




作者:迟策
声明:本文主要介绍 RisingWave 0.1.10 版本中的设计。RisingWave 的开发进展迅速,本文中的技术细节随时可能失去时效性。
在数据库系统中,我们可以通过创建索引(Index)来加快连接(Join)计算的速度。例如,Postgres 支持索引扫描(Index Scans),通过扫描索引而不是原始数据来加快 Join 的速度。然而,"索引"在流处理系统中很难实现,原因有二:
流处理系统的中间状态通常来说都是 "一读一写(one-read-one-write)"。流处理系统处理的是无边界的数据(unbounded data),这就需要通过状态存储来持久化计算的中间状态,在系统故障时从 checkpoint 恢复。而这些中间状态,通常只有单个并行度的单个算子读写,不会被共享。
索引并不是在数据流图上流动的流数据,而是被算子查询的对象。一般来说,流数据在数据流中流动,算子永远能获得数据流里上游算子推送过来的数据。流算子只根据流上的数据和自己本地的中间状态进行运算。而索引是需要主动查询的,而非在图上流动。算子需要主动获取索引以得到最终的结果。
Differential Dataflow(DD)实现了一种数据流系统上的索引 Arrangement。Arrangement 可以理解为一个 MVCC 的索引,它记录了 (索引键, 时间) → 值 的映射。为流数据建立的 Arrangement 本质上是一种索引,下游算子可以高效地通过索引键(Index Key)来查询某个时间点对应的所有 value。
在 Arrangement 之上,DD 在其流处理系统中引入了 Delta Join,这是一种特殊的 Join 算子。只要所有需要 Join 的流在 Join Key 上有索引,Delta Join 就可以完全利用索引产生最终的 Join 结果,无需任何中间状态。也就是说,如果两个 Join 覆盖了同一个流,而这个流是有索引的,那么两个 Join 的 Delta Join 算子可以直接访问这个流上的相同的 Arrangement,从而节省了存储和维护成本。相比之下,一个普通的 Join 算子需要分别持久化左右两个数据流的记录。此外,如果是多路 Join,还需要持久化每一次二路 Join 的结果。
通过 Arrangement 和 Delta Join,我们可以在流系统中共享状态,并节省重复状态带来的成本。这听上去很棒,但这种方法不直接适用于 RisingWave,原因有二:
Arrangement Join 是作为内存中 MVCC 实现的,其中每条记录都有时间戳,而且没有考虑索引的持久性。然而,在 RisingWave 中,流是没有时间戳的。
DD 中的 Delta Join 只能在单个实例中工作,而 RisingWave 从设计之初就是一个分布式系统。
在 RisingWave 中,我们通过修改 Delta Join 的实现来支持状态共享。其核心思想是探索底层云原生状态存储的基于历时(epoch-based)的 MVCC 能力。本文将先介绍 RisingWave 在云原生存储上的数据持久化流程;然后介绍共享状态的实现;最后,将详细介绍 RisingWave 中 Delta Join 的实现。
RisingWave 中的 Checkpointing
RisingWave 的状态存储引擎 Hummock 的数据主要存在于两个地方:每个计算节点的共享缓冲区(Shared Buffer)和对象存储服务(比如 MinIO、S3 等)。Shared Buffer 以 checkpoint 的 epoch 来组织数据;对象存储服务使用 LSM 树来组织数据。Hummock 中存储的是某一个时间点的快照。算子在某个 epoch 内计算的中间状态保存在算子内部的 Flush Buffer 中。
我们以一个简单的 query 为例:
CREATE MATERIALIZED VIEW mv_1 AS SELECT * FROM t1, t2 WHERE t1.v1 = t2.v2;
这个 query 在流处理引擎中产生了两个 TableScan 算子—— Join 算子和 Materialize 算子。TableScan 算子将内部表(或外部数据源)的变化实时注入下游算子;Join 算子用于计算满足 t1.v1 = t2.v2 这个 Join 条件的两个流的匹配项;Materialize 算子将最终结果物化到存储中,用户可以 query。假设两个表 t1 和 t2 分别只有一列 v1 和 v2。此时,用户在 t1 中插入了两行数据 1,2。
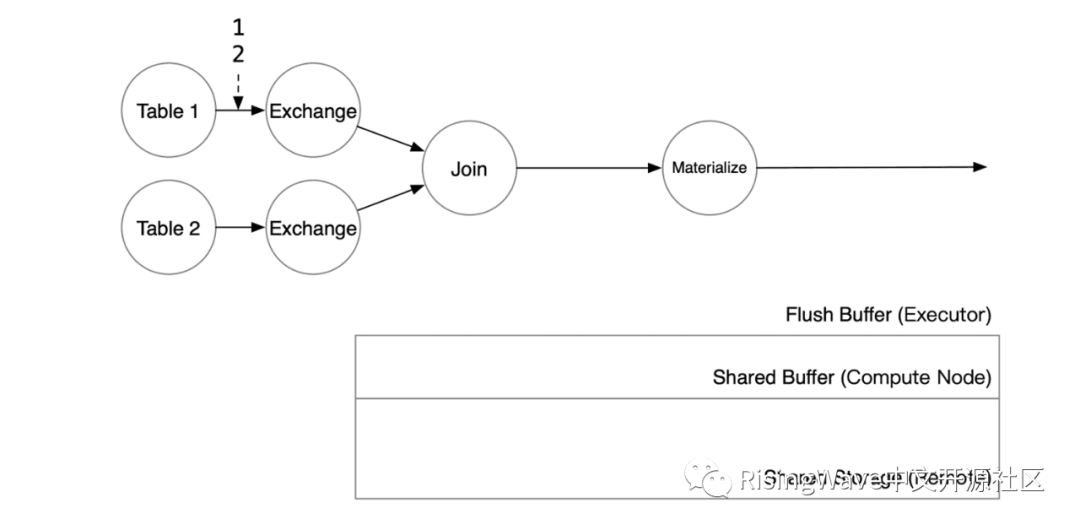
两行数据到达 Join 算子后,算子将查询缓存,判断这两行在 t2 中是否有匹配。如果缓存没有命中,那么算子将转而搜索状态存储。状态存储将扫描 Shared Buffer 以及共享存储(Shared Storage)上的数据,并合并 Flush Buffer 后得到 t2 对应的两行。
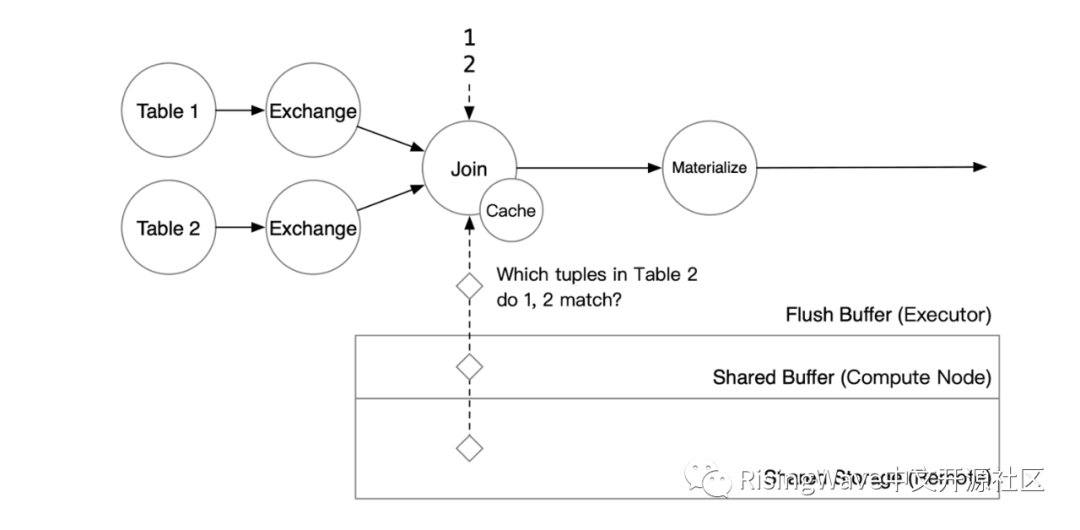
匹配到数据后,t1 新增的两行会被写到算子的 Flush Buffer 中。同时,匹配的数据会通过数据流传到下游算子。
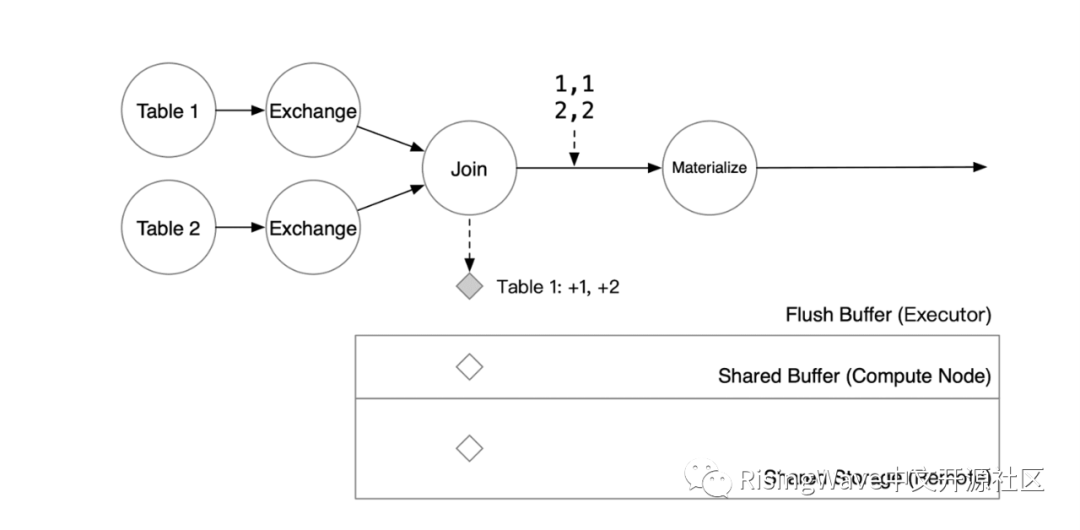
然后,下游的 Materialize 算子会将这新增的两行保存到自己的 Flush Buffer 中。
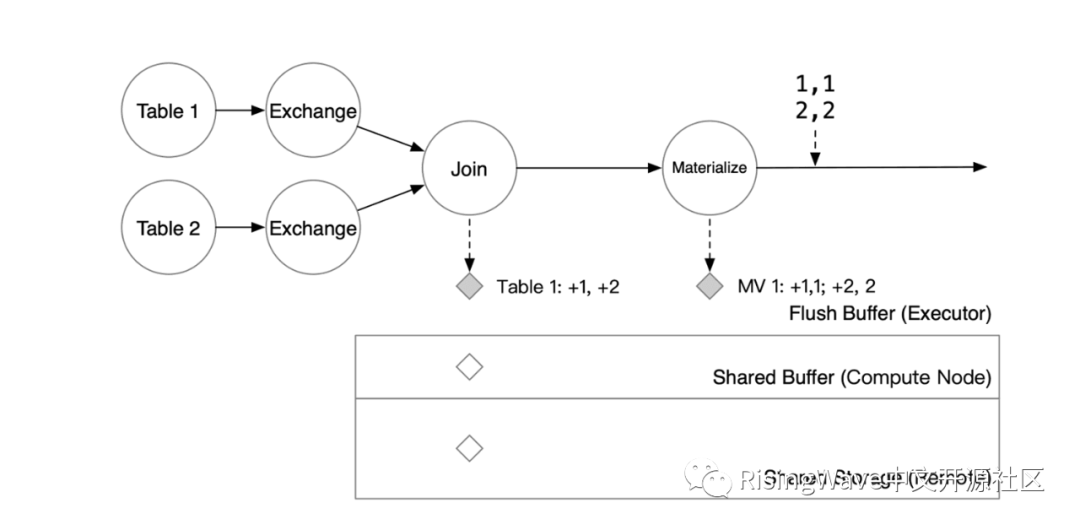
此时,系统会决定启动一次 checkpointing。RisingWave 的元信息服务会在 checkpointing 开始时,将 barrier 注入到所有数据源中。在这个例子中,有两个源,Table 1和Table 2。当系统注入一个 epoch = 5 的 barrier 时,epoch = 4 的数据将被算子写入状态存储中,而收到 barrier 的算子接下来将处理 epoch = 5 的数据。
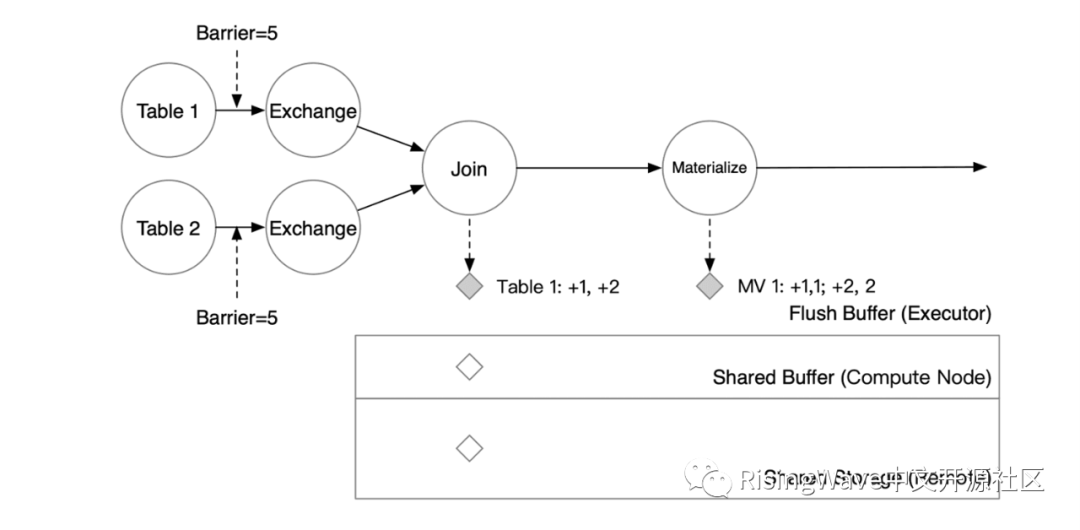
Join 算子对其两个上游的 barrier。收到 barrier 后,算子将 Flush Buffer 里的数据以 KV 对的形式写入到状态存储的 Shared Buffer 中,算子就可以开始处理下一批数据了。
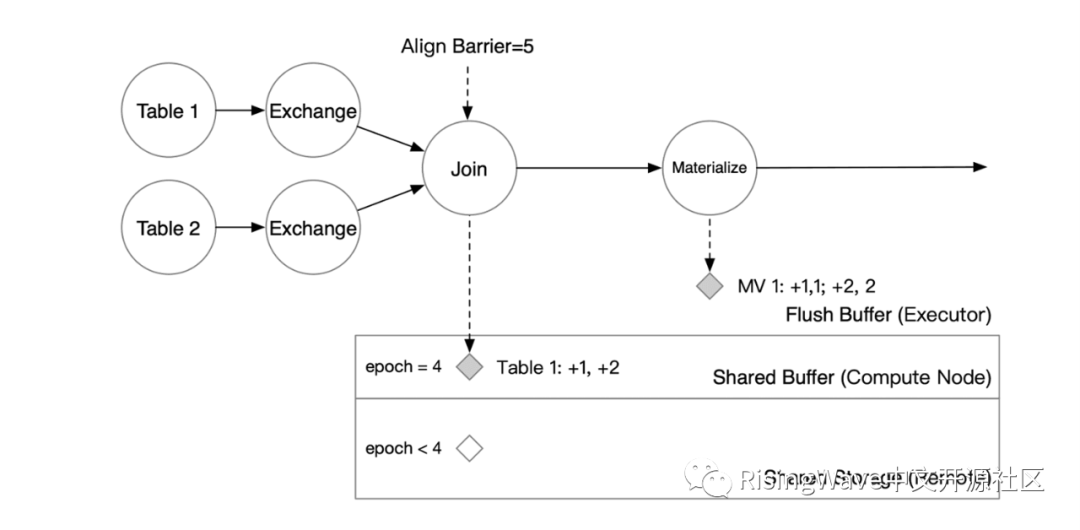
Barrier 流过 Materialize 算子后,物化结果也会被写入 Shared Buffer 中。
当 barrier 流过整个图后,每个计算节点会将 Shared Buffer 中的数据在后台编码成 SST 并上传到 Shared Storage 层。当所有节点都上传后,checkpointing 就宣告完成。此时,Shared Buffer 将清除已 checkpointing 的数据,Shared Storage 上的数据也将对用户的批查询可见。
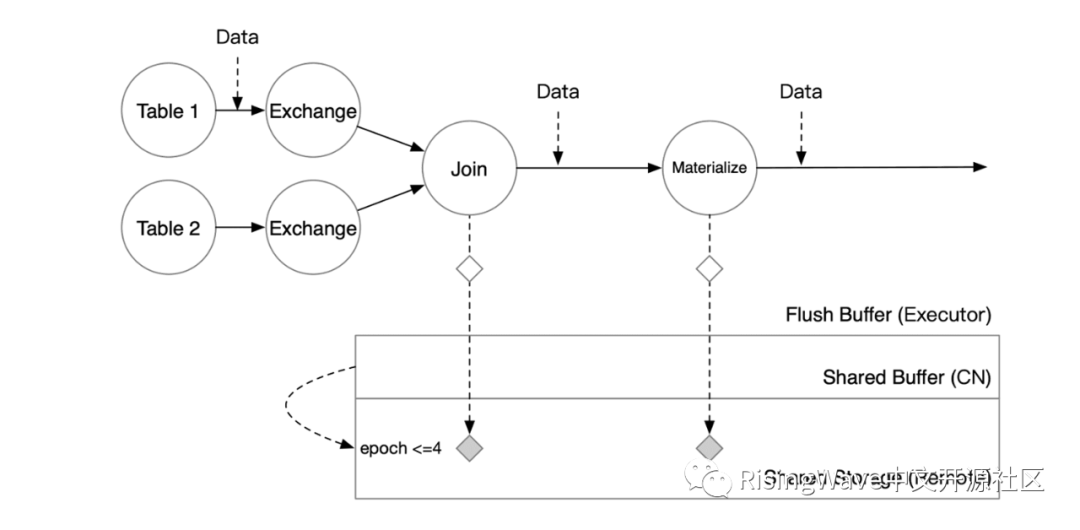
在这个时候,当用户执行查询时,例如 SELECT * FROM mv_1,就可以看到最新的数据。
因此,对于算子来说,checkpointing 就是简单地将数据编码并写到 Shared Buffer 中,不需要等待任何 I/O 操作。计算节点在后台会将写入 Shared Buffer 的数据上传到 Shared Storage 上,异步地完成 checkpointing 过程,在此期间完全不会影响流算子的正常计算。
共享状态和索引
索引
CREATE TABLE table(v1 int, v2 int, v3 int);CREATE INDEX idx on table(v1, v2);
这里 CREATE INDEX 等同于:
CREATE MATERIALIZED VIEW idx as SELECT * FROM table ORDER BY v1, v2;
在 RisingWave 中,索引就是按照用户指定的索引 key 排序的一个特殊物化视图,而物化视图本质上就是按一定规则排序的 KV 对。如果一个算子想查询所有满足条件 v1 = 1, v2 = 2 的记录,它只需要在索引视图中按顺序扫描以 [1, 2] 开头的所有记录即可。索引物化视图是使用 Arrange 算子构建的。
接下来,我们讨论如何实现共享索引——允让多个下游算子同时访问这个索引(共享状态)。在 RisingWave 里,大部分状态都是“一写一读(one-read-one-write)”的。例如,Join 就只会读写当前算子负责的的 join key。数据放在 Shared Storage 上,只是方便了调整并行度 (scale-in, scale-out)。要实现“一写多读(one-write-multiple-read)”的状态,需要考虑以下几点:
怎么保证算子能读到一致的状态?如果某个中间状态处于正在被写入的过程中,那么对于这个状态的访问一致性有问题,需要做一些特殊处理。
读取共享状态如何减少对于流算子的影响?如果每次读取共享状态都需要访问远程存储,或是通过 RPC 向上游计算节点查询,会极大地影响流计算的性能。
单节点共享状态
我们先讨论一下单节点上共享状态的情况。首先我们假设有一个叫做 Read 的算子需要读取共享状态。Read 算子恰好与 Arrange 算子在同一个计算节点上。
此时,Arrange 算子收到了 barrier。
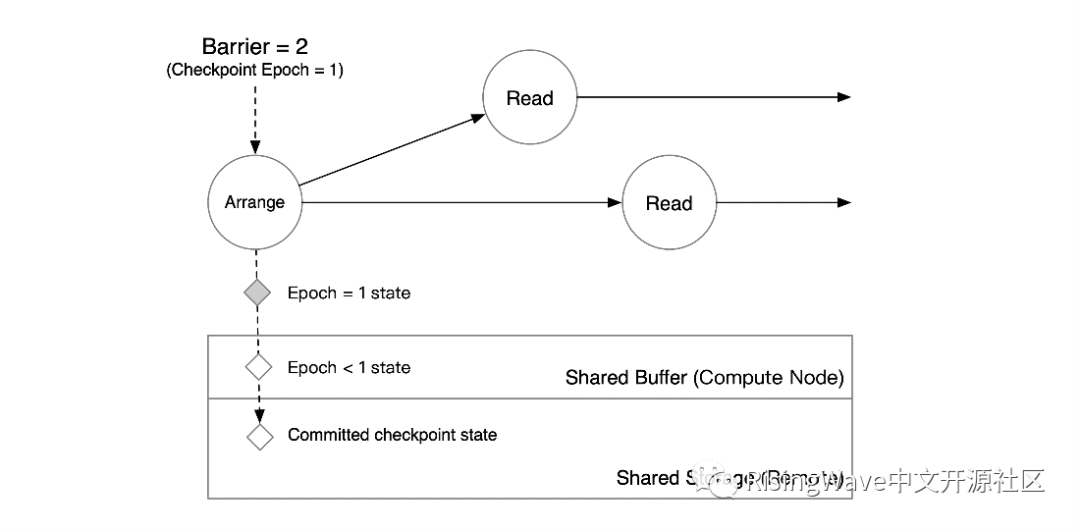
Arrange 算子把 epoch = 1 的数据写入 Shared Buffer,并把 barrier 发送到下游算子。
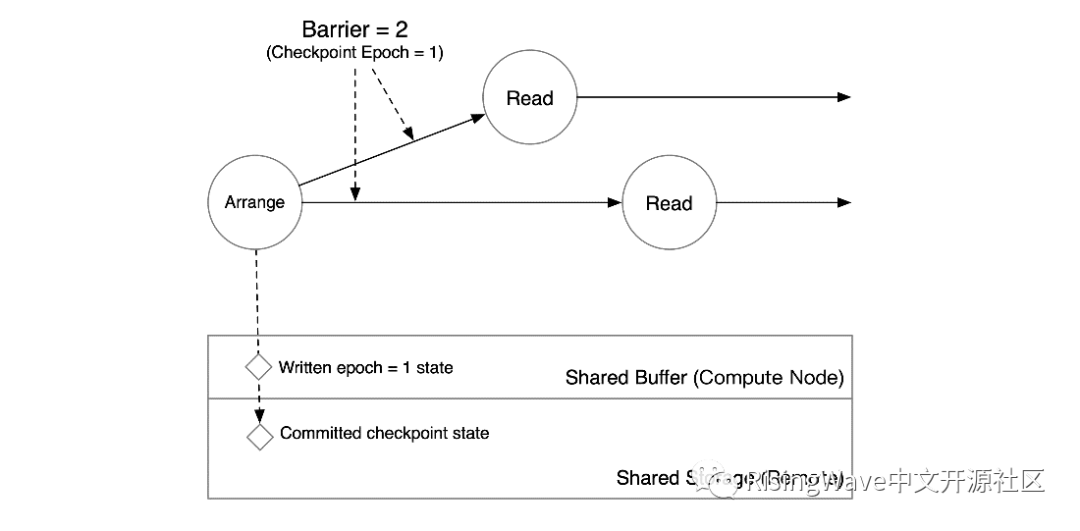
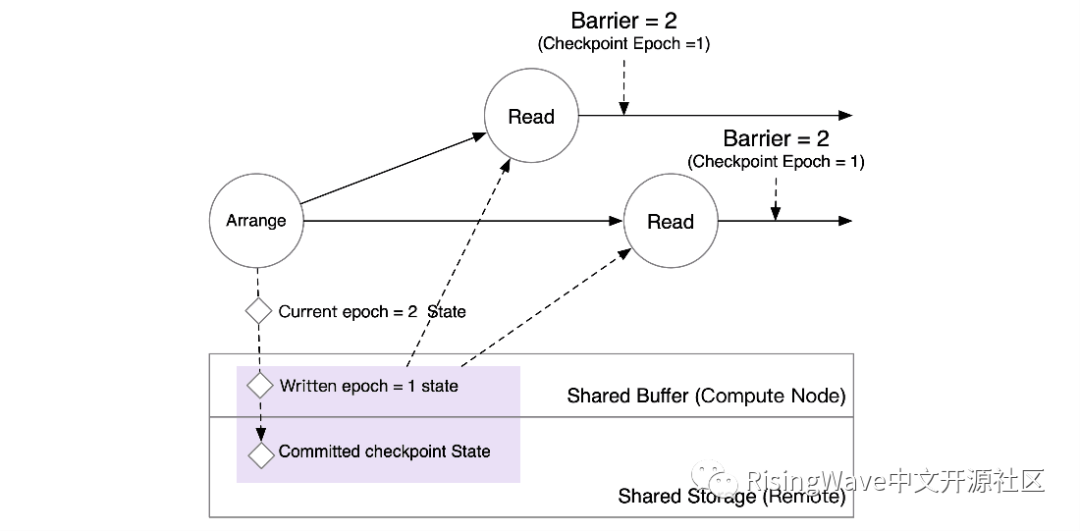
当 Read 算子收到 barrier 时,就意味着上游算子已经将其状态写入 Shared Buffer 中。因此,单节点场景下,下游算子可以直接读取 Arrange 算子写入 Shared Buffer 的 epoch = 1 的数据。存储在收到读 epoch = 1 的请求后,将合并 Shared Storage 上 epoch < 1 的数据和 Shared Buffer 中 epoch = 1 的数据,得到 epoch = 1 Arrange 算子在状态存储中完整的状态快照。
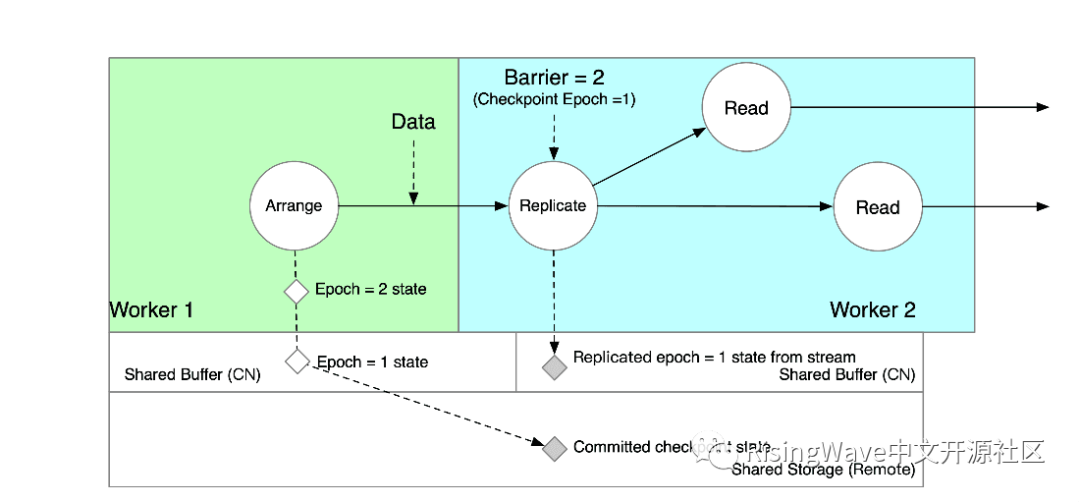
跨节点共享状态
Arrange 和 Read 算子被分配在两个节点上,即 Worker 1 和 Worker 2。在下游节点 Worker 2 中,我们为 Arrange 算子创建一个“影子算子(shadow operator)” Replicate。在 Replicate 算子收到上游 Arrange 发送的数据后,就将数据复制一份写入Worker 2 的 Shared Buffer。
Read 算子收到 barrier,就表明其本地计算的数据可以在其所在的节点上可以读到了。如下图所示,由 Read 算子读取的数据实际上是 Worker 2 的 Shared Buffer 中复制的数据,以及 Shared Storage 上的数据的组合。此时,由 Arrange 算子写入的数据同时存在于 Worker 1 和 Worker 2 的 Shared Buffer。
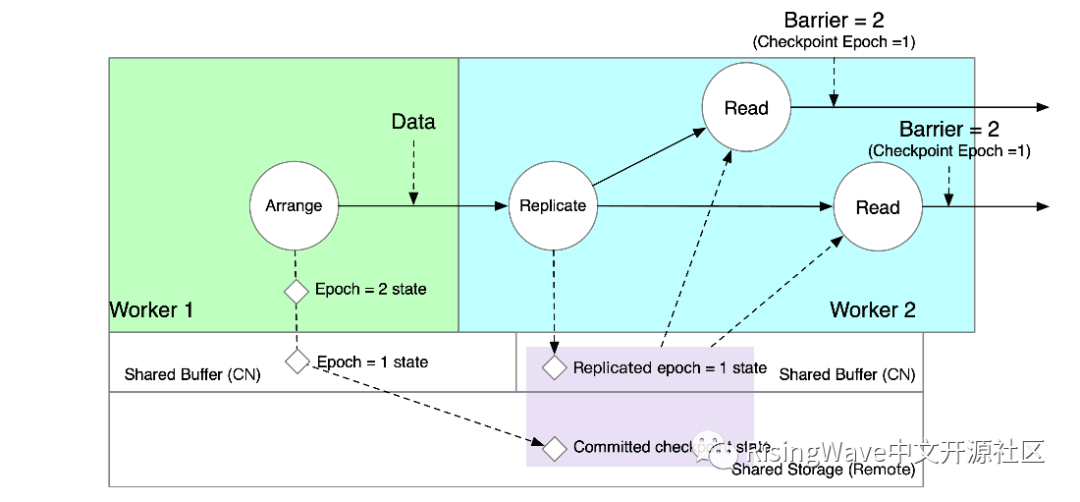
在 checkpointing 过程中,只有 Worker 1,即 Arrange 所在的节点,会将其本地 Shared Buffer 中的状态上传到 Shared Storage。下游的 Worker 2 会直接销毁内存中 Replicate 复制的“影子数据”。此时,如果 Read 算子发起读 epoch = 1 的请求,就可以全部从 Shared Storage 上读到了。
Delta Join
数学原理
对于流处理系统,给定查询 A⋈B(假设是自然连接(Natural Join),即等值连接(Equal Join)),流引擎实际上需要在每个 epoch 中计算 Δ(A⋈B)。根据关系代数的等价规则,我们有:
Δ(A⋈B)=[ΔA⋈(B∪ΔB)]∪(ΔB∪A)
该规则还可推广到多路连接(multi-way joins)。例如,三路 Join 查询的 △(A⋈B⋈C) 可以扩展为:
Δ(A⋈B⋈C)=[ΔA⋈(B∪ΔB)⋈(C∪ΔC)] ∪[ΔB⋈A⋈(C∪ΔC)] ∪[ΔC⋈A⋈B]
容易发现,n 路 Join 的增量,永远都可以展开成 n 项式,每一项都是 n 项的积。其中:
第一项是 ΔT。
每张表只出现一次。
除了第一项外,每张表都以 T 或 T+ΔT 的形式出现。
在 RisingWave 中,我们可以用数据流图来表示流引擎中的这种 Delta Join 运算。T+ΔT 可以从当前 epoch 的索引中读取,而 T 可以从上一个 epoch 的索引中读取。例如,对于一个三路 Join,使用上述公式,我们可以构建以下数据流图。
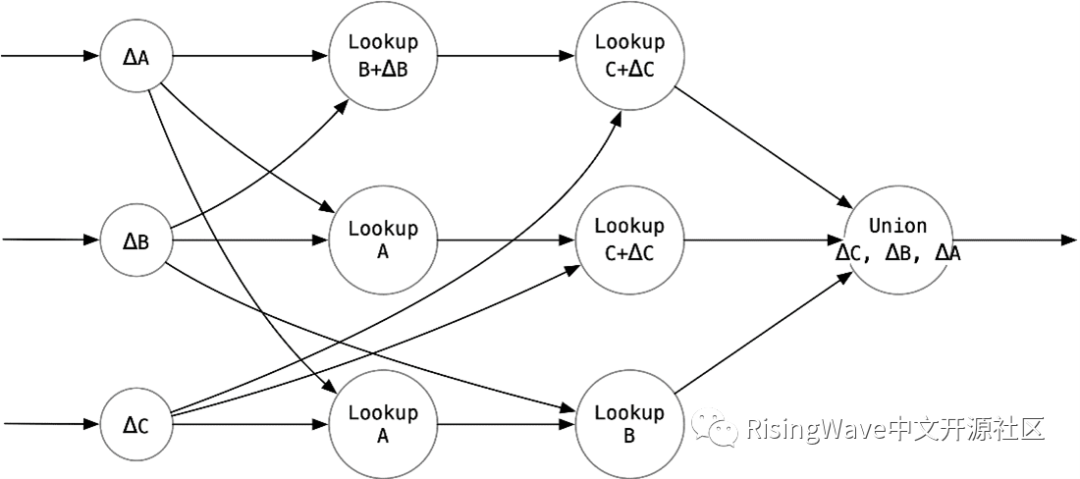
每一行恰好对应式算子中的一项。
我们实现了一个特殊的 Union 算子,它依次合并了来自三个上游 Lookup 执行器的 delta 流。首先输出 ΔC 一路的数据,然后是 ΔB,最后是 ΔA。否则会导致有因果关系的两条记录顺序颠倒,产生错误的结果。
Lookup 算子的实现
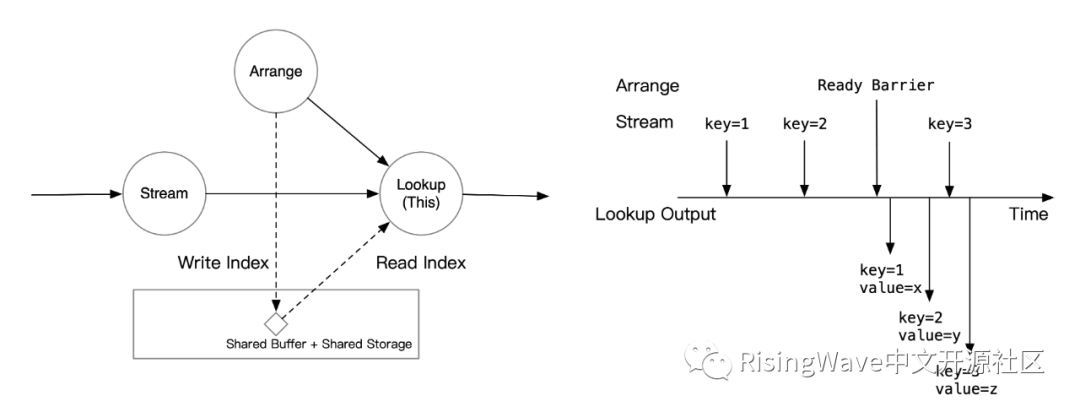
如果 Lookup 算子访问当前 epoch 的索引,Lookup 算子会等到 Arrange 一侧的 barrier 到来后再开始计算。如下图所示,在收到 ready barrier 之前,Lookup 会将流上的数据缓存下来;在收到 barrier 后,就会立刻开始处理积压的数据,在索引中匹配流上 join key 对应的数据。
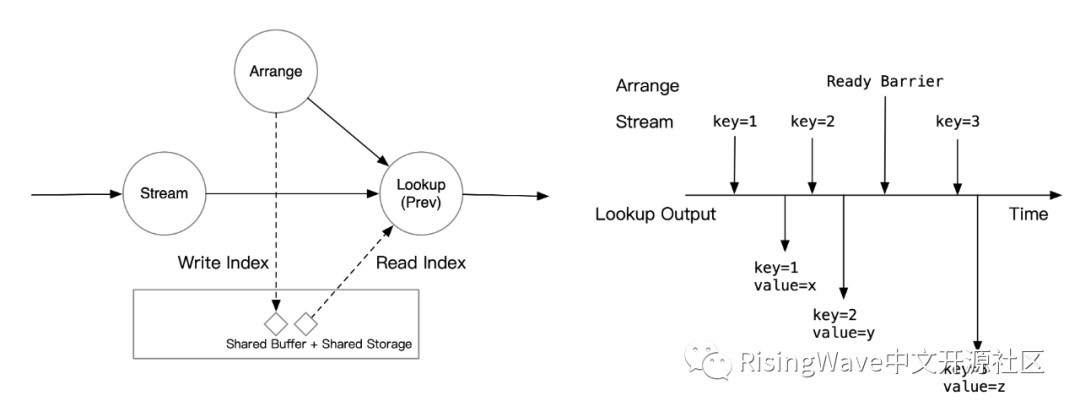
如果 Lookup 算子访问上一个 epoch 的索引,因为Lookup 算子会对齐 barrier,处理当前 epoch 数据时,一定已经收过上一个 epoch 的 barrier。因此,上一个 epoch 的索引必然已经可以访问了。在这个模式下, Lookup 收到一个消息,就会直接与索引的一条消息相匹配。
Delta Join 在优化器中的表示
总结
RisingWave 是 RisingWave Labs 开源的基于 SQL 的云原生流数据库,使用 Rust 实现。欢迎加入我们的 Slack 社区,在 Twitter 和 Linkedin 上关注我们,并订阅我们的 Youtube 频道。更多 RisingWave 资讯,等你探索。
RisingWave是一个云原生SQL流式数据库。其旨在降低构建实时应用的门槛以及成本。
✨ GitHub: risingwave.com/github
💻 官网: risingwave.com
👨💻 Slack: risingwave.com/slack

