






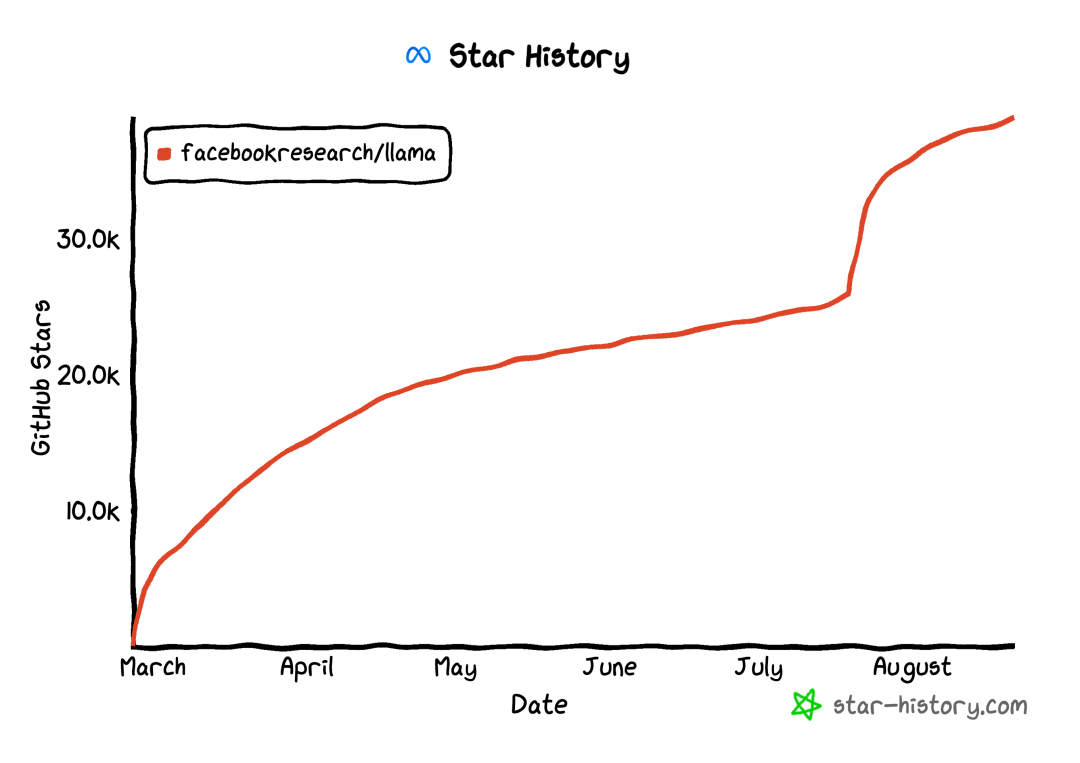
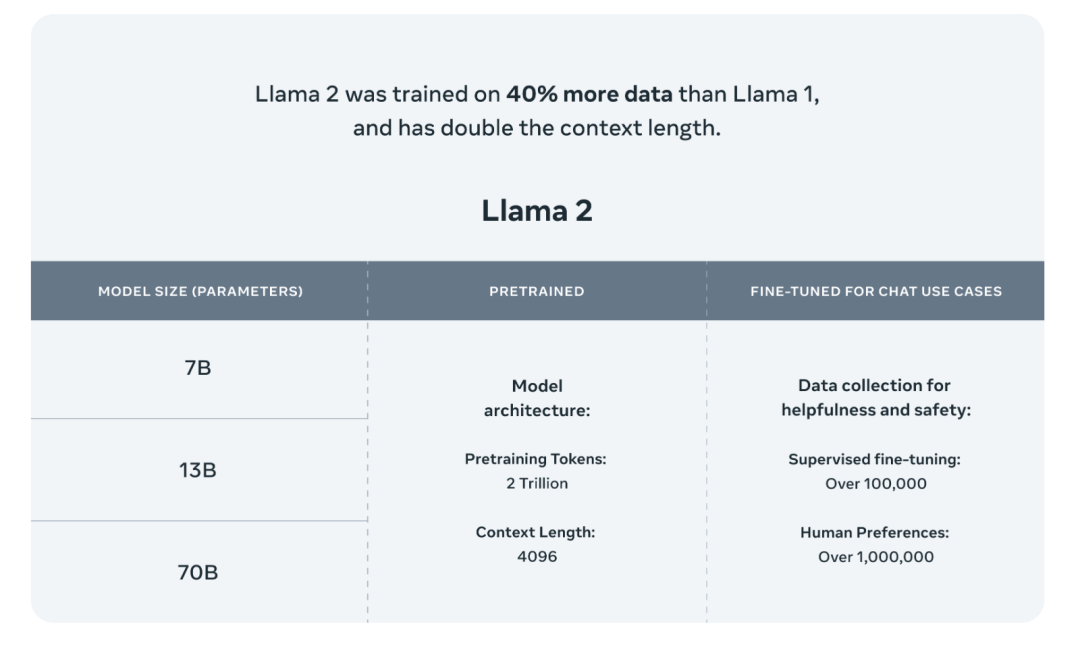
Llama

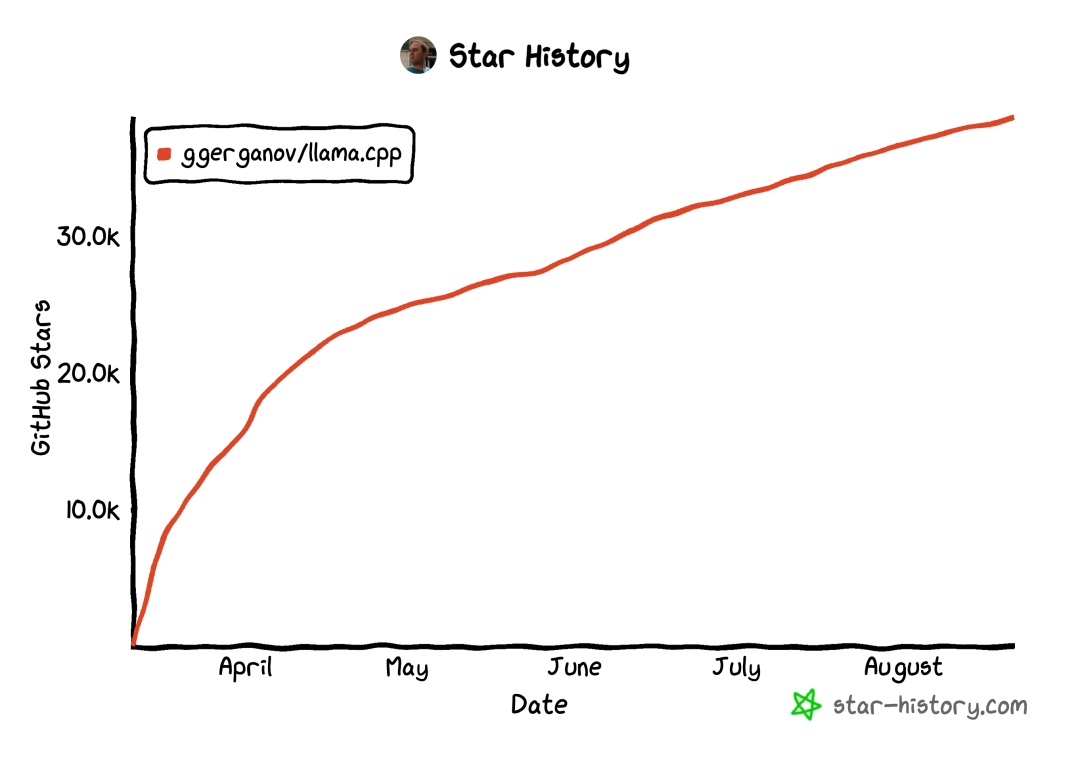
llama.cpp
在 Google Pixel5 上,以 1 token/s 的速度运行 7B 参数模型。
在 M2 Macbook Pro 上,以 16 token/s 运行 7B 参数模型。
在 4GB RAM 的 Raspberry Pi 上运行 7B 模型,速度 0.1 token/s。

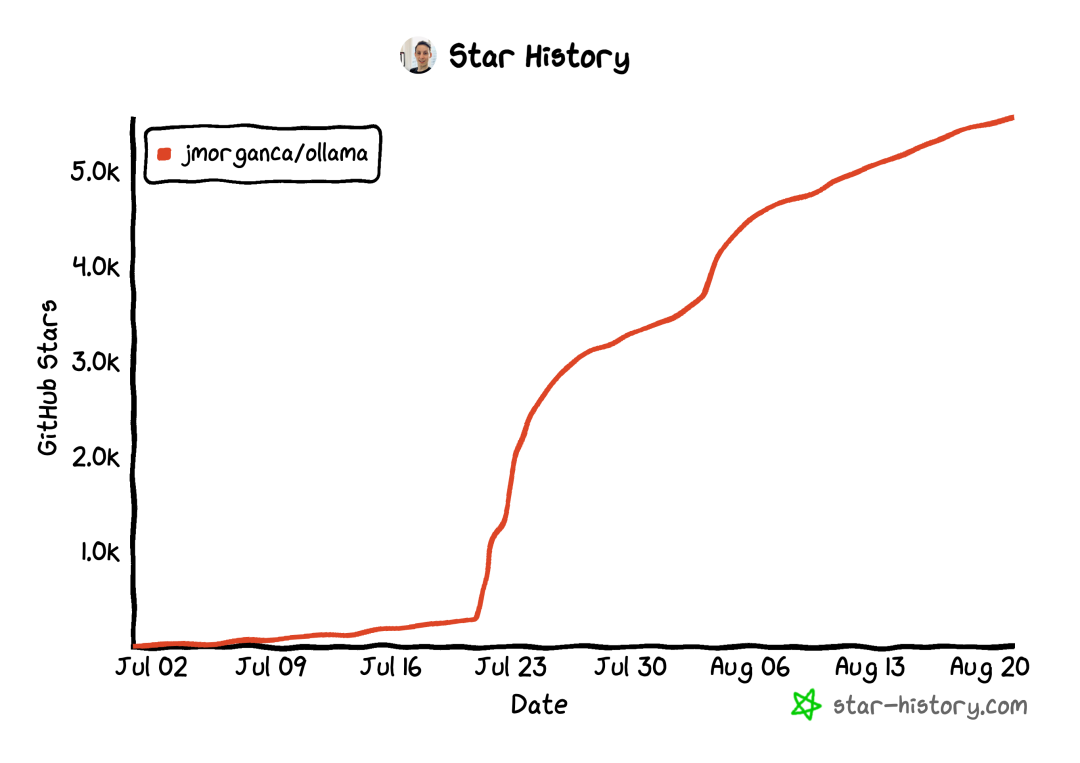
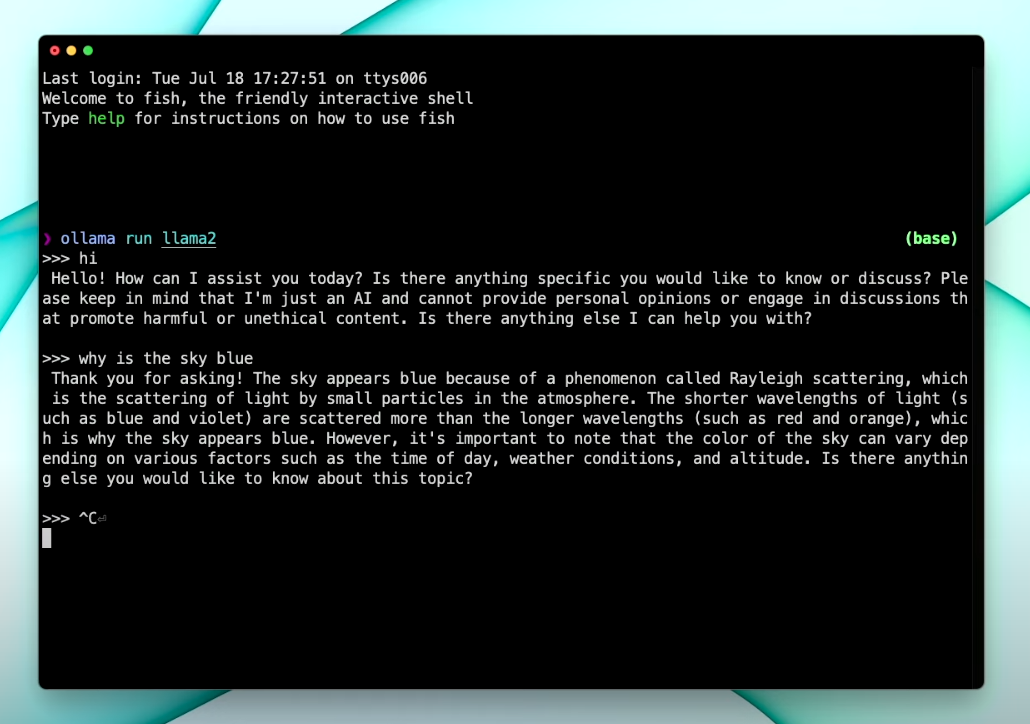
Ollama

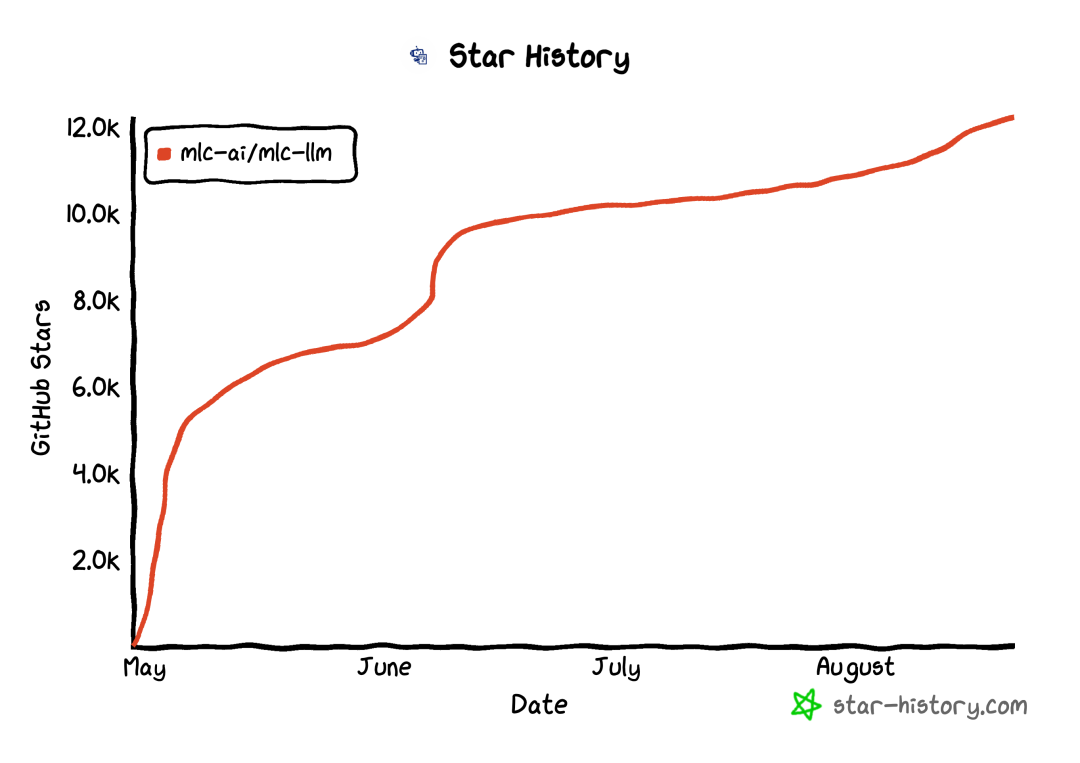
MLC LLM


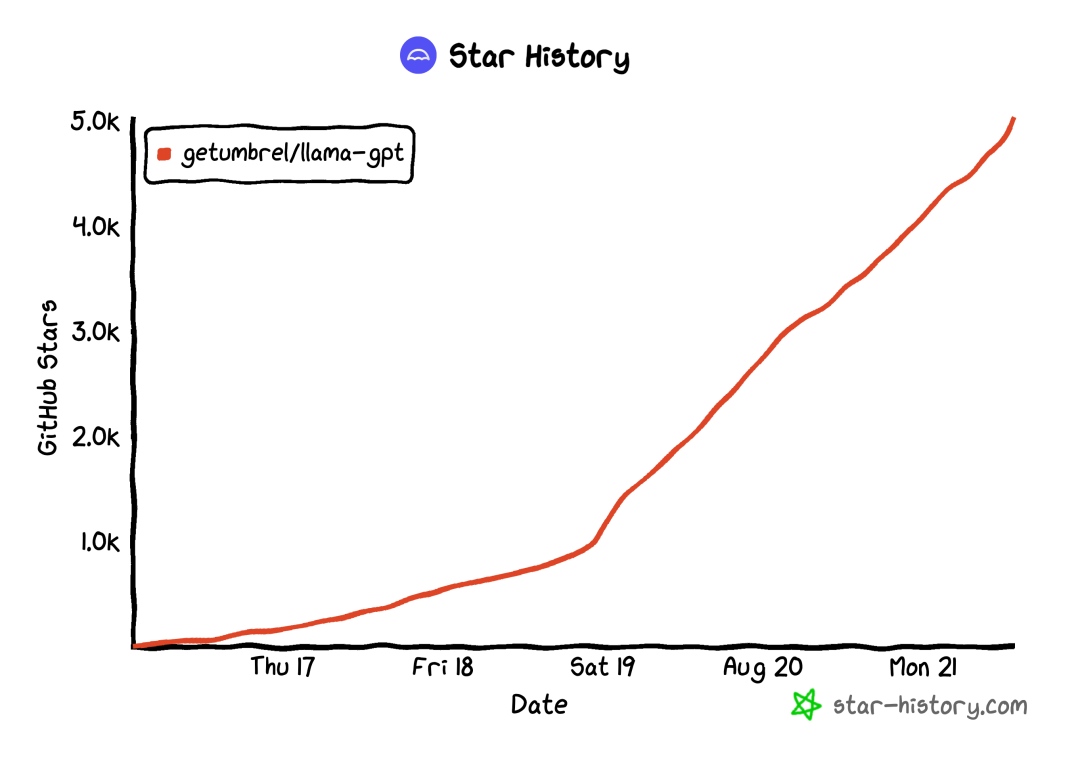
LlamaGPT
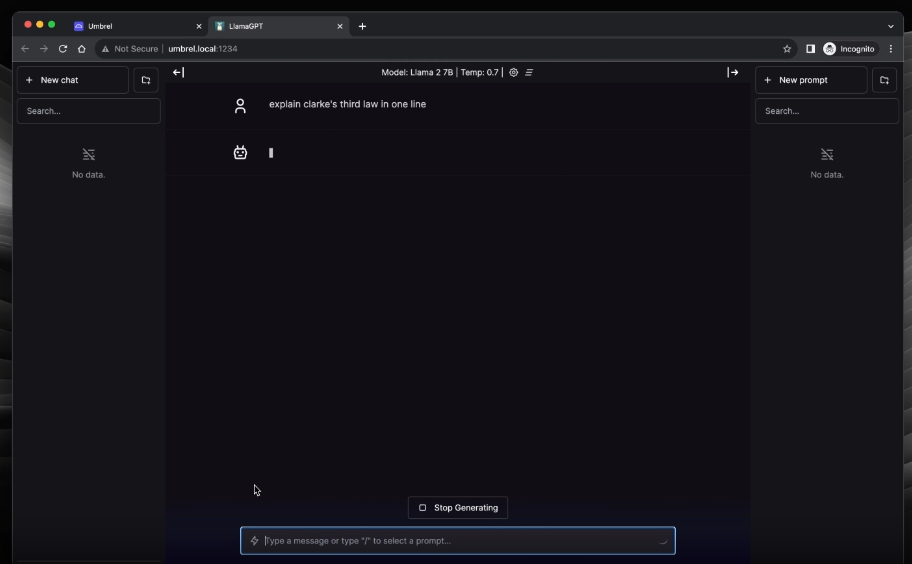

最后
https://simonwillison.net/2023/Aug/1/llama-2-mac/
https://huggingface.co/blog/llama2
https://replicate.com/blog/run-llama-locally



文章转载自Bytebase,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
