




|作者:Yingjun Wu RisingWave Labs CEO
如果你正在寻找一个流处理系统来构建新的流分析或流 ETL 应用,RisingWave 或许就是你想要的。RisingWave 是一个分布式 SQL 流数据库,尤其擅长流处理。
它适用于你的流处理应用吗?
这个问题所隐含的前提是 RisingWave 是否适合你的负载和业务需求。在本文中,我们将引导你了解 RisingWave 的各个方面,内容涵盖用户界面、性能、正确性、可扩展性和弹性、容错能力和可用性、持久性、服务能力、集成,以及部署。
RisingWave 是一个流数据库
RisingWave 是一个为流处理而设计的开源分布式 SQL 数据库。作为一个流数据库,RisingWave 以数据库的形式处理流数据。它使用 SQL 作为接口来摄取、管理、查询和存储持续生成的数据流。
RisingWave 旨在降低构建实时应用的复杂性和成本。它获取摄入流数据,当新数据到达时执行增量计算,并动态更新结果。
作为一个流数据库系统,RisingWave 在自有的存储中维护结果,以便用户可以高效地访问数据。你还可以将数据从 RisingWave 传送到外部流以进行存储或进一步处理。
RisingWave 的开源版本已在 GitHub[1] 上发布,采用真正的开源许可 — Apache License 2.0。它已经准备好投入生产使用,并已在数十家公司部署完成。RisingWave 的托管版本 RisingWave Cloud 目前正处于公开测试[2]阶段。
解耦的计算存储架构提供了更好的杠杆作用
RisingWave 是一个分布式系统。它利用计算/存储解耦的架构以较低成本实现无限的可扩展性。
目前,一个 RisingWave 集群中有四种类型的节点:
•前端(Frontend
):前端是一个无状态代理,通过 Postgres 协议接受用户查询。它负责解析、验证、优化以及提供每次查询的结果。•计算节点(ComputeNode
):计算节点负责执行优化后的查询计划。•压缩器(Compactor
):压缩器是一个无状态工作节点,负责为存储引擎执行压缩任务。•元服务器(MetaServer
):元服务器是中央元数据管理服务。它还是个故障检测器,定期向集群中的前端和计算节点发送心跳。
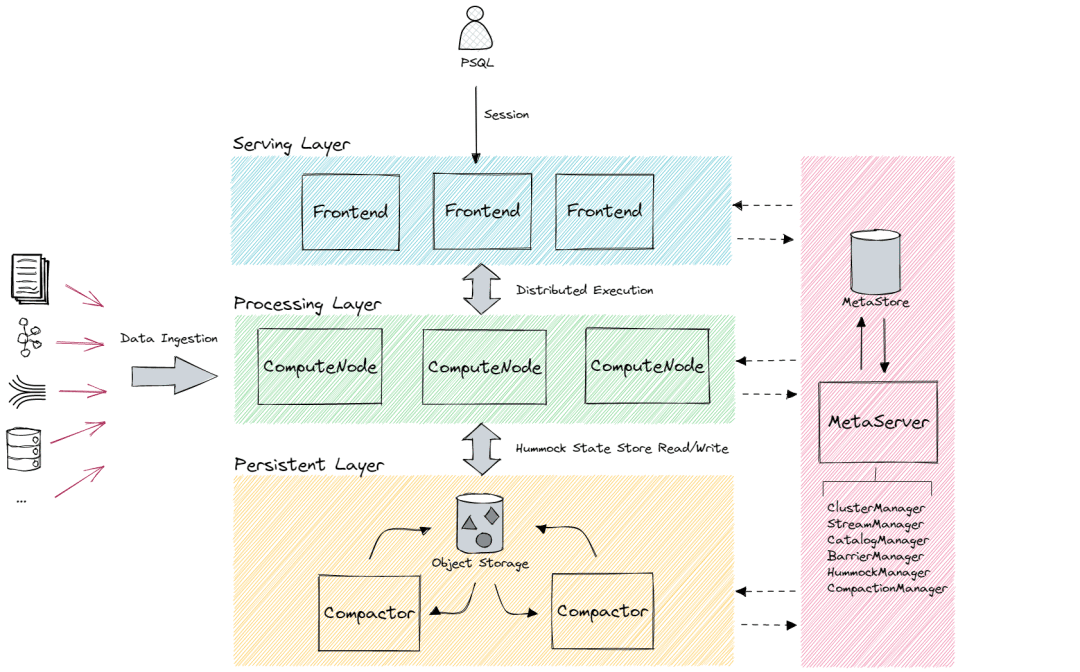
最顶层的组件是 Postgres 客户端。它通过 基于 TCP 的 Postgres wire 协议[3] 发出查询。图中最左侧的组件是流数据源。
Kafka[4] 是最具代表性的流数据源系统。此外,Redpanda[5]、Apache Pulsar[6]、AWS Kinesis[7]、Google Pub/Sub[8] 也被广泛使用。来自 Kafka 的流将通过数据库中的管道被读取和处理。最底层的组件是 AWS S3 或者 MinIO(一个开源、与 S3 兼容的系统)。
交互
RisingWave 是一个 SQL 流数据库。用户可以编写 Postgres 风格的 SQL 语句来摄取、处理和管理流数据。与大数据风格的流处理系统(如 Flink、Spark Streaming)不同,RisingWave 不提供原生的 Java、Scala 或 Python API。由于 RisingWave 与 PostgreSQL 兼容,用户可以直接使用第三方 PostgreSQL 驱动程序与其他编程语言(如 Java、Python、Node.js)进行交互。
为了扩展 RisingWave 的复杂查询的可表达性,我们推出了用户自定义函数(UDF)[9]框架,Python 是首个被支持的语言。RisingWave 会在专用进程中托管 UDF,并远程调用它们。我们还在探索将 UDF 部署到无服务器计算服务,如 AWS Lambda,以提供优秀的可伸缩性和更好的成本控制。
性能
RisingWave 对于高吞吐量流处理有着高度的优化。我们使用 Nexmark 基准测试的性能评估显示,RisingWave 在大多数查询中比 Apache Flink 实现了 10-50% 更高的吞吐量。详细的性能报告将在 2023 年第二季度发布。
RisingWave 不是一个内存式系统。它使用分层存储架构来管理计算状态和持久数据:新摄取的和经常访问的数据会保存在内存中,不经常访问的数据存储在 S3 或其他等效的远程存储中。
RisingWave 使用 Rust 编写,这是种为高性能编程设计的低级编程语言。与基于 JVM 的系统相比,RisingWave 不会产生运行管理或垃圾收集导致的性能代偿。
正确性
RisingWave 是一个流处理系统。它保证了数据的“一致性和完整性[10]”。具体来说:
RisingWave 同时是一个数据库系统。但(在0.1.16或更早版本中)不是 OLTP 数据库,无法用于处理数据库事务。RisingWave 保证所有读取都能得到数据库的一致性快照。
可扩展性和弹性
RisingWave 从设计之初就是一个分布式系统。所有数据都存储在底层对象存储中,而计算层可以在工作负载波动时快速扩缩容。扩容过程几乎可以在不中断数据处理的情况下立即完成。
在内部,RisingWave 使用一致性哈希算法将数据动态分区到每个计算节点。这些计算节点通过计算它们独特的部分数据并相互交换输出结果来协作。由于有了分区,RisingWave 可以在每个节点上实现缓存局部性,并获得与无共享系统相当的整体性能。
容错能力和可用性
像许多其他流处理系统一样,RisingWave 实现了 Chandy-Lamport 算法以获取一致性快照。一致性快照有助于 RisingWave 高效地从故障中恢复。
由于 RisingWave 专门的共享存储设计,恢复过程比其他类似的系统更快。系统可以在恢复后立即从上个检查点继续。唯一受影响的是缓存,会在恢复后逐渐重建。
目前,默认检查点频率为 10 秒。因此,恢复过程将使系统回到 10 秒前的状态并从那里继续,即恢复点目标(RPO)。另外,通过心跳超时检测故障可能需要大约 10 秒。它们共同构成了恢复时间目标(RTO)。
持久性
RisingWave 会对其存储的数据进行持久化。用户可以通过发出 DML 语句(如 INSERT
)或直接使用连接器向 RisingWave 插入数据。
我们建议在生产环境中使用来自消息代理或上游系统的直接 CDC 的连接器。接收到的数据将与检查点一起存储在 RisingWave 的存储中。要使用连接器,用户只需在创建表时添加一些额外的属性。为了实现数据持久性和精确一次传递,连接器偏移量将保留在检查点中。
在系统故障时,RisingWave 将从检查点偏移量开始继续摄取数据,确保没有数据丢失。然而,用户须确保消息代理中存储的数据得到持久化。
包括 INSERT/UPDATE/DELETE
在内的 DML 语句有助于手动修改数据。然而,如果系统在它们被持久化之前意外失败,就可能会丢失数据。FLUSH
命令能明确地让系统持久化数据。在未来的版本中,我们计划提供一个写入前日志(WAL),以确保数据零丢失。
查询能力
RisingWave 使用物化视图(materialized view)来存储流处理结果。它能为用户提供超低延迟的并发查询。我们使用标准基准的实验评估就是一个很好的例子。实验结果表明,RisingWave 可以在毫秒级别的延迟下对并发查询作出应答。我们将在今年晚些时候发布一个公共实验报告。
集成
点击查看我们的综合集成列表[11]。在此我们着重介绍其中几个。
Source
•消息代理:Apache Kafka、Redpanda、Apache Pulsar、AWS Kinesis、Google Pub/Sub
•数据库(CDC 直连):MySQL、PostgreSQL
•文件:S3
Sink
•消息代理:Apache Kafka、Redpanda
•数据库:MySQL、PostgreSQL、Redis、Cassandra、DynamoDB
•数据湖:Apache Hudi、Apache Iceberg
第三方工具
•实时仪表板:Grafana
•BI 工具:Superset、Metabase、DBeaver
部署
通过我们的官方云托管平台 RisingWave Cloud[12] 部署 RisingWave 是最简单的方法。我们现在支持 AWS 的大多数区域,GCP 的支持也即将推出。此外,我们提供开源的 Kubernetes operator[13],以便用户在本地 Kubernetes 集群上运行 RisingWave。对于存储,RisingWave 接受任何与 S3 兼容的存储服务,包括 MinIO 和 Ceph。
我们建议不要仅使用二进制文件部署 RisingWave,因为这可能需要额外的操作才能实现高可用性。
其他:OLTP 和 OLAP
RisingWave 不支持事务语义。因此,如果你正在寻找一个支持事务性负载的系统,那么比 RisingWave 更好的选择可能有:AWS Aurora[14] 或 Google Spanner[15]。RisingWave 没有实现列式存储,也没有针对交互式分析负载进行优化。但是,RisingWave 可以轻松地与主流 OLTP、OLAP 数据库进行集成。
结论
RisingWave 是一个现代化的分布式 SQL 数据库,专为流处理打造。它极大地节省了构建流分析或流 ETL 应用程序的工作量。
由于其解耦的计算存储架构,RisingWave 可以较其他流处理系统实现更高的成本效益。RisingWave 已经在许多创新公司中得到部署。访问官网[16]获取更多信息。
References
[1]
GitHub: https://github.com/risingwavelabs/risingwave[2]
公开测试: risingwave.cloud/auth/signup[3]
基于 TCP 的 Postgres wire 协议: https://www.postgresql.org/docs/current/protocol.html[4]
Kafka: https://kafka.apache.org/intro[5]
Redpanda: https://docs.redpanda.com/docs/get-started/quick-start/[6]
Apache Pulsar: https://pulsar.apache.org/docs/2.11.x/[7]
AWS Kinesis: https://aws.amazon.com/kinesis/getting-started/?nc=sn&loc=3[8]
Google Pub/Sub: https://cloud.google.com/pubsub/docs/overview[9]
用户自定义函数(UDF): https://www.risingwave.dev/docs/current/user-defined-functions/[10]
一致性和完整性: https://www.confluent.io/blog/rethinking-distributed-stream-processing-in-kafka/[11]
集成列表: https://www.risingwave.dev/docs/current/rw-integration-summary/[12]
RisingWave Cloud: https://www.risingwave.com/products/RisingWaveCloud/[13]
Kubernetes operator: https://www.risingwave.dev/docs/current/risingwave-kubernetes/[14]
AWS Aurora: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html[15]
Google Spanner: https://cloud.google.com/spanner[16]
官网: https://www.risingwave.com

