




实战系列
相信有不少伙伴对大模型有所耳闻,但也是一知半解,也许你知道很重要可以为自己的工作提供帮助但是不知道该如何结合,又或是转行的过程中并不知道从何入手,网上的教程要么不包含具体的操作步骤要么需要好几篇合在一起才能弄清。我们接下来会每周更新一篇文章用尽可能通俗易懂的语言来介绍大模型相关的技术以及应用,并且还有保姆级的实战教程,从0开始教你怎么操作。
今天先用一篇文章简单导入,介绍一下大模型是什么,如何实现的,以及可以用在什么地方,比较适合小小白阅读哦。
大模型是什么

说到大型语言模型 LLM(large language model),大家最熟悉的应该就是 chatGPT 用到的 GPT 系列。LLM 又被统称为 foundation models (基石模型)是指由神经网络组成的语言模型,通常包含数十亿个或更多的参数,是使用自监督学习或半监督学习来训练大量未标记的文本所得。可以捕捉更复杂的模式和关系,从而提供更准确和强大的预测和模式识别能力,有助于解决许多领域的挑战,包括自然语言处理、计算机视觉、语音识别等。
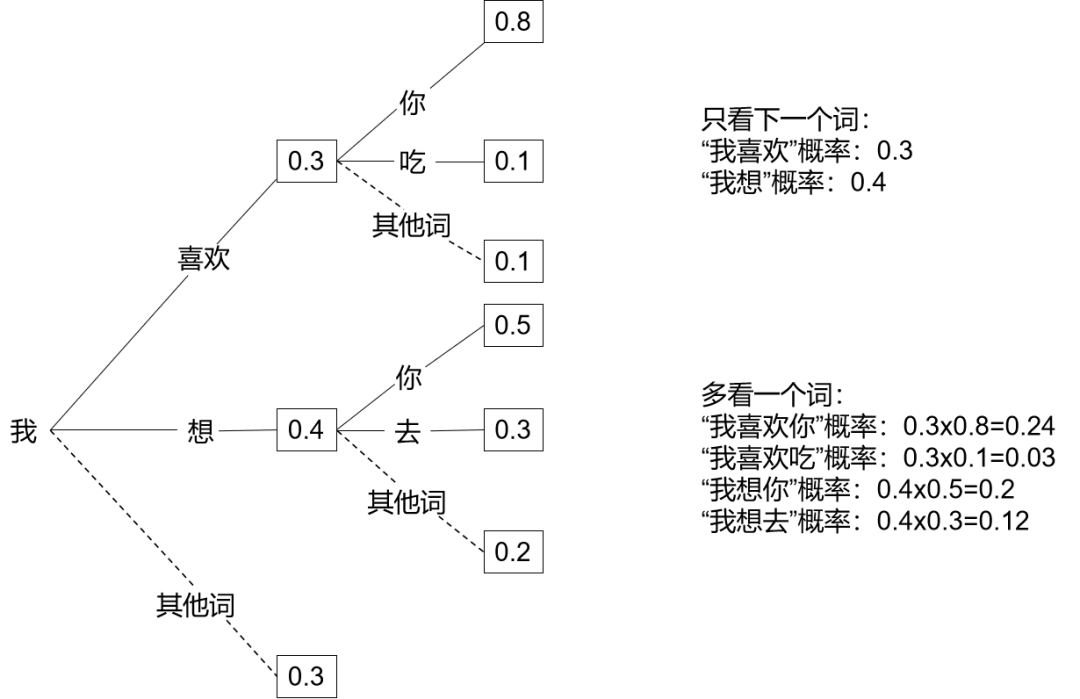
简单点说大模型就是用大量级数据进行训练,拥有大规模参数,能够处理复杂任务和大规模数据的模型。








总结
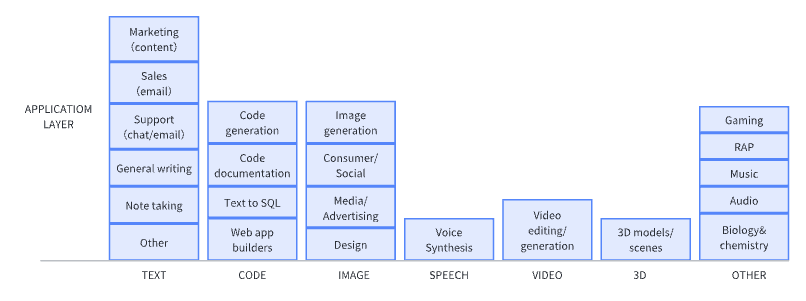
其实从上面的内容中不难看出,目前大模型可以应用到各个领域,大家也可以打开脑洞想想如何将 AI 助手结合到我们的工作学习中,学会如何正确的使用大模型帮助我们更快更好的完成目标任务,比如这篇文章,就是在 chatGPT 小助理的协助下完成的(害羞)。总之,跟上时代的步伐对于我们而言终归是有益处的,如果觉得有所帮助,可以点个关注,追更教程。
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

文章转载自向量检索实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
