




Tutorialspoint 数据结构和算法教程
来源:易百教程
数据结构和算法教程™
什么是数据结构?
数据结构是组织数据,以便有效地使用它的系统方法。下列术语的数据结构的基础方面。
- 接口 − 每个数据结构有一个接口。接口表示一个数据结构支持的操作集合。一个接口仅提供支持的操作的列表,参数类型,他们可以接受并返回这些操作的类型。
- 实现 − 实现提供了数据结构的内部表示。实现还提供了在数据结构的操作中使用的算法的定义。
数据结构的特征
- 正确性 − 数据结构的实现应该正确地实现它的接口。
- 时间复杂度 − 运行时间或数据结构的操作的执行时间必须尽可能的小。
- 空间复杂度 − 数据结构操作的内存使用量应尽可能少。
数据结构的需要
随着应用程序越来越复杂和数据丰富,有三种常见的问题应用要面临。
- 数据搜索 − 考虑100万(106)物品商店的清单。如果应用程序搜索一个项目。它需要搜索项目100万次(106) 项目每次减慢搜索。随着数据的增长,搜索将变得更加缓慢。
- 处理器速度 − 处理器速度虽然是非常高的,属于有限的,如果数据增长到十亿的记录。
- 多个请求 − 随着成千上万的用户可以同时搜索Web服务器上的数据,甚至是非常快的服务器,也有可能搜索数据失败。
为了解决上述问题,使用数据结构来解救。数据可以组织在数据结构中,使得在一种方式在所有的项目可以不要求搜索和所需的数据,可几乎立即搜索。
执行时间案例
有三种情况通常用于相对地对各种数据结构的执行时间进行比较。
- 最坏的情况 − 这是一个特定的数据结构操作,需要采取的最大时间的方案。如果一个操作的最坏情况下的时间是:ƒ(n),那么这个操作不会花时间超过ƒ(n)的时间,其中: ƒ(n)表示n个函数。
- 平均情况 − 这是该方案描绘的数据结构的一个操作的平均执行时间。如果一个操作需要:ƒ(n)时间执行,则 m 的操作将采取mƒ(n)的时间。
- 最佳案例 − 这是该方案描绘的数据结构的一个操作,至少可能的执行时间。如果一个操作需要ƒ(n)的时间,然后执行实际操作可能需要一段时间的随机数,这将是最大到 ƒ(N)。
基本术语
- 数据 − 数据值或设定值。
- 数据项 − 数据项是指值的一个单元。
- 组项 − 被划分为子项数据项被称为组项目。
- 基本项目 − 不能分割数据项被称为基本项目。
- 属性和实体 − 实体是含有某些属性或可被分配的值的属性。
- 实体集 − 类似属性的实体构成的实体集。
- 字段 − 字段是信息表示一个实体的属性单个基本单元。
- 记录 − 记录是一个给定的实体的字段值的集合。
- 文件 − 文件是在给定实体集的实体记录的集合。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 数据结构和算法教程
环境设置 - 数据结构和算法教程™
本地环境设置
如果愿意设置C语言编程环境,需要在您的计算机上提供以下两个软件:(一)文本编辑器;(二)C编译器。
文本编辑器
这将被用来输入/编写程序。 少数的编辑的实例包括:Windows Notepad, OS Edit command, Brief, Epsilon, EMACS, 和 vim / vi。
文本编辑器的名称和版本在不同的操作系统可能有变化。例如,记事本可用在 Windows , VIM 或 vi 可以在 Windows中也可以在 Linux或UNIX 上使用。
编辑器中创建的文件称为源文件,它包含程序源代码。对于C程序的源文件通常命名扩展为 ".c".
在开始编程之前,请确保有一个文本编辑器,有足够的经验来编写计算机程序,保存在一个文件,编译并最终执行。
C编译器
写在源文件中的源代码是人类可读的源代码程序。它需要“编译”,转成机器语言,使 CPU 能够真正执行程序按给定的指令。
C语言编译器将用于将源代码编译到最终的可执行程序。学习本教程前,假设你有关于一门编程语言编译器的基础知识。
最常用的和免费提供的编译器是GNU C/C++编译器,也可以使用 HP 或 Solaris 的编译器,如果你有相应的操作系统的话。
以下部分将指导如何在不同的操作系统上安装GNU C/C++编译器。我们这里使用的是 C/C++,因为 GNU gcc 编译器适用于 C 和 C++ 编程语言。
在UNIX/Linux上安装
如果您使用的是 Linux 或 UNIX,然后通过在命令行中输入以下命令来检查 GCC 是否已在系统上安装 −
$ gcc -v
如果 GNU 编译器已安装在您的计算机上,那么它应该如下打印信息的东西:
Using built-in specs.
Target: i386-redhat-linux
Configured with: ../configure --prefix=/usr .......
Thread model: posix
gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)
如果没有安装GCC,那么参考详细说明 http://gcc.gnu.org/install/
本教程基于Linux(Ubuntu),所有给出的例子已编译在 Linux系统之上测试通过。
在Mac OS安装
如果使用的是Mac OS X,获得GCC最简单的方法是下载从苹果的网站上下载 Xcode 开发工具,并按照简单的安装说明。 设置了 Xcode 以后就可以使用 GNU 编译器的C/C++。
Xcode是目前可在以下网址找到:developer.apple.com/technologies/tools/.
在Windowx上安装
要在 Windows 中安装 GCC,首先需要安装MinGW。要安装MinGW,访问 MinGW的主页:www.mingw.org, 并按照链接到 MinGW 的下载页面。下载 MinGW 的安装程序,它应该被命名为 MinGW-<版本>.exe 文件的最新版本。
在安装MinWG,至少必须安装 gcc-core, gcc-g++, binutils 和 MinGW 运行时,但可能需要安装更多组件。
添加 MinGW 的安装目录的 bin 子目录到 PATH 环境变量中,这样就可以直接使用名称在命令行上指定使用这些工具。
当安装完成后,就可以从Windows命令行运行 gcc, g++, ar, ranlib, dlltool 和 其他几个GNU工具。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
数据结构算法基础 - 数据结构和算法教程™
算法是一步步的过程,它定义一组指令在一定的顺序,以执行获得所需的输出。算法通常在独立的基本语言,即一种算法可以在一个以上的程序设计语言中实现。
但从数据结构来看,以下是算法的一些重要类别 −
- 搜索 − 在一个数据结构中搜索一个项目算法。
- 排序− 排序在某些顺序算法
- 插入 − 在数据结构中插入项算法
- 更新 − 在数据结构中更新现有的项算法
- 删除 − 从数据结构中删除现有项目算法
算法的特点
并非所有的程序可以被称为一种算法。算法应具有下面特征 -
- 明确 − 算法应该是明确的,毫不含糊的。它的每个步骤(或相),和它们的输入/输出的应明确和必须导致只有一个意思
- 输入 − 算法应该具有0个或多个明确定义的输入
- 输出 − 算法应该有1个或多个明确定义的输出,并且应当匹配所需的输出
- 有限性 − 算法必须终止在有限的之后的步骤
- 可能性 − 应当与可用资源是可行的
- 独立 − 算法应该有逐步的方向,应该是独立于任何编程代码
如何写一个算法?
没有用于写入的算法定义明确的标准。相反,它是问题和资源依存。算法不是写来支持特定的编程代码。
我们知道,所有的编程语言共享基础代码结构,如循环(do, for, while),流程控制(if-else)等。这些常见的结构可用于写一种算法。
我们以一步一个脚印的方式来写算法,但它并非总是如此。算法的编写是一个过程,是执行的明确定义的问题域之后。也就是说,我们应该知道问题域,为此我们设计一个解决方案。
示例
让我们尝试用一个例子来学习算法的编写。
问题 − 设计一个算法,两个数字相加并显示结果。
step 1 − START
step 2 − declare three integers a, b & c
step 3 − define values of a & b
step 4 − add values of a & b
step 5 − store output of step 4 to c
step 6 − print c
step 7 − STOP
算法告诉程序员如何编写程序。可替代地,算法可以写为 −
step 1 − START ADD
step 2 − get values of a & b
step 3 − c ← a + b
step 4 − display c
step 5 − STOP
在设计和算法分析,通常第二个方法是,用于描述的算法。它可以很容易的分析算法忽略所有不必要的定义。可以观察正在使用什么操作方法以及该过程是流动的。
写入步骤的数字是可选的。
我们设计一个算法,获得特定问题的解决方案。问题可以有一个以上的方式解决。
因此,许多解决方案的算法可以衍生为一个给定的问题。下一步就是分析这些提议解决方案的算法和实现最适合的。
算法分析
算法的效率可以在两个不同的阶段进行分析,实施前和实施后,如下所述 −
- 先验分析 − 这是一种算法的理论分析。算法的效率是通过假设所有其它因素,例如测量,处理器速度,是常数,对实施无影响。
- 后验分析 − 这是一种算法的实证分析。所选的算法使用编程语言来实现。这接着目标计算机的机器上执行。在这种分析中,实际统计像运行时间和所需的空间,会被收集。
我们将在这里学习的先验算法分析。算法分析与处理涉及的各种操作的执行或运行时间。操作的运行时间可以定义为每操作来执行的计算机指令编号。
算法复杂度
假设X是一种算法,n是输入数据的大小,所使用算法 X 的时间和空间是决定 X 的效率的两个主要因素:
- 时间因素 − 时间是通过计算键操作的数量来衡量,例如,在排序算法的比较
- 空间因素 − 空间是通过计数,由算法所需的最大存储器空间来测量。
在一个算法F(N)算法测量运行时间和/或存储空间复杂性,输入数据的规模是必需的。
空间复杂度
算法空间的复杂性表示存储器空间由该算法在其生命周期所需的时间。算法所需的空间等于以下两个要素的总和 −
- 固定部件是存储某些数据和变量,是独立的问题的大小所需的空间。例如,简单变量和常量在使用,程序大小等。
- 可变部分是由变量所需要的空间,其大小取决于问题的大小。例如动态内存分配,递归栈空间等。
任何算法的 P 空间复杂度 S(P)是 S(P) = C + SP(I),其中 C 是固定部分和S(I)在算法中是可变部分这依赖于实例特征 I 。下面是一个简单的例子,试图解释这一概念 −
Algorithm: SUM(A, B)
Step 1 - START
Step 2 - C ← A + B + 10
Step 3 - Stop
在这里,我们有三个变量A,B和C和一个常数。这里 S(P)=1+3. 现在空间取决于数据类型定变量和常数类型,它会相应地相乘。
时间复杂度
算法的时间复杂度表示运行到完成算法所需的时间量。时间要求可以被定义为一个数值函数 T(n), 这里 T(n) 可测的步骤的数量,提供的每个步骤消耗恒定的时间。
例如,增加了两个n位整数需要n步。因此,总的计算时间是 T(n)= c*n, 这里 c 是采取另外两个比特的时间。这里可以观察到 T(n)的线性增长作为输入大小增加。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 数据结构算法基础
数据结构渐近分析 - 数据结构和算法教程™
算法的渐近分析,指的是定义它的运行时性能的数学基础/帧。利用渐近分析,我们可以很好地得出一种算法结论:最好的情况,平均情况和最坏的情况。
渐近分析输入的约束,即如果没有输入到算法可以断定在一个恒定的时间工作。而非 “输入” 的其他因素都被认为恒量。
渐近分析是指计算中的数学单元的任何操作的运行时间。例如,一种操作的运行时间被计算为 f(n),以及用于另一操作它计算为 g(n2)。这意味着第一操作运行时间线性增加而增加,n 和运行第二操作时间会在 n 增加时成倍增加。同样地,如果 n 足够小,那么两个操作的运行时间将几乎相同。
通常情况下,由算法所需要的时间在三种类型 −
- 最好情况 − 程序执行所需的最短时间。
- 平均情况 − 程序执行所需的平均时间。
- 最坏情况 − 程序执行所需的最长时间。
渐近表示法
下面是常用的,在计算运行时间的算法的复杂性使用渐近符号。
- Ο 标注
- Ω 标注
- θ 标注
大标注,Ο
Ο(n)是表达的上限的算法的运行时间的正式方法。它测量的最坏情况下的时间复杂度和时间的算法可能才能完成最长时间。 For example, for a function例如,对于一个函数f(n)
Ο(
f
(
n
))
=
{
g
(
n
)
:
there exists c
>
0
and
n
0
such that
g
(
n
)
≤
c
.
f
(
n
)
for
all n
>
n
0
.
}
欧米茄标注, Ω
Ω(n)是表达的下界的算法的运行时间的正式方法。它衡量最好情况下的时间复杂度和时间的算法可能才能完成最佳用量。
例如,对于一个函数 f(n)
Ω(
f
(
n
))
≥
{
g
(
n
)
:
there exists c
>
0
and
n
0
such that
g
(
n
)
≤
c
.
f
(
n
)
for
all n
>
n
0
.
}
西塔标注, θ
θ(n)表达正式的方式,既下界和上界的算法的运行时间。它被表示为如下。
θ(
f
(
n
))
=
{
g
(
n
)
if
and
only
if
g
(
n
)
=
Ο(
f
(
n
))
and
g
(
n
)
=
Ω(
f
(
n
))
for
all n
>
n
0
.
}
常量 | − | Ο(1) |
对数 | − | Ο(log n) |
线性 | − | Ο(n) |
n log n | − | Ο(n log n) |
二次 | − | Ο(n2) |
立方 | − | Ο(n3) |
多项式 | − | nΟ(1) |
指数 | − | 2Ο(n) |
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 数据结构渐近分析
数据结构基本概念 - 数据结构和算法教程™
数据结构是一种能够以这样一种方式,它可以有效地利用组织的数据。本教程介绍了相关的数据结构的基本条件。
数据定义
数据定义定义了以下特征的特定数据。
- 原子性 − 定义应该定义一个单一的概念
- 可追溯 − 定义应能够被映射到一些数据元素。
- 准确性 − 定义应该是毫不含糊的。
- 简洁明了 − 定义应该是可以理解的。
数据对象
数据对象表示具有数据的对象。
数据类型
数据类型是各种类型的数据的分类方式,例如整型,字符串等。这决定了能够与相应数据的类型,操作的类型,可以在相应的数据类型来执行的类型中使用的值。有两种类型的数据类型-
- 内置数据类型
- 导出的数据类型
内置数据类型
这些数据类型是一种语言的内置支持,被称为内置数据类型。例如,大部分的语言提供了以下内置数据类型。
- 整数
- 布尔(true, false)
- 浮点(十进制数)
- 字符和字符串
导出数据类型
这些数据类型它们是独立实现的,因为它们可以在一个或其他的方式来实现,叫作导出的数据类型。这些数据类型通常是由它们主要或内建的数据类型和相关联的操作的组合来构建。例如 -
- 列表
- 数组
- 栈
- 队列
基本操作
在数据结构中的数据通过特定的操作进行处理。选择很大程度上是特定的数据结构依赖于需要在该数据结构执行操作的频率。
- 遍历
- 搜索
- 插入
- 删除
- 排序
- 合并
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 数据结构基本概念
数组 - 数据结构和算法教程™
数组基础知识
数组是一个容器,该容器可容纳固定数目项目,这些项目应该都是相同的类型。大多数的数据结构的利用数组来实现它们的算法。以下我们来了解数组中的概念和一些重要的术语。
- 元素 − 存储在数组中的每个项被称为一个元素。
- 索引 − 在一个数组元素所在的每个位置,是具有一个用于识别该元素的数值索引。
数组表示
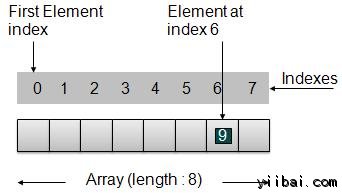
按照如上所示图中,以下是要考虑的重要问题。
- 索引从 0 开始
- 数组的长度为 8,这意味着它可以存储 8 个元素。
- 每个元素可以通过它的索引来访问。例如,我们可以在索引6获取元素的值:9。
基本操作
以下是由数组所支持的基本操作。
- 遍历 − 一个一个地打印所有的数组元素。
- 插入 − 给定索引处添加(插入)元素。
- 删除 − 删除给定索引处的元素。
- 搜索 − 搜索用特定索引或元素值。
- 更新 − 更新给定索引处的元素。
在C语言中,当初始化一个数组大小,然后将其分配元素的默认值,在下列顺序。
数据类型 | 默认值 |
bool | false |
char | 0 |
int | 0 |
float | 0.0 |
double | 0.0f |
void | |
wchar_t | 0 |
插入操作
插入操作是插入一个或多个数据元素到一个数组。根据要求,新元素可以在开始,结束或数组中的任何给定的索引位置加入。
在这里,可以看到插入操作的实际执行,我们在数组的末尾添加(插入)数据 −
算法
数组是一个有 MAX 个元素的线性无序数组。
示例
结果
LA是一个线性数组(无序)配有N个元素,K是正整数且 K<= N。 下面就是 ITEM 插入到 LA 的第 K 个位置的算法
1. Start
2. Set J = N
3. Set N = N+1
4. Repeat steps 5 and 6 while J >= K
5. Set LA[J+1] = LA[J]
6. Set J = J-1
7. Set LA[K] = ITEM
8. Stop
示例
下面是上述算法的执行 −
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
n = n + 1;
while( j >= k){
LA[j+1] = LA[j];
j = j - 1;
}
LA[k] = item;
printf("The array elements after insertion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}
当编译和执行,上面的程序产生以下结果 -
The original array elements are :
LA[0]=1
LA[1]=3
LA[2]=5
LA[3]=7
LA[4]=8
The array elements after insertion :
LA[0]=1
LA[1]=3
LA[2]=5
LA[3]=10
LA[4]=7
LA[5]=8
删除操作
删除指从数组中删除去现有元素,并重新组织数组的所有元素。
算法
考虑 LA 是一个具有 n 个元素线性数组,以及 K 是正整数,其中 K<= N。下面的算法是删除在 LA 中第 K 个位置的可用元素。
1. Start
2. Set J = K
3. Repeat steps 4 and 5 while J < N
4. Set LA[J-1] = LA[J]
5. Set J = J+1
6. Set N = N-1
7. Stop
示例
下面是上述算法的执行 −
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
j = k;
while( j < n){
LA[j-1] = LA[j];
j = j + 1;
}
n = n -1;
printf("The array elements after deletion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}
当编译和执行,上面的程序产生以下结果 -
The original array elements are :
LA[0]=1
LA[1]=3
LA[2]=5
LA[3]=7
LA[4]=8
The array elements after deletion :
LA[0]=1
LA[1]=3
LA[2]=7
LA[3]=8
搜索操作
可以在数组元素的值或它的索引执行搜索。
算法
考虑 LA 是一个具有 n 个元素线性数组,以及 K 是正整数,如 K<= N。下面的算法是使用顺序搜索找出元素 ITEM 的值。
1. Start
2. Set J = 0
3. Repeat steps 4 and 5 while J < N
4. IF LA[J] is equal ITEM THEN GOTO STEP 6
5. Set J = J +1
6. PRINT J, ITEM
7. Stop
示例
下面是上述算法的执行 -
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 5, n = 5;
int i = 0, j = 0;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
while( j < n){
if( LA[j] == item ){
break;
}
j = j + 1;
}
printf("Found element %d at position %d\n", item, j+1);
}
当编译和执行,上面的程序产生以下结果 -
The original array elements are :
LA[0]=1
LA[1]=3
LA[2]=5
LA[3]=7
LA[4]=8
Found element 5 at position 3
更新操作
更新操作是从数组指定索引处更新指定的现有元素。
算法
考虑 LA 是一个具有 n 个元素线性数组,K是正整数,且 K<= N。下面算法是更新在 LA 的第K个位置的可用元素。
1. Start
2. Set LA[K-1] = ITEM
3. Stop
示例
下面是上述算法的执行
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5, item = 10;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
LA[k-1] = item;
printf("The array elements after updation :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}
当编译和执行,上面的程序产生以下结果
The original array elements are :
LA[0]=1
LA[1]=3
LA[2]=5
LA[3]=7
LA[4]=8
The array elements after updation :
LA[0]=1
LA[1]=3
LA[2]=10
LA[3]=7
LA[4]=8
本站代码下载:http://www.yiibai.com/siteinfo/download.html
哈希表 - 数据结构和算法教程™
哈希表是一个数据结构,其中插入和搜索操作都非常快而不管哈希表的大小。 这几乎是一个常数或 O(1)。哈希表使用数组作为存储介质,并使用散列技术来生成索引,其中的元素是被插入或查找。
哈希
散列是一种技术将范围键值转换为一定范围一个数组的索引。我们将使用模运算符来获得一系列键值。考虑大小是 20 的哈希表的一个例子,下列的项目是要被存储的。项目是(键,值)格式。
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
Sr.No. | Key | Hash | 数组索引 |
1 | 1 | 1 % 20 = 1 | 1 |
2 | 2 | 2 % 20 = 2 | 2 |
3 | 42 | 42 % 20 = 2 | 2 |
4 | 4 | 4 % 20 = 4 | 4 |
5 | 12 | 12 % 20 = 12 | 12 |
6 | 14 | 14 % 20 = 14 | 14 |
7 | 17 | 17 % 20 = 17 | 17 |
8 | 13 | 13 % 20 = 13 | 13 |
9 | 37 | 37 % 20 = 17 | 17 |
线性探测
正如我们所看到的,可能要发生的是所使用的散列技术来创建已使用数组的索引。在这种情况下,我们可以直到找到一个空的单元,通过查看下一个单元搜索数组中下一个空的位置。这种技术被称为线性探测。
Sr.No. | Key | Hash | 数组索引 | 线性探测后,数组索引 |
1 | 1 | 1 % 20 = 1 | 1 | 1 |
2 | 2 | 2 % 20 = 2 | 2 | 2 |
3 | 42 | 42 % 20 = 2 | 2 | 3 |
4 | 4 | 4 % 20 = 4 | 4 | 4 |
5 | 12 | 12 % 20 = 12 | 12 | 12 |
6 | 14 | 14 % 20 = 14 | 14 | 14 |
7 | 17 | 17 % 20 = 17 | 17 | 17 |
8 | 13 | 13 % 20 = 13 | 13 | 13 |
9 | 37 | 37 % 20 = 17 | 17 | 18 |
基本操作
以下是这是继哈希表的主要的基本操作。
- 搜索 − 在哈希表中搜索一个元素。
- 插入 − 在哈希表中插入元素。
- 删除 − 删除哈希表的元素。
数据项
定义有一些基于键的数据数据项,在哈希表中进行搜索。
struct DataItem {
int data;
int key;
};
散列方法
定义一个散列方法来计算数据项的 key 的散列码。
int hashCode(int key){
return key % SIZE;
}
搜索操作
当一个元素要被搜索。通过计算 key 的散列码并定位使用该哈希码作为索引数组的元素。使用线性探测得到元素,如果没有找到,再计算散列代码元素继续向前。
struct DataItem *search(int key){
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL){
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
插入操作
当一个元素将要插入。通过计算键的哈希代码,找到使用哈希码作为索引在数组中的索引。使用线性探测空的位置,如果一个元素在计算哈希码被找到。
void insert(int key,int data){
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1){
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
删除操作
当一个元素要被删除。计算通过键的哈希代码,找到使用哈希码作为索引在数组中的索引。使用线性探测得到的元素,如果没有找到,再计算哈希码的元素向前。当找到,存储虚拟项目也保持哈希表完整的性能。
struct DataItem* delete(struct DataItem* item){
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL){
if(hashArray[hashIndex]->key == key){
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
要查看 C语言的哈希实现,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
哈希表实例程序(C语言) - 数据结构和算法教程™
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define SIZE 20
struct DataItem {
int data;
int key;
};
struct DataItem* hashArray[SIZE];
struct DataItem* dummyItem;
struct DataItem* item;
int hashCode(int key){
return key % SIZE;
}
struct DataItem *search(int key){
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL){
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
void insert(int key,int data){
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1){
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
struct DataItem* delete(struct DataItem* item){
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL){
if(hashArray[hashIndex]->key == key){
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
// 显示所示数据项
void display(){
int i = 0;
for(i = 0; i<SIZE; i++) {
if(hashArray[i] != NULL)
printf(" (%d,%d)",hashArray[i]->key,hashArray[i]->data);
else
printf(" ~~ ");
}
printf("\n");
}
int main(){
dummyItem = (struct DataItem*) malloc(sizeof(struct DataItem));
dummyItem->data = -1;
dummyItem->key = -1;
insert(1, 20);
insert(2, 70);
insert(42, 80);
insert(4, 25);
insert(12, 44);
insert(14, 32);
insert(17, 11);
insert(13, 78);
insert(37, 97);
display();
item = search(37);
if(item != NULL){
printf("Element found: %d\n", item->data);
}else{
printf("Element not found\n");
}
delete(item);
item = search(37);
if(item != NULL){
printf("Element found: %d\n", item->data);
}else{
printf("Element not found\n");
}
}
如果我们编译并运行上述程序那么这将产生以下结果 -
~~ (1,20) (2,70) (42,80) (4,25) ~~ ~~ ~~ ~~ ~~ ~~ ~~ (12,44) (13,78) (14,32) ~~ ~~ (17,11) (37,97) ~~
Element found: 97
Element not found
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 哈希表实例程序(C语言)
链表 - 数据结构和算法教程™
链表基础知识
连接表是通过链接连接在一起的数据结构的一个序列。
链表是一个序列的链接,其中包含项目。每个链接中包含到另一条连接。链表是数组之后第二种最常用的数据结构。 以下是理解链表的概念,重要术语。
- Link − 链表中的每个链路可以存储数据称为一个元素。
- Next − 链表的每个链接包含一个链接到下一个被称为下一个。
- LinkedList − LinkedList 包含连接链接到名为 First 的第一个环节。
链表表示
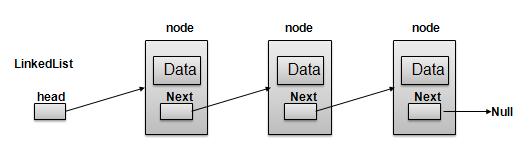
按照如上所示图中,以下是要考虑的重要问题。
- 链表包含一个名为第一个(first)的链接元素。
- 每个链路进行数据字段和链接域叫做下一个(next)。
- 每一个Link链接,其利用其下一个链接的下一个链接。
- 最后一个链接带有链接的空标记列表的末尾。
链表的类型
以下是链表的各种版本。
- 简单的链表 − 项目导航是向前。
- 双向链表 − 项目可以导航向前和向后的方式。
- 循环链表 − 最后一个项目中包含的第一个元素的链接在下一个以及第一个元素链接到最后一个元素的上一个。
基本操作
以下是通过一个列表支持的基本操作。
- 插入 − 在列表的开头添加元素。
- 删除 − 删除在列表开头的元素。
- 显示 − 显示完整列表。
- 搜索 − 搜索给定键的元素。
- 删除 − 删除给定键的元素。
插入操作
插入是三个步骤的过程 -
- 使用提供的数据创建一个新的连接。
- 指向新建链接到旧的第一个链接。
- 第一个链接指向到这个新链接。
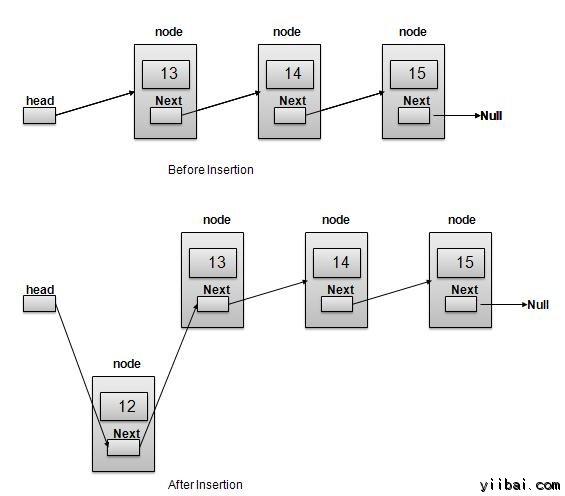
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
删除操作
删除是两个步骤过程-
- 找第一个链接指向作为临时链路相连。
- 第一个链接指向到临时链接的下一个链接。
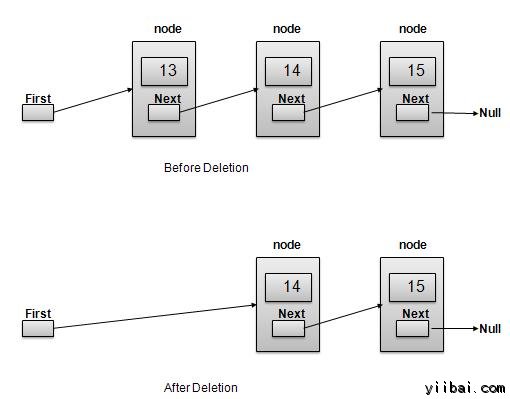
//delete first item
struct node* deleteFirst(){
//save reference to first link
struct node *tempLink = head;
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
导航操作
导航是一个递归步骤的过程,是许多操作的基础,如:搜索,删除等 −
- 获取指向的第一个链接是当前链接的链接。
- 检查如果当前链接不为空则显示它。
- 指向当前链接到下一个链接,并移动到上面的步骤。
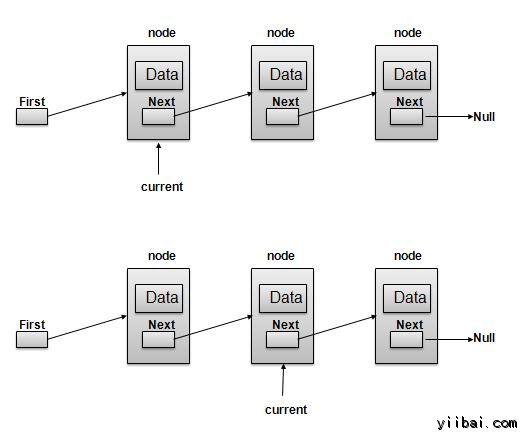
注意 −
//display the list
void printList(){
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
while(ptr != NULL){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
printf(" ]");
}
高级操作
以下是一个列表中指定的高级操作
- 排序 − 排序基于一个特定列表上的顺序的
- 反转 − 反转链表
排序操作
我们使用冒泡排序排序列表。
void sort(){
int i, j, k, tempKey, tempData ;
struct node *current;
struct node *next;
int size = length();
k = size ;
for ( i = 0 ; i < size - 1 ; i++, k-- ) {
current = head ;
next = head->next ;
for ( j = 1 ; j < k ; j++ ) {
if ( current->data > next->data ) {
tempData = current->data ;
current->data = next->data;
next->data = tempData ;
tempKey = current->key;
current->key = next->key;
next->key = tempKey;
}
current = current->next;
next = next->next;
}
}
}
反转操作
下面的代码演示了逆转单向链表。
void reverse(struct node** head_ref) {
struct node* prev = NULL;
struct node* current = *head_ref;
struct node* next;
while (current != NULL) {
next = current->next;
current->next = prev;
prev = current;
current = next;
}
*head_ref = prev;
}
要查看 C编程语言链表实现,请 点击 。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
链表实例程序(C语言) - 数据结构和算法教程™
下面是用 C语言来实现链表的一个实例程序,具体细节如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
struct node {
int data;
int key;
struct node *next;
};
struct node *head = NULL;
struct node *current = NULL;
//display the list
void printList(){
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
while(ptr != NULL){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
printf(" ]");
}
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
//delete first item
struct node* deleteFirst(){
//save reference to first link
struct node *tempLink = head;
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
//is list empty
bool isEmpty(){
return head == NULL;
}
int length(){
int length = 0;
struct node *current;
for(current = head; current!=NULL; current = current->next){
length++;
}
return length;
}
//find a link with given key
struct node* find(int key){
//start from the first link
struct node* current = head;
//if list is empty
if(head == NULL){
return NULL;
}
//navigate through list
while(current->key != key){
//if it is last node
if(current->next == NULL){
return NULL;
}else{
//go to next link
current = current->next;
}
}
//if data found, return the current Link
return current;
}
//delete a link with given key
struct node* delete(int key){
//start from the first link
struct node* current = head;
struct node* previous = NULL;
//if list is empty
if(head == NULL){
return NULL;
}
//navigate through list
while(current->key != key){
//if it is last node
if(current->next == NULL){
return NULL;
}else{
//store reference to current link
previous = current;
//move to next link
current = current->next;
}
}
//found a match, update the link
if(current == head) {
//change first to point to next link
head = head->next;
}else {
//bypass the current link
previous->next = current->next;
}
return current;
}
void sort(){
int i, j, k, tempKey, tempData ;
struct node *current;
struct node *next;
int size = length();
k = size ;
for ( i = 0 ; i < size - 1 ; i++, k-- ) {
current = head ;
next = head->next ;
for ( j = 1 ; j < k ; j++ ) {
if ( current->data > next->data ) {
tempData = current->data ;
current->data = next->data;
next->data = tempData ;
tempKey = current->key;
current->key = next->key;
next->key = tempKey;
}
current = current->next;
next = next->next;
}
}
}
void reverse(struct node** head_ref) {
struct node* prev = NULL;
struct node* current = *head_ref;
struct node* next;
while (current != NULL) {
next = current->next;
current->next = prev;
prev = current;
current = next;
}
*head_ref = prev;
}
main() {
insertFirst(1,10);
insertFirst(2,20);
insertFirst(3,30);
insertFirst(4,1);
insertFirst(5,40);
insertFirst(6,56);
printf("Original List: ");
//print list
printList();
while(!isEmpty()){
struct node *temp = deleteFirst();
printf("\nDeleted value:");
printf("(%d,%d) ",temp->key,temp->data);
}
printf("\nList after deleting all items: ");
printList();
insertFirst(1,10);
insertFirst(2,20);
insertFirst(3,30);
insertFirst(4,1);
insertFirst(5,40);
insertFirst(6,56);
printf("\nRestored List: ");
printList();
printf("\n");
struct node *foundLink = find(4);
if(foundLink != NULL){
printf("Element found: ");
printf("(%d,%d) ",foundLink->key,foundLink->data);
printf("\n");
}else{
printf("Element not found.");
}
delete(4);
printf("List after deleting an item: ");
printList();
printf("\n");
foundLink = find(4);
if(foundLink != NULL){
printf("Element found: ");
printf("(%d,%d) ",foundLink->key,foundLink->data);
printf("\n");
}else{
printf("Element not found.");
}
printf("\n");
sort();
printf("List after sorting the data: ");
printList();
reverse(&head);
printf("\nList after reversing the data: ");
printList();
}
如果我们编译并运行上述程序,那么这将产生以下结果 -
Original List:
[ (6,56) (5,40) (4,1) (3,30) (2,20) (1,10) ]
Deleted value:(6,56)
Deleted value:(5,40)
Deleted value:(4,1)
Deleted value:(3,30)
Deleted value:(2,20)
Deleted value:(1,10)
List after deleting all items:
[ ]
Restored List:
[ (6,56) (5,40) (4,1) (3,30) (2,20) (1,10) ]
Element found: (4,1)
List after deleting an item:
[ (6,56) (5,40) (3,30) (2,20) (1,10) ]
Element not found.
List after sorting the data:
[ (1,10) (2,20) (3,30) (5,40) (6,56) ]
List after reversing the data:
[ (6,56) (5,40) (3,30) (2,20) (1,10) ]
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 链表实例程序(C语言)
双向链表 - 数据结构和算法教程™
双向链表是链表变型,相比于单链表导航或者是向前和向后的两种方式。以下是重要的术语来理解双向链表的概念
- Link − 链表的每个链路存储数据称为一个元素。
- Next − 链表的每个链接包含一个链接到下一个被称为下一个(Next)。
- Prev − 链表的每个链接包含一个链接,称为上一个链接(Prev)。
- LinkedList − LinkedList包含连接链接到名为首先第一个链接,并称为最后的最后一个链接(Last)。
双向链表表示
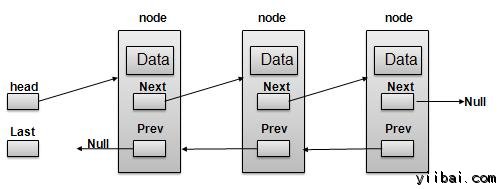
按照如上图中所示,以下是要考虑的重要问题。
- 双向链表包含一个名为第一个(first)和最后一个链接(last)元素。
- 每个链路负责数据字段和LINK域被称为下一个(Next)。
- 每一个Link链接,其利用其下一个链接指向下一个链接。
- 每一个Link链接使用其上一个链接指向上一个链接。
- 最后一个链接带有链接的空标记列表的末尾。
基本操作
下面是一个列表支持的基本操作。
- 插入 − 在列表的开头添加的元素。
- 删除− 删除在列表开头的元素。
- 插入最后 − 在列表的末尾添加元素。
- 删除最后 − 删除列表的末尾的元素。
- 插入之后− 列表中的项目后添加元素。
- 删除 − 用键从列表中删除一个元素。
- 正向显示 − 以向前的方式显示完整列表。
- 后向显示 − 向后的方式显示完整列表。
插入操作
下面的代码演示了插入操作,从一个双向链表的开始。
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()){
//make it the last link
last = link;
}else {
//update first prev link
head->prev = link;
}
//point it to old first link
link->next = head;
//point first to new first link
head = link;
}
删除操作
下面的代码演示了删除操作,在一个双向链表的开始。
//delete first item
struct node* deleteFirst(){
//save reference to first link
struct node *tempLink = head;
//if only one link
if(head->next == NULL){
last = NULL;
}else {
head->next->prev = NULL;
}
head = head->next;
//return the deleted link
return tempLink;
}
在结尾插入操作
下面的代码演示了在一个双向链表的最后一个位置的插入操作。
//insert link at the last location
void insertLast(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if(isEmpty()){
//make it the last link
last = link;
}else {
//make link a new last link
last->next = link;
//mark old last node as prev of new link
link->prev = last;
}
//point last to new last node
last = link;
}
要查看 C编程语言的实现,请点击 。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
循环链表 - 数据结构和算法教程™
循环链表是链接的列表,其中第一个元素指向最后一个元素和最后一个元素指向第一个元素的链接变型。单向链表和双向链表都可以做成作为循环链表。
单链表循环
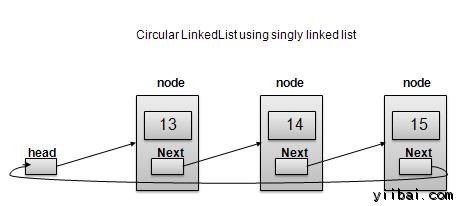
双向链表循环
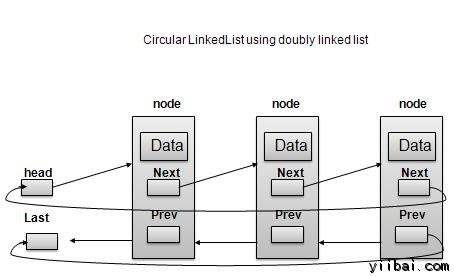
按照如上所示的插图,下面是要考虑的重要问题。
- 最后一个链接的下一个点到列表的第一个链接单独使用,在单/双向链表两种情况都可以使用。
- 在双向链表中,第一个链接的前一个指向最后列表的最后一个链接。
基本操作
下面是一个循环列表支持的重要操作。
- 插入 − 在列表的开头插入的元素。
- 删除 − 在列表的开头删除元素。
- 显示 − 显示列表。
长度操作
下面的代码演示了插入操作在基于单链表循环链表。
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data= data;
if (isEmpty()) {
head = link;
head->next = head;
}
else{
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
}
删除操作
下面的代码演示了在基于单链表循环链表的删除操作。
//delete first item
struct node * deleteFirst(){
//save reference to first link
struct node *tempLink = head;
if(head->next == head){
head = NULL;
return tempLink;
}
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
显示列表操作
下面的代码演示显示循环链表列表操作。
//display the list
void printList(){
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
if(head != NULL){
while(ptr->next != ptr){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
}
printf(" ]");
}
要看到它在 C语言编程实现,请点击 。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
循环链表实例程序(C语言) - 数据结构和算法教程™
使用 C语言来实现循环链表的实例程序,如下所示:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
struct node {
int data;
int key;
struct node *next;
};
struct node *head = NULL;
struct node *current = NULL;
bool isEmpty(){
return head == NULL;
}
int length(){
int length = 0;
//if list is empty
if(head == NULL){
return 0;
}
current = head->next;
while(current != head){
length++;
current = current->next;
}
return length;
}
//insert link at the first location
void insertFirst(int key, int data){
//create a link
struct node *link = (struct node*) malloc(sizeof(struct node));
link->key = key;
link->data = data;
if (isEmpty()) {
head = link;
head->next = head;
}
else{
//point it to old first node
link->next = head;
//point first to new first node
head = link;
}
}
//delete first item
struct node * deleteFirst(){
//save reference to first link
struct node *tempLink = head;
if(head->next == head){
head = NULL;
return tempLink;
}
//mark next to first link as first
head = head->next;
//return the deleted link
return tempLink;
}
//display the list
void printList(){
struct node *ptr = head;
printf("\n[ ");
//start from the beginning
if(head != NULL){
while(ptr->next != ptr){
printf("(%d,%d) ",ptr->key,ptr->data);
ptr = ptr->next;
}
}
printf(" ]");
}
main() {
insertFirst(1,10);
insertFirst(2,20);
insertFirst(3,30);
insertFirst(4,1);
insertFirst(5,40);
insertFirst(6,56);
printf("Original List: ");
//print list
printList();
while(!isEmpty()){
struct node *temp = deleteFirst();
printf("\nDeleted value:");
printf("(%d,%d) ",temp->key,temp->data);
}
printf("\nList after deleting all items: ");
printList();
}
如果我们编译并运行上述程序那么这将产生以下结果 -
Original List:
[ (6,56) (5,40) (4,1) (3,30) (2,20) ]
Deleted value:(6,56)
Deleted value:(5,40)
Deleted value:(4,1)
Deleted value:(3,30)
Deleted value:(2,20)
Deleted value:(1,10)
List after deleting all items:
[ ]
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 循环链表实例程序(C语言)
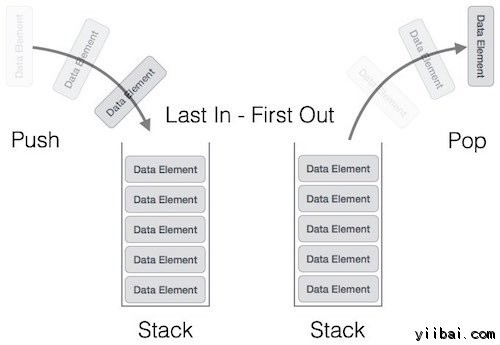
堆栈 - 数据结构和算法教程™
堆栈是一个抽象数据类型(ADT),在大多数编程语言中常用。它被命名堆,因为它就像一个现实世界的堆,例如 - 扑克牌板或堆等。

一个真实世界的堆栈允许保存操作仅在一端进行。例如,我们只可以把或从堆栈顶部取出存储卡或板。同样地,堆栈ADT允许仅在一端执行所有数据操作。在任何特定时间,我们只能访问一个堆栈的顶部元素。
这一特点使它成为后进先出的数据结构。 LIFO表示后进先出。这里放置(插入或添加)最后元素,在第一次访问。在堆的术语中,插入操作被称为PUSH操作,删除操作称为POP操作。
堆栈表示
如下图试图描绘出堆栈及其操作 -
堆栈可通过数组,结构和链表来实现。堆栈可以是固定大小或它可动态调整。在这里,我们要实现使用堆栈数组,这使用的是一个固定大小的堆栈实现。
基本操作
堆栈操作可能涉及初始化堆栈,使用它,然后去对其进行初始化。除了这些基本的东西,堆栈用于以下两个主要的操作 -
- push() − 推(存储)在栈上的元素。
- pop() − 除去(访问)堆栈上的元素。
当数据被压入堆栈。
要使用堆栈有效,我们需要检查栈的情况也是如此。为了同样的目的,下面的功能添加到栈 -
- peek() − 得到的堆栈顶部的数据元素,但不删除它。
- isFull() − 检查堆栈是否满了。
- isEmpty() − 检查堆栈是否为空的。
在任何时候,我们保持一个指向最后压入堆栈的数据。这种指针总是代表堆栈的顶部,因此命名为:top(顶部)。顶部指针提供堆栈顶部的值,但不删除它。
首先,我们应该了解程序,以支持堆栈功能 -
peek()
peek()函数算法
begin procedure peek
return stack[top]
end procedure
peek()函数的 C语言编程实现,如下:
int peek() {
return stack[top];
}
isfull()
isfull()函数算法:
begin procedure isfull
if
top
equals to MAXSIZE
return true
else
return false
endif
end procedure
isfull()函数的C语言编程实现
bool isfull() {
if(top == MAXSIZE)
return true;
else
return false;
}
isempty()
isEmpty()函数算法
begin procedure isempty
if
top
less than 1
return true
else
return false
endif
end procedure
isEmpty()函数的 C语言编程实现略有不同。我们初始化顶部值为 -1, 由于指数数组从0开始。因此,我们检查如果顶部是小于零或-1,以确定是否堆栈是空的。下面的代码
bool isempty() {
if(top == -1)
return true;
else
return false;
}
PUSH/推送操作
把一个新的数据元素到堆栈的过程被称为推入操作。推操作涉及一系列步骤 -
- 步骤 1 − 检查堆栈是否满了
- 步骤 2 − 如果堆栈已满,则产生错误并退出
- 步骤 3 − 如果堆栈未满,增加顶部指向下一个空的空间
- 步骤 4 − 添加数据元素堆栈位置,其中指向顶部
- 步骤 5 − 返回成功
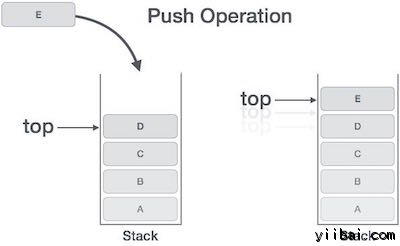
如果链表用于实现堆栈,则在步骤3中,我们需要动态分配的空间。
算法PUSH操作
一个简单的算法推送操作可推导如下 -
begin procedure push: stack, data
if stack is full
return null
endif
top ← top + 1
stack[top] ← data
end procedure
这个算法用C语言来实现,是很容易的。请参见下面的代码 -
void push(int data) {
if(!isFull()) {
top = top + 1;
stack[top] = data;
}
else {
printf("Could not insert data, Stack is full.\n");
}
}
弹出操作
访问内容要从堆栈取出,被称为弹出操作。在数组实现POP()操作,数据元素实际上未被删除,而是顶部递减到一个较低的位置,栈指向下一个值。但在链表实现,pop()方法实际上删除数据元素,并释放内存空间。
弹出操作可能包括以下步骤 −
- 步骤 1 − 检查堆栈是否为空
- 步骤 2 − 如果栈为空,则产生错误并退出
- 步骤 3 − 如果堆栈不空,访问数据元素是在顶部指向
- 步骤 4 − 顶部值降低1
- 步骤 5 − 返回成功
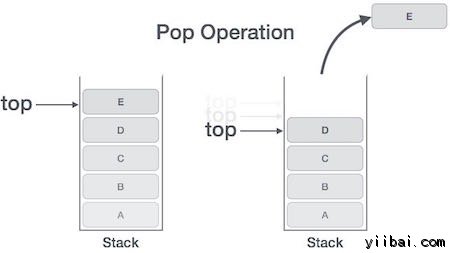
POP算法操作
一个简单的算法弹出操作可以如下 -
begin procedure pop: stack
if stack is empty
return null
endif
data ← stack[top]
top ← top - 1
return data
end procedure
这个算法的 C语言实现,如下所示 -
int pop(int data) {
if(!isempty()) {
data = stack[top];
top = top - 1;
return data;
}
else {
printf("Could not retrieve data, Stack is empty.\n");
}
}
对于C编程语言的完整堆栈程序,请点击
本站代码下载:http://www.yiibai.com/siteinfo/download.html
堆栈实例代码(C语言) - 数据结构和算法教程™
堆栈实例代码(C语言)如下所示:
#include <stdio.h>
int MAXSIZE = 8;
int stack[8];
int top = -1;
int isempty() {
if(top == -1)
return 1;
else
return 0;
}
int isfull() {
if(top == MAXSIZE)
return 1;
else
return 0;
}
int peek() {
return stack[top];
}
int pop() {
int data;
if(!isempty()) {
data = stack[top];
top = top - 1;
return data;
}
else {
printf("Could not retrieve data, Stack is empty.\n");
}
}
int push(int data) {
if(!isfull()) {
top = top + 1;
stack[top] = data;
}
else {
printf("Could not insert data, Stack is full.\n");
}
}
int main() {
// push items on to the stack
push(3);
push(5);
push(9);
push(1);
push(12);
push(15);
printf("Element at top of the stack: %d\n" ,peek());
printf("Elements: \n");
// print stack data
while(!isempty()) {
int data = pop();
printf("%d\n",data);
}
printf("Stack full: %s\n" , isfull()?"true":"false");
printf("Stack empty: %s\n" , isempty()?"true":"false");
return 0;
}
上面的程序代码输出如下:
Element at top of the stack: 15
Elements:
15
12
1
9
5
3
Stack full: false
Stack empty: true
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 堆栈实例代码(C语言)
表达式分析 - 数据结构和算法教程™
编写算术表达式的方法被称为符号。一个算术表达式可以写成在三个不同的但等效的符号,即, 不改变的本质或表达的输出。这些符号是 -
- 中间符号
- 前缀(波兰)符号
- 后缀(反向波兰)符号
这些符号被命名为它们如何利用运算符表达式。我们将在这里学会这些内容。
中间符号
我们编写表达式中缀记号,例如,A-B+C,其中运算符用于在两者之间的操作数。这是很容易为我们人类所读,写和说中缀表示法,但不能使用计算设备顺利计算。用算法来处理中间符号是困难和昂贵的时间和空间消耗。
前缀表示法
在此标记,运营商的前缀操作数,即算提前写入操作数。在此标记,操作符到前缀操作数,即操作符提前写入操作数。 例如,+ab. 这相当于其中缀符号 a+b. 前缀表示法也被称为波兰表示法。
后缀表示法
这个符号风格被称为逆波兰表示法。在此标记风格,操作者后缀操作数,即,操作符是在操作数后写的。例如,ab+. 这相当于其中缀符号:a+b.
下表简要试图展示在所有三个符号的差异 −
S.n. | 中缀表示法 | 前缀表示法 | 后缀表示法 |
1 | a + b | + a b | a b + |
2 | (a + b) * c | * + a b c | a b + c * |
3 | a * (b + c) | * a + b c | a b c + * |
4 | a / b + c / d | + / a b / c d | a b / c d / + |
5 | (a + b) * (c + d) | * + a b + c d | a b + c d + * |
6 | ((a + b) * c) - d | - * + a b c d | a b + c * d - |
解析表达式
正如我们所讨论的,它并不是设计一个算法或程序来解析中缀符号非常有效的方法。相反,这些中缀符号首先被转换成或者后缀或前缀符号,然后计算。
分析任何算术表达式,我们需要注意运算符优先级和关联性。
优先级
当一个操作数是在两个不同的操作符之间,其中操作符将先采取操作数,由操作者于其他的优先级决定。例如 -

由于乘法运算的优先级高于加法,b * c 将首先计算。运算符优先级的表格在稍后提供。
关联性
关联性描述了使用相同的优先级运算符出现在一个表达式规则。例如,在表达式 a+b−c, +和 - 都具有相同的优先级,那么该表达式的一部分将首先计算,通过这些运算符的关联性决定的。在这里,无论是 + 和 - 是左关联的,所以表达式将被计算作为 (a+b)−c.
优先级和结合,确定一个表达式的计算顺序。运算符优先级和结合表如下所示(最高到最低)−
S.n. | 操作符 | 优先级 | 关联性 |
1 | Esponentiation ^ | 最高 | 右关联 |
2 | Multiplication ( * ) & Division ( / ) | 次高 | 左关联 |
3 | Addition ( + ) & Subtraction ( − ) | 最低 | 左关联 |
在表达式计算任何时间点,顺序可以通过使用括号所改变。 例如,
在A + B * C,表达部分:B * C将首先计算,这是由于乘法优先于加法。我们在这里使用括号,使 A + B 首先进行评估计算,如(A + B)* C。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
队列 - 数据结构和算法教程™
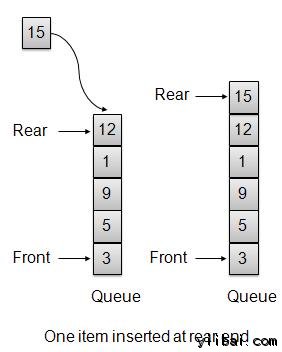
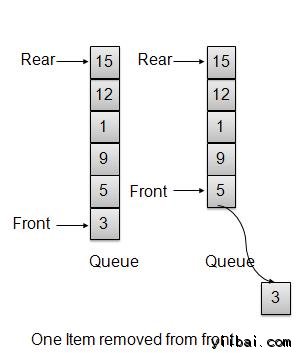
队列是一个抽象的数据结构,与堆栈有些相似。较对比于栈,队列打开两端。 一端总是用来插入数据(排队),另一个是用来删除数据(离队)。 队列使用先入先出的方法,即,第一存储的数据项先被访问。如下:
队列中的一个真实的例子可以是单向的车道单行道,其中车辆第一进入,第一离开。更多真实世界的例子可以看出,队列在售票窗口和巴士站。
队列表示
正如我们现在知道,在队列中访问两端出于不同的原因,如下图试图解释队列表示数据结构 -

与栈,队列相同,也可以使用数组,链表,指针和结构来实现。为简单起见,我们将使用一维数组实现队列。
基本操作
队列操作可能涉及到初始化或定义队列,利用它完成从内存中清除它。在这里,我们将试着去了解使用队列相关的基本操作 -
- enqueue() − 添加(存储)项目到队列中。
- dequeue() − 从队列中删除(访问)项目。
很少有更多的功能需要在上述队列提高操作效率。它们有 -
- peek() − 获得在队列前面的元素而不移除它。
- isfull() − 检查队列是否已满。
- isempty() − 检查队列是否为空。
在队列中,我们总是出队(或访问)数据,通过前面的指针,查询(或存储)我们把后面的指针的帮助下将队列中的数据指出。
让我们先来了解一个队列的辅助功能 −
peek()
像栈,此功能可以看到在队列的前部的数据。peek() 函数算法如下 −
begin procedure peek
return queue[front]
end procedure
在C语言中 peek()函数的实现-
int peek() {
return queue[front];
}
isfull()
由于我们使用一维数组实现的队列,我们只是检查后指针要达到最大范围(MAXSIZE),以确定队列已满。在情况下,我们保持队列以循环链表的形式,该算法将有所不同。isfull()函数算法如下:
begin procedure isfull
if
rear
equals to MAXSIZE
return true
else
return false
endif
end procedure
在C语言中的 isfull()函数的实现 -
bool isfull() {
if(rear == MAXSIZE - 1)
return true;
else
return false;
}
isempty()
isEmpty()函数算法 -
begin procedure isempty
if
front
is less than MIN OR
front
is greater than
rear
return true
else
return false
endif
end procedure
如果前面的值小于 MIN 或 0,它告诉队列尚未初始化,因此空。
下面是C语言编程代码 -
bool isempty() {
if(front < 0 || front > rear)
return true;
else
return false;
}
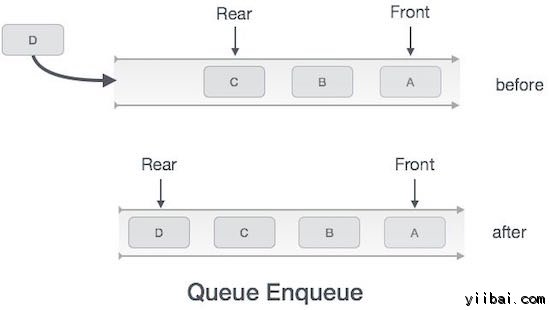
入队操作
由于队列维护两个数据指针,前部和后部,其操作比堆栈相对较难实现。
应采取以下步骤来将数据排入队列(插入)到一个队列 -
- Step 1 − 检查队列是否已满
- Step 2 − 如果队列已满,产生溢出错误,然后退出
- Step 3 − 如果队列未满,增加尾部指针指向下一个空的空间
- Step 4 − 添加数据元素到队列位置,其中后方(rear)指向
- Step 5 − 返回成功
有时,我们还要检查,如果队列被初始化或不处理任何意外情况。
排入队列的操作算法
procedure enqueue(data)
if queue is full
return overflow
endif
rear ← rear + 1
queue[rear] ← data
return true
end procedure
排入队列 enqueue() 函数的 C语言的实现-
int enqueue(int data)
if(isfull())
return 0;
rear = rear + 1;
queue[rear] = data;
return 1;
end procedure
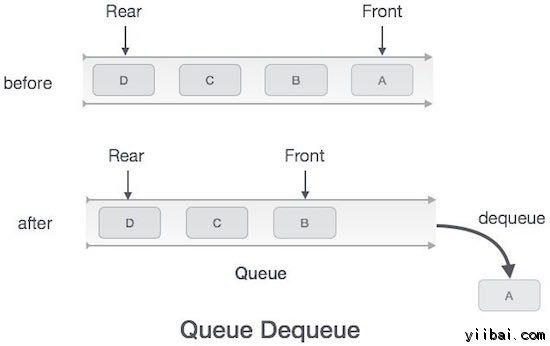
解列操作
从队列中访问数据是两个任务的过程 − 访问前在这里指的是所指向的数据,以及访问后删除数据。将采取以下步骤来执行解列操作 -
- Step 1 − 检查队列是否为空
- Step 2 − 如果队列为空,产生溢错误,然后退出
- Step 3 − 如果队列不为空,访问数据,并向前指向
- Step 3 − 增量前指针指向下一个可用的数据元素
- Step 5 − 返回成功
算法解列操作 -
procedure dequeue
if queue is empty
return underflow
end if
data = queue[front]
front ← front - 1
return true
end procedure
出队列 dequeue() 的C语言实现:
int dequeue() {
if(isempty())
return 0;
int data = queue[front];
front = front + 1;
return data;
}
对于C编程语言的完整队列程序,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
队列实例代码(C语言) - 数据结构和算法教程™
队列实例代码(C语言),具体的实现如下代码所示:
QueueDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX 6
int intArray[MAX];
int front = 0;
int rear = -1;
int itemCount = 0;
int peek(){
return intArray[front];
}
bool isEmpty(){
return itemCount == 0;
}
bool isFull(){
return itemCount == MAX;
}
int size() {
return itemCount;
}
void insert(int data){
if(!isFull()){
if(rear == MAX-1){
rear = -1;
}
intArray[++rear] = data;
itemCount++;
}
}
int removeData(){
int data = intArray[front++];
if(front == MAX){
front = 0;
}
itemCount--;
return data;
}
int main() {
/* insert 5 items */
insert(3);
insert(5);
insert(9);
insert(1);
insert(12);
// front : 0
// rear : 4
// ------------------
// index : 0 1 2 3 4
// ------------------
// queue : 3 5 9 1 12
insert(15);
// front : 0
// rear : 5
// ---------------------
// index : 0 1 2 3 4 5
// ---------------------
// queue : 3 5 9 1 12 15
if(isFull()){
printf("Queue is full!\n");
}
// remove one item
int num = removeData();
printf("Element removed: %d\n",num);
// front : 1
// rear : 5
// -------------------
// index : 1 2 3 4 5
// -------------------
// queue : 5 9 1 12 15
// insert more items
insert(16);
// front : 1
// rear : -1
// ----------------------
// index : 0 1 2 3 4 5
// ----------------------
// queue : 16 5 9 1 12 15
// As queue is full, elements will not be inserted.
insert(17);
insert(18);
// ----------------------
// index : 0 1 2 3 4 5
// ----------------------
// queue : 16 5 9 1 12 15
printf("Element at front: %d\n",peek());
printf("----------------------\n");
printf("index : 5 4 3 2 1 0\n");
printf("----------------------\n");
printf("Queue: ");
while(!isEmpty()){
int n = removeData();
printf("%d ",n);
}
}
如果我们编译并运行上述程序那么这将产生以下结果 -
Queue is full!
Element removed: 3
Element at front: 5
----------------------
index : 5 4 3 2 1 0
----------------------
Queue: 5 9 1 12 15 16
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 队列实例代码(C语言)
队列优先级 - 数据结构和算法教程™
优先级队列比队列更专业的数据结构。像普通队列,优先级队列中有相同的方法,但在使用上是有比较大的区别的。在优先级队列数据项都受到键值排序,以便与最低键的值,数据项在前方,键的最高值的数据项在后方,反之亦然。因此,我们根据它的键值分配的优先项。数值越低,优先级越高。以下是优先级队列的主要方法。
基本操作
- 插入/入队 − 增加数据项到队列的后部。
- 删除/出队 − 从队列的前面删除一个数据项。
优先级队列表示
我们将在本文中使用数组来实现队列。还有一些通过队列支持更多的操作如下。
- Peek − 获得在队列前面的元素。
- isFull − 检查队列是否已满。
- isEmpty − 检查队列是否为空。
插入/入队操作
每当一个元素被插入队列时,优先级队列根据其顺序插入对应的数据项。在这里,我们假设高值的数据具有低优先级。
void insert(int data){
int i = 0;
if(!isFull()){
// if queue is empty, insert the data
if(itemCount == 0){
intArray[itemCount++] = data;
}else{
// start from the right end of the queue
for(i = itemCount - 1; i >= 0; i-- ){
// if data is larger, shift existing item to right end
if(data > intArray[i]){
intArray[i+1] = intArray[i];
}else{
break;
}
}
// insert the data
intArray[i+1] = data;
itemCount++;
}
}
}
删除/解列操作
每当一个元素是从队列中删除,队列使用项目计数得到元素。一旦元素被移除,项目计数减一。
int removeData(){
return intArray[--itemCount];
}
演示程序
PriorityQueueDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX 6
int intArray[MAX];
int itemCount = 0;
int peek(){
return intArray[itemCount - 1];
}
bool isEmpty(){
return itemCount == 0;
}
bool isFull(){
return itemCount == MAX;
}
int size(){
return itemCount;
}
void insert(int data){
int i = 0;
if(!isFull()){
// if queue is empty, insert the data
if(itemCount == 0){
intArray[itemCount++] = data;
}else{
// start from the right end of the queue
for(i = itemCount - 1; i >= 0; i-- ){
// if data is larger, shift existing item to right end
if(data > intArray[i]){
intArray[i+1] = intArray[i];
}else{
break;
}
}
// insert the data
intArray[i+1] = data;
itemCount++;
}
}
}
int removeData(){
return intArray[--itemCount];
}
int main() {
/* insert 5 items */
insert(3);
insert(5);
insert(9);
insert(1);
insert(12);
// ------------------
// index : 0 1 2 3 4
// ------------------
// queue : 12 9 5 3 1
insert(15);
// ---------------------
// index : 0 1 2 3 4 5
// ---------------------
// queue : 15 12 9 5 3 1
if(isFull()){
printf("Queue is full!\n");
}
// remove one item
int num = removeData();
printf("Element removed: %d\n",num);
// ---------------------
// index : 0 1 2 3 4
// ---------------------
// queue : 15 12 9 5 3
// insert more items
insert(16);
// ----------------------
// index : 0 1 2 3 4 5
// ----------------------
// queue : 16 15 12 9 5 3
// As queue is full, elements will not be inserted.
insert(17);
insert(18);
// ----------------------
// index : 0 1 2 3 4 5
// ----------------------
// queue : 16 15 12 9 5 3
printf("Element at front: %d\n",peek());
printf("----------------------\n");
printf("index : 5 4 3 2 1 0\n");
printf("----------------------\n");
printf("Queue: ");
while(!isEmpty()){
int n = removeData();
printf("%d ",n);
}
}
如果我们编译并运行上述程序,那么这将产生以下结果 -
Queue is full!
Element removed: 1
Element at front: 3
----------------------
index : 5 4 3 2 1 0
----------------------
Queue: 3 5 9 12 15 16
本站代码下载:http://www.yiibai.com/siteinfo/download.html
线性搜索(查找) - 数据结构和算法教程™
线性搜索(查找)是一个非常简单的搜索算法。在这种类型的搜索,顺序查找是由在所有项目一个接一个来的。 每一个项目一个一个地检查,如果找到匹配则特定数据项被返回,否则继续搜索,直到收集数据结束。
算法
Linear Search ( A: array of item, n: total no. of items ,x: item to be searched)
Step 1: Set i to 1
Step 2: if i > n then go to step 7
Step 3: if A[i] = x then go to step 6
Step 4: Set i to i + 1
Step 5: Go to Step 2
Step 6: Print Element x Found at index i and go to step 8
Step 7: Print element not found
Step 8: Exit
要查看C编程语言的线性搜索实现,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 线性搜索(查找)
线性搜索实例程序(C语言) - 数据结构和算法教程™
线性搜索实例程序,使用 C语言实现如下所示:
#include <stdio.h>
#define MAX 20
// array of items on which linear search will be conducted.
int intArray[MAX] = {1,2,3,4,6,7,9,11,12,14,15,16,17,19,33,34,43,45,55,66};
void printline(int count){
int i;
for(i = 0;i <count-1;i++){
printf("=");
}
printf("=\n");
}
// this method makes a linear search.
int find(int data){
int comparisons = 0;
int index = -1;
int i;
// navigate through all items
for(i = 0;i<MAX;i++){
// count the comparisons made
comparisons++;
// if data found, break the loop
if(data == intArray[i]){
index = i;
break;
}
}
printf("Total comparisons made: %d", comparisons);
return index;
}
void display(){
int i;
printf("[");
// navigate through all items
for(i = 0;i<MAX;i++){
printf("%d ",intArray[i]);
}
printf("]\n");
}
main(){
printf("Input Array: ");
display();
printline(50);
//find location of 1
int location = find(55);
// if element was found
if(location != -1)
printf("\nElement found at location: %d" ,(location+1));
else
printf("Element not found.");
}
如果我们编译并运行上述程序那么这将产生以下结果 -
Input Array: [1 2 3 4 6 7 9 11 12 14 15 16 17 19 33 34 43 45 55 66 ]
==================================================
Total comparisons made: 19
Element found at location: 19
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 线性搜索实例程序(C语言)
二进制搜索(查找) - 数据结构和算法教程™
二进制搜索(二进制查找)是一个非常快的搜索算法。这种搜索算法适用于分裂和治之的原则。对于该算法正确工作数据收集应是有序的形式。
二进制搜索通过比较集合的中部项目来搜索的特定项目。如果出现匹配,那么返回项目的索引。如果中间项大于项目,然后项目是在搜索子数组中间项目的右侧的项目,否则其它会在位于子数组中间项左侧搜索。 这个过程一直持续在子数组中操作直到子数组的大小减少到零。
二进制搜索减半搜索的项目,从而降低比较数量必须作出非常少的数量。
算法
Binary Search ( A: array of item, n: total no. of items ,x: item to be searched)
Step 1: Set lowerBound = 1
Step 2: Set upperBound = n
Step 3: if upperBound < lowerBound go to step 12
Step 4: set midYiibai = ( lowerBound + upperBound ) / 2
Step 5: if A[midYiibai] < x
Step 6: set lowerBound = midYiibai + 1
Step 7: if A[midYiibai] > x
Step 8: set upperBound = midYiibai - 1
Step 9 if A[midYiibai] = x go to step 11
Step 10: Go to Step 3
Step 11: Print Element x Found at index midYiibai and go to step 13
Step 12: Print element not found
Step 13: Exit
要查看二进制搜索使用数组实现在C语言编程,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 二进制搜索(查找)
二进制搜索/查找程序(C语言) - 数据结构和算法教程™
二进制搜索/查找程序(C语言),如下代码所示:
#include <stdio.h>
#define MAX 20
// array of items on which linear search will be conducted.
int intArray[MAX] = {1,2,3,4,6,7,9,11,12,14,15,16,17,19,33,34,43,45,55,66};
void printline(int count){
int i;
for(i = 0;i <count-1;i++){
printf("=");
}
printf("=\n");
}
int find(int data){
int lowerBound = 0;
int upperBound = MAX -1;
int midPoint = -1;
int comparisons = 0;
int index = -1;
while(lowerBound <= upperBound){
printf("Comparison %d\n" , (comparisons +1) ) ;
printf("lowerBound : %d, intArray[%d] = %d\n", lowerBound,lowerBound,intArray[lowerBound]);
printf("upperBound : %d, intArray[%d] = %d\n", upperBound,upperBound,intArray[upperBound]);
comparisons++;
// compute the mid point
midPoint = (lowerBound + upperBound) / 2;
// data found
if(intArray[midPoint] == data){
index = midPoint;
break;
}
else {
// if data is larger
if(intArray[midPoint] < data){
// data is in upper half
lowerBound = midPoint + 1;
}
// data is smaller
else{
// data is in lower half
upperBound = midPoint -1;
}
}
}
printf("Total comparisons made: %d" , comparisons);
return index;
}
void display(){
int i;
printf("[");
// navigate through all items
for(i = 0;i<MAX;i++){
printf("%d ",intArray[i]);
}
printf("]\n");
}
main(){
printf("Input Array: ");
display();
printline(50);
//find location of 1
int location = find(55);
// if element was found
if(location != -1)
printf("\nElement found at location: %d" ,(location+1));
else
printf("\nElement not found.");
}
如果我们编译并运行上述程序,那么这将产生以下结果 -
Input Array: [1 2 3 4 6 7 9 11 12 14 15 16 17 19 33 34 43 45 55 66 ]
==================================================
Comparison 1
lowerBound : 0, intArray[0] = 1
upperBound : 19, intArray[19] = 66
Comparison 2
lowerBound : 10, intArray[10] = 15
upperBound : 19, intArray[19] = 66
Comparison 3
lowerBound : 15, intArray[15] = 34
upperBound : 19, intArray[19] = 66
Comparison 4
lowerBound : 18, intArray[18] = 55
upperBound : 19, intArray[19] = 66
Total comparisons made: 4
Element found at location: 19
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 二进制搜索/查找程序(C语言)
冒泡排序算法 - 数据结构和算法教程™
冒泡排序是一个简单的排序算法。这个排序算法是基于比较算法,其中每对相邻元件的比较和元素,如果它们不按顺序则交换位置。这个算法是不适合大的数据集,它平均值和最坏情况的复杂性是O(n2),其中n是项目的排位。
算法
我们假定列表是n个元素的阵列。我们进一步假设 swap函数,交换给定数组元素的值。
begin BubbleSort(list)
for all elements of list
if list[i] > list[i+1]
swap(list[i], list[i+1])
end if
end for
return list
end BubbleSort
伪代码
我们观察算法,冒泡排序比较每对数组元素,除非整个阵列完全是升序排列。这可能会导致几个复杂的问题,如果数组不需要更多的交换,因为所有的元素都已经升序顺序。
为了缓解这个问题,我们用换一个的标志变量,它会帮助我们,看是否有交换的发生与否。如果没有交换的发生,即数组不需要更多的处理进行排序,它会跳出循环。
气泡排序算法的伪代码可写成如下 -
procedure bubbleSort( list : array of items )
loop = list.count;
for i = 0 to loop-1 do:
swapped = false
for j = 0 to loop-1 do:
/* compare the adjacent elements */
if list[j] > list[j+1] then
/* swap them */
swap( list[j], list[j+1] )
swapped = true
end if
end for
/*if no number was swapped that means
array is sorted now, break the loop.*/
if(not swapped) then
break
end if
end for
end procedure return list
实现
还有一个问题,我们并没有在原来的算法及其简易伪地址,也就是说,在每次迭代后的最高值,位于数组的结尾。所以,下一次迭代需要不包括已排序的元素。为了这个目的,在我们的实现中限制了内循环,以避免已排序值。
要查看C编程语言冒泡排序的实现,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
冒泡排序算法实例程序(C语言) - 数据结构和算法教程™
冒泡排序算法实例程序,C语言代码实现如下:
#include <stdio.h>
#include <stdbool.h>
#define MAX 10
int list[MAX] = {1,8,4,6,0,3,5,2,7,9};
void display(){
int i;
printf("[");
// navigate through all items
for(i = 0; i < MAX; i++){
printf("%d ",list[i]);
}
printf("]\n");
}
void bubbleSort() {
int temp;
int i,j;
bool swapped = false;
// loop through all numbers
for(i = 0; i < MAX-1; i++) {
swapped = false;
// loop through numbers falling ahead
for(j = 0; j < MAX-1-i; j++) {
printf(" Items compared: [ %d, %d ] ", list[j],list[j+1]);
// check if next number is lesser than current no
// swap the numbers.
// (Bubble up the highest number)
if(list[j] > list[j+1]) {
temp = list[j];
list[j] = list[j+1];
list[j+1] = temp;
swapped = true;
printf(" => swapped [%d, %d]\n",list[j],list[j+1]);
}
else {
printf(" => not swapped\n");
}
}
// if no number was swapped that means
// array is sorted now, break the loop.
if(!swapped) {
break;
}
printf("Iteration %d#: ",(i+1));
display();
}
}
main(){
printf("Input Array: ");
display();
printf("\n");
bubbleSort();
printf("\nOutput Array: ");
display();
}
如果我们编译并运行上述程序,那么它应该产生以下结果 -
Input Array: [1 8 4 6 0 3 5 2 7 9 ]
Items compared: [ 1, 8 ] => not swapped
Items compared: [ 8, 4 ] => swapped [4, 8]
Items compared: [ 8, 6 ] => swapped [6, 8]
Items compared: [ 8, 0 ] => swapped [0, 8]
Items compared: [ 8, 3 ] => swapped [3, 8]
Items compared: [ 8, 5 ] => swapped [5, 8]
Items compared: [ 8, 2 ] => swapped [2, 8]
Items compared: [ 8, 7 ] => swapped [7, 8]
Items compared: [ 8, 9 ] => not swapped
Iteration 1#: [1 4 6 0 3 5 2 7 8 9 ]
Items compared: [ 1, 4 ] => not swapped
Items compared: [ 4, 6 ] => not swapped
Items compared: [ 6, 0 ] => swapped [0, 6]
Items compared: [ 6, 3 ] => swapped [3, 6]
Items compared: [ 6, 5 ] => swapped [5, 6]
Items compared: [ 6, 2 ] => swapped [2, 6]
Items compared: [ 6, 7 ] => not swapped
Items compared: [ 7, 8 ] => not swapped
Iteration 2#: [1 4 0 3 5 2 6 7 8 9 ]
Items compared: [ 1, 4 ] => not swapped
Items compared: [ 4, 0 ] => swapped [0, 4]
Items compared: [ 4, 3 ] => swapped [3, 4]
Items compared: [ 4, 5 ] => not swapped
Items compared: [ 5, 2 ] => swapped [2, 5]
Items compared: [ 5, 6 ] => not swapped
Items compared: [ 6, 7 ] => not swapped
Iteration 3#: [1 0 3 4 2 5 6 7 8 9 ]
Items compared: [ 1, 0 ] => swapped [0, 1]
Items compared: [ 1, 3 ] => not swapped
Items compared: [ 3, 4 ] => not swapped
Items compared: [ 4, 2 ] => swapped [2, 4]
Items compared: [ 4, 5 ] => not swapped
Items compared: [ 5, 6 ] => not swapped
Iteration 4#: [0 1 3 2 4 5 6 7 8 9 ]
Items compared: [ 0, 1 ] => not swapped
Items compared: [ 1, 3 ] => not swapped
Items compared: [ 3, 2 ] => swapped [2, 3]
Items compared: [ 3, 4 ] => not swapped
Items compared: [ 4, 5 ] => not swapped
Iteration 5#: [0 1 2 3 4 5 6 7 8 9 ]
Items compared: [ 0, 1 ] => not swapped
Items compared: [ 1, 2 ] => not swapped
Items compared: [ 2, 3 ] => not swapped
Items compared: [ 3, 4 ] => not swapped
Output Array: [0 1 2 3 4 5 6 7 8 9 ]
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 冒泡排序算法实例程序(C语言)
插入排序 - 数据结构和算法教程™
插入排序是一个简单的排序算法。这种排序算法是就地比较基础的算法,其中一个项目被采取,其适当的位置进行搜索,而且此项目将插入到特定的位置不断增长的排序列表。该算法是不适合大的数据集作为它平均值和最坏情况的复杂性是O(n2) 其中n是的项目数量。
伪代码
procedure insertionSort( A : array of items )
int holePosition
int valueToInsert
for i = 1 to length(A) inclusive do:
/* select value to be inserted */
valueToInsert = A[i]
holePosition = i
/*locate hole position for the element to be inserted */
while holePosition > 0 and A[i-1] > valueToInsert do:
A[holePosition] = A[holePosition-1]
holePosition = holePosition -1
end while
/* insert the number at hole position */
A[holePosition] = valueToInsert
end for
end procedure
要查看C编程语言插入排序的实现,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
选择排序 - 数据结构和算法教程™
选择排序是一个简单的排序算法。这个排序算法是一个基于就地比较算法,其中列表被分为两部分,排序部分,左端和右端未分类的一部分。最初排序的部分是空的,未分类的部分是整个列表。
最小的元素是从无序数组选择并交换,使用最左边的元素,以及元素变成有序数组的一部分。此过程继续由一个元素向右移动无序数组的边界。
该算法是不适合大的数据集,作为它平均值和最坏情况的复杂性是 O(n2) 其中n是项目的数量。
伪代码
Selection Sort ( A: array of item)
procedure selectionSort( A : array of items )
int indexMin
for i = 1 to length(A) - 1 inclusive do:
/* set current element as minimum*/
indexMin = i
/* check the element to be minimum */
for j = i+1 to length(A) - 1 inclusive do:
if(intArray[j] < intArray[indexMin]){
indexMin = j;
}
end for
/* swap the minimum element with the current element*/
if(indexMin != i) then
swap(A[indexMin],A[i])
end if
end for
end procedure
要查看C编程语言选择排序的实现,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
选择排序实例程序(C语言) - 数据结构和算法教程™
在C语言中实现选择排序的程序,详细的代码如下:
#include <stdio.h>
#include <stdbool.h>
#define MAX 7
int intArray[MAX] = {4,6,3,2,1,9,7};
void printline(int count){
int i;
for(i = 0;i <count-1;i++){
printf("=");
}
printf("=\n");
}
void display(){
int i;
printf("[");
// navigate through all items
for(i = 0;i<MAX;i++){
printf("%d ", intArray[i]);
}
printf("]\n");
}
void selectionSort(){
int indexMin,i,j;
// loop through all numbers
for(i = 0; i < MAX-1; i++){
// set current element as minimum
indexMin = i;
// check the element to be minimum
for(j = i+1;j<MAX;j++){
if(intArray[j] < intArray[indexMin]){
indexMin = j;
}
}
if(indexMin != i){
printf("Items swapped: [ %d, %d ]\n" , intArray[i], intArray[indexMin]);
// swap the numbers
int temp = intArray[indexMin];
intArray[indexMin] = intArray[i];
intArray[i] = temp;
}
printf("Iteration %d#:",(i+1));
display();
}
}
main(){
printf("Input Array: ");
display();
printline(50);
selectionSort();
printf("Output Array: ");
display();
printline(50);
}
如果我们编译并运行上述程序,那么这将产生以下结果 -
Input Array: [4, 6, 3, 2, 1, 9, 7]
==================================================
Items swapped: [ 4, 1 ]
iteration 1#: [1, 6, 3, 2, 4, 9, 7]
Items swapped: [ 6, 2 ]
iteration 2#: [1, 2, 3, 6, 4, 9, 7]
iteration 3#: [1, 2, 3, 6, 4, 9, 7]
Items swapped: [ 6, 4 ]
iteration 4#: [1, 2, 3, 4, 6, 9, 7]
iteration 5#: [1, 2, 3, 4, 6, 9, 7]
Items swapped: [ 9, 7 ]
iteration 6#: [1, 2, 3, 4, 6, 7, 9]
Output Array: [1, 2, 3, 4, 6, 7, 9]
==================================================
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 选择排序实例程序(C语言)
合并排序算法 - 数据结构和算法教程™
排序是指以特定的格式排列数据。排序算法指定安排在一个特定的顺序数据的方式。 最常见的顺序是数字或字典顺序。
重要性在一个事实,即数据检索可以被优化,以非常高的水平,如果数据存储在一个有序的方式排序。排序也用来表示更可读格式的数据。一些可以在实际情况中排序的例子如下。
要查看C编程语言归并排序的实现,请点击这里 。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
合并排序算法实例程序(C语言) - 数据结构和算法教程™
合并排序算法C语言实例程序,如下图所示:
#include <stdio.h>
int a[20], b[20], n;
void merging(int low, int mid, int high) {
int l1,l2,i;
for(l1 = low, l2 = mid + 1, i = low; l1 <= mid && l2 <= high; i++){
if(a[l1] <= a[l2])
b[i] = a[l1++];
else
b[i] = a[l2++];
}
while(l1 <= mid)
b[i++] = a[l1++];
while(l2 <= high)
b[i++] = a[l2++];
for(i = low; i <= high; i++)
a[i] = b[i];
}
void sort(int low,int high) {
int mid;
if(low < high) {
mid = (low+high) / 2;
sort(low, mid);
sort(mid+1, high);
merging(low, mid, high);
}
else {
return;
}
}
int main() {
int i;
printf("Enter N ");
scanf("%d",&n);
printf("Enter elements\n");
for(i = 1; i <= n; i++)
scanf("%d",& a[i]);
sort(1,n);
printf("After sorting\n");
for(i = 1; i <= n; i++)
printf("%d\n", a[i]);
}
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 合并排序算法实例程序(C语言)
希尔排序 - 数据结构和算法教程™
希尔排序是一种高效排序算法和基于插入排序算法。该算法避免了大的变化作为插入排序的一种情况,如果较小的值很远右边那么必须移动到最左边。该算法采用插入排序上广为传播的元素先对它们进行排序,然后排序不太广泛分布的元素。 这个间距称为间隔。该间隔是根据Knuth的公式所计算 (h=h*3 +1) 其中h为间隔并且初始值是1。该算法是用于中等大小的数据组很有效,因为它的平均和最坏情况的复杂性是O(n),其中n为项目数量。
伪代码
procedure shellSort( A : array of items )
int innerPosition, outerPosition
int valueToInsert, interval = 1
/* calculate interval*/
while interval < A.length /3 do:
interval = interval * 3 +1
while interval > 0 do:
for outer = interval; outer < A.length; outer ++ do:
/* select value to be inserted */
valueToInsert = A[outer]
inner = outer;
/*shift element towards right*/
while inner > interval -1 && A[inner - interval] >= valueToInsert do:
A[inner] = A[inner-1]
inner = inner - interval
end while
/* insert the number at hole position */
A[inner] = valueToInsert
end for
/* calculate interval*/
interval = (interval -1) /3;
end while
end procedure
要查看C编程语言希尔排序的实现,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
希尔排序实例程序(C程序) - 数据结构和算法教程™
使用C语言来编写 shell 排序程序实例,如下所示:
#include <stdio.h>
#include <stdbool.h>
#define MAX 7
int intArray[MAX] = {4,6,3,2,1,9,7};
void printline(int count){
int i;
for(i = 0;i <count-1;i++){
printf("=");
}
printf("=\n");
}
void display(){
int i;
printf("[");
// navigate through all items
for(i = 0;i<MAX;i++){
printf("%d ",intArray[i]);
}
printf("]\n");
}
void shellSort(){
int inner, outer;
int valueToInsert;
int interval = 1;
int elements = MAX;
int i = 0;
while(interval <= elements/3) {
interval = interval*3 +1;
}
while(interval > 0) {
printf("iteration %d#:",i);
display();
for(outer = interval; outer < elements; outer++) {
valueToInsert = intArray[outer];
inner = outer;
while(inner > interval -1 && intArray[inner - interval] >= valueToInsert) {
intArray[inner] = intArray[inner - interval];
inner -= interval;
printf(" item moved :%d\n",intArray[inner]);
}
intArray[inner] = valueToInsert;
printf(" item inserted :%d, at position :%d\n",valueToInsert,inner);
}
interval = (interval -1) /3;
i++;
}
}
int main() {
printf("Input Array: ");
display();
printline(50);
shellSort();
printf("Output Array: ");
display();
printline(50);
return 1;
}
如果我们编译并运行上述程序那么这将产生以下结果 -
Input Array: [4, 6, 3, 2, 1, 9, 7]
==================================================
iteration 0#: [4, 6, 3, 2, 1, 9, 7]
item moved :4
item inserted :1, at position :0
item inserted :9, at position :5
item inserted :7, at position :6
iteration 1#: [1, 6, 3, 2, 4, 9, 7]
item inserted :6, at position :1
item moved :6
item inserted :3, at position :1
item moved :6
item moved :3
item inserted :2, at position :1
item moved :6
item inserted :4, at position :3
item inserted :9, at position :5
item moved :9
item inserted :7, at position :5
Output Array: [1, 2, 3, 4, 6, 7, 9]
==================================================
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 希尔排序实例程序(C程序)
快速排序 - 数据结构和算法教程™
快速排序是一种高效的排序算法,并基于分割数据的数组成更小的数组。一个大的数组被划分成两个数组,其中一个保持值比规定的值小的表示基于支点在其上的分区是由与另一个数组保存值大于支点的值。
快速排序分割数组,然后调用自身递归两次排序得到的两个子数组。该算法对大型数据集作为平均和最坏情况的复杂性相当有效率为O(nlogn),其中n是项目的数目。
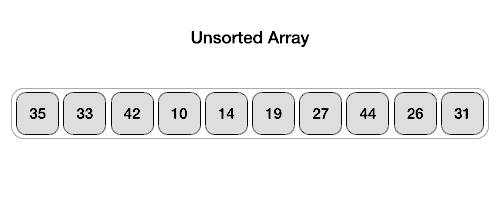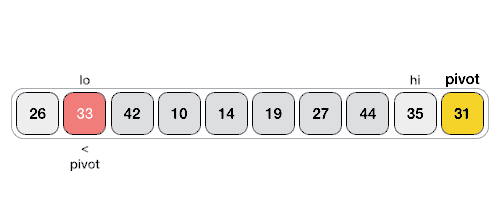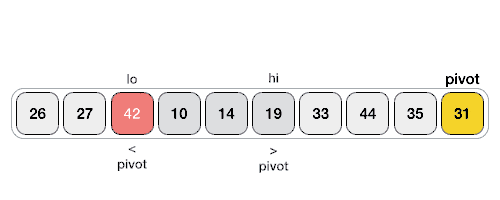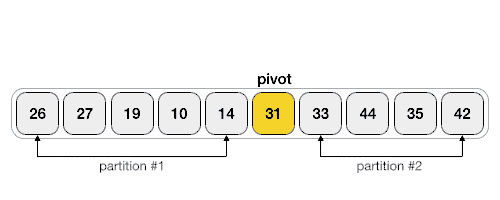
伪代码
A : array of items
procedure quickSort(left, right)
if right-left <= 0
return
else
pivot = A[right]
partition = partitionFunc(left, right, pivot)
quickSort(left,partition-1)
quickSort(partition+1,right)
end if
end procedure
function partitionFunc(left, right, pivot)
leftTutorialser = left -1
rightTutorialser = right
while True do
while A[++leftTutorialser] < pivot do
//donothing
end while
while rightTutorialser > 0 && A[--rightTutorialser] > pivot do
//donothing
end while
if leftTutorialser >= rightTutorialser
break
else
swap leftTutorialser,rightTutorialser
end if
end while
swap leftTutorialser,right
return leftTutorialser
end function
procedure swap (num1, num2)
temp = A[num1]
A[num1] = A[num2]
A[num2] = temp;
end procedure
要查看C编程语言快速排序的实现,请点击这里
本站代码下载:http://www.yiibai.com/siteinfo/download.html
快速排序实例程序(C语言) - 数据结构和算法教程™
快速排序实例程序,C语言实现的详细如下:
#include <stdio.h>
#include <stdbool.h>
#define MAX 7
int intArray[MAX] = {4,6,3,2,1,9,7};
void printline(int count){
int i;
for(i = 0;i <count-1;i++){
printf("=");
}
printf("=\n");
}
void display(){
int i;
printf("[");
// navigate through all items
for(i = 0;i<MAX;i++){
printf("%d ",intArray[i]);
}
printf("]\n");
}
void swap(int num1, int num2){
int temp = intArray[num1];
intArray[num1] = intArray[num2];
intArray[num2] = temp;
}
int partition(int left, int right, int pivot){
int leftTutorialser = left -1;
int rightTutorialser = right;
while(true){
while(intArray[++leftTutorialser] < pivot){
//do nothing
}
while(rightTutorialser > 0 && intArray[--rightTutorialser] > pivot){
//do nothing
}
if(leftTutorialser >= rightTutorialser){
break;
}else{
printf(" item swapped :%d,%d\n",
intArray[leftTutorialser],intArray[rightTutorialser]);
swap(leftTutorialser,rightTutorialser);
}
}
printf(" pivot swapped :%d,%d\n", intArray[leftTutorialser],intArray[right]);
swap(leftTutorialser,right);
printf("Updated Array: ");
display();
return leftTutorialser;
}
void quickSort(int left, int right){
if(right-left <= 0){
return;
}else{
int pivot = intArray[right];
int partitionTutorials = partition(left, right, pivot);
quickSort(left,partitionTutorials-1);
quickSort(partitionTutorials+1,right);
}
}
main(){
printf("Input Array: ");
display();
printline(50);
quickSort(0,MAX-1);
printf("Output Array: ");
display();
printline(50);
}
如果我们编译并运行上述程序,那么这将产生以下结果 -
Input Array: [4 6 3 2 1 9 7 ]
==================================================
pivot swapped :9,7
Updated Array: [4 6 3 2 1 7 9 ]
pivot swapped :4,1
Updated Array: [1 6 3 2 4 7 9 ]
item swapped :6,2
pivot swapped :6,4
Updated Array: [1 2 3 4 6 7 9 ]
pivot swapped :3,3
Updated Array: [1 2 3 4 6 7 9 ]
Output Array: [1 2 3 4 6 7 9 ]
==================================================
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » 快速排序实例程序(C语言)
图数据结构 - 数据结构和算法教程™
图是一个集合,其中一些对对象都是通过链路连接的对象的图形表示。互联的对象是通过顶点来表示,以及连接所述顶点的链接被称为边缘。
形式上,曲线图是一对集(V, E), 其中V是顶点组及E是边集,连接顶点的对。看看下面的图 -
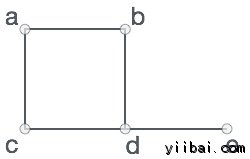
另外,在上述图中,
V = {a, b, c, d, e}
E = {ab, ac, bd, cd, de}
图数据结构
数学图可在数据结构中表示。我们可以使用顶点数组和边缘的二维数组来表示图。 在进一步前进学习前,让我们熟悉一下一些重要术语−
- 顶点 − 图的每个节点被表示为顶点。在下面的例子中给出,标记圆圈代表顶点。因此,A至G的顶点。使用数组,如下面的图片我们可以代表他们。这里A可以通过索引0,B可以使用索引1等来识别。
- 边缘 − 边表示两个顶点之间的线的两个顶点之间的路径。在下面的例子中给出,线路从A到B,B到C等代表边缘。我们可以用一个二维数组来表示数组所示图如下。这里AB可以表示为1,在第0行,第1列,BC为1,在第1行,列2等等,保持其他的组合为0。
- 相邻 − 两个节点或顶点相邻当它们通过一个边彼此连接。在下面的例子给出,B是相邻的A,C是相邻B等。
- 通路 − 路径代表两个顶点之间的边的序列。在下面的例子给出ABCD表示从A到D的路径。
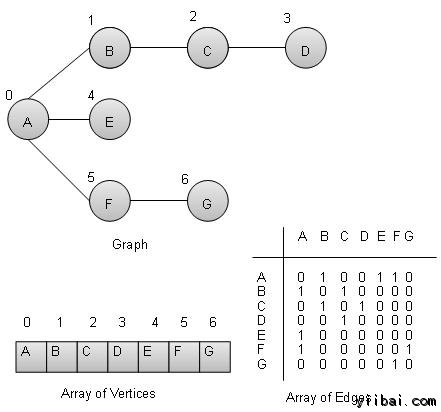
基本操作
以下是遵循图的基本操作。
- 添加顶点 − 添加一个顶点到图。
- 添加边缘 − 图的两个顶点之间添加边线。
- 显示顶点 − 显示一个图形的顶点。
添加顶点操作
//add vertex to the vertex list
void addVertex(char label){
struct vertex* vertex = (struct vertex*) malloc(sizeof(struct vertex));
vertex->label = label;
vertex->visited = false;
lstVertices[vertexCount++] = vertex;
}
添加边缘操作
//add edge to edge array
void addEdge(int start,int end){
adjMatrix[start][end] = 1;
adjMatrix[end][start] = 1;
}
显示边缘操作
//display the vertex
void displayVertex(int vertexIndex){
printf("%c ",lstVertices[vertexIndex]->label);
}
本站代码下载:http://www.yiibai.com/siteinfo/download.html
深度优先遍历 - 数据结构和算法教程™
深度优先搜索算法
深度优先搜索算法(DFS)遍历深度区运动的图并使用堆栈记下要获得的下一个顶点,当一个死尾发生时迭代开始搜索。
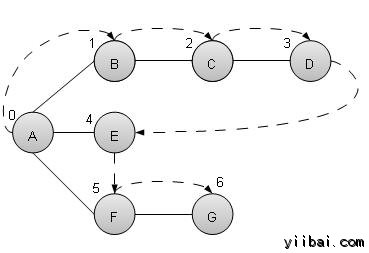
正如上面给出的例子,DFS算法从A遍历到B到C再到D到E,然后到F,最后到G它采用下列规则。
- 规则 1 − 访问邻近的未访问顶点。标记它已访问。并显示它,最后将其推入堆栈。
- 规则 2 − 如果没有相邻顶点发现,从堆栈中弹出一个顶点。(它会从栈弹出没有相邻顶点的所有顶点)
- 规则 3 − 重复第1条和第2条,直到堆栈为空。
void depthFirstSearch(){
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//push vertex index in stack
push(0);
while(!isStackEmpty()){
//get the unvisited vertex of vertex which is at top of the stack
int unvisitedVertex = getAdjUnvisitedVertex(peek());
//no adjacent vertex found
if(unvisitedVertex == -1){
pop();
}else{
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
push(unvisitedVertex);
}
}
//stack is empty, search is complete, reset the visited flag
for(i = 0;i < vertexCount;i++){
lstVertices[i]->visited = false;
}
}
本站代码下载:http://www.yiibai.com/siteinfo/download.html
广度优先遍历 - 数据结构和算法教程™
广度优先搜索算法
广度优先搜索算法(BFS)遍历图在广度运动并使用队列记得要获得下一个顶点,当穷途末路发生时迭代开始搜索。
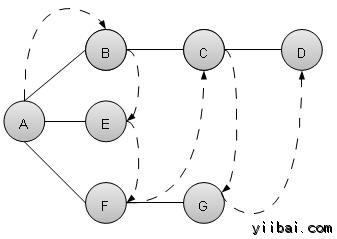
正如上面的例子给出的,BFS算法首先从A到B遍历到E到F,再到C和G最后到D. 它采用以下规则。
- 规则 1 − 访问邻近的未访问顶点。标记它访问并显示它。将其插入到队列中。
- 规则 2 − 如果没有相邻顶点发现,删除队列中的第一个顶点。
- 规则 3 − 重复第1条和第2条,直到队列为空。
void breadthFirstSearch(){
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//insert vertex index in queue
insert(0);
int unvisitedVertex;
while(!isQueueEmpty()){
//get the unvisited vertex of vertex which is at front of the queue
int tempVertex = removeData();
//no adjacent vertex found
while((unvisitedVertex = getAdjUnvisitedVertex(tempVertex)) != -1){
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
insert(unvisitedVertex);
}
}
//queue is empty, search is complete, reset the visited flag
for(i = 0;i<vertexCount;i++){
lstVertices[i]->visited = false;
}
}
演示程序
GraphDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX 10
struct Vertex {
char label;
bool visited;
};
//stack variables
int stack[MAX];
int top = -1;
//queue variables
int queue[MAX];
int rear = -1;
int front = 0;
int queueItemCount = 0;
//graph variables
//array of vertices
struct Vertex* lstVertices[MAX];
//adjacency matrix
int adjMatrix[MAX][MAX];
//vertex count
int vertexCount = 0;
//stack functions
void push(int item) {
stack[++top] = item;
}
int pop() {
return stack[top--];
}
int peek() {
return stack[top];
}
bool isStackEmpty(){
return top == -1;
}
//queue functions
void insert(int data){
queue[++rear] = data;
queueItemCount++;
}
int removeData(){
queueItemCount--;
return queue[front++];
}
bool isQueueEmpty(){
return queueItemCount == 0;
}
//graph functions
//add vertex to the vertex list
void addVertex(char label){
struct Vertex* vertex = (struct Vertex*) malloc(sizeof(struct Vertex));
vertex->label = label;
vertex->visited = false;
lstVertices[vertexCount++] = vertex;
}
//add edge to edge array
void addEdge(int start,int end){
adjMatrix[start][end] = 1;
adjMatrix[end][start] = 1;
}
//display the vertex
void displayVertex(int vertexIndex){
printf("%c ",lstVertices[vertexIndex]->label);
}
//get the adjacent unvisited vertex
int getAdjUnvisitedVertex(int vertexIndex){
int i;
for(i = 0; i<vertexCount; i++)
if(adjMatrix[vertexIndex][i] == 1 && lstVertices[i]->visited == false)
return i;
return -1;
}
void depthFirstSearch(){
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//push vertex index in stack
push(0);
while(!isStackEmpty()){
//get the unvisited vertex of vertex which is at top of the stack
int unvisitedVertex = getAdjUnvisitedVertex(peek());
//no adjacent vertex found
if(unvisitedVertex == -1){
pop();
}else{
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
push(unvisitedVertex);
}
}
//stack is empty, search is complete, reset the visited flag
for(i = 0;i < vertexCount;i++){
lstVertices[i]->visited = false;
}
}
void breadthFirstSearch(){
int i;
//mark first node as visited
lstVertices[0]->visited = true;
//display the vertex
displayVertex(0);
//insert vertex index in queue
insert(0);
int unvisitedVertex;
while(!isQueueEmpty()){
//get the unvisited vertex of vertex which is at front of the queue
int tempVertex = removeData();
//no adjacent vertex found
while((unvisitedVertex = getAdjUnvisitedVertex(tempVertex)) != -1){
lstVertices[unvisitedVertex]->visited = true;
displayVertex(unvisitedVertex);
insert(unvisitedVertex);
}
}
//queue is empty, search is complete, reset the visited flag
for(i = 0;i<vertexCount;i++){
lstVertices[i]->visited = false;
}
}
main() {
int i, j;
for(i = 0; i<MAX; i++) // set adjacency
for(j = 0; j<MAX; j++) // matrix to 0
adjMatrix[i][j] = 0;
addVertex('A'); //0
addVertex('B'); //1
addVertex('C'); //2
addVertex('D'); //3
addVertex('E'); //4
addVertex('F'); //5
addVertex('G'); //6
/* 1 2 3
* 0 |--B--C--D
* A--|
* |
* | 4
* |-----E
* | 5 6
* | |--F--G
* |--|
*/
addEdge(0, 1); //AB
addEdge(1, 2); //BC
addEdge(2, 3); //CD
addEdge(0, 4); //AC
addEdge(0, 5); //AF
addEdge(5, 6); //FG
printf("Depth First Search: ");
//A B C D E F G
depthFirstSearch();
printf("\nBreadth First Search: ");
//A B E F C G D
breadthFirstSearch();
}
如果我们编译并运行上述程序,那么这将产生以下结果 -
Depth First Search: A B C D E F G
Breadth First Search: A B E F C G D
本站代码下载:http://www.yiibai.com/siteinfo/download.html
树(二叉树) - 数据结构和算法教程™
树表示由边缘连接的节点。我们将要具体地讨论二叉树或二叉搜索树。
二叉树是用于数据存储目的的特殊的数据结构。二叉树有一个特殊的情况,每个节点可以有两个子节点。二叉树有序数组和链表的两个好处,搜索排序在数组插入或删除操作一样快的,在链表也是尽可能快。
术语
以下是关于树的重要方面。
- 路径 − 路径是指沿一棵树的边缘节点的序列。
- 根 − 节点在树的顶部被称为根。有每棵树只有一个根和一个路径从根节点到任何节点。
- 父子点 − 除根节点的任何一个节点都有一个边缘向上的节点称为父节点。
- 子节点 − 给定节点的边缘部分连接向下以下节点被称为它的子节点。
- 叶子点 − 节点不具有任何子节点被称为叶节点。
- 子树 − 子树代表一个节点的后代。
- 访问 − 访问是指检查某个节点的值在控制的节点上时。
- 遍历 − 遍历意味着通过节点传递一个特定的顺序。
- 层次 − 一个节点的层次表示的节点的产生。如果根节点的级别是0,那么它的下一子结点为1级,其孙子是2级等。
- 键 − 键表示基于一个节点在其上的搜索操作将被进行了一个节点的值。
二叉搜索树表现出特殊的行为。一个节点的左子的值必须低于其父的值,节点的右子节点的值必须大于它的父节点的值。
二叉搜索树表示
我们将使用节点对象来实现树,并通过引用连接它们。
基本操作
以下是遵循树的基本操作。
- 搜索 − 搜索一棵树中的元素
- 插入 − 插入元素到一棵树中
- 前序遍历 − 遍历树前序方法
- 中序遍历 − 遍历树在序方法
- 后序遍历− 遍历树的后序方法
节点
限定了具有一些数据,引用其左,右子节点的节点。
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};
搜索操作
每当一个元素被搜索。开始从根节点搜索后,如果数据小于键值,在左子树中搜索元素,否则在右子树搜索元素。每一个节点按照同样的算法。
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
}//else go to right tree
else{
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
return current;
}
}
插入操作
每当一个元素被插入。首先找到它应有的位置。从根节点开始搜索,那么如果数据小于键值,在搜索左子树空位置并插入数据。否则,在右子树搜索空位置并插入数据。
void insert(int data){
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL){
root = tempNode;
}else{
current = root;
parent = NULL;
while(1){
parent = current;
//go to left of the tree
if(data < parent->data){
current = current->leftChild;
//insert to the left
if(current == NULL){
parent->leftChild = tempNode;
return;
}
}//go to right of the tree
else{
current = current->rightChild;
//insert to the right
if(current == NULL){
parent->rightChild = tempNode;
return;
}
}
}
}
}
前序遍历
这是一个简单的三个步骤。
- 访问根结点
- 遍历左子树
- 遍历右子树
void preOrder(struct node* root){
if(root != NULL){
printf("%d ",root->data);
preOrder(root->leftChild);
preOrder(root->rightChild);
}
}
中序遍历
这是一个简单的三个步骤。
- 遍历左子树
- 访问根结点
- 遍历右子树
void inOrder(struct node* root){
if(root != NULL){
inOrder(root->leftChild);
printf("%d ",root->data);
inOrder(root->rightChild);
}
}
后序遍历
这是一个简单的三个步骤。
- 遍历左子树
- 遍历右子树
- 访问根结点
void postOrder(struct node* root){
if(root != NULL){
postOrder(root->leftChild);
postOrder(root->rightChild);
printf("%d ",root->data);
}
}
演示程序
TreeDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};
struct node *root = NULL;
void insert(int data){
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL){
root = tempNode;
}else{
current = root;
parent = NULL;
while(1){
parent = current;
//go to left of the tree
if(data < parent->data){
current = current->leftChild;
//insert to the left
if(current == NULL){
parent->leftChild = tempNode;
return;
}
}//go to right of the tree
else{
current = current->rightChild;
//insert to the right
if(current == NULL){
parent->rightChild = tempNode;
return;
}
}
}
}
}
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
}//else go to right tree
else{
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
return current;
}
void preOrder(struct node* root){
if(root != NULL){
printf("%d ",root->data);
preOrder(root->leftChild);
preOrder(root->rightChild);
}
}
void inOrder(struct node* root){
if(root != NULL){
inOrder(root->leftChild);
printf("%d ",root->data);
inOrder(root->rightChild);
}
}
void postOrder(struct node* root){
if(root != NULL){
postOrder(root->leftChild);
postOrder(root->rightChild);
printf("%d ",root->data);
}
}
void traverse(int traversalType){
switch(traversalType){
case 1:
printf("\nPreorder traversal: ");
preOrder(root);
break;
case 2:
printf("\nInorder traversal: ");
inOrder(root);
break;
case 3:
printf("\nPostorder traversal: ");
postOrder(root);
break;
}
}
int main() {
/* 11 //Level 0
*/
insert(11);
/* 11 //Level 0
* |
* |---20 //Level 1
*/
insert(20);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
*/
insert(3);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* |--42 //Level 2
*/
insert(42);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* |--42 //Level 2
* |
* |--54 //Level 3
*/
insert(54);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* 16--|--42 //Level 2
* |
* |--54 //Level 3
*/
insert(16);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* 16--|--42 //Level 2
* |
* 32--|--54 //Level 3
*/
insert(32);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* |
* 32--|--54 //Level 3
*/
insert(9);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* | |
* 4--| 32--|--54 //Level 3
*/
insert(4);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* | |
* 4--|--10 32--|--54 //Level 3
*/
insert(10);
struct node * temp = search(32);
if(temp != NULL){
printf("Element found.\n");
printf("( %d )",temp->data);
printf("\n");
}else{
printf("Element not found.\n");
}
struct node *node1 = search(2);
if(node1 != NULL){
printf("Element found.\n");
printf("( %d )",node1->data);
printf("\n");
}else{
printf("Element not found.\n");
}
//pre-order traversal
//root, left ,right
traverse(1);
//in-order traversal
//left, root ,right
traverse(2);
//post order traversal
//left, right, root
traverse(3);
}
如果我们编译并运行上述程序,那么这将产生以下结果 -
Visiting elements: 11 20 42 Element found.(32)
Visiting elements: 11 3 Element not found.
Preorder traversal: 11 3 9 4 10 20 16 42 32 54
Inorder traversal: 3 4 9 10 11 16 20 32 42 54
Postorder traversal: 4 10 9 3 16 32 54 42 20 11
本站代码下载:http://www.yiibai.com/siteinfo/download.html
树遍历 - 数据结构和算法教程™
前序遍历
这是一个简单的三个步骤。
- 访问根结点
- 遍历左子树
- 遍历右子树
void preOrder(struct node* root){
if(root != NULL){
printf("%d ",root->data);
preOrder(root->leftChild);
preOrder(root->rightChild);
}
}
中序遍历
这是一个简单的三个步骤。
- 遍历左子树
- 访问根结点
- 遍历右子树
void inOrder(struct node* root){
if(root != NULL){
inOrder(root->leftChild);
printf("%d ",root->data);
inOrder(root->rightChild);
}
}
后序遍历
这是一个简单的三个步骤。
- 遍历左子树
- 遍历右子树
- 访问根结点
void postOrder(struct node* root){
if(root != NULL){
postOrder(root->leftChild);
postOrder(root->rightChild);
printf("%d ",root->data);
}
}
演示程序
TreeDemo.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdbool.h>
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};
struct node *root = NULL;
void insert(int data){
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL){
root = tempNode;
}else{
current = root;
parent = NULL;
while(1){
parent = current;
//go to left of the tree
if(data < parent->data){
current = current->leftChild;
//insert to the left
if(current == NULL){
parent->leftChild = tempNode;
return;
}
}//go to right of the tree
else{
current = current->rightChild;
//insert to the right
if(current == NULL){
parent->rightChild = tempNode;
return;
}
}
}
}
}
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL)
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
}//else go to right tree
else{
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
return current;
}
void preOrder(struct node* root){
if(root != NULL){
printf("%d ",root->data);
preOrder(root->leftChild);
preOrder(root->rightChild);
}
}
void inOrder(struct node* root){
if(root != NULL){
inOrder(root->leftChild);
printf("%d ",root->data);
inOrder(root->rightChild);
}
}
void postOrder(struct node* root){
if(root != NULL){
postOrder(root->leftChild);
postOrder(root->rightChild);
printf("%d ",root->data);
}
}
void traverse(int traversalType){
switch(traversalType){
case 1:
printf("\nPreorder traversal: ");
preOrder(root);
break;
case 2:
printf("\nInorder traversal: ");
inOrder(root);
break;
case 3:
printf("\nPostorder traversal: ");
postOrder(root);
break;
}
}
int main() {
/* 11 //Level 0
*/
insert(11);
/* 11 //Level 0
* |
* |---20 //Level 1
*/
insert(20);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
*/
insert(3);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* |--42 //Level 2
*/
insert(42);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* |--42 //Level 2
* |
* |--54 //Level 3
*/
insert(54);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* 16--|--42 //Level 2
* |
* |--54 //Level 3
*/
insert(16);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* |
* 16--|--42 //Level 2
* |
* 32--|--54 //Level 3
*/
insert(32);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* |
* 32--|--54 //Level 3
*/
insert(9);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* | |
* 4--| 32--|--54 //Level 3
*/
insert(4);
/* 11 //Level 0
* |
* 3---|---20 //Level 1
* | |
* |--9 16--|--42 //Level 2
* | |
* 4--|--10 32--|--54 //Level 3
*/
insert(10);
struct node * temp = search(32);
if(temp != NULL){
printf("Element found.\n");
printf("( %d )",temp->data);
printf("\n");
}else{
printf("Element not found.\n");
}
struct node *node1 = search(2);
if(node1 != NULL){
printf("Element found.\n");
printf("( %d )",node1->data);
printf("\n");
}else{
printf("Element not found.\n");
}
//pre-order traversal
//root, left ,right
traverse(1);
//in-order traversal
//left, root ,right
traverse(2);
//post order traversal
//left, right, root
traverse(3);
}
如果我们编译并运行上述程序,那么这将产生以下结果 -
Visiting elements: 11 20 42 Element found.(32)
Visiting elements: 11 3 Element not found.
Preorder traversal: 11 3 9 4 10 20 16 42 32 54
Inorder traversal: 3 4 9 10 11 16 20 32 42 54
Postorder traversal: 4 10 9 3 16 32 54 42 20 11
本站代码下载:http://www.yiibai.com/siteinfo/download.html
二叉搜索树 - 数据结构和算法教程™
二叉搜索树表现出特殊的行为。一个节点的左子必须具备值小于它的父代值,并且节点的右子节点的值必须大于它的父值。
二叉搜索树表示
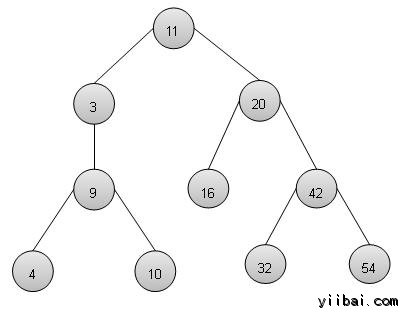
我们将使用节点对象来实现树,并通过引用连接它们。
基本操作
以下是遵循树的基本操作。
- 搜索 − 搜索一棵树中的元素。
- 插入 − 插入元素到一棵树中。
- 前序遍历 − 遍历一棵树方法。
- 后序遍历 − 遍历树在序方法。
- 后序遍历 − 遍历树的后序方法。
节点
限定了具有一些数据,引用其左,右子节点的节点。
struct node {
int data;
struct node *leftChild;
struct node *rightChild;
};
搜索操作
每当一个元素是被搜索。开始从根节点搜索,如果数据小于键值,在左子树中搜索元素,否则搜索元素在右子树。每一个节点按照同样的算法。
struct node* search(int data){
struct node *current = root;
printf("Visiting elements: ");
while(current->data != data){
if(current != NULL) {
printf("%d ",current->data);
//go to left tree
if(current->data > data){
current = current->leftChild;
}//else go to right tree
else{
current = current->rightChild;
}
//not found
if(current == NULL){
return NULL;
}
}
}
return current;
}
插入操作
每当一个元素将被插入。首先找到它应有的位置。开始从根节点搜索,如果数据小于键值,搜索空位置在左子树那么插入数据。否则,搜索空位置在右子树并插入数据。
void insert(int data){
struct node *tempNode = (struct node*) malloc(sizeof(struct node));
struct node *current;
struct node *parent;
tempNode->data = data;
tempNode->leftChild = NULL;
tempNode->rightChild = NULL;
//if tree is empty
if(root == NULL){
root = tempNode;
}else{
current = root;
parent = NULL;
while(1){
parent = current;
//go to left of the tree
if(data < parent->data){
current = current->leftChild;
//insert to the left
if(current == NULL){
parent->leftChild = tempNode;
return;
}
}//go to right of the tree
else{
current = current->rightChild;
//insert to the right
if(current == NULL){
parent->rightChild = tempNode;
return;
}
}
}
}
}
本站代码下载:http://www.yiibai.com/siteinfo/download.html
堆 - 数据结构和算法教程™
堆是平衡二叉树数据结构,其中根节点键与它的子相比并设置相应在一种特殊情况。如果α有子节点β那么 -
key(α) ≥ key(β)
作为父的值大于这个子,这个属性会产生最大堆。基于该标准堆可以有两种类型 -
For Input → 35 33 42 10 14 19 27 44 26 31
- 最小堆 − 其中根节点的值小于或等于任一其子点。
- 最大堆 − 其中根节点的值大于或等于任一其子节点。
两个树都使用相同的输入及到达顺序构成。
最大堆构造算法
我们将用同样的例子来说明如何创建最大堆。程序创建最大堆与最小堆是类似,但使用最小值代替最大值。
我们将通过一次插入一个元素以导出最大堆算法。在任何时间点,堆必须保持其性能。 当在插入时,假设插入在堆字段在树中的节点。
Step 1 − 在堆的末尾创建新节点
Step 2 − 分配节点的新值
Step 3 − 比较其父与这个孩子节点的值
Step 4 − 如果父值小于子,那么交换它们
Step 5 − 重复步骤3和4,直到堆属性保存
注 − 在最小堆构造算法,预计父节点的值要小于子节点。
我们先看一张卡通插图来了解最大堆构建。拿我们之前用的相同输入样本。

最大堆删除算法
让我们推导一个算法的最大堆删除。删除最大(小)堆总是发生在根部去除最大(或最小)值。
Step 1 − 删除
Step 2 − 分配节点的新值
Step 3 − 比较其父与这个孩子节点的值
Step 4 − 如果父值小于子,那么交换它们
Step 5 − 重复步骤3和4,直到堆属性保存
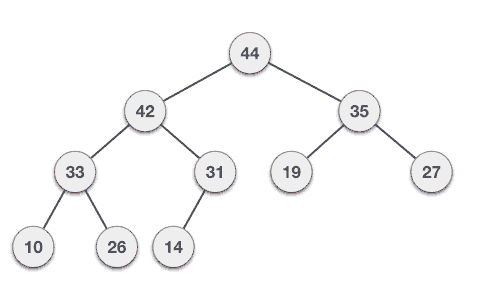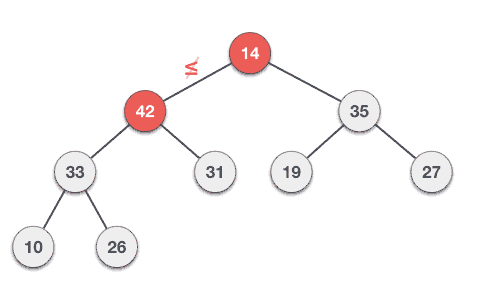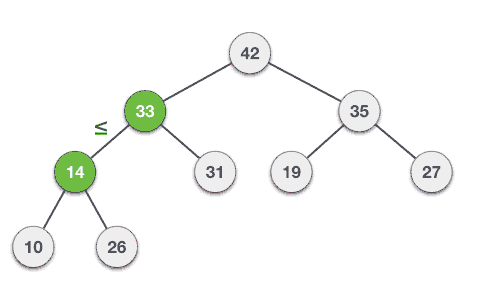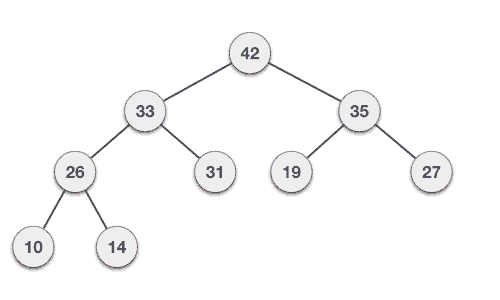
本站代码下载:http://www.yiibai.com/siteinfo/download.html
递归基础知识 - 数据结构和算法教程™
一些计算机编程语言允许一个模块或函数来调用自身。这种技术被称为递归。在递归函数α直接调用自己或调用函数β,反过来调用原函数α。该函数α被称为递归函数。
特性
递归函数可以无限执行就类似一个循环。为了避免递归函数的无穷运行,一个递归函数必须具备有两个属性 -
- 基本准则 − 必须有至少一个基本的标准或条件,例如,当满足此条件时函数停止递归调用自身。
- 由浅入深 − 递归调用应该在那个递归调用作出每次涉及靠近基标准这样的方式前进。
实现
许多编程语言通过堆栈的方式实现递归。一般来说,当一个函数(调用者)调用另一个函数(被调用者)或本身作为被调用, 调用者传送函数执行控制权被调用。
这意味着,调用方函数具有暂停其执行并在稍后继续时从被调用函数的执行控制返回。在这里,调用函数需要从执行的角度入手正是它把自己搁置。它也需要完全相同的数据值执行。为此,活动记录(或堆栈帧)可以创建调用函数。
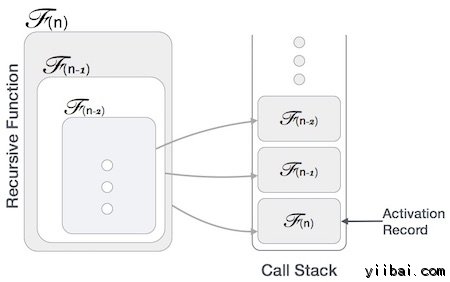
此活动记录保留局部变量的信息,形式参数,返回地址并传递给调用函数的所有信息。
递归分析
有人可能会认为,作为同样的任务可以反复地来完成,为什么使用递归?第一个原因是递归使得程序更具可读性,并因为今天的提升 CPU 系统中,递归比迭代更加高效。
时间复杂度
如果是迭代,我们采取迭代次数来计算的时间复杂度。同样,在递归的情况下,假设一切都不变,我们试着找出递归调用的次数。 调用一个函数是 Ο(1), 因此(n)数量是递归调用作出递归函数的时间 Ο(n)。
空间复杂度
空间复杂度是算作所需要的执行模块的额外空间量。如遇迭代,编译器几乎不要求任何额外的空间。 编译器不断更新并反复使用的变量值。 但如遇到递归,系统需要的递归调用作出每次存储激活记录。因此可以认为,空间递归函数的复杂性可能比用迭代的函数去更高。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
