




点击蓝字 关注我们
讲师介绍

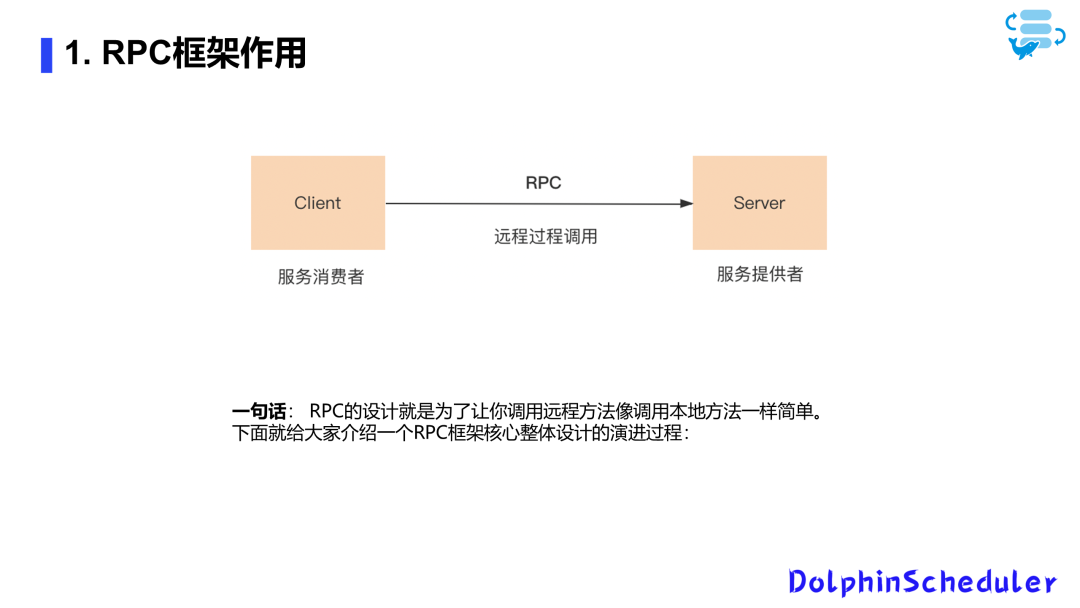
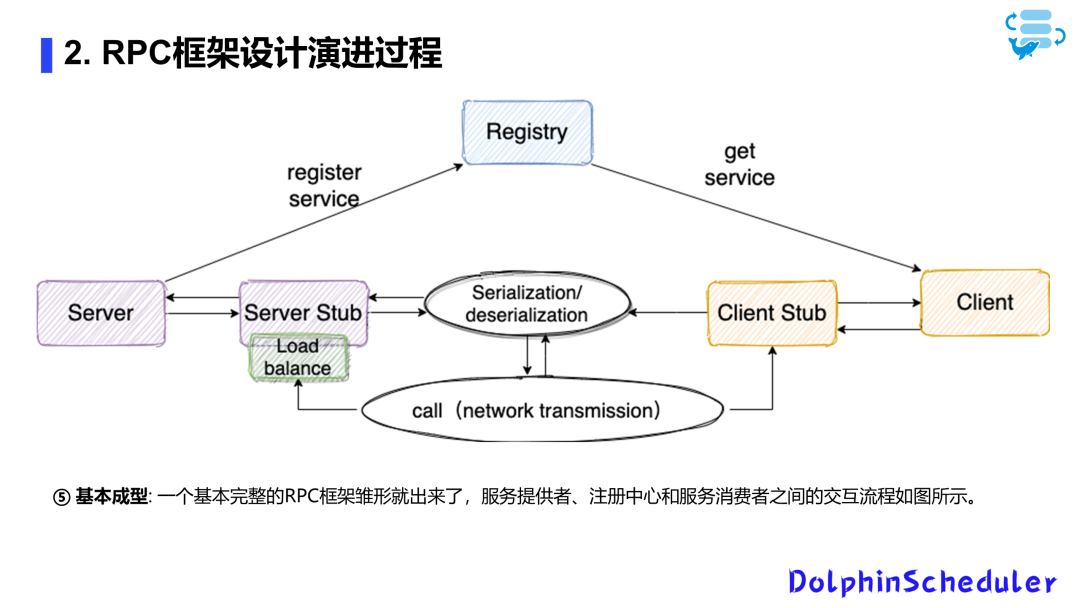
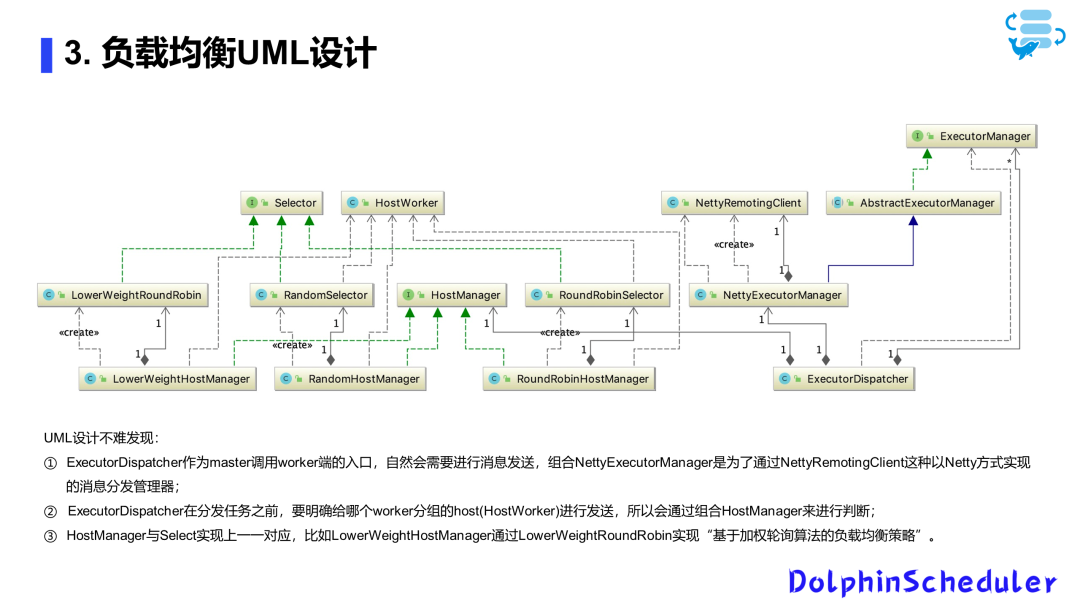
RPC核心架构的演进设计

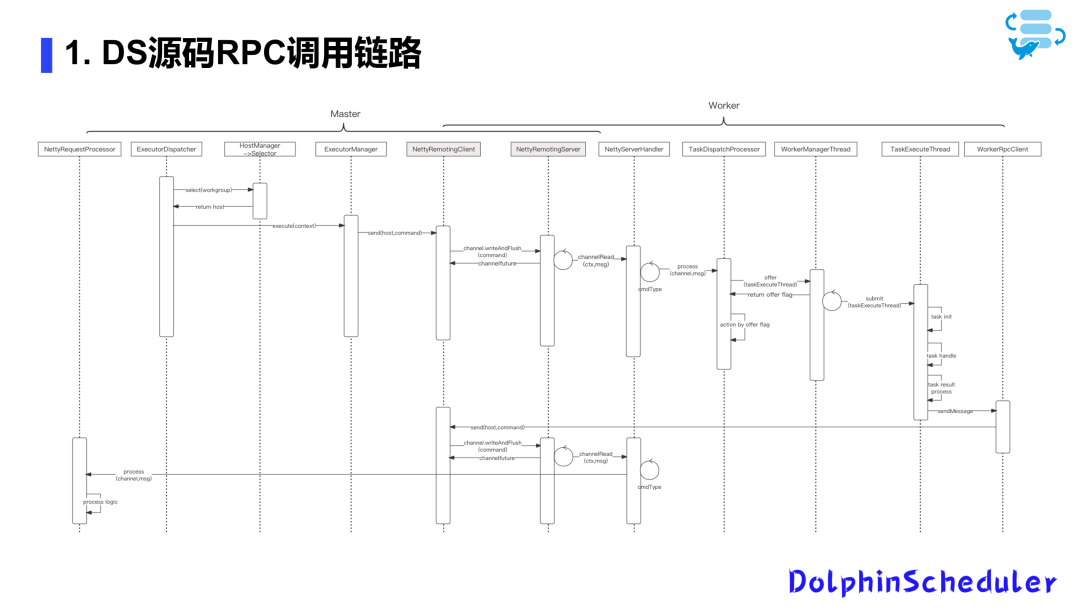
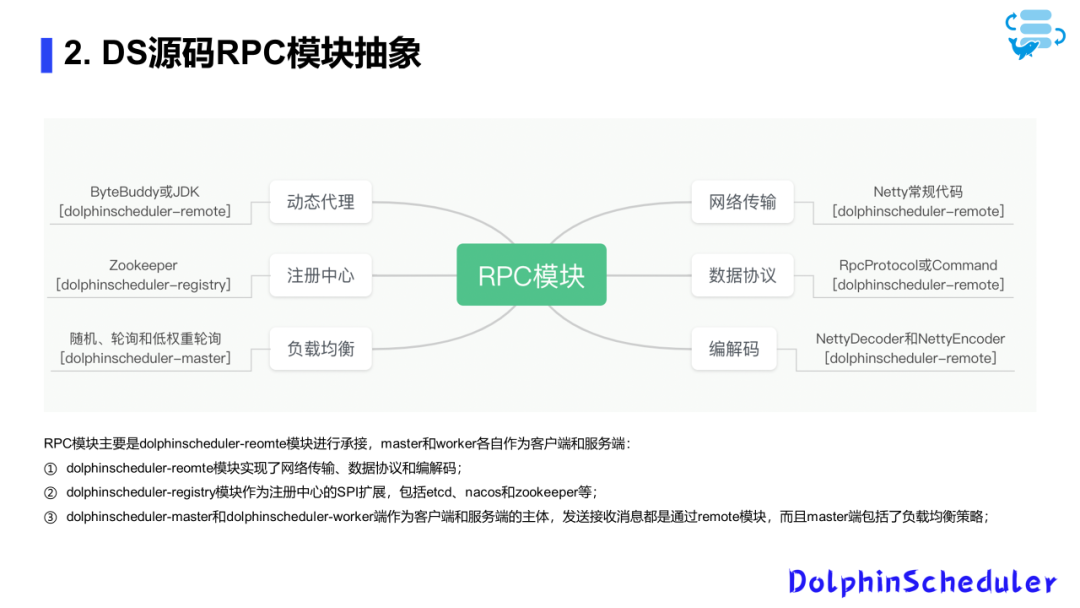
RPC代码剖析

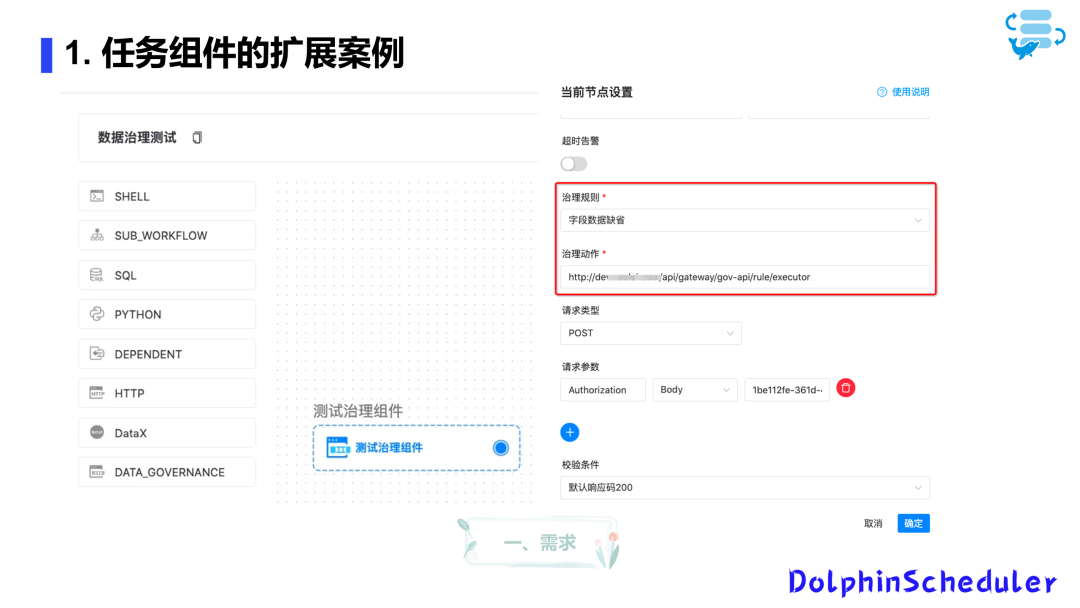
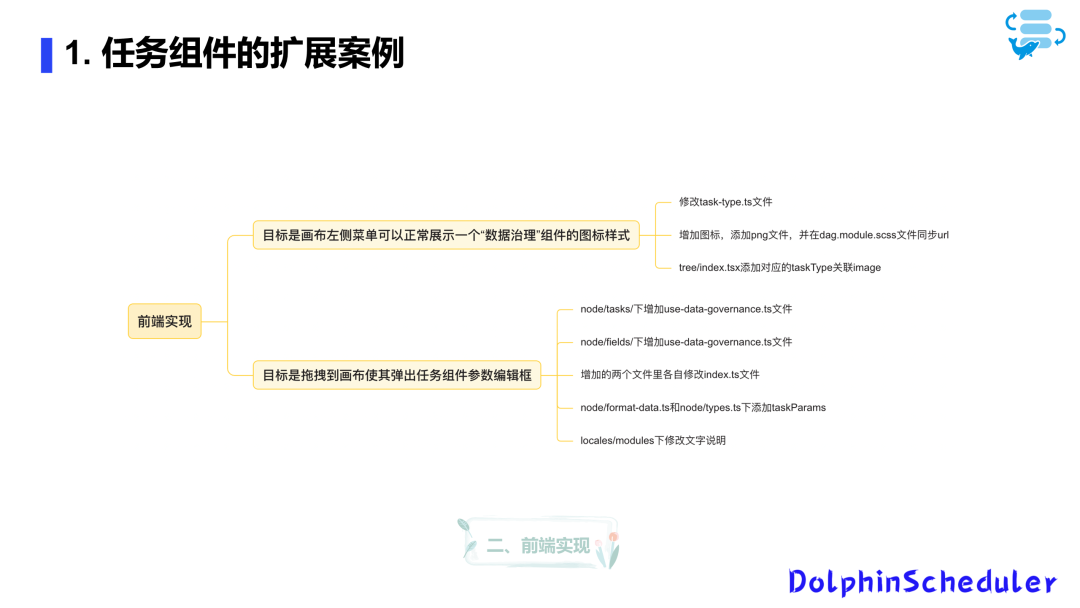
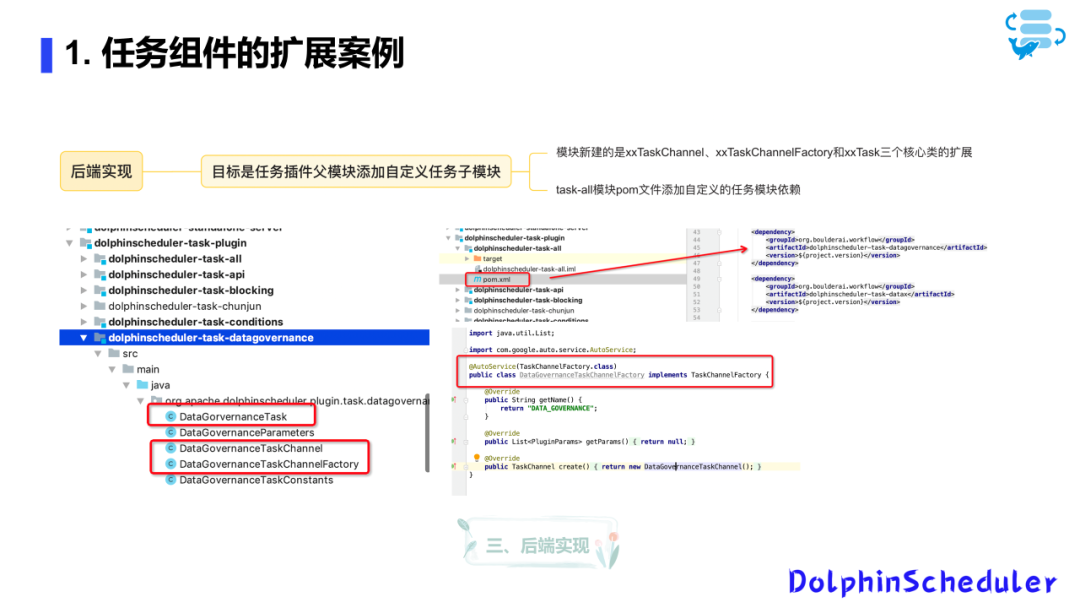
二开实战案例
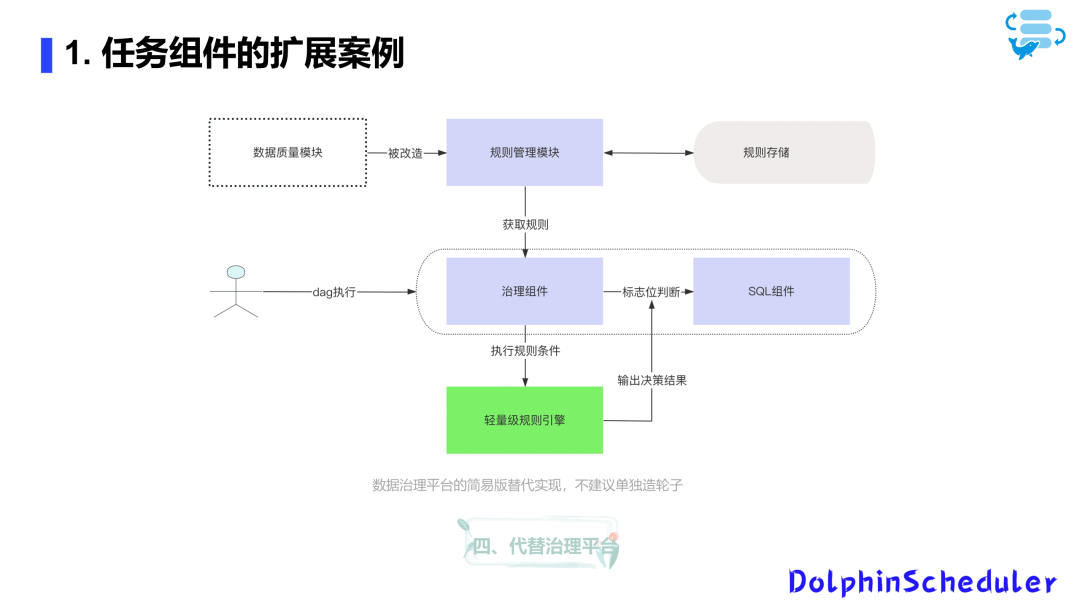
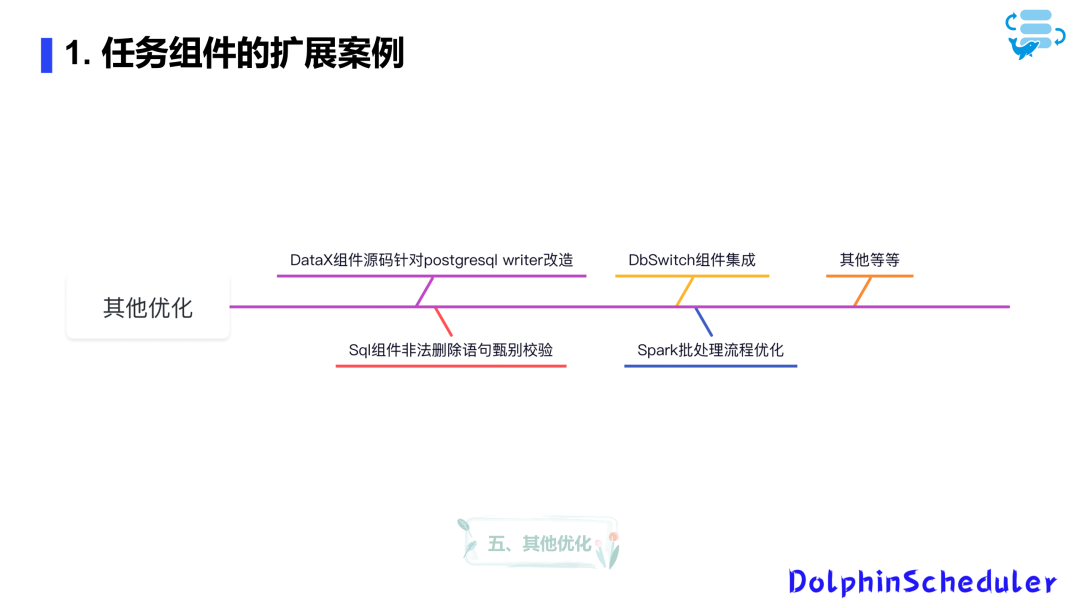
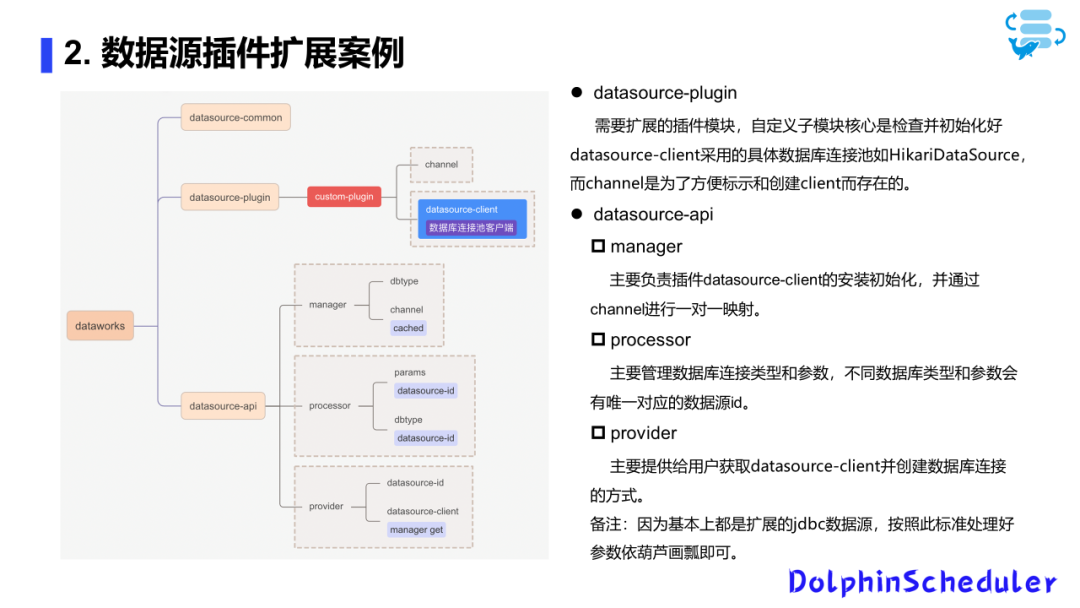
此外,通过Processor的帮助,你可以在创建数据源时使用数据源的参数,根据数据源的ID找到缓存的插件,然后执行相应的操作。
04
总结
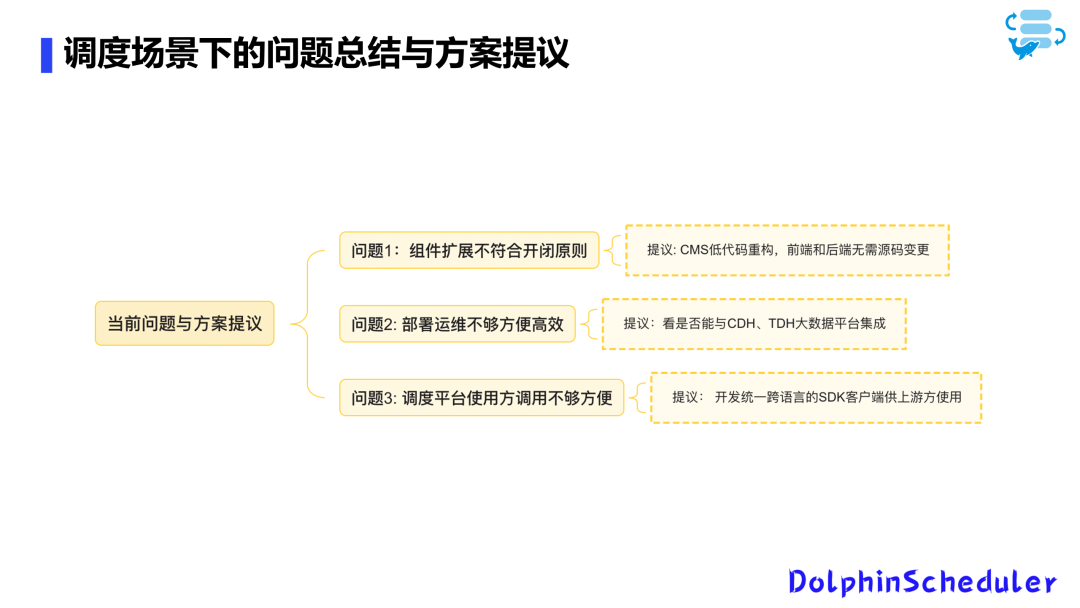
因此,我认为目前虽然有Python的SDK和通过Java中的HTTP调用的方式,但远远不够。我们需要一种统一的跨语言SDK客户端,就像使用RPC客户端一样简单,通过几行代码就能实现调用。我认为后续可以考虑这种客户端,将Python和Java等语言进行统一。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds,好友申请注明“入交流群+姓名+公司+职位信息“,群里是实名制,仅用于验证身份)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
☞Apache DolphinScheduler 荣获“掘进技术引力榜”「2023 年度 ROBUST 开源项目」奖项!

