




论文分享
分享者:田冰,华中科技大学计算机在读博士
主题:可计算存储架构下的大规模近似最近邻搜索研究
背景
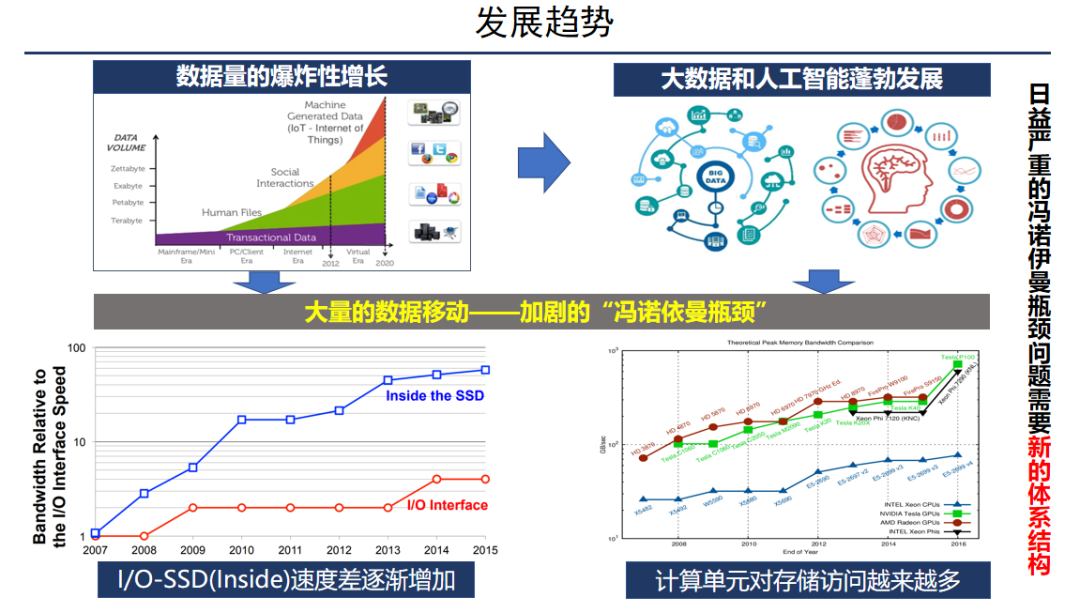
向量搜索的兴起主要源于两方面原因。首先,由于智能手机、物联网设备和社交媒体等应用的迅猛发展,非结构化数据(如图像、文本和视频等)呈现爆炸式增长的趋势。据预测,到2025年,80%的数据将由非结构化数据组成。其次,非结构化数据往往难以被计算机直接识别,需要使用特定的语义特征来实现高质量数据处理,而向量正是这种语义特征的一种形式。
这种趋势促进了大数据和人工智能的快速发展。尽管 CPU 的性能不断增强,但存储器的发展速度远远落后于 CPU,这导致了所谓的“冯诺伊曼瓶颈”问题。此外,大数据应用需要处理海量数据,计算单元对存储器的访问频率也越来越高,进一步加剧了瓶颈问题。
近年来,闪存技术得到了不断改进,但闪存内部带宽和I/O接口速度的差距仍在不断增加。这些趋势表明,我们需要新的体系结构来解决日益严重的冯诺依曼瓶颈问题。
传统的以 CPU 为核心的计算机架构存在着许多限制,特别是在处理特定领域的应用时,难以发挥出优异的性能。例如,在处理神经网络或一些并行计算时,CPU 的性能可能无法满足需求。为了弥补这种缺陷并提高计算机处理数据的能力,目前专门针对不同领域的定制化架构正在迅速发展。其原理是利用高性能的处理单元,根据数据的状态进行处理,并定制微结构以适应特定领域的应用程序,从而实现数量级的性能提升,同时还要达到更低的功耗比。
可计算存储

例如,GPU 可用于处理运算密集的任务,而 TPU、NPU 和 PIM 等专用架构也在快速发展。在数据传输方面,可以将 CPU 对网络包的处理任务、分布式环境下的一致性或并发控制卸载到 DPU 或智能网卡上,以提高系统整体效率。可计算存储是基于移动计算比移动数据更高效的思想,即在数据存储的地方做计算,以减少数据移动的开销。
存储与网络协会将可计算存储定义为一种能够提供与存储耦合的可计算存储功能,赋予存储器一定的计算资源,从而将 CPU 的一部分数据密集型任务卸载到存储器的内部架构,以减少数据移动带来的开销。
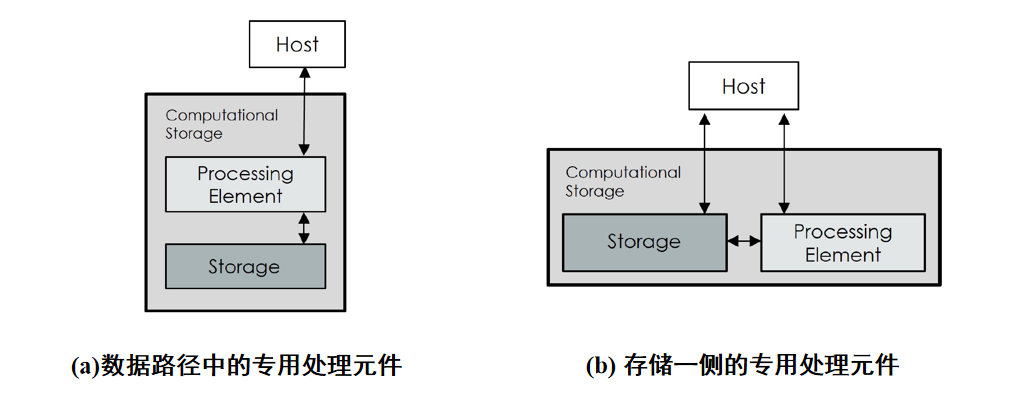
上图是两种可计算存储的通用架构。(a)为 on 的结构,即存储控制器可以同时负责数据 IO 请求和计算功能;(b)是 offpa 的架构,这种架构是在存储器内部单独集成一个 FPGA 或者是一个高端的 arm 芯片,计算单元与存储介质通过一个内部的互联总线相连接,使得计算单元可以直接去获取存储介质当中的数据,且不需要经过主机参与。
传统存储架构与可计算存储架构的对比
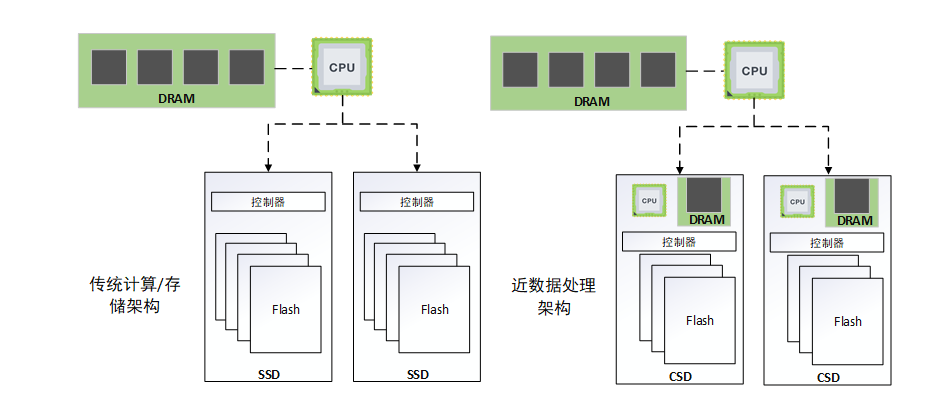
上图是传统架构与可计算存储加持的一个近数据处理架构的对比。由于可计算存储每个存储器内部它都可以进行数据处理,所以说这样一种架构,它在扩展的时候不会受到 CPU 与存储器之间的 IO 总线带宽的限制。
Vstore
那么在了解了可计算存储的概念之后,下面介绍去年发表在体系结构顶会 DAC'22 上面的一篇文章,该文章介绍了结合可计算存储与大规模 ANNS 相结合的实例 Vstore。
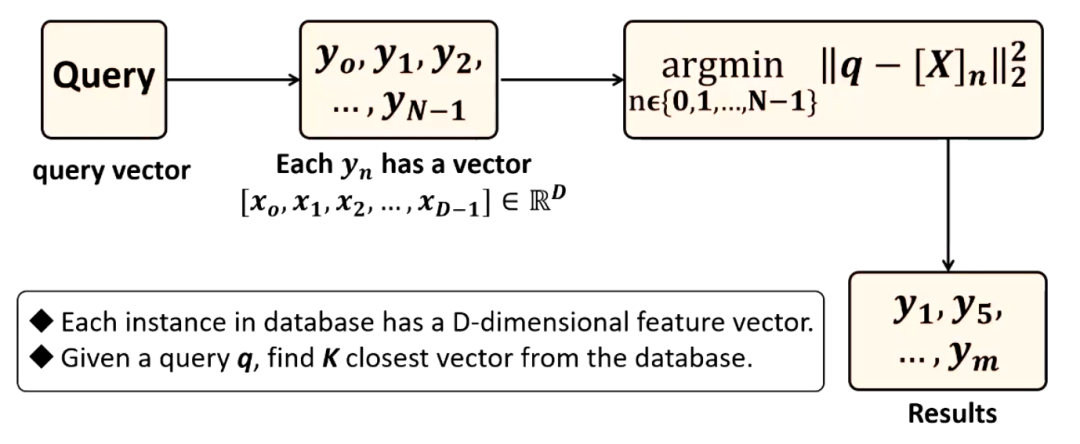
向量搜索是一种数据的处理方式。它的定义是在一个给定的数据集当中,每个实例都有一个包含 D 个特征的向量,即向量由 D 维特征组成,然后我们给定一个查询向量 q ,向量搜索的目标就是在给定的这个数据集当中,根据定义的距离计算函数找到与我们要查询的向量最接近的 K 个邻居。
为什么提出 Vstore?
以非结构化数据检索为例,传统的解决方案,都是利用手动特征进行图像检索。首先是准确率比较低,其次是返回的结果质量比较差。那么随着深度学习技术的发展,现在的技术都是利用一个神经网络,然后来获取数据特定的语义特征,并将其映射到一个高维的向量,然后来获得更高的检索的准确度。
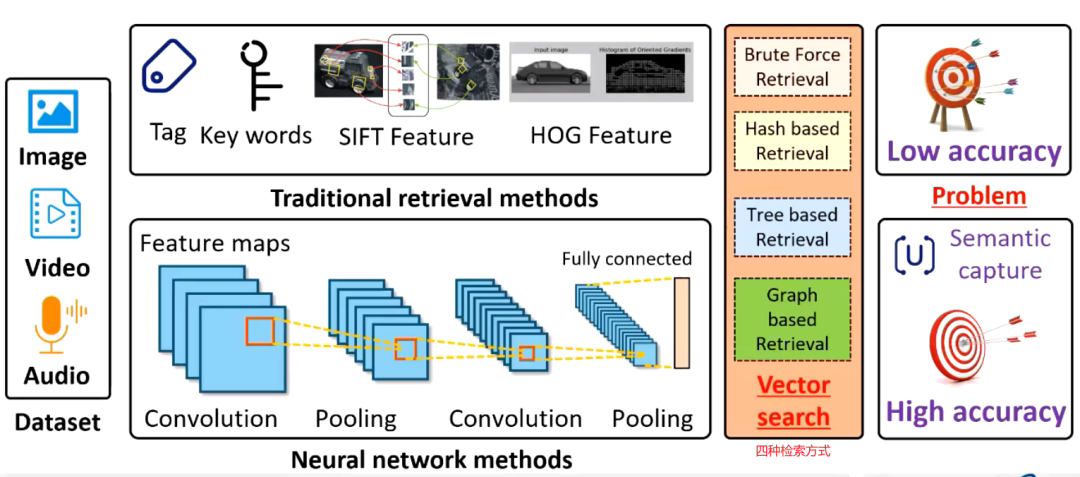
这个非结构化数据被编码为向量之后,剩下的工作其实就是向量搜索。目前的向量搜索主要的方法可以分为四种,第一种就是暴力搜索。但是暴力搜索的时间成本和资源成本往往令人难以接受,于是就出现了后面的三种最近邻搜索方式,即基于哈希的检索,基于树的检索和基于图的检索,其中基于图的检索表现出非常优异的性能。
我们来细看一下基于图的结构,它以向量作为点,然后用图结构当中的边来表征向量之间的一个距离关系,边连接的两个点即为彼此的邻居,向量之间的距离越近,他们就越有可能成为邻居。
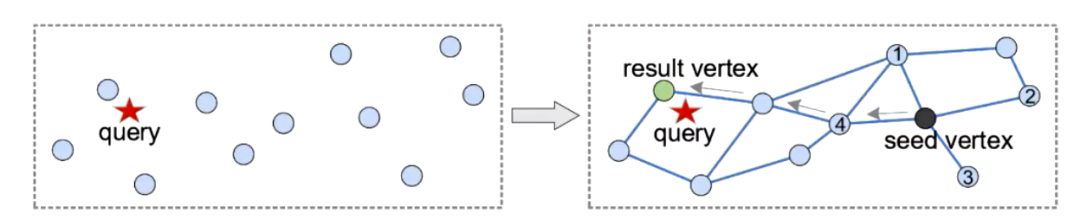
查询的大致过程如下:
我们从起始点开始从邻居节点中寻找与查询点距离最近的距离最近的结点,不断的迭代,直到找到与查询对应距离比较近的邻居,以满足设定的条件。
由于基于图的方法表现出非常好的性能呢,针对它学术界进行了很多研究。但是随着语义信息更加丰富的数据集的逐渐增多,对生产系统提出了更高的挑战和要求。
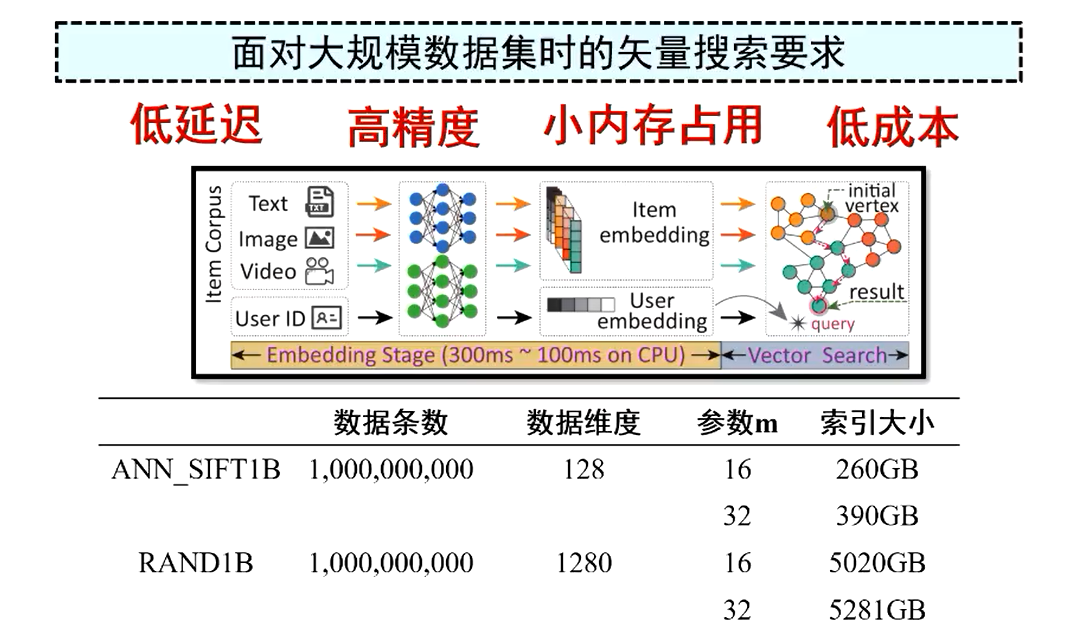
首先要求更低的延迟和更高的准确度。
我们以推荐系统为例,查询在进行向量搜索之前必须经历不同的处理阶段,所以向量搜索阶段的执行时间限定在亚毫秒级别甚至更短。但是如果我们使用 CPU 来处理十亿级别的数据集时,它的处理时间往往都要超过100毫秒。
第二个就是需要更小的内存占用和成本。
虽然上面我们知道基于图的方法能表现出优异的查询性能,但是这样一个结构最大的缺点就是需要消耗大量的内存空间。比如对十亿数据集建立一个图的索引需要超过 390GB 的 DRAM 才能容纳所有的数据,也就是说,处理这样的数据集必须配备 390GB 以上的内存。所以小的内存占用,可以释放数据集在向量检索阶段所耗费资源,并且降低数据中心总的应用成本。
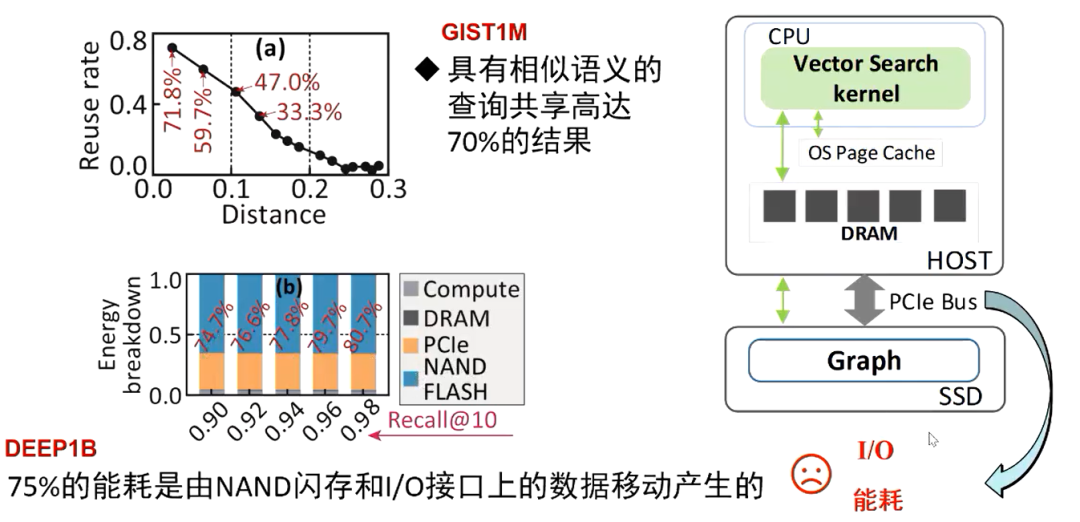
通过运行 GIST1M 和 DEEP1B 这两个数据集来对应用层面和系统层面进行分析。在应用层面,通过执行相似查询时分析顶点访问的轨迹,发现具有相似语义的查询在执行的过程中会共享70%的结果。在系统层面,如果将 DEEP1B 的图索引存储在 SSD 中,可以发现总能耗中有75%是由闪存的内部芯片和 IO 接口之间的数据传输产生的,这表现出一个显著的 IO 瓶颈的问题。
因此,为了降低向量搜索的时间开销和存储成本,这篇文章提出了一种基于可计算存储的解决方案,也就是 Vstore。
原先在主机上运行向量搜索,每发送一个 IO 请求实际上都要经过操作系统复杂的虚拟文件系统,块 IO 接口以及设备驱动这些复杂的 IO 栈。现在 Vstore 可以将基于图的向量搜索过程全部卸载到可计算存储设备当中,避免了在搜索的过程中产生的大量的 IO 请求以及复杂的操作系统存储栈,而且还释放了主机的 CPU 以及内存资源,让 CPU 有更多的资源去负责别的工作。
整体架构
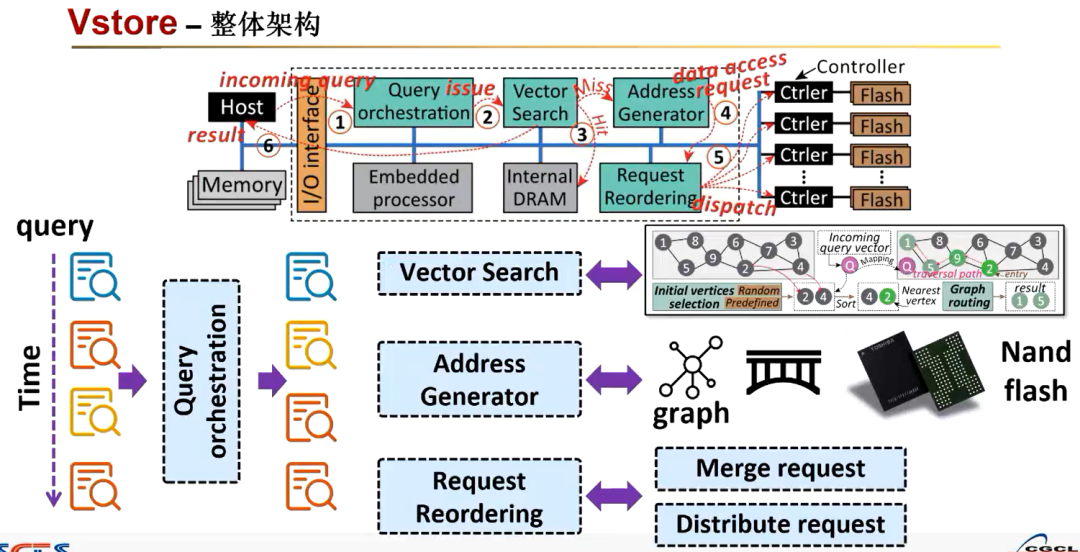
Vstore 的实现是在 OpenSSD 里 ssd 的控制器当中,可以充分利用 ssd 内部的带宽。它主要包括查询编排,向量搜索,地址生成器和请求编排四个引擎(上图中蓝绿色部分)。
查询编排引擎主要是负责重新组织我们传入的查询,以便在芯片内存当中重复使用读取的向量。
向量搜索引擎就是将图的搜索过程从软件映射为硬件的一个电路,支持初始顶点选择和图形路由阶段,以进行基于图形的向量搜索。
地址生成器引擎旨在识别顶点和邻居列表的地址请求编排会对每一个请求进行合并和分配,然后来提高数据的传输带宽。
下面具体的介绍一下。
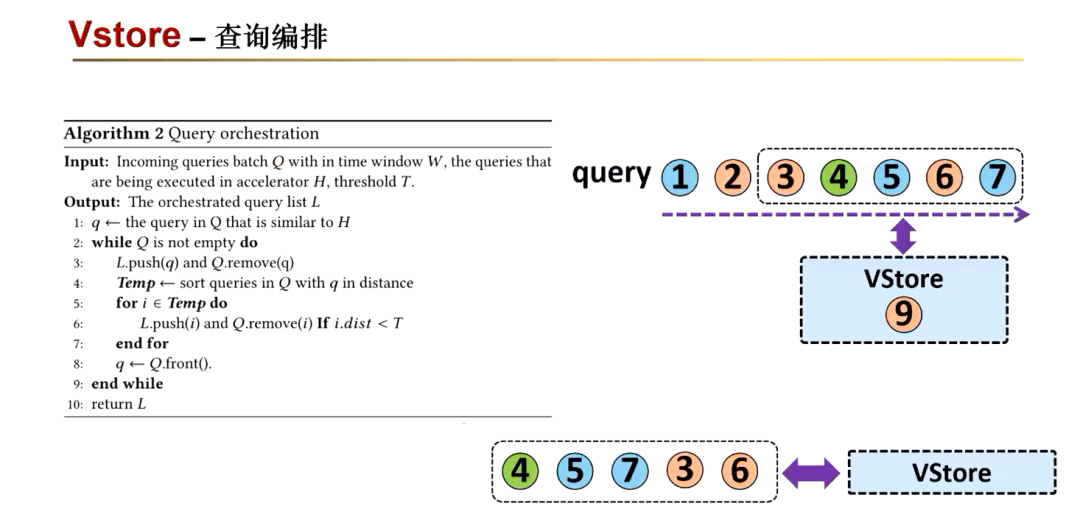
先来看一下查询的编排。它是基于相似的语义查询,可能会共享相同的图片的路径,最终在图中相同的区域终止。所以在执行的过程中,首先按照与正在执行查询的一个距离关系,就是对时间窗口内的查询进行重新的一个排序,使得接下来要执行的一个查询与正在处理的查询之间有着更多的数据重用,来达到更高的数据成用率。再评估剩下的查询它们之间的距离,将相似的查询分组在一起,这样可以有一个前后的关系,来达到良好的数据重用。
向量搜索引擎维护了三个缓冲区,分别是边的缓冲区,顶点的缓冲区,还有地址的缓冲区。在具体的执行过程中,如果要请求特定的顶点,它会首先在顶点的缓冲区里面去寻找,如果命中的话,那就直接从这个缓冲区里面去读取数据,就不需要再发送请求了;如果不命中的话,就把对应的顶点发送给地址生成器。
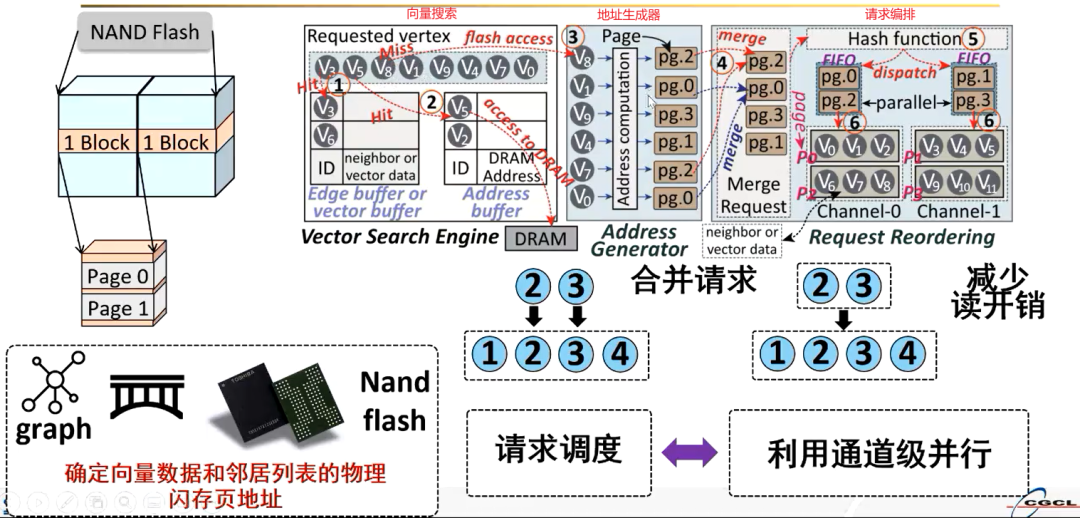
地址生成器的作用就是根据顶点来计算它的对应的物理闪存页地址。但是由于 ssd 内的闪存它的操作粒度是以页为单位的,一个页的粒度大小往往是 4KB 左右,而顶点向量的大小一般是几十字节或者几百字节。如此一来,一个页就有可能包含大量的顶点,所以这就会出现一个现象,不同的顶点会对应相同的物理闪存页;如果按照顺序对这些页进行请求的话,会造成一个冗余的数据访问。
因此可以将同一个页对应的不同的请求进行合并,比如上图中的顶点 V7 和 V8 对应的物理页地址都是 pg.2,就可以将这两个请求进行合并,在读取 pg.2 的时候,同时把顶点 V7 和 V8 的信息都给读上来,这样的话来减少请求的次数。
由于 ssd 内部配置了多个闪存的通道,每个闪存的通道都有一个 flash 的控制器,可以单独的进行数据的读取,这样一来就可以实现并行数据处理。如果将所有的物理页的地址都发送给同一个闪存通道的话,是难以利用这种并行的优势的。请求编排便是通过一个哈希函数将要到来的不同的物理地址请求进行一个重新的编排,使得每一个闪存通道都可以平均分配到物理页的请求,从而充分的利用 ssd 内部多个闪存通道的并行优势,来减少页面读取的开销。
实验结果
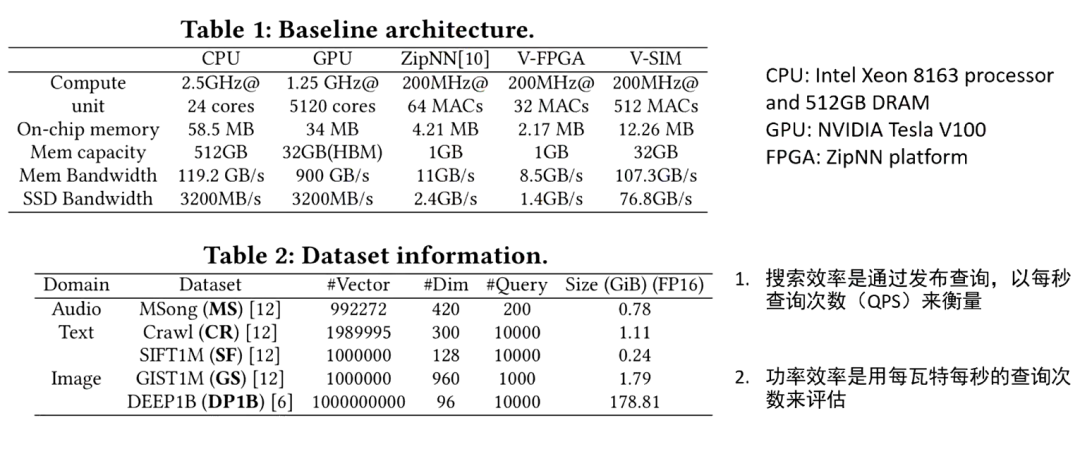
上图是这篇文章的一个实验设计。文章作者实现了一个基于 FPGA 的可计算存储的硬件原型,使用了 V-FPGA 和一个基于 SimpleSSD 模拟器的实现:V-SIM。使用的实验基准是与 CPU,GPU 还有基于 FPGA 的 ZipNN 做对比,选择了五个不同的真实向量的搜索数据集,用 QPS 来衡量搜索效率,即每秒的执行的查询次数;然后功率效率是利用每瓦特每秒的查询次数来评估。
性能比较
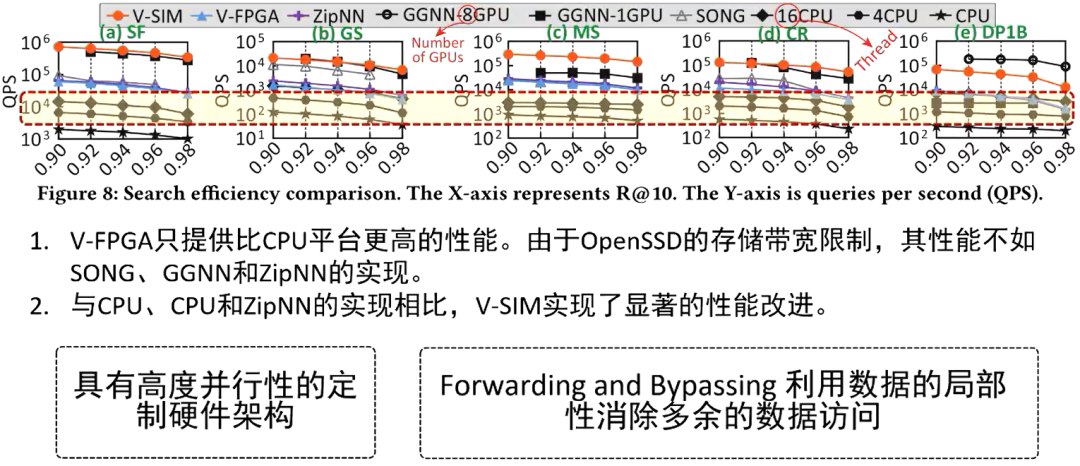
根据上图性能比较的结果可以发现,与cpu平台相比的话,V-FPGA 即可计算存储的硬件原型能提供更高的一个性能,与 GPU 的 SONG、GGNN 和 ZipNN 等方案有着相当的性能。
因为 V-FPGA 使用的是一个性能较弱的硬件原型,他们使用的模拟器加大了内部的存储带宽,所以随着 ssd 内部存储带宽的提高,目前与 CPU、GPU和 ZipNN 的实现相比,V-SIM 实现了显著的性能提升。
能耗效率比较
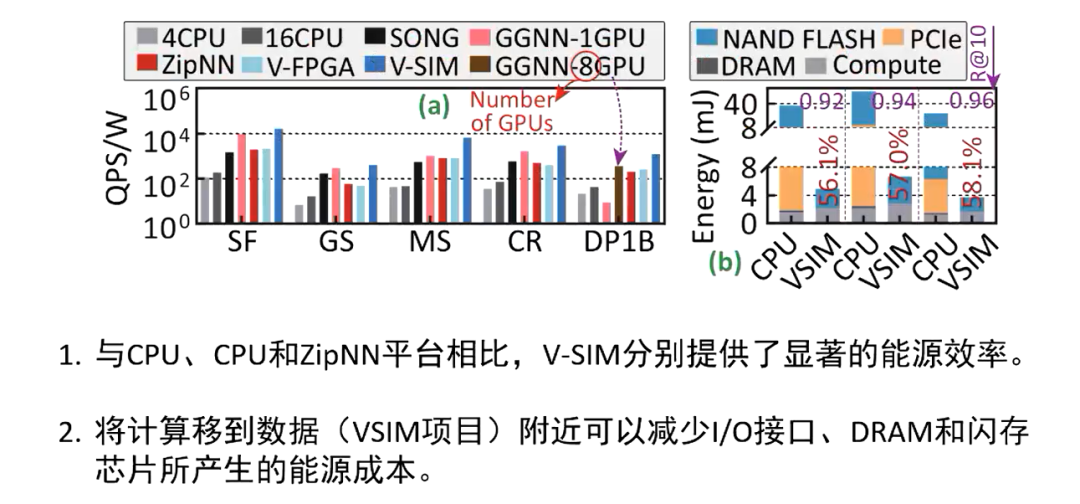
对于能耗效率方面,这篇文章也是分别与 CPU、GPU 和 FPGA 的平台进行了相比。可以看到上图中深蓝色的柱子是 V-SIM 的方案,与这些基准测试相比呢,都有着显著的性能提升,尤其是在处理 DEEP1B 这种超大的数据集时,性能提升的比较显著。这正是因为他们将计算移动到了数据附近,减少了 IO 接口还有主机的 DRAM 以及闪存的芯片产生的能源成本。
现有问题与未来展望
以上就是 Vstore 的大概内容。目前单一的图结构并不一定能在大规模的 ANN 场景中表现出很好的性能,基于树/聚类/分区与基于图的混合的索引的方法,更能胜任大规模的 ANN 场景的需求。
其次,现有的工作在对 ANN 进行卸载到可计算存储的方案中,都没有考虑可计算存储的设备的处理能力,如果将 ANN 所有的计算负载全部都给卸载到可计算存储设备中,可能会导致整体性能的一个下降。
针对这个问题,我们做了一个实验,把原来卸载到可计算存储中 ANN 的过程的一部分还给 CPU 去执行,存在凸曲线的性能变化,即保留一定的数据给 CPU 处理,整体的性能要优于全部卸载的方案。
这就给予了我们一个启发,也是目前正在做的一项工作。通过构建一个多探针的分区图的混合索引,卸载到可计算存储中实现一个访存优化和高效并行的软硬件协同的机制。通过这样一个机制来为大规模 ANN 提供更好的性能。以上就是分享的全部内容。
参考文献
[1] Shengwen L, Ying W, Ziming Y, Cheng L, Huawei L, Xiaowei L. VStore: in-storage graph based vector search accelerator. In: Proceedings of the 59th ACM/IEEE Design Automation Conference (DAC’ 22), San Francisco, California, USA, July 10-14, 2022, 2022: 997–1002.
[2] Kim J-H, Park Y-R, Do J, Ji S-Y, Kim J-Y. Accelerating Large-Scale Graph-Based Nearest Neighbor Search on a Computational Storage Platform. IEEE Transactions on Computers, 2022, 72(1): 278–290.
[3] Tobias V, Arthur B, Ilia P. nKV: near-data processing with KV-stores on native computational storage. In: Proceedings of International Workshop on Data Management on New Hardware (DaMoN’ 20), Portland, Oregon, USA, June 15, 2020, 2020:1-11.
[4]“SmartSSD,”2021.[Online].Available:https://www.xilinx.com/applications/data-center/computational-storage/smartssd.html.
[5] Xiaoyi Z, Feng Z, Shu L, Kun W, Wei X, Dengcai X. Optimizing Performance for Open-Channel SSDs in Cloud Storage System. In: Proceedings of the 35th IEEE International Parallel and Distributed Processing Symposium (IPDPS’ 21), Portland, OR, USA, May 17-21, 2021, 2021:902-911.
点击阅读原文查看往期活动
未来活动预告:
4月22日 张鹏程 上海交通大学博士
主题待定……
5月-6月
晏潇 南方科技大学研究助理教授
最大内积检索近期进展
向隆 南方科技大学博士
主题待定……
还有神秘嘉宾(业内大咖),猜猜会是谁呢?
To be continue……
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

