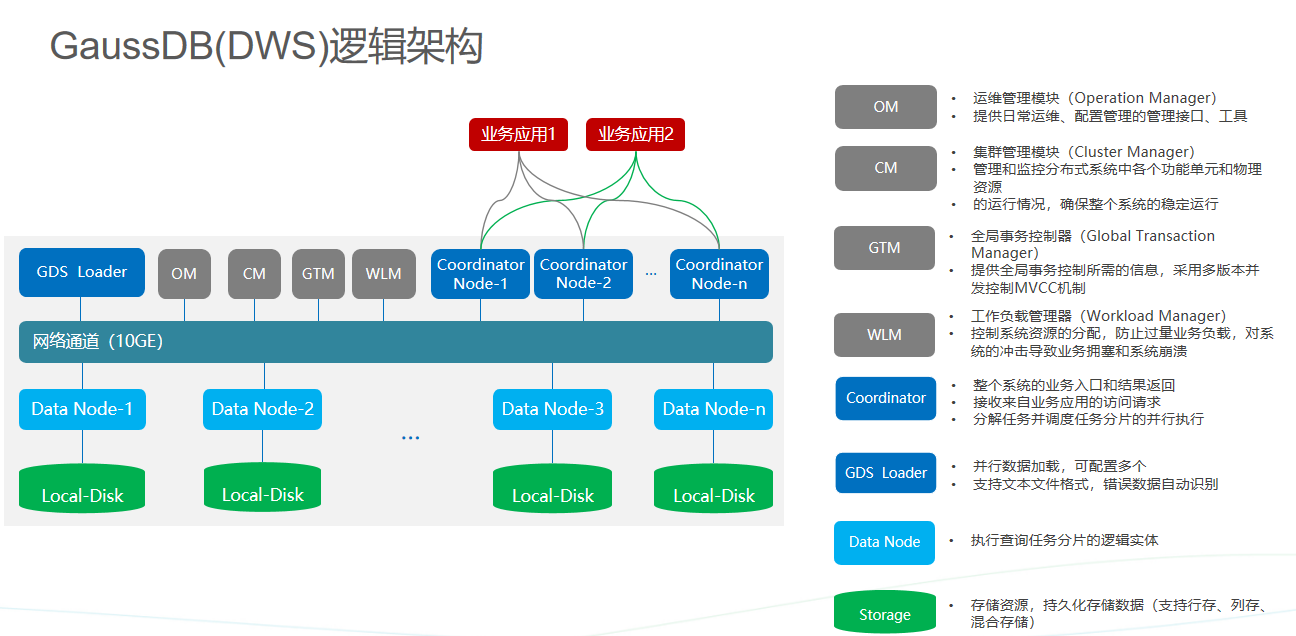
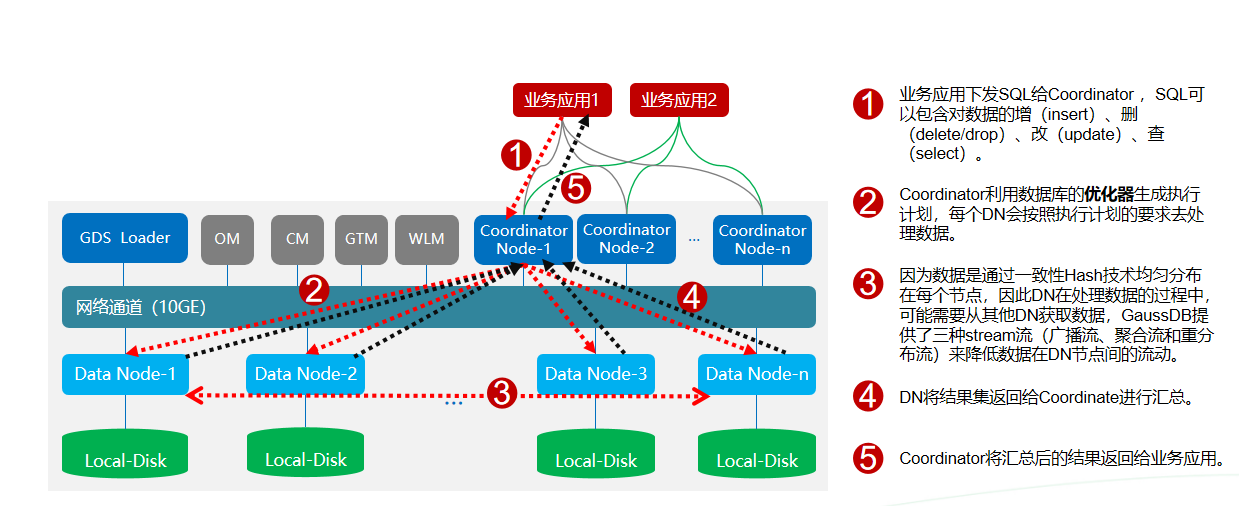
分布式环境的数据布局
为了解决PB级海量数据的高性能查询和数据导入,DWS采用了两层数据布局机制来利用并发度提高性能
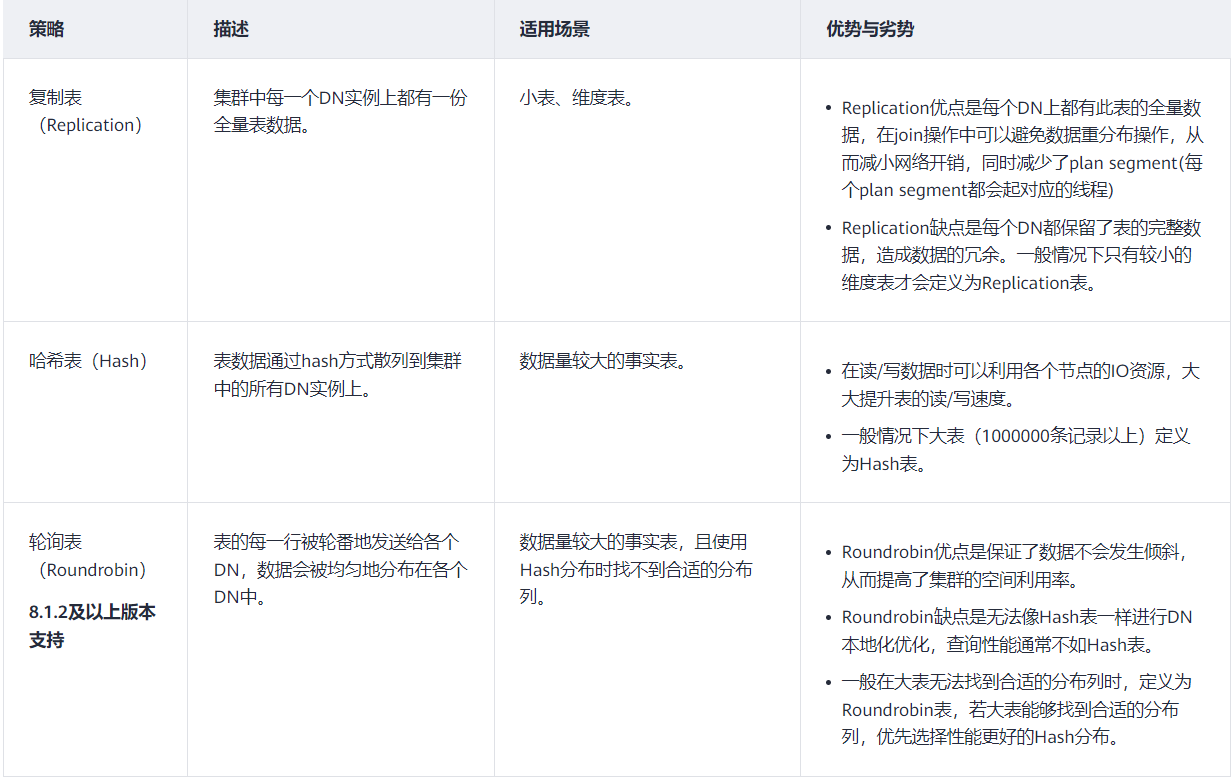
第一层:用户可在创建表时指定数据分布策略(Hash分布、复制分布),数据写入系统时根据对应的分布策略确定存储在哪一个节点上。
第二层,节点内部数据进一步通过分区规则进行细分。
(1)数据分布式存储
DWS采用水平分表的方式,将业务数据表的元组打散存储到各个节点内。这样带来的好处在于,查询中通过查询条件过滤不必要的数据,快速定位到数据存储位置,可极大提升数据库性能。
水平分表方式将一个数据表内的数据,按合适分布策略分散存储在多个节点内,DWS支持如表1所示的数据分布策略。用户可在CREATE TABLE时增加DISTRIBUTE BY参数,来对指定的表应用数据分布功能。
CREATE TABLE CUSTOMER
(
C_CUSTKEY BIGINT NOT NULL CONSTRAINT C_CUSTKEY_pk PRIMARY KEY ,
C_NAME VARCHAR(25) ,
C_ADDRESS VARCHAR(40) ,
C_NATIONKEY INT ,
C_PHONE CHAR(15) ,
C_ACCTBAL DECIMAL(15,2)
)
DISTRIBUTE BY HASH(C_CUSTKEY);
CREATE TABLE customer_address
(
ca_address_sk INTEGER NOT NULL ,
ca_address_id CHARACTER(16) NOT NULL ,
ca_street_number CHARACTER(10) ,
ca_street_name CHARACTER varying(60) ,
ca_street_type CHARACTER(15) ,
ca_suite_number CHARACTER(10)
)
WITH (ORIENTATION = COLUMN, COMPRESSION=HIGH,COLVERSION=2.0)
DISTRIBUTE BY HASH (ca_address_sk);
ORIENTATION:
指定表数据的存储方式,即行存方式、列存方式,该参数设置成功后就不再支持修改。
取值范围:
ROW,表示表的数据将以行式存储。
行存储适合于OLTP业务,此类型的表上交互事务比较多,一次交互会涉及表中的多个列,用行存查询效率较高。
COLUMN,表示表的数据将以列式存储。
列存储适合于数据仓库业务,此类型的表上会做大量的汇聚计算,且涉及的列操作较少。
默认值:ROW,即行存方式。
COMPRESSION:
指定表数据的压缩级别,它决定了表数据的压缩比以及压缩时间。一般来讲,压缩级别越高,压缩比也越大,压缩时间也越长;反之亦然。实际压缩比取决于加载的表数据的分布特征。
取值范围:
列存表的有效值为YES/NO和/LOW/MIDDLE/HIGH,默认值为LOW。当设置为YES时,压缩级别默认为LOW。
行存表压缩功能暂未商用,如需使用请联系技术支持工程师。
COLVERSION:
取值范围:
1.0:列存表的每列以一个单独的文件进行存储,文件名以relfilenode.C1.0、relfilenode.C2.0、relfilenode.C3.0等命名。
2.0:列存表的每列合并存储在一个文件中,文件名以relfilenode.C1.0命名。
说明:
8.1.0集群版本该参数默认值为1.0,8.1.1及以上集群版本该参数默认值为2.0,若集群版本由8.1.0升级至8.1.1或以上版本,该参数默认值也会由1.0变为2.0。
在建列存表时,选择COLVERSION=2.0,相比于1.0存储格式,在以下场景中性能有明显提升:
创建列存宽表场景下,建表时间显著减少。
roach备份数据场景下,备份时间显著减少。
build、catch up耗时显著减少。
占用磁盘空间大小显著减少。
(2)数据分区
数据分区是数据库产品普遍具备的功能。在DWS分布式系统中,数据分区是在一个节点内部按照用户指定的策略对数据做进一步的水平分表,将表按照指定范围划分为多个数据互不重叠的部分(Partition)。
DWS支持范围分区(Range Partitioning)和List分区功能,即根据表的一列或者多列,将要插入表的记录分为若干个范围(这些范围在不同的分区里没有重叠),然后为每个范围创建一个分区,用来存储相应的数据。用户在CREATE TABLE时增加PARTITION参数,即表示针对此表应用数据分区功能。
三、日常运维命令
3.1 如何连接DWS数据库
cd /opt
source gsql_env.sh
进入gsql的bin目录下,执行gsql命令进行数据库连接。
cd bin
gsql -d gaussdb -h 数据库IP -p 8000 -U dbadmin -W 数据库用户密码 -r;
3.2.会话类型命令
查看指定用户的会话连接数上限。
SELECT ROLNAME,ROLCONNLIMIT FROM PG_ROLES WHERE ROLNAME='user1';
SELECT COUNT(*) FROM V$SESSION WHERE USERNAME='user1';
SELECT DATNAME,DATCONNLIMIT FROM PG_DATABASE WHERE DATNAME='';
SELECT COUNT(*) FROM PG_STAT_ACTIVITY WHERE DATNAME='';
杀掉所有空闲会话
select pg_terminate_backend(pid) from pg_stat_activity where state='idle';
在GaussDB(DWS) 控制台设置会话闲置超时时长session_timeout
在GaussDB(DWS) 控制台设置最大连接数max_connections
查看CN进程是否异常重启:
ps -eo pid,lstart,etime,cmd | grep coo
3.3用户、权限用户
--修改密码
SELECT NOW();
SELECT * FROM pgxc_query_audit('2022-10-27 01:00:00','2022-10-27 02:00:00') where username='username';
ALTER USER username ACCOUNT UNLOCK;
ALTER USER username IDENTIFIED BY 'password';
-- 把schema 授权给用户
GRANT USAGE ON SCHEMA schema_name TO u1;
GRANT SELECT ON ALL TABLES IN SCHEMA schema_name TO u1;
执行以下命令,将schema中未来新建的表的权限也赋予指定的用户:
ALTER DEFAULT PRIVILEGES IN SCHEMA schema_name GRANT SELECT ON TABLES TO u1;
--如果需要给某个用户赋权“可查询数据库所有schema里所有表”,
可通过系统表PG_NAMESPACE查询出schema后授权。例如:
SELECT 'grant select on all tables in '|| nspname || 'to u1' FROM pg_namespace;
--禁止如下授权
grant select on table t1 to public
因为执行过grant select on table t1 to public这条sql,该sql中关键字public表示该权限要赋予给所有角色,包括以后创建的角色,所以新用户对该表也有访问权限。public可以看做是一个隐含定义好的组,它总是包含所有角色。
因此,执行完revoke select on table t1 from 新用户之后,虽然新用户没有了该表的访问权限(通过该表的relacl字段也可以看到),但是他仍然有public的权限,所以仍能访问该表。
select relname, relacl from pg_class where relname = 't1'
处理方法
需要revoke回public的权限,然后对use3用户的权限单独管控。但是由于revoke回public的权限后可能导致原来能访问该表的用户(use1和use2)无法访问该表,影响现网业务,因此需要先对这些用户执行grant赋予相应权限,然后revoke回public的权限。
--授权用户创建GDS或OBS外表权限
ALTER USER user_name USEFT;
SELECT rolname,roluseft FROM pg_roles WHERE rolname ='u1' ORDER BY rolname desc;
--有两个用户tom和jerry,jerry想要在tom的同名schema下创建表,于是tom把该schema的all权限赋给jerry
grant all on schema tom to jerry;
grant tom to jerry;
--删除的用户存在依赖关系
3.4.锁等待检测
3.4.1.对于版本8.1.x及以上版本
(1)通过pgxc_lock_conflicts视图查看锁冲突情况。
SELECT * FROM pgxc_lock_conflicts;

上图,回显中查看granted为“f”,表示VACUUM FULL语句正在等待其他锁。
granted为“t”,表示INSERT语句是持有锁。
nodename,表示锁产生在的位置,即CN或DN位置,例如cn_5001
(2)杀锁
execute direct on (cn_5001) 'SELECT PG_TERMINATE_BACKEND(pid)';
3.4.2. 对于版本8.0以下版本
(1)在数据库中执行以下语句,获取操作对应的query_id
SELECT * FROM pgxc_stat_activity WHERE query LIKE '%vacuum%'AND waiting = 't';

(2)根据获取的query_id,执行以下语句查看是否存在锁等待,并获取对应的tid。
SELECT * FROM pgxc_thread_wait_status WHERE query_id = {query_id};

回显中“wait_status”存在“acquire lock”表示存在锁等待。
同时查看“node_name”显示在对应的CN或DN上存在锁等待,记录相应的CN或DN名称
(3)执行以下语句,到等锁的对应CN或DN上从pg_locks中查看VACUUM FULL操作在等待哪个锁。
以下以cn_5001为例,如果在DN上等锁,则改为相应的DN名称。pid为2获取的tid。
回显中记录relation的值。
execute direct on (cn_5001) 'SELECT * FROM pg_locks WHERE pid = {tid} AND granted = ''f''';

(4)根据获取的relation,从pg_locks中查看当前持有锁的pid。{relation}从3获取。
execute direct on (cn_5001) 'SELECT * FROM pg_locks WHERE relation = {relation} AND granted = ''t''';
(5)根据pid,执行以下语句,查到对应的SQL语句。{pid}从4获取。
execute direct on (cn_5001) 'SELECT query FROM pg_stat_activity WHERE pid={pid}';

(6)据语句内容确认是中止持锁语句还是另找时间做VACUUM FULL。
如果终止,则执行以下语句。pid从4获取。中止结束后,再尝试重新执行VACUUM FULL。
execute direct on (cn_5001) 'SELECT PG_TERMINATE_BACKEND(pid)';

SELECT w.query as waiting_query,
w.pid as w_pid,
w.usename as w_user,
l.query as locking_query,
l.pid as l_pid,
l.usename as l_user,
n.nspname || '.' || c.relname as tablename
from pg_stat_activity w join pg_locks l1 on w.pid = l1.pid
and not l1.granted join pg_locks l2 on l1.relation = l2.relation
and l2.granted join pg_stat_activity l on l2.pid = l.pid join pg_class c on c.oid = l1.relation join pg_namespace n on n.oid=c.relnamespace
where w.waiting;
SELECT PG_TERMINATE_BACKEND(PID);
lockwait_timeout单位为毫秒(ms),默认值为20分钟。
3.5 磁盘使用率过高
连接数据库,执行以下SQL语句查询脏页率超过30%的较大表,并且按照表大小从大到小排序。
SELECT schemaname AS schema, relname AS table_name, n_live_tup AS analyze_count, pg_size_pretty(pg_table_size(relid)) as table_size, dirty_page_rate
FROM PGXC_GET_STAT_ALL_TABLES
WHERE schemaName NOT IN ('pg_toast', 'pg_catalog', 'information_schema', 'cstore', 'pmk')
AND dirty_page_rate > 30
ORDER BY table_size DESC, dirty_page_rate DESC;
根据查询结果,对于表大小超过10G的表,执行如下操作。
VACUUM FULL ANALYZE schema.table_name;
将脏页Top5的表,进行VACUUM FULL清理(清理时,最高磁盘空间>70%时,请串行清理)
注意:VACUUM FULL操作会锁表,VACUUM FULL期间,该表的所有访问会阻塞,并等待VACUUM FULL结束,请合理安排调度时间,避免锁表影响业务。
VACUUM FULL是对当前表的有效数据抽出来重新整理,同时清理脏数据,该操作会临时占用额外的整理空间(这部分空间待整理完成后释放),因此空间会先增后降,请提前计算好VACUUM FULL所需要的空间再行处理(额外的整理空间大小=表大小* (1 – 脏页率))。
3.6 SQL执行很慢,性能低,有时长时间运行未结束
问题现象
SQL执行很慢,性能低,有时长时间运行未结束。
原因分析
SQL运行慢可从以下几方面进行分析:
使用EXPLAIN命令查看SQL执行计划,根据执行计划判断是否需要进行SQL调优。
分析查询是否被阻塞,导致语句运行时间过长,可以强制结束有问题的会话。
审视和修改表定义。选择合适的分布列,避免数据倾斜。
分析SQL语句是否使用了不下推的函数,建议更换为支持下推的语法或函数。
对表定期做vacuum full和analyze,可回收已更新或已删除的数据所占据的磁盘空间。
检查表有无索引支撑,建议例行重建索引。
数据库经过多次删除操作后,索引页面上的索引键将被删除,造成索引膨胀。例行重建索引,可有效的提高查询效率。
对业务进行优化,分析能否将大表进行分表设计。
处理方法
(1)查看当前正在运行(非idle)的SQL信息:
SELECT pid,datname,usename,state,waiting,query FROM pgxc_stat_activity WHERE state <> 'idle';
(2)查看当前处于阻塞状态的查询语句:
SELECT pid,datname, usename, state,waiting,query FROM pgxc_stat_activity WHERE state <> 'idle' and waiting=true;
(3)如果有阻塞
SELECT pg_terminate_backend(pid);
(4)如果没有阻塞
ANALYZE table_name;
Vacuum full table_name;
SELECT * FROM pg_size_pretty(pg_table_size('tablename'));
Vacuum full table_name;
3.7 数据倾斜导致SQL执行慢,大表SQL执行无结果
(1)通过等待视图查看作业的运行情况,发现作业总是等待部分DN,或者个别DN
select wait_status, count(*) as cnt from pgxc_thread_wait_status where wait_status not like '%cmd%' and wait_status not like '%none%' and wait_status not like '%quit%' group by 1 order by 2 desc;
(2)执行慢语句的explain performance显示,发现各个DN的基表scan的时间和行数不均衡
explain performance select avg(ss_wholesale_cost) from store_sales;
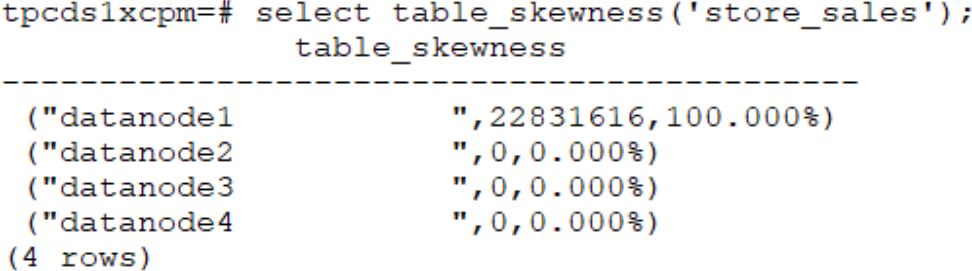
(3)通过倾斜检查接口可以发现数据倾斜。
select table_skewness('store_sales');
select table_distribution('public','store_sales');
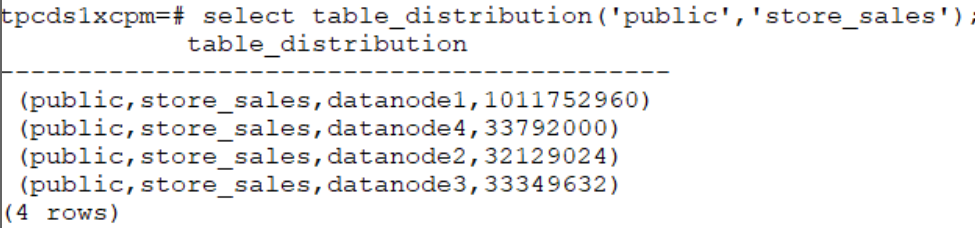
(4)如何找到倾斜的表
SELECT * FROM pgxc_get_table_skewness ORDER BY totalsize DESC;
如果超过1万张表,用上面语句慢,建议用下面语句
8.1.2及之前集群版本中使用table_distribution()函数自定义输出,减少输出列进行计算优化
SELECT schemaname,tablename,max(dnsize) AS maxsize, min(dnsize) AS minsize
FROM pg_catalog.pg_class c
INNER JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
INNER JOIN pg_catalog.table_distribution() s ON s.schemaname = n.nspname AND s.tablename = c.relname
INNER JOIN pg_catalog.pgxc_class x ON c.oid = x.pcrelid AND x.pclocatortype = 'H'
GROUP BY schemaname,tablename;
8.1.3及以上集群版本中支持使用gs_table_distribution()函数,全库查询所有表的数据倾斜情况。全库表查询时,gs_table_distribution()函数优于table_distribution()函数;在大集群大数据量场景下,如果进行全库表表查询,建议优先使用gs_table_distribution()函数。
SELECT schemaname,tablename,max(dnsize) AS maxsize, min(dnsize) AS minsize
FROM pg_catalog.pg_class c
INNER JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
INNER JOIN pg_catalog.gs_table_distribution() s ON s.schemaname = n.nspname AND s.tablename = c.relname
INNER JOIN pg_catalog.pgxc_class x ON c.oid = x.pcrelid AND x.pclocatortype = 'H'
GROUP BY schemaname,tablename;
---使用如下语句可快速查询到大表:
select schemaname||'.'||tablename as table, sum(dnsize) as size from gs_table_distribution() group by 1 order by 2 desc limit 10;
---使用如下语句可快速查询表的倾斜率:
WITH skew AS
(
SELECT
schemaname,
tablename,
pg_catalog.sum(dnsize) AS totalsize,
pg_catalog.avg(dnsize) AS avgsize,
pg_catalog.max(dnsize) AS maxsize,
pg_catalog.min(dnsize) AS minsize,
(pg_catalog.max(dnsize) - pg_catalog.min(dnsize)) AS skewsize,
pg_catalog.stddev(dnsize) AS skewstddev
FROM pg_catalog.pg_class c
INNER JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
INNER JOIN pg_catalog.gs_table_distribution() s ON s.schemaname = n.nspname AND s.tablename = c.relname
INNER JOIN pg_catalog.pgxc_class x ON c.oid = x.pcrelid AND x.pclocatortype IN('H', 'N')
GROUP BY schemaname,tablename
)
SELECT
schemaname,
tablename,
totalsize,
avgsize::numeric(1000),
(maxsize/totalsize)::numeric(4,3) AS maxratio,
(minsize/totalsize)::numeric(4,3) AS minratio,
skewsize,
(skewsize/totalsize)::numeric(4,3) AS skewratio,
skewstddev::numeric(1000)
FROM skew
WHERE totalsize > 0;
表的分布键的选择方法:
如果此列的distinct值比较大,并且没有明显的数据倾斜,也可以把多列定义成分布列。
如何看distinct的大小?
select count(distinct column1) from table;
如何看数据是不是有倾斜?
select count(*) cnt, column1 from table group by column1 order by cnt limit 100;
选用经常做JOIN字段/group by的列,可以减少STREAM运算。
不推荐的实践:
分布列用默认值(第一列)。
分布列用sequence自增生成。
分布列用随机数生成(除非任意列,或者任意两列的组合做分布键都是倾斜的,一般不选用这种方法)。
3.8 VACUUM FULL一张表后,表文件大小无变化
table_name表本身没有delete过数据,使用VACUUM FULL table_name后无需清理delete的数据。因此表大小清理前后一样大。
在执行VACUUM FULL table_name时有并发的事务存在,可能会导致VACUUM FULL跳过清理那些最近删除的数据,导致清理不完全。
对于可能原因的第二种情况,给出如下两种处理方法:
如果在VACUUM FULL时有并发的事务存在,此时需要等待所有事务结束,再次执行VACUUM FULL命令对该表进行清理。
如果使用上面的方法清理后,表文件大小仍然无变化,确认集群中没有正在运行的任务,且所有数据都已经保存后,可使用如下操作方式:
执行以下命令查询当前的事务XID。
select txid_current();
再执行以下命令查看活跃事务列表:
select txid_current_snapshot();
如果发现活跃事务列表中有XID比当前的事务XID小时,重启集群后,再次使用VACUUM FULL命令对该表进行清理。
3.9表数据膨胀导致SQL查询慢,用户前台页面数据加载不出
查看执行计划
查看是否数据倾斜
检查内存相关参数,设置不合理,需要优化。
单节点总内存大小为256G
max_process_memory为12G,设置过小
shared_buffers为32M,设置过小
work_mem:CN:64M 、DN:64M
max_active_statements: -1(不限制并发数)
gs_guc set -Z coordinator -Z datanode -N all -I all -c "max_process_memory=25GB"
gs_guc set -Z coordinator -Z datanode -N all -I all -c "shared_buffers=8GB"
gs_guc set -Z coordinator -Z datanode -N all -I all -c "work_mem=128MB"
进一步分析扫描慢的原因,发现表数据膨胀严重,对其中一张8G大小的表,总数据量5万条,做完vacuum full后大小减小为5.6M。
3.10 集群报错内存溢出
执行以下语句查询当前集群的内存使用情况,
观察是否有实例的dynamic_used_memory已经大于或者接近于该实例的max_dynamic_memory,出现上述报错,一般为dynamic_used_memory达到上限。
select * from pgxc_total_memory_detail;
开启topsql的情况下,使用实时topsql查询正在执行的高内存query语句,根据结果中的max_peak_memory以及memory_skew_percent值,较大的值就是消耗内存较多的语句。
select nodename,pid,dbname,username,application_name,min_peak_memory,max_peak_memory,average_peak_memory,memory_skew_percent,substr(query,0,50) as query from pgxc_wlm_session_statistics;
SELECT pg_terminate_backend(pid);
3.11 sql执行慢排查
(1)未收集统计信息导致查询性能差
处理办法:对语句执行explain verbose时有Warning信息
(2)执行计划中因为有not in走NestLoop导致SQL语句执行慢
处理办法:把not in改成not exists
(3)慢sql过滤条件中未涉及分区字段,导致执行计划未分区剪枝,走了全表扫描,性能严重裂化。
处理办法:把查询条件改成分区健
(4)行数估算过小,优化器选择走NestLoop导致性能下降
处理办法:select * from pg_thread_wait_status where query_id='149181737656737395';
gstack 14104
通过set enable_indexscan = off关闭索引功能,让优化器生成的执行计划不走NestLoop,而走Hashjoin。
(5)语句中存在“in 常量”导致SQL执行无结果
处理办法:set qrw_inlist2join_optmode to rule_base;
(6)动态负载管理下的CCN排队,业务整体缓慢,只有少量语句在执行,其余业务语句都在排队中(wait in ccn queue)。
处理办法:查询pg_session_wlmstat视图,查看status为running的语句是否个数很少,而且statement_mem字段数值是否较大(单位为MB,一般认为大于max_dynamic_memory 1/3即为大内存语句)。如果都符合就可以判断是此类语句占据内存导致整体运行缓慢。
select usename,substr(query,0,20),threadid,status,statement_mem from pg_session_wlmstat where usename not in (''omm'',''Ruby'') order by statement_mem,status desc;
pg_terminate_backend(threadid);
场景二:所有语句状态都是pending状态,没有运行的语句。此时应是管控机制出现异常,直接查杀所有线程,即可恢复正常。
select pg_terminate_backend(pid) from pg_stat_activity where usename not in ('omm','Ruby');
(7)用户执行业务报错:"ERROR: Failed to connect dn_6001_6002, detail:1021 Cannot get stream index, maybe comm_max_stream is not enough.",
处理办法:用户数据库的comm_max_datanode参数为默认值1024,在正常批量业务运行时查到DN之间stream数量大约为600~700,当批量任务运行时如果有临时查询,就会超过上限,导致上述报错。
分析过程
GUC参数comm_max_stream表示任意两个DN之间stream的最大数量。
在CN上查询当前任意两个DN之间stream情况:
select node_name,remote_name,count(*) from pgxc_comm_send_stream group by 1,2 order by 3 desc limit 100;
在DN上查询当前DN与其他DN之间stream情况:
select node_name,remote_name,count(*) from pg_comm_send_stream group by 1,2 order by 3 desc limit 100;
处理措施:修改参数comm_max_stream 1024
(8)ERROR: canceling statement due to statement timeoutTime.
执行语句超时
SET statement_timeout TO 0;
ALTER USER username SET statement_timeout TO 600000;
(9)查询最耗时的SQL
SELECT current_timestamp - query_start AS runtime, datname, usename, query FROM pg_stat_activity where state != 'idle' ORDER BY 1 desc;
SELECT query FROM pg_stat_activity WHERE current_timestamp - query_start > interval '1 days';
(10)执行计划存在“Streaming(type: REDISTRIBUTE)”,即DN根据选定的列把数据重分布到所有的DN,这将导致DN之间存在较大通信数据量
处理结果:需要选择分布健关联。
最后修改时间:2023-08-25 15:17:55
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
