






非结构化数据通常指没有预定义结构的数据,如图片,视频,文本等。
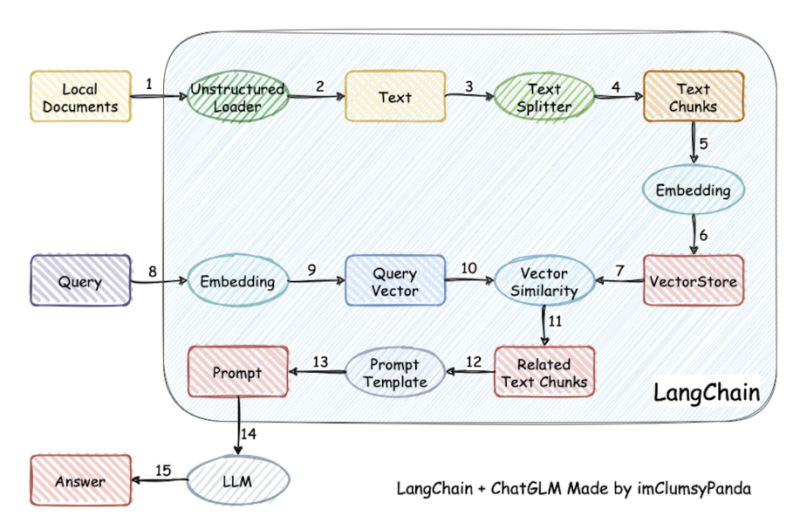
回看到过程中可选的向量数据库
用pgvector实现文本相似度检测其实相当简单
cd /tmp
git clone --branch v0.4.4 https://github.com/pgvector/pgvector.git
cd pgvector
make
make install # may need sudo
CREATE EXTENSION vector;
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name='moka-ai/m3e-base',
model_kwargs={'device': 'cpu'})
import os
from langchain.vectorstores.pgvector import PGVector
PGVECTOR_CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "postgres"),
user=os.environ.get("PGVECTOR_USER", "postgres"),
password=os.environ.get("PGVECTOR_PASSWORD", "123456"),
)
from langchain.vectorstores.pgvector import DistanceStrategy
data = [
"猫追老鼠",
"小猫捉啮齿动物",
"我喜欢火腿三明治",
"你使用的是什么embedding算法"
]
metadatas = [
{"answer":"老鼠可能被抓到"},
{"answer":"啮齿动物被抓到"},
{"answer":"火腿和三明治是不错的搭配"},
{"answer":"我使用的是m3e-base作为embedding算法,对中文的支持更好"}
]
PGVector.from_texts(texts = data,
embedding=embeddings,
collection_name="custom_qa",
connection_string=PGVECTOR_CONNECTION_STRING,
metadatas=metadatas
)
from langchain.docstore.document import Document
query = "猫捉老鼠"
print("="*80)
docs_with_score: list[tuple[Document, float]] = store.similarity_search_with_score(query)
for doc, score in docs_with_score:
print("Score:", score)
print(doc.page_content)
print(doc.metadata)
print("-"*80)
================================================================= Score: 0.04342155086519628
猫追老鼠
{'answer': '老鼠可能被抓到'}
-----------------------------------------------------------------
Score: 0.12241556104896034
小猫捉啮齿动物
{'answer': '啮齿动物被抓到'}
-----------------------------------------------------------------
Score: 0.33161097392725436
我喜欢火腿三明治
{'answer': '火腿和三明治是不错的搭配'}
-----------------------------------------------------------------
Score: 0.3587415090526611
你使用的是什么embedding算法
{'answer': '我使用的是m3e-base作为embedding算法,对中文的支持更好'}
-----------------------------------------------------------------
在实际使用中从向量数据库中搜索到的结果会被选出前几条,一起放到LLM中按照相关性分配权重进行归纳总结。
小 结

文章转载自瀚高数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
