




实战系列
本期是 Faiss 系列的第二期,主要介绍了 Faiss 常用的索引方法以及各自的优缺点,还不了解 Faiss 的小伙伴可以点击下方图片看一看上期的内容。


Faiss核心原理
在了解 Faiss 的索引之前,要知道Faiss的核心原理。主要是两部分:倒排索引 IVF 和乘积量化 PQ,这两个方法是 Faiss 实现高速,少内存以及精确索引的主要手段。
倒排索引 IVF
IVF(Inverted File System):首先在具有代表性的数据上训练聚类中心,然后将 base 加入到最近的聚类中心的桶里,在 search 的时候,query 先和聚类中心比对,再在一定数目的桶里做暴力搜索。
解释:IVF 其实很好理解,假如我们想要在全国范围内找到一个给定年龄,性别,身高体重等信息的人,那么其中的一个办法是,拿这些信息和全国的人都一一对比,然后找到和这个条件最相近的一类人。但是如果我们先把全国的人按照省份进行划分,先看这个人是哪个省份的,接着从这个省份里去全量搜,那么计算量降了一个数量级,如果是按城市划分,则计算量可以降低好几个量级,这就是 IVF 的基本原理。
暴力搜索(query 和 base 一一比对,选择最近的)的方式是在全空间进行搜索,为了加快查找速度,几乎所有的ANN方法都是通过对全空间进行分割(聚类),将其分割成很多小的子空间,在搜索时,通过某种方式快速锁定在某一(几)个子空间,然后在这几个子空间中进行遍历。
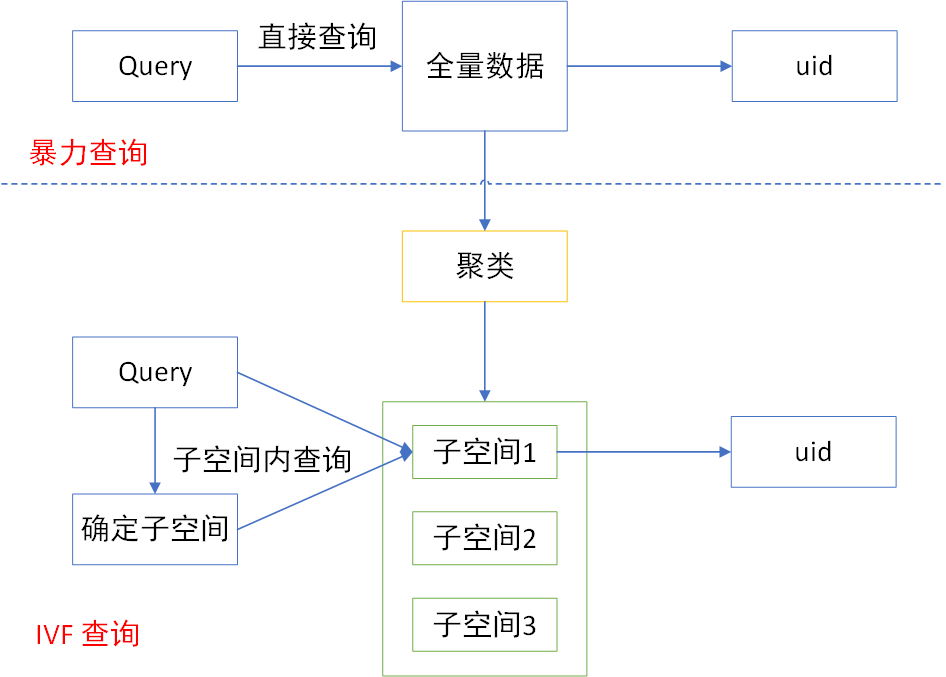
确定子空间: 通过计算 query 向量和所有子空间中心(如子空间内所有向量的均值)的距离,选出距离最近的 K 个子空间,表示和该 query 最相近的向量,最有可能在这几个子空间里。
缺点:
1.可能会损失精度,找到的是局部解,不是全局最优:
很可能更相近的向量不在遍历的这几个空间内,因此找到的相似向量不是全局最优的,在 faiss 中有两个参数,分别是 nlist 和 nprobe,其中前者决定了对全量用户聚类的个数,一般来说聚类个数越大,训练过程越慢,检索速度越快(每个子空间需要遍历的向量变少),后者决定了每次检索几个子空间,一般来说,检索的子空间越多,检索越精确,但是检索速度越慢。两者需要做一定的权衡。特别地,当两者相等时,等价于暴力检索。
2.检索速度可能不太稳定:
一般来说,在进行聚类后,检索的速度应该是暴力检索的1/nlist ,但是由于聚类算法不可能保证每个类包含的向量数量都是一样的,实际直觉上各个类的大小也不应该一样(如每个省份的人有多有少),因此在需要对较大的子空间进行遍历时,需要消耗较多的时间,反之则速度更快。一般有个常量 C 来表示,整体的查询效率为 C/nlist。
3.内存消耗较大:
无论是训练还是最后的检索,为了提升速度,都需要把全量数据加载到内存中,这种方法没有对向量进行压缩,内存消耗较大。
乘积量化
乘积量化的核心思想还是聚类。其主要分为两个步骤,Cluster 和 Assign,也即聚类和量化。
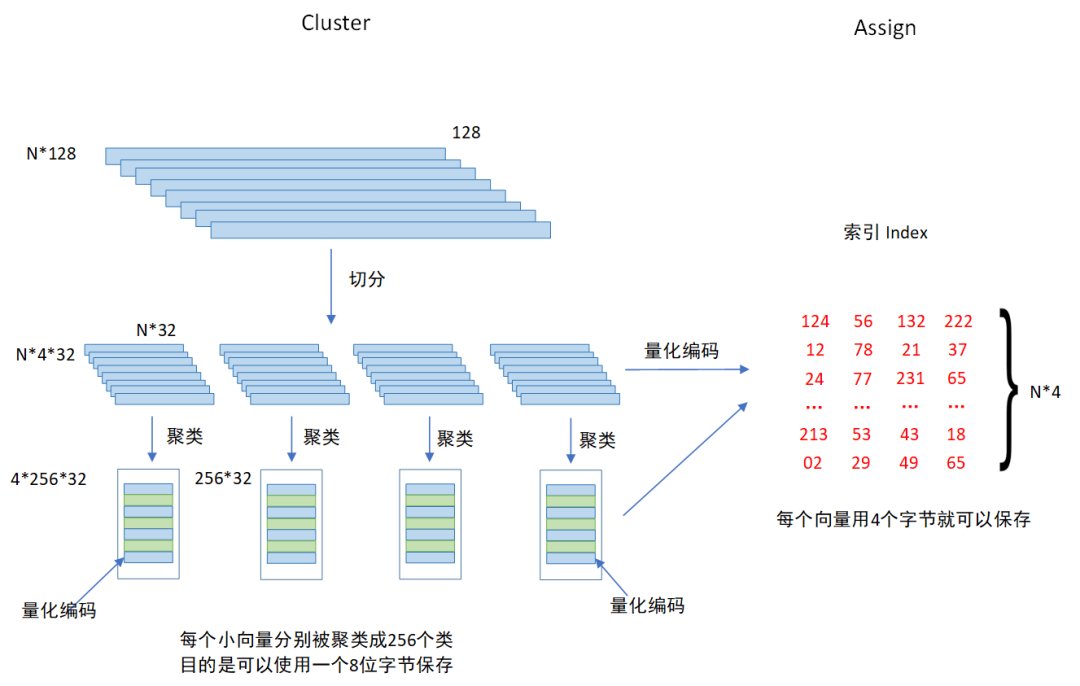
乘积量化有个重要的参数 m_split ,这个参数控制着向量被切分的段数,如图所示,假设每个向量的维度为128,每个向量被切分为4段,这样就得到了4个小的向量,对每段小向量分别进行聚类,聚类个数为256个,这就完成了 Cluster。然后做 Assign 操作,先每个聚类进行编码,然后分别对每个向量来说,先切分成四段小的向量,对每一段小向量,分别计算其对应的最近的簇心,然后使用这个簇心的 ID 当做该向量的第一个量化编码,依次类推,每个向量都可以由4个 ID(4 x 8 = 32)进行编码。
每个 ID 可以由一个字节保存,每个向量只需要用4个字节就可以编码,这样就完成的向量的压缩,节省了大量的内存,压缩比率2000+。
这一步其实就是 Faiss 训练的部分,目的是为了获取索引 Index。在完成向量压缩,获取索引之后,就要考虑如何进行向量查询,下图表示了某个查询向量Query进行查询时的操作流程:

由上图可以看出,当来到一个查询向量后,和训练时一样,首先需要对这个向量进行切分,这样就可以得到四小段的向量,然后计算每个小向量和对应的256个类中心的距离,存在一个距离矩阵或者数组中,接着就可以通过查表,来计算查询向量Query和每个向量之间的距离。计算方式就是累加每个小向量之间的距离之和。
Faiss 常用的索引介绍
1.暴力检索:Flat
即查询向量 query 与 base 向量库进行一一匹配计算,因此该方式的索引比较耗时,但召回率是最好的。(测试数据的维度128,数据集100000,返回 topk=10,查询向量 nq = 100,之后的测试数据相同)
def demo_IndexFlatL2():d = 128 #2048维数据nb = 100000 #database sizenq = 100loopTimes = 10np.random.seed(1234) #随机数种子#创建索引,大部分索引需要训练步骤,IndexFlatL2跳过这一步index = faiss.IndexFlatL2(d)print(index.is_trained)print("生成数据插入索引")#随机nb个数据插入索引xb = np.random.random((nb,d)).astype('float32')xb[:,0] += np.arange(nb)/1000index.add(xb)#随机nq个数用于查询xq = np.random.random((nq,d)).astype('float32')xq[:,0] +=np.arange(nq) 1000k = 10 #查询距离最近#Dis是距离 np对象,表示相似向量的距离;Id是索引(np对象,表示相似用户ID)start = time.perf_counter() #单位 微秒for i in range(loopTimes):Dis, Id = index.search(xq, k)search_time = (time.perf_counter() - start)qps = (nq * loopTimes) ((search_time))print("QPS = %.4f" %(qps))
QPS:5001.5669
Recall:100%
2.倒排索引+暴力检索:IVFFLAT
利用倒排索引的方法加速 Flat 的检索速度
def demo_IndexIVFFLat():d = 128nb = 100000nq = 100 #查询次数np.random.seed(1234)nlist = 100 #聚类中心个数k = 10 #查询最近的个数quantizer = faiss.IndexFlatL2(d)index = faiss.IndexIVFFlat(quantizer,d,nlist,faiss.METRIC_L2)xb = np.random.random((nb,d)).astype('float32')xb[:,0] += np.arange(nb) 1000index.train(xb)index.add(xb)print("index.ntotal",index.ntotal)xq = np.random.random((nq,d)).astype('float32')xq[:,0] +=np.arange(nq) 1000index.nprobe = 10 #每次搜索时聚类中心的个数loopTimes = 10start = time.perf_counter()for i in range(loopTimes):Dis, Id = index.search(xq, k)search_time = (time.perf_counter() - start)qps = (nq * loopTimes) ((search_time))print("QPS = %.4f" %(qps))
QPS:28487.7201
Recall:99.3%
3.乘积量化:PQ
利用 PQ 的方法创建索引
def demo_IndexPQ():d = 128 #维度nb = 100000 #数据量np.random.seed(1234)xb = np.random.random((nb,d)).astype('float32')xb[:,0] += np.arange(nb) 1000m = 8k = 10index = faiss.IndexPQ(d, m, 8)index.train(xb)index.add(xb)for nq in [1,2,4,8,16,32,64,100,128,256]:print("now begin nq = {}".format(nq))xq = np.random.random((nq,d)).astype('float32')xq[:,0] += np.arange(nq) 1000count = 10start = time.perf_counter()for i in range(count):index.search(xq, k)search_time = time.perf_counter() - startqps = (nq * count) ((search_time))print("QPS = %.4f" %(qps))
QPS:17104.6015
Recall:60.8%
4.倒排索引+乘积量化:IVFPQ
IndexIVFPQ 基于 Product Quantizer(乘积量化)的压缩算法编码向量大小到指定的字节数的索引算法,存储的向量是压缩过的,查询的距离是近似的,结合了 IVF 以及 PQ 的优势所建立的索引。
def demo_IndexIVFPQ():d = 128 #向量维度nb = 100000 #向量集大小nq = 100 #查询次数np.random.seed(1234)#生成数据总量xb = np.random.random((nb,d)).astype('float32')xb[:,0] += np.arange(nb) 1000#生成查询的数据xq = np.random.random((nq,d)).astype('float32')xq[:,0] += np.arange(nq) 1000nlist = 100 #聚簇中心的个数m = 8 #每个矢量的字节数;将原向量分为几段k = 10 #查询最近的个数quantizer = faiss.IndexFlatL2(d)index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8)index.train(xb)index.add(xb)loopTimes = 10index.nprobe = 10start = time.perf_counter()for i in range(loopTimes):Dis, Id = index.search(xq, k)search_time = (time.perf_counter() - start)qps = (nq * loopTimes) ((search_time))print("QPS = %.4f" %(qps))
QPS:83201.5975
Recall:56.6%
召回率测试样例
利用 Flat 所返回的 id 为基准,其他几种索引返回的 id 与 Flat 的 id 进行对比并找出相同的个数,计算召回率
import faissimport numpy as npimport timedef Recall():d = 128 #2048维数据nb = 100000 #database sizenq = 100loopTimes = 10np.random.seed(1234)#创建索引,大部分索引需要训练步骤,IndexFlatL2跳过这一步indexFlatL2 = faiss.IndexFlatL2(d)print(indexFlatL2.is_trained)print("生成数据插入索引")#随机nb个数据插入索引xb = np.random.random((nb,d)).astype('float32')xb[:,0] += np.arange(nb)/1000indexFlatL2.add(xb)#随机nq个数用于查询xq = np.random.random((nq,d)).astype('float32')xq[:,0] +=np.arange(nq) / 1000#print(xq)k = 10 #查询距离最近#Dis是距离 np对象,表示相似向量的距离;Id是索引(np对象,表示相似用户ID)for i in range(loopTimes):Dis, idFlatL2 = indexFlatL2.search(xq, k)print(idFlatL2)#******************** IVFFLAT ********************************************nlist = 100 #聚类中心个数k = 10 #查询最近的个数quantizerFlatL2 = faiss.IndexFlatL2(d)indexIVFFlat = faiss.IndexIVFFlat(quantizerFlatL2, d, nlist, faiss.METRIC_L2)indexIVFFlat.nprobe = 1indexIVFFlat.train(xb)indexIVFFlat.add(xb)for i in range(loopTimes):disIVFFLAT, idIVFFlat = indexIVFFlat.search(xq, k)print(idIVFFlat)num = 0for i in range(100):for j in range(10):if idIVFFlat[i][j] in idFlatL2:num = num+1print("num: %d" %num)print("recall: {}%".format((num)/1000 *100))#**************************PQ*****************************m = 8indexPQ = faiss.IndexPQ(d, m, 8)indexPQ.train(xb)indexPQ.add(xb)for i in range(loopTimes):disPQ, idPQ = indexPQ.search(xq, k)print(idPQ)num_2 = 0for i in range(100):for j in range(10):if idPQ[i][j] in idFlatL2:num_2 = num_2+1print("num_2: %d " % num_2)print("IndexPQ recall: {}%".format((num_2)/1000 *100))#**************************IndexIVFPQ**********************************quantizer = faiss.IndexFlatL2(d)indexIVFPQ = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8)indexIVFPQ.nprobe = 1indexIVFPQ.train(xb)indexIVFPQ.add(xb)for i in range(loopTimes):disIVFPQ, idIVFPQ = indexIVFPQ.search(xq, k)print(idIVFPQ)num_3 = 0for i in range(100):for j in range(10):if idIVFPQ[i][j] in idFlatL2:num_3 = num_3+1continueprint("num_3: %d " % num_3)print("IndexIVFPQ recall: {}%".format((num_3)/1000 *100))if __name__ == '__main__':Recall()
总结

根据我们上面的测试发现,每一种索引都有自己的优缺点。例如 Flat 相关的索引,准确度是最高的,但由于使用的是暴力计算的方法,它的时间是最久的;而 PQ 相关的索引,虽然在时间上有所提升,但由于是压缩过的,所以他的准确度是较低的。因此我们读者在使用的时候可以根据自己的场景选择合适的索引来构建自己的项目。

向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

