




|作者:Yingjun Wu RisingWave Labs CEO
十年前,我接触了一个大数据项目,叫做Stratosphere(http://stratosphere.eu/)。这个项目用一个页面就吸引了我:使用3行代码便可以在单机上启动一个集群并使用MapReduce方式计算WordCount程序。要知道,在Hadoop盛行的年代,从安装Hadoop到写WordCount程序跑起来都要花好几个小时。当看到一个项目能够用3行代码便能做到同样功能的时候,很显然会令人眼前一亮。也是因为这3行代码,让我深度探索了这个项目,并在之后成为了这个项目的贡献者。
如今,那个曾经叫做Stratosphere的项目已经改名成Apache Flink,并且成为了大数据时代最火的流计算引擎。而于之前那个Stratosphere不同的是,Flink已经成为了一个庞大的项目,其复杂程度令人生畏。而那个参与Flink最早一版流计算引擎设计开发的我,依然向往着极简的用户体验,期望用户能够开速上手,极速体验到简单高效的流计算。带着这一信念,我与小伙伴们一起打造了云时代的流数据库RisingWave,为用户提供如使用PostgreSQL一般的高性能流计算体验。
在本文,我就为大家演示,如何使用4行代码,使用RisingWave开启你的流计算之旅。
1什么是流计算
注:如果你对流计算已经有一定的认识,那么可以直接跳过这一段。
批计算与流计算是数据处理的两种最基本模式。在过去的20年中,批计算系统与流计算系统都经历了快速迭代,从单机时代到分布式时代,再从大数据时代到云时代,批计算系统与流计算系统均在架构上有了大幅改进。
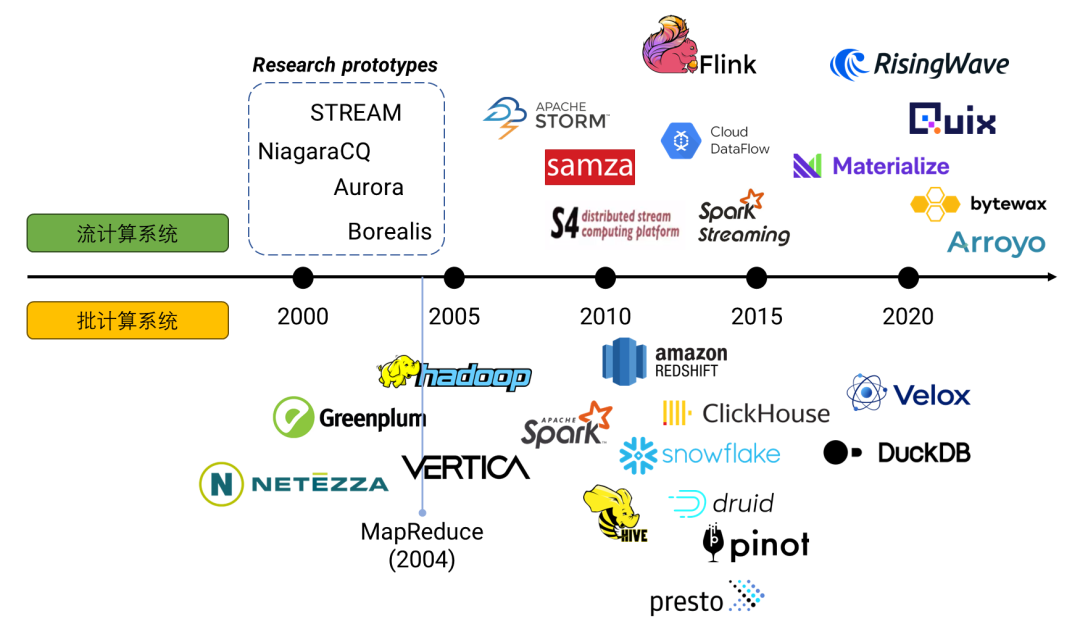
批计算与流计算最核心的两个区别在于:
批计算系统的计算由用户驱动,而流计算系统的计算由事件驱动; 批计算系统采用全量计算模型,而流计算系统采用增量计算模型。
不管是批计算还是流计算,它们都是往“实时”这一方向发展。如今,批系统被广泛的运用在交互式分析场景中,而流计算系统则被广泛的运用在监控、告警、自动化等场景。
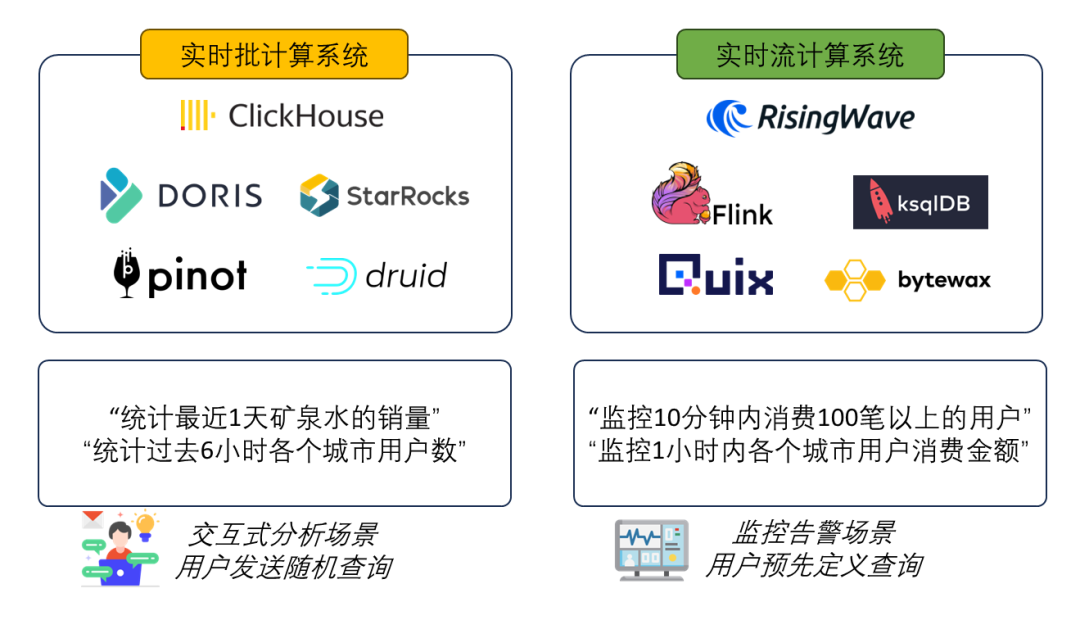
2RisingWave:用PostgreSQL的体验进行流计算
RisingWave是一款以Apache 2.0协议开源的SQL流数据库。它使用PostgreSQL兼容的接口,允许用户能像操作PostgreSQL数据库一样进行分布式流计算。
RisingWave最典型的场景有两个:一个是流式ETL,另一个是流式分析。
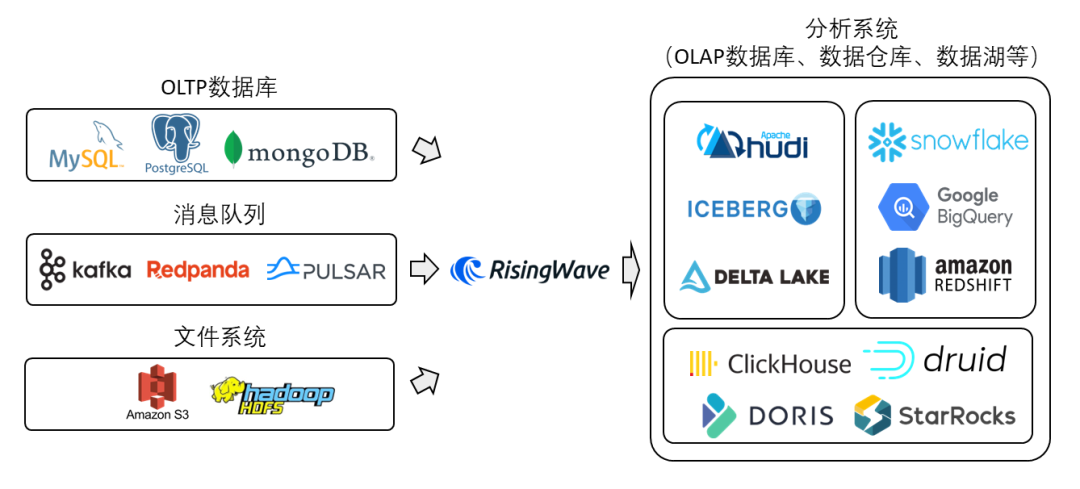
所谓流式ETL,便是将各类消息源(如OLTP数据库、消息队列、文件系统等)经过加工之后(比如进行join、aggregation、groupby、windowing等)实时导入到终端系统(如OLAP数据库、数据仓库、数据湖等分析类系统,或是导回OLTP数据库、消息队列、文件系统中)。在该场景中,RisingWave可完全替换Apache Flink。
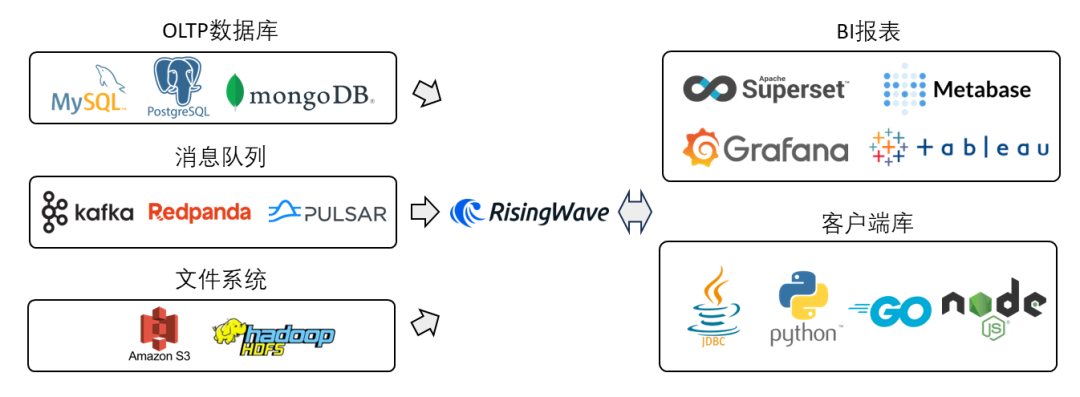
所谓流式分析,便是将各类消息源(如OLTP数据库、消息队列、文件系统等)经过加工之后(比如进行join、aggregation、groupby、windowing等)直接呈现在终端BI报表中,或是允许用户直接使用不同语言客户端库访问。在该场景中,RisingWave可替换Apache Flink与SQL/NoSQL数据库(如MySQL、PostgreSQL、Cassandra、Redis等)的组合。
34行代码部署RisingWave
首先在Linux或者Mac的命令行窗口里执行三行命令安装并运行RisingWave:
$ brew tap risingwavelabs/risingwave
$ brew install risingwave
$ risingwave playground
然后打开一个命令行窗口,执行以下命令连接到RisingWave:
$ psql -h localhost -p 4566 -d dev -U root
为了易于理解,我们先尝试创建一个表,并用INSERT来添加一些测试数据。在实际场景中,我们需要从消息队列里拿数据,那个部分留到后面再介绍。
我们来创建一个网页浏览记录的表:
CREATE TABLE website_visits (
timestamp TIMESTAMP,
user_id VARCHAR,
page_id VARCHAR,
action VARCHAR
);
接下来我们创建一个物化视图来统计每个页面的访问量,访问者数量,以及最后访问时间。这里要插一句,基于流数据的物化视图是RisingWave的一个核心功能。
CREATE MATERIALIZED VIEW page_visits_mv AS
SELECT page_id,
COUNT(*) AS total_visits,
COUNT(DISTINCT user_id) AS unique_visitors,
MAX(timestamp) AS last_visit_time
FROM website_visits
GROUP BY page_id;
我们用INSERT来加入一些数据。
INSERT INTO website_visits (timestamp, user_id, page_id, action) VALUES
('2023-06-13T10:00:00Z', 'user1', 'page1', 'view'),
('2023-06-13T10:01:00Z', 'user2', 'page2', 'view'),
('2023-06-13T10:02:00Z', 'user3', 'page3', 'view'),
('2023-06-13T10:03:00Z', 'user4', 'page1', 'view'),
('2023-06-13T10:04:00Z', 'user5', 'page2', 'view');
看一下目前的结果:
SELECT * from page_visits_mv;
-----Results
page_id | total_visits | unique_visitors | last_visit_time
---------+--------------+-----------------+---------------------
page2 | 2 | 2 | 2023-06-13 10:04:00
page3 | 1 | 1 | 2023-06-13 10:02:00
page1 | 2 | 2 | 2023-06-13 10:03:00
(3 rows)
让我们再插入5组数据:
INSERT INTO website_visits (timestamp, user_id, page_id, action) VALUES
('2023-06-13T10:05:00Z', 'user1', 'page1', 'click'),
('2023-06-13T10:06:00Z', 'user2', 'page2', 'scroll'),
('2023-06-13T10:07:00Z', 'user3', 'page1', 'view'),
('2023-06-13T10:08:00Z', 'user4', 'page2', 'view'),
('2023-06-13T10:09:00Z', 'user5', 'page3', 'view');
分两次插入数据是想模拟数据不停进入的过程。让我们再来看一下现在的结果:
SELECT * FROM page_visits_mv;
-----Results
page_id | total_visits | unique_visitors | last_visit_time
---------+--------------+-----------------+---------------------
page1 | 4 | 3 | 2023-06-13 10:07:00
page2 | 4 | 3 | 2023-06-13 10:08:00
page3 | 2 | 2 | 2023-06-13 10:09:00
(3 rows)
我们看到结果已经更新。如果我们处理的是真正的流数据,那么这个结果是会自动保持最新的。
4实现与Kafka交互
鉴于流数据处理中消息队列较为常用,我们可以来看一下如何实时获取并处理Kafka中的数据。
如果你还没安装Kafka,那么先到官网下载合适的压缩包(这里以3.4.0为例),然后解压:
$ tar -xzf kafka_2.13-3.4.0.tgz
$ cd kafka_2.13-3.4.0
下面我们来启动Kafka。
生成一个集群UUID:
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
格式化日志目录:
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
启动Kafka服务器:
$ bin/kafka-server-start.sh config/kraft/server.properties
启动Kafka服务器之后,我们可以创建一个话题(topic)。
$ bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092
创建成功后,我们就可以从命令行直接输入消息。
先运行以下命令启动生产者程序:
$ bin/kafka-console-producer.sh --topic test --bootstrap-server localhost:9092
待出现>
符号时,我们可以输入消息了。为了方便在RisingWave消费数据,我们按照JSON格式输入数据。
{"timestamp": "2023-06-13T10:05:00Z", "user_id": "user1", "page_id": "page1", "action": "click"}
{"timestamp": "2023-06-13T10:06:00Z", "user_id": "user2", "page_id": "page2", "action": "scroll"}
{"timestamp": "2023-06-13T10:07:00Z", "user_id": "user3", "page_id": "page1", "action": "view"}
{"timestamp": "2023-06-13T10:08:00Z", "user_id": "user4", "page_id": "page2", "action": "view"}
{"timestamp": "2023-06-13T10:09:00Z", "user_id": "user5", "page_id": "page3", "action": "view"}
我们可以启动一个消费者程序来查看我们输入的消息。
$ bin/kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092
下面我们看一下在RisingWave怎么来获取这个消息队列的数据。在这个场景中,RisingWave扮演的是消息的消费者角色。我们现在回到RisingWave窗口(即psql窗口),创建一个数据源(source),这样就能与刚才创建的主题(topic)建立连接。需要注意的是,这里只是建立连接,还没真正的开始消费数据。
在创建数据源时,对于JSON类型的数据,我们可以直接定义schema来映射流数据中的相关字段。为了避免与上面的表重名,我们将数据源命名为website_visits_stream
。
CREATE source IF NOT EXISTS website_visits_stream (
timestamp TIMESTAMP,
user_id VARCHAR,
page_id VARCHAR,
action VARCHAR
)
WITH (
connector='kafka',
topic='test',
properties.bootstrap.server='localhost:9092',
scan.startup.mode='earliest'
)
ROW FORMAT JSON;
我们需要创建一个物化视图(materialized view)来让RisingWave开始摄取数据并进行计算。为了便于理解,我们创建了与上面的例子中类似的物化视图。
CREATE MATERIALIZED VIEW visits_stream_mv AS
SELECT page_id,
COUNT(*) AS total_visits,
COUNT(DISTINCT user_id) AS unique_visitors,
MAX(timestamp) AS last_visit_time
FROM test
GROUP BY page_id;
我们现在可以看一下结果:
SELECT * FROM visits_stream_mv;
-----Results
page_id | total_visits | unique_visitors | last_visit_time
---------+--------------+-----------------+---------------------
page1 | 1 | 1 | 2023-06-13 10:07:00
page2 | 3 | 2 | 2023-06-13 10:08:00
page3 | 1 | 1 | 2023-06-13 10:09:00
(3 rows)
至此我们已经从Kafka里获取数据并对数据进行了处理。
5进阶:用RisingWave搭一个实时监控系统
在流处理的应用中,实时监控是一个较为常见的需求。你可以在对数据进行实时处理后进行实时的可视化展示。RisingWave可以作为数据源,直接接入可视化工具(例如Superset, Grafana等)并将处理后的指标数据进行实时展示。鼓励各位可以尝试一下自己搭建一个流处理+可视化展示的系统。具体的步骤可以参考我们的使用场景文档(https://www.risingwave.dev/docs/current/use-risingwave-to-monitor-risingwave-metrics/)。在该文档中,我们使用RisingWave来监控和处理系统运行指标,并实时在Grafana中展示。我们的演示较为简单,相信各位基于真实数据,在自己熟悉的业务场景中,能够实现丰富得多的展示效果。
6总结
RisingWave的最大特点就是简洁:用户可以几乎无门槛的使用SQL进行分布式流计算。在性能方面,RisingWave也远胜于Apache Flink等大数据时代的流计算平台。那么性能到底有多少提升?剧透一下:无状态(stateless)计算的性能提升在10% -30%左右,有状态(stateful)计算的性能提升在10倍或以上!敬请期待即将发布的性能报告。高效流计算平台,就应该从简单开始。

