




论文分享
本篇文章探讨了将向量检索系统与关系数据库集成的问题,用于支持近似最近邻搜索和关系运算符的混合查询。然而,高维向量索引因为不具备传统索引的查询单调性属性,而导致了现有的向量检索系统依赖于保留单调性的临时索引(通过召回 TopK')来方便查询。由于难以预测最佳 K',从而查询性能不理想。
作者提出了 VBASE 系统,该系统声明了一个共同属性-松弛单调性,将两个看似不兼容的系统统一起来。这一共同属性使 VBASE 能够规避仅有 TopK 接口的限制,从而显著提高效率。同时证明它保留了基于 TopK 的解决方案的召回率。作者从 VBASE 系统架构、查询处理和优化技术等方面来介绍 VBASE 的方法。论文还提供了评估结果,表明 VBASE 在复杂的向量查询上比其他向量系统性能高出三个数量级。
贡献
VectorSearch
1.VBASE 正式定义了 "松弛单调性"。这一特性代表了所有向量检索系统的核心,以及这些索引能有效工作的原因。
2.VBASE 基于松弛单调性构建了一个统一数据库引擎。可以处理多种复杂查询的情况。
3.VBASE 与纯 TopK 的方法有相同的精度,且执行计划更高效。
4.基于 PostgreSQL 实现 VBASE,仅额外增加2000行代码。
方法
VectorSearch
1.松弛单调性
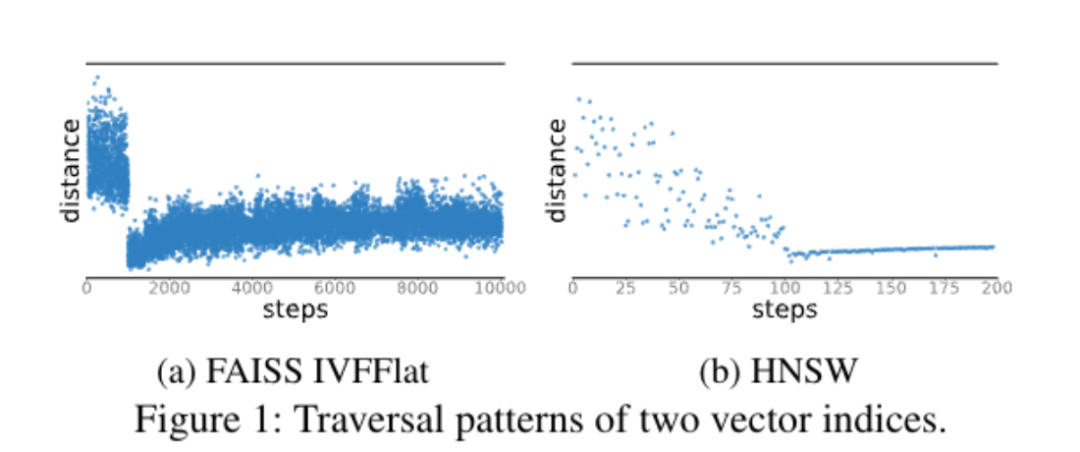
论文以 IVFFlat 和 HNSW 为例,认为绝大多数近似最近邻检索算法都遵循两阶段的检索模式,即查询首先逐渐接近目标向量邻域,然后趋于稳定,并以近似方式稳步偏离目标向量区域。松弛单调性使得系统通过计算以目标向量为中心的邻域球半径与当前索引遍历位置到目标向量之间的距离来确定查询是否已进入第二阶段。VBASE 系统利用这一特性大大提高了效率,同时保留了基于 TopK 的解决方案的精度。
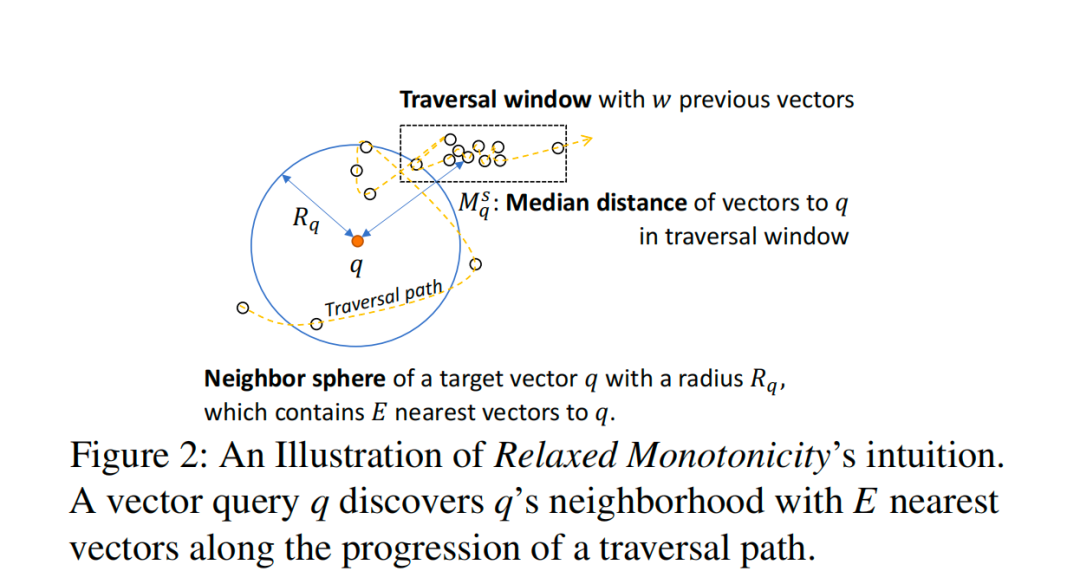
从论文中的图2,我们可以看出 VBASE 如何利用松弛单调性来作为终止条件。该图表示了一个二维空间,其中一个查询向量 q 位于中心,一组向量 v1、v2、...、vR 围绕 q 排列成一个圆圈。同时会维护一个遍历窗口,该窗口在遍历索引时移动。当索引遍历离开以 q 为中心的球体并进入第二阶段时,查询就会终止。要确定它是否进入第二阶段,需要首先定义 Rq,即以 q 为中心的相邻球体的半径,以及 Msq,即查询的当前索引遍历窗口中的点与 q 之间的距离的中位数,是否大于 Rq。
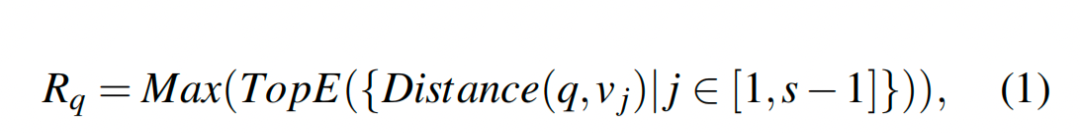
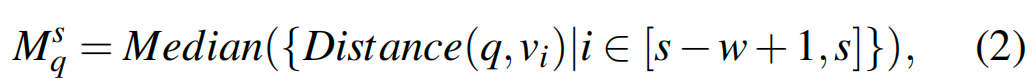
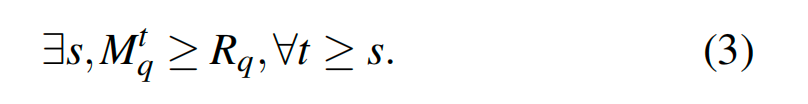
2.图索引中的参数定义
以 HNSW 为例,搜索阶段使用最佳优先(Brute Force)遍历,从一个起点开始。BF 检索会维护一个大小为 ef 的候选队列。这个队列实质上代表了包含 ef 个向量的邻域圆空间。因此,对于 HNSW,E 等于 ef。BF 遍历会通过候选队列中的向量,并访问其相邻向量来扩大探索范围。如果某个邻居未被访问,且其与目标向量 q 的距离小于排序队列中最远的向量(即 Rq),遍历会用新向量替换最远的向量,并重置队列。由于遍历只比较被遍历的当前向量本身和 Rq,因此公式 2 中的遍历窗口 w 等于 1。
3.基于分区的索引中的参数定义
基于分区的向量索引,如 FAISS IVFFlat 和 SPANN ,将向量划分为多个簇,在这些簇中,附近的向量聚集在一起。在第一阶段的遍历过程中,IVFFlat 会遍历聚类中心,找出 m 个最接近的簇,然后在第二阶段遍历 m 个簇中的向量,当 m 个簇中的所有向量都遍历完毕时,IVFFlat 结束,这表明在向量搜索访问 m 个簇后,已经满足了松弛单调性公式 3。有鉴于此,公式 1 中的 E 设为 TopK 查询的 K,公式 2 中的遍历窗口 w 设为 m 个簇中的向量总数。
4.标量索引中的参数定义
标量索引是宽松单调性的一种特例,因为它永远满足严格单调性。其中 w 和 E 都设为 1,公式 3 始终为真。
5.混合查询
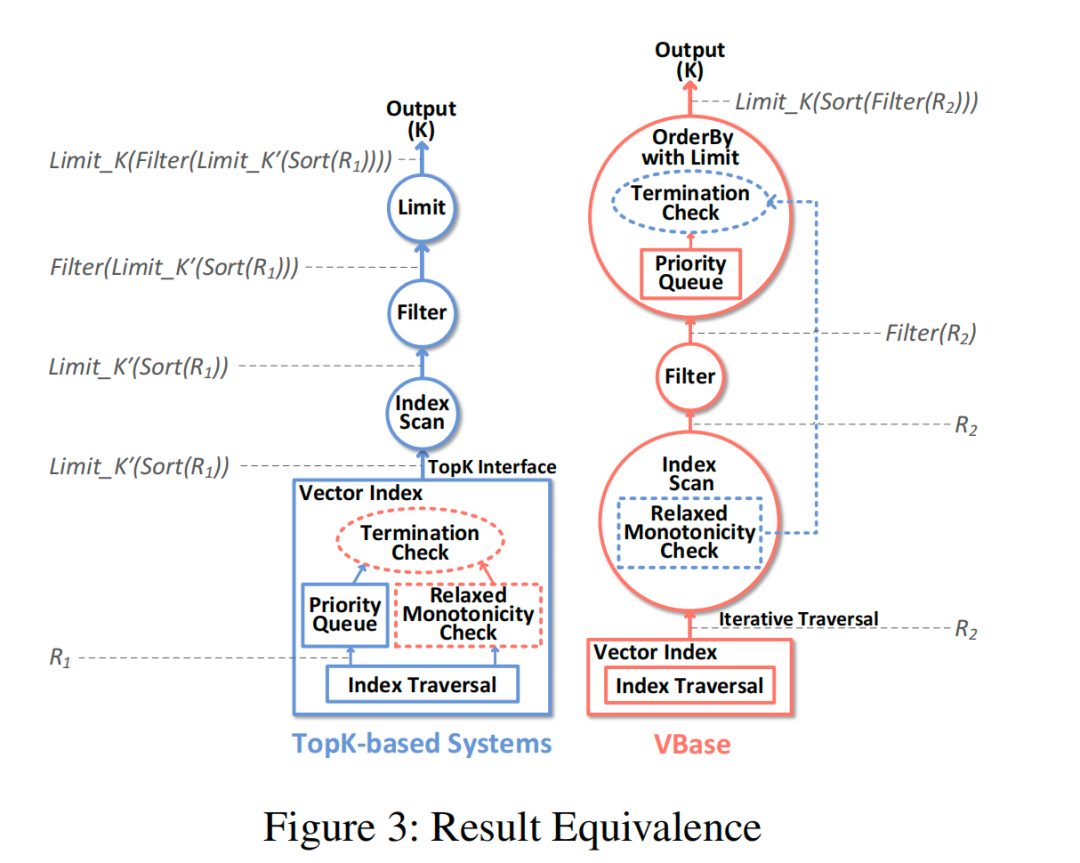
从论文中的图3可以看出,在混合查询场景下, VBASE 系统与之前的基于Topk的检索系统的区别。首先TopK 系统中,首先需要暴露 TopK 接口,在向量集合 R1 中返回 TopK'。这 K' 个向量会通过 Filter 进行过滤。最后形成输出 K。而在 VBASE 中,这是一个迭代搜索的系统(符合 sql 优化中的火山模型),向量集合 R2 中的每条向量都会首先检查松弛单调性,如果发现正在远离目标则直接终止查询。接下来通过过滤器,继续检查优先级队列(索引原始的终止条件)。迭代终止条件主要有两个,一是K近邻检索的原始终止条件,二是松弛单调性检查。
6.火山模型
VBASE 基于 ProstgreSQL 实现,且满足火山模型。sql 查询中的火山模型的定义如下:该计算模型将关系代数中每一种操作抽象为一个 Operator,将整个 SQL 构建成一个 Operator 树,从根节点到叶子结点自上而下地递归调用 next() 函数。
例如 SQL:
SELECT Id, Name, Age, (Age - 30) * 50 AS BonusFROM PeopleWHERE Age > 30
对应火山模型如下:
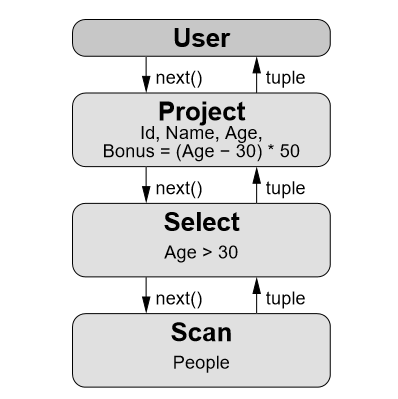
在 VBASE 中会提供三种接口分别是 Open、Next、Close。例如在 HNSW 中 VBASE 调用 Open 在高层图上进行搜索。在查询执行期间,每次调用 Next 都会返回当前最近的未访问节点,将其记录下来,并将其邻近节点添加为候选向量。所有向量将在 Close 函数中清除。
7.查询计划
查询计划是估算复杂查询的成本的过程。在本文的背景下,查询计划包含估算涉及近似最近邻搜索和关系运算符的查询的向量代数计算、选择性估计和索引扫描成本。向量计算的成本为与维度相关的函数,而选择性估计则使用基于采样的方法进行。索引扫描成本估算包括估算基于分区和基于图表的索引 的启动成本和遍历成本。三种成本公式表示如下:
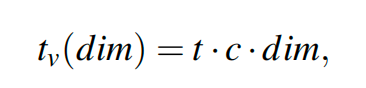
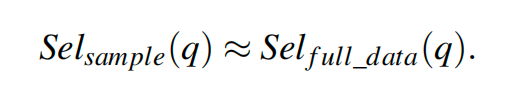
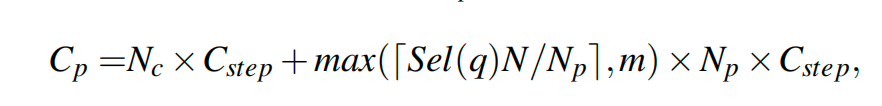
实验
VectorSearch
定义了八种不同的复杂查询场景,分别为单向量的 TopK、单向量 TopK+ 数值过滤、单向量 TopK+ 字符串过滤、多列 TopK、多列 TopK+ 数值过滤、多列 TopK+ 字符串过滤、向量的范围搜索、Join 检索。
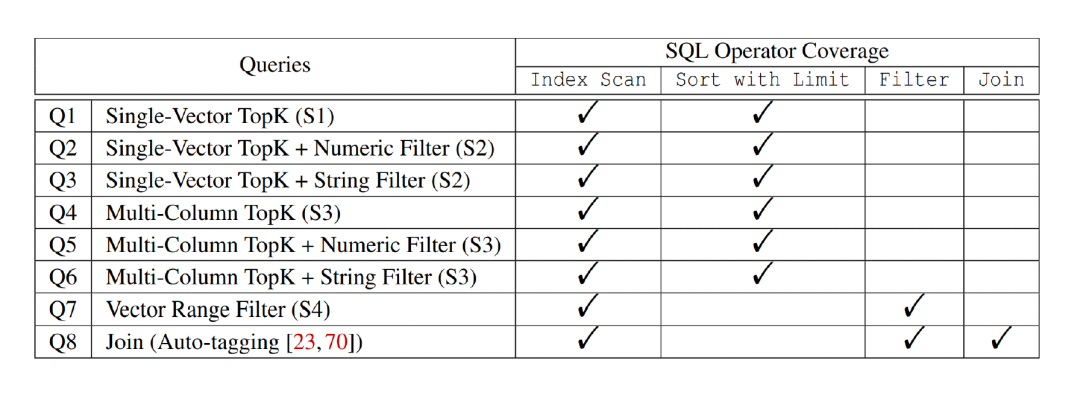
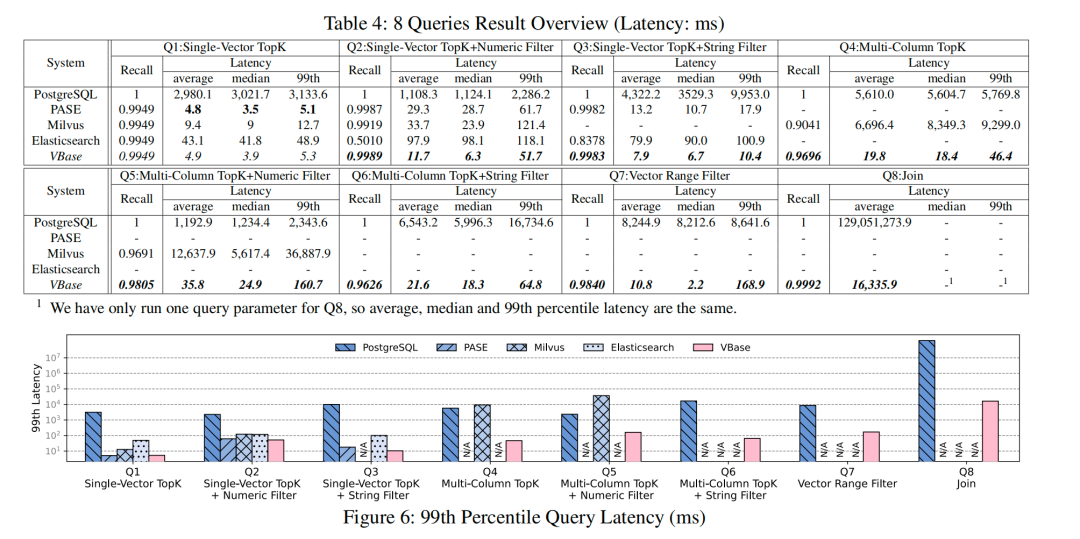
从实验结果来看,目前对一些复杂场景的查询,大多数向量数据库还并没有支持,而 VBASE 支持了八种检索模式,且延迟和召回率有一定的保证。其中在单向量 TopK+ 过滤器的场景下对比 TopK 系统会有10倍的性能提升。多向量查询对比 ANNS 会有100倍的提速。Join 场景下,对比 ProstegreSQL 会有三个数量级的优势。
总结
总结来看,VBASE 系统基于 ProstgreSQL 开发,利用松弛单调性的特点,集成了向量检索和过滤器形成了统一查询引擎。代码量不到2000行的更新,但保证了在复杂查询场景下的检索性能。点击阅读原文可获取论文链接。
— 参考文献 —
[1] Zhang Q, Xu S, Chen Q, et al. {VBASE}: Unifying Online Vector Similarity Search and Relational Queries via Relaxed Monotonicity[C]//17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). 2023.
[2] https://github.com/facebookresearch/faiss.
[3] Malkov Y A, Yashunin D A. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 42(4): 824-836.
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

