




【示例】
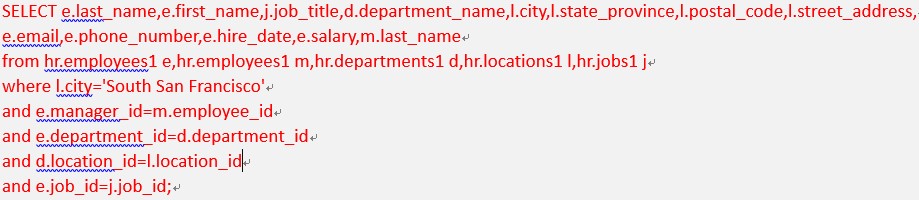
图 1 SQL语句
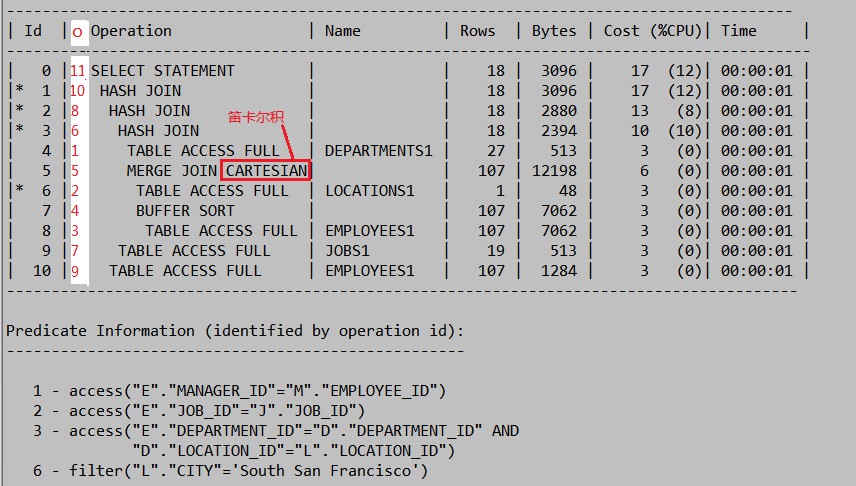
图 2 执行计划
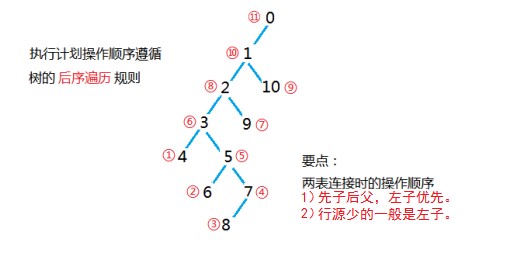
图 3 执行计划树

图 4 执行结果统计
一、 执行计划的表示
Id:执行计划的行表示,每行代表一个执行过程,但不是SQL的执行顺序,从0开始;
Operation:执行的操作描述,该描述是按前导空格进行分层的二叉树,“由根及叶”表示,前导空格最长的那行层级最低,本例中ID=8,但实际的执行顺序是“由叶到根”,自上而下,第一个叶子节点最先被执行,即ID=4,然后向下,第二个叶子,ID=6,继续,下一个叶子,ID=8,到底,逐层递退,最后输出总结果,即ID=0;
Oper Id:该Id是笔者为表述二叉树的构成加上去的,从1开始,以红圈标示;
Cost(%CPU):表示IO+CPU成本的总和,即,Cost = I/O cost + CPU
cost,Oracle会按某个算法将CPU cost转换成IO cost;
%CPU表示CPU成本占总COST的百分比,即四舍五入后的CPU/(CPU+IO) X100%
值,如ID=3的hash join,CPU占总cost的10%,而总cost为10,据此可知,该操作的CPU
cost = 10 X 10% = 1,而IO cost = 10 – 10X10% =9。
二、执行计划的遍历
SQL语句二叉树的执行采用后序遍历,其规则为:先左后右、先子后父、左支发起、逐层递退。即:对于当前结点,先输出它的左孩子,然后输出它的右孩子,最后输出该结点,而针对于任一结点,都必须按前述规则一直向下搜索,直到发现它是“盲端”,即叶子结点时为止。
故上述操作实际的执行次序,按红圈数字表示为:①②③④⑤⑥⑦⑧⑨⑩-11,结束;按ID则为:4-6-8-7-5-3-9-2-10-1-0;
本例的具体步骤表述如下:
-
先“全表扫描”(TABLE ACCESSS FULL)第一个数据表department1,别名为d;
-
再全表扫描数据表locations1,别名为l
-
再全扫第二个employees1表,别名为e;
-
对3)执行缓冲区排序;
-
对4)、2)两表执行“笛卡尔积”;
-
对1)、5)执行hash join;
-
再全扫jobs1表,别名为j;
-
对6)、7)执行hash join ;
-
再全扫第二个employees1表,别名为m;
-
对8)、9)继续hash join ;
-
最后,输出SQL执行结果。
二、执行计划的要点
上面一大堆的话看起来很复杂,甚至有点烧脑,其实,对于初学者来说帮助并不大。什么二叉树的遍历,什么SQL执行次序,搞不搞得明白关系不太大。
在执行计划中,通常我们只需要关心两件事:一是执行计划针对什么对象执行了什么类型的操作?图2中的name列就是操作涉及的对象,operation就是“动作”。对象可以是表、视图、索引等等,动作包括很多,其中最常见的就是“TABLE
ACCESSS FULL”、“TABLE ACCESS BY INDEX ROWID”、“INDEX RANGE
SCAN”等等,优化原则是大表中只读取小部分数据时,尽量让执行计划走索引,防止“全表扫描”,小表能走索引更好,走不了索引,全表扫描也关系不大;二是图4统计结果中的一致性读(consistent
gets)的数值是否过大?这个值越大,则表示该SQL执行效率越低。一致性读的概念是在处理当前操作的时候需要在一致性读状态上获取了多少次数据块,这些块产生的主要原因是因为在当前查询的过程中,同时有其他会话也对数据块进行了修改操作,为保证数据的一致性,所以需要对回滚段中的数据块的前映像进行查询。
简单说,对象与操作指示了使用什么手段和途径来获取数据,一致性读代表了你操作的数据是否属于“热点”,要么你“圈定”的范围过大,要么你读取的数据“过热”。解决范围的问题是增加筛选条件和尽量让计划走索引。
索引的用意是“以空间换时间”。你的会话用时越短,那么造成“拥塞”的几率就大幅下降,“过热”之说自然就缓解了。可是,这些都是在付出磁盘空间的前提下才达成的,反而言之,索引越多,不仅是占用的空间增大,而且数据的维护代价更大,这需要根据使用场景进行平衡与折中。
三、执行计划的谓词
SQL 谓词就是返回值为 TRUE、FALSE 或 UNKNOWN 的表达式。
谓词用于 WHERE 子句 和 HAVING 子句 的搜索条件中,还用于 FROM
子句的联接条件以及需要布尔值的其他构造中。
图2执行计划的“predicate information”给出了当前语句的谓词信息。
Predicate Information 有2 个取值:filter 和 access,其中access
一般为索引读或hash join,此处最重要的在于查看filter是否有发生了数据类型转换,一旦转换,则可能抑制了索引,也增大了开销。如下:COL1是字符型,而谓词对其强制转换,建议修改COL1 = ‘2’。
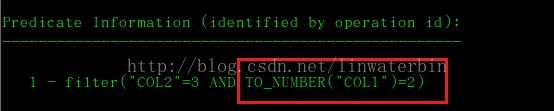
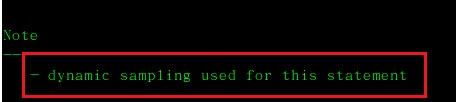
此外,如果谓词信息提示“语句采用动态采样”(Note:–dynamic sampling used for this
statement),则表明统计信息过期变质了,或者压根就没分析过表,用户需要手工分析表或索引。如下:对相关数据表或索引收集统计信息,exec dbms_gather_stat或者ANALYZE TABLE/INDEX ……compute statistics。
四、多表连接的驱动
1)nested loop join (NL连接)
2)hash join(HJ连接)
3)sort merge join(SM连接)
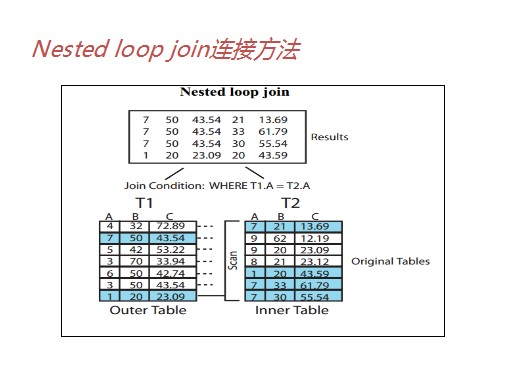
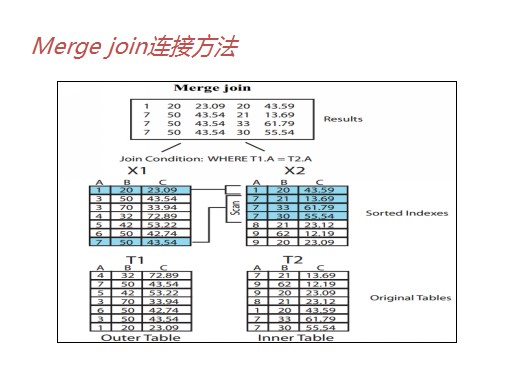
三种连接方法适用场景

五、执行计划的干预
Oracle
Hints是一种机制,用来告诉优化器按照我们告诉它的方式生成执行计划,为语句添加
Hints(提示)来实现干预优化器优化的目的。
不建议在代码中使用hint,在代码使用hint使得CBO无法根据实际的数据状态选择正确的执行计划。
通常的hint提示有:
/*+ index (emp,emp_idx) */ 强制优化器走索引
/*+ use_nl(emp,dept)*/ 表示采用嵌套循环连接。
/*+ use_merge(emp,dept) */ 表示采用排序合并连接。
/*+ use_hash(emp,dept)*/ 表示采用哈希连接。
/*+ leading(emp) */ 表示选择emp为驱动表。
/*+ order */ 按照from列出的表顺序进行连接。
/* +parallel */ 使用并行查询(先要将表使能为并行查询alter table xxx
parallel|noparallel)
例1: /*+DRIVING_SITE(TABLE)*/
强制与ORACLE所选择的不同的驱动表进行查询执行.
例如:
SELECT /*+DRIVING_SITE(CLINIC_MASTER)*/ * FROM CLINIC_MASTER
C,OUTP_ORDER_DESC O WHERE C.VISIT_DATE=trunc(O.VISIT_DATE) AND
C.VISIT_NO=O.VISIT_NO ;
例2 /*+USE_NL(TABLE)*/
将指定表与嵌套的连接的行源进行连接,并把指定表作为内部表.
例如:
SELECT /*+ORDERED USE_NL(OUTP_ORDER_DESC)*/
OUTP_BILL_ITEMS.VISIT_NO,OUTP_ORDER_DESC.ORDERED_BY,OUTP_ORDER_DESC.DOCTOR FROM
OUTP_ORDER_DESC,OUTP_BILL_ITEMS WHERE
OUTP_ORDER_DESC.VISIT_NO=OUTP_BILL_ITEMS.VISIT_NO;
例3. /*+USE_MERGE(TABLE)*/
将指定的表与其他行源通过合并排序连接方式连接起来.
例如:
SELECT /*+USE_MERGE(OUTP_ORDER_DESC,OUTP_BILL_ITEMS)*/ * FROM
OUTP_ORDER_DESC,OUTP_BILL_ITEMS WHERE
OUTP_ORDER_DESC.VISIT_NO=OUTP_BILL_ITEMS.VISIT_NO;
例4. /*+USE_HASH(TABLE)*/
将指定的表与其他行源通过哈希连接方式连接起来.
例如:
SELECT /*+USE_HASH(OUTP_ORDER_DESC,OUTP_BILL_ITEMS)*/ * FROM
OUTP_ORDER_DESC,OUTP_BILL_ITEMS WHERE
OUTP_ORDER_DESC.VISIT_NO=OUTP_BILL_ITEMS.VISIT_NO;
六、聚簇因子直方图
- 聚簇因子(clustering_factor):
是使用B树索引进行区间扫描的成本很重要因素,反映数据在表中分布的随机程度。聚簇因子越高,则数据在表中的分布随机程度越高,也就是越能说明索引条目指向随机的表数据块,进行索引范围查询的时候就会产生越高的I/O量。反之,聚簇因子越接近表数据块的数量。
我们在查询索引状态的时候,通常会用到user_indexes这张表,这张表中有一列叫CLUSTERING_FACTOR(即,聚簇因子)。好的聚簇因子,其值接近表的块数;差的聚簇因子,其值接近表的行数。
改进聚簇因子的办法是:
1)对于表上的多个索引以及组合索引的情形,索引的创建应考虑按照经常频繁读取的大范围数据的读取顺序来创建索引。
2)定期重构表(针对堆表),也就是使得表与索引上的数据顺序更接近。注意:是重构表,而不是重建索引。
3)使用聚簇表来代替堆表。
- 直方图:
在Oracle中直方图是一种对数据分布质量情况进行描述的工具。它会按照某一列不同值出现数量多少,以及出现的频率高低来绘制数据的分布情况,以便能够指导优化器根据数据的分布做出正确的选择。在某些情况下,表的列中的数值分布将会影响优化器使用索引还是执行全表扫描的决策。
analyze table t1 compute statistics; --收集统计信息,但没有收集索引列的直方图
analyze table t1 compute statistics for all indexed columns;
收集统计信息包括收集直方图
select * from user_tab_histograms where table_name=‘T1’; —查询直方图视图
七、写在最后
刚开始写下这个题目时,我还没有发现自己给自己挖了个大坑。写着写着,麻烦来了。首先,这个坑所涉及的范围很广泛,你很难三两句交代清楚,而更头大的是,我发现自己越来越不清楚,这有点像盲人骑着瞎马,现在在哪儿?下一站是哪儿?目标要去哪儿?反正我是“两眼一摸黑”;其次,几乎这个坑所涉及的每一个主题,在网上都有无数好手天花乱坠的各种解释,有从官方文档翻译过来的,有从实验模拟出来的,有不知道从哪儿“参考”过来的,这很有点像早年在电线杆上出现的小广告——啥病都敢治,啥药都敢吃,你所能做的,就是在沙子里面找芝麻,因为你其实跟他们没啥区别,甚至也看不到别人的“尾灯”;最后,关于这个坑的方面写起来似乎没边没沿,但实际上你能做的事却很有限,即便做了努力,也不要对结果抱有任何不切实际的幻想。因为性能优化说到底,它跟软、硬件环境是密切相关的,你需要在投入和产出上综合权衡。
何况,某些优化手段是有风险的,某些应用场景你通常也是没法准确模拟的,所以制定详细、周密的计划就成了重中之重的大事。或许,你辛辛苦苦地优化了一个流程环节,满以为可以高枕无忧了,然而,这个流程的下一个环节正迎来之前在上一个环节尚未暴露出来的“隐患”。这时,你才发现,你成了这个连锁反应中的一个棋子,后面似乎还有一盘更大的棋在等着你呢。
有人说,跑题是我一直以来的老毛病,呵呵,这人跟我中学的历任语文老师一样,堪称“所见略同”的英雄。
这是一段没有前言的后语。
参考文献:
-
什么是 SQL 谓词,如何使用 SQL
谓词?https://www.cnblogs.com/vin-c/archive/2022/06/13/16371426.html -
Consistent gets
说明https://www.cnblogs.com/tianlesoftware/archive/2012/09/16/3609188.html -
关于consistent gets https://www.cnblogs.com/lkj371/p/15168591.html
-
聚簇因子 https://blog.csdn.net/flighting_sky/article/details/8847568
-
oracle中hint 详解 https://www.cnblogs.com/emilyyoucan/p/7844795.html
