




论文分享
作者:王梦召,浙江大学在读博士
个人主页:mzwang.top
文章总结
Vector Search
视觉时装搜索时能够操纵属性是一个有意义的场景。文章的背景主要是应用导向的。面向的场景是,用户在搜索一个商品时,给出一张照片和一些文本描述,并通过文本描述修改照片的某些内容。
本文的解决思路是将图像和文本嵌入到一个公共空间,通过查询给出的图像嵌入和文本嵌入之间的算术运算构建该空间中的一个新向量(对应用户的目标),用该新向量通过相似度计算检索用户的目标。下图清楚展示了这一过程。
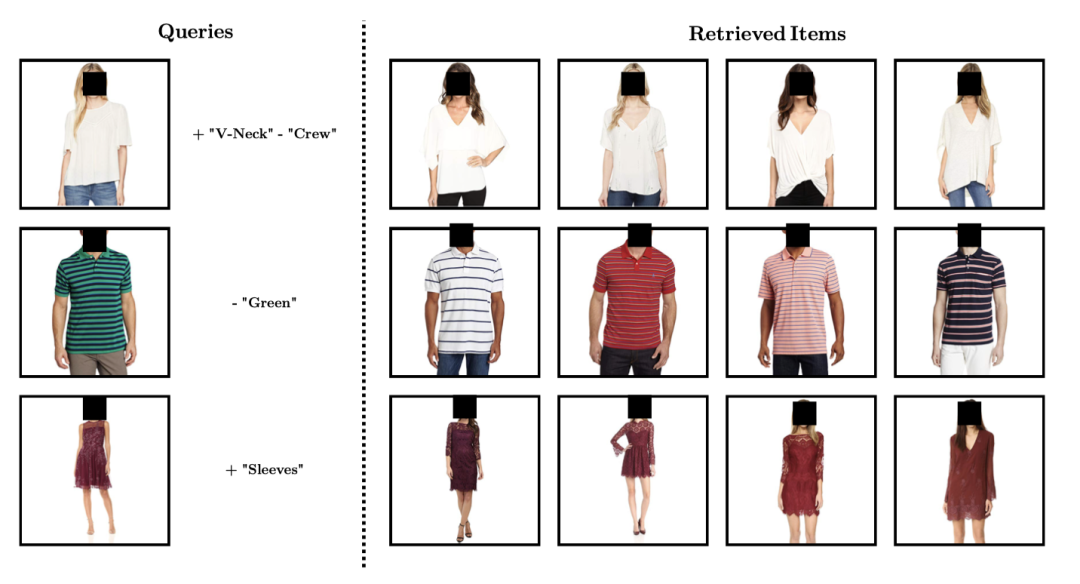
研究内容概述
Vector Search
一个令人惊奇的神器:向量的算术性质
“Paris” - “France” +“Italy” = “Rome”
given f I , a representing vector of an image of a blue car, f I - “blue” + “red” yields a representing vector of a red car image.
本文关注时装领域的多模态搜索,提出了Mini-Batch Match Retrieval,每个mini-batch由匹配和不匹配的图像-文本对组成。本文为每一个item学习一个embedding,并从mini-batch中尝试划分正确的图像-文本对。
本文探索了视觉时装属性提取,只需要利用有噪声的catalog data,不需要额外的注释。
本文设计3种不同的多模态搜索方法:
(1)图像-文本联合嵌入,查询算术性质;
(2)学习属性提取,视觉搜索+soft文本过滤;
(3)查询算术性质+soft文本过滤。
数据
Vector Search
训练数据:50万时装商品,每一个商品条目由图像+文本元数据组成;
基数据(测试数据):150万时装商品;
训练
Vector Search
模型概览
如下图所示,整个模型由两大部分组成,一部分为Joint Embedding,即联合嵌入训练,另一部分为Attribute Extraction,即属性提取。
Joint Embedding:
图像经图像编码器(ResNet-18)提取为视觉特征向量,文本通过文本编码器(word2vec,文本视为词袋,词嵌入相加得到文本嵌入)生成文本嵌入 fT 。图像嵌入得到的视觉特征向量通过一个额外的全连接层(FC)映射到与文本相同的嵌入空间,即得到 fI。通过 fT 和 fI 计算一个损失函数:
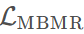
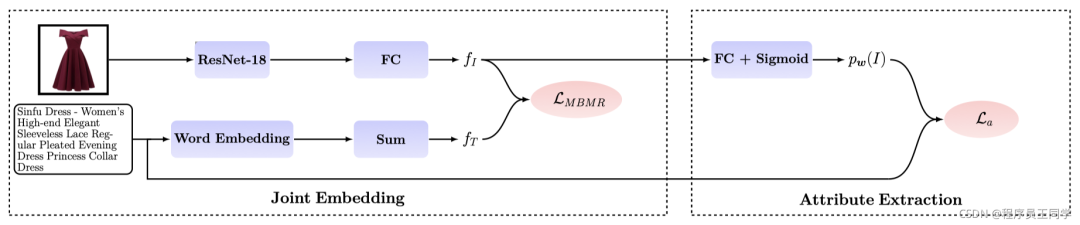
Attribute Extraction:
该部分的输入为上一部分的 fI,其经FC+Sigmoid(多标签分类)转化为属性概率向量 Pw( I )(它的维度由词典的尺寸决定),条目的文本元数据作为属性的真值,此时损失函数 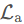 根据上述两者计算。
根据上述两者计算。
总的损失函数是上述两个损失函数的加权之和。
文本元数据预处理
(1)Tokenization: 描述文本划分为一组标记;
(2) 将单词标准化为其基本形式,以避免具有相同视觉含义的多个单词变体;(3)识别更可能具有视觉意义的名词和形容词标记,并忽略其余部分;
(4)在数据集中出现次数少于某个硬截止阈值(本文设为500)的单词被删除,从而减少噪音并避免不必要的大词汇量。
Joint Embedding (Mini-Batch Match Retrieval Objective)
目标概述:相匹配的图像-文本对彼此之间应该互相接近(在公共嵌入空间中)。
在训练集中,每一个 mini-batch 由 N 个商品条目组成,即
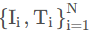
Ii 是图像,Ti 是文本元数据。任意一图像嵌入 fI 和文本嵌入 fT,计算两者的余弦相似度:
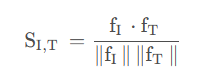
Ii 匹配 Tj 的概率:
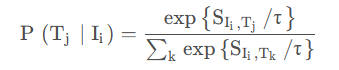
τ是一个温度参数。类似地,Ti 匹配 Ij 的概率:
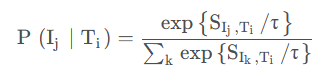
因此,总的损失函数为(交叉熵):

Attributes Extraction
一个好的joint embedding模型学习到的图像嵌入和文本嵌入应达到:根据两者的余弦相似度可由其中一者(比如图像)得到另一相似的(对应的文本描述)。然而,存在下面两个问题:
(1)不是所有的词都具有相同的视觉基础;
(2)不同词的词频变化较大。
为此,本文通过Attributes Extraction部分进一步优化模型。一个全连接层将图像嵌入映射为词典尺寸(紧接着一个sigmoid函数)。输出为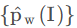 ,它是词典中的一个词属于该图像的概率。真值是该图像的元数据描述存在的词。
,它是词典中的一个词属于该图像的概率。真值是该图像的元数据描述存在的词。
一个词 w 属于图像 I 的概率更多细节计算参考原文公式(5)-(8)。
三种不同的多模态检索方案(具体执行)
Vector Search
查询算术方法
给定一个查询,它由图像和一些喜欢的或不喜欢的属性组成。根据上一部分介绍的模型将图像和文本嵌入到相同的空间,通过图像嵌入和文本嵌入之间的算术运算得到一个独立的查询向量 q= fI + fT,用该向量去执行查询。
属性过滤方法
先属性过滤,把与查询文本描述不一致的都过滤掉,然后对剩余的进行纯图像的检索。根据条目是否是完整无错误的分以下两种情况计算相似度。
完整无错误的条目(理想的):
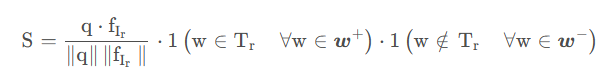
其中 q= fI,Pw(Ir)是查询给出的喜欢(或者不喜欢)属性在(或不在)条目图像 Ir 中的概率。该方法即软属性过滤。
联合方法
将之前描述的两种方法结合成一个强大的方法。通过使用软属性过滤以及基于查询算术运算执行搜索来做到这一点。添加属性过滤的是为了更好地满足文本操作标准。由于属性过滤是有瑕疵的,仅将其与视觉搜索一起使用是不够的,因为它会导致在不考虑文本操作的情况下检索视觉相似的条目。
该方法计算公式与式(1)形式相同,不同处为:q= fI + fT。
评估
Vector Search
查询样本的构建
取样一些商品图片,从公共服装属性集合中提取一些想要的或不想要的文本描述(与图片一一对应)。文本要求(从相应的查询图像中):添加;移除;取代。
评估结果
标准化折扣累积收益(nDCG):评估每个查询前 K 个检索结果的相关性,并根据排序进行惩罚。
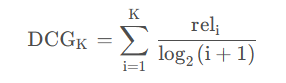
reli 表示排在第 i 个位置结果与查询的相关性(根据一些准则计算,具体与模态有关)。
根据公式(2)预先计算一个 IDCG(Ideal-DCG),它是在理想排序结果上计算的(可认为是真值);根据查询得到的结果由式(2)再计算一个 qDCG,从而 nDCG=qDCG/IDCG.
针对具体的模态,相关性计算如下:
视觉 nDCG(V−nDCG)。基于从基线视觉搜索模型中提取的视觉相关性。这个纯视觉模型在条目图像上使用triplet损失进行训练,其中对于每个查询图像,将同一条目的不同图像视为正样本,将不同条目的图像视为负样本。相关性是从该基线模型中提取的条目和查询视觉特征之间的余弦相似度。
文本nDCG(T−nDCG)。根据文本约束的要求是否满足,具体地,如果文本给出的渴望要求出现在参考条目的元数据描述中则满足,如果文本给出的不需要的要求没有出现在参考条目的元数据描述中则满足。要求被满足的比率即为文本的nDCG。
多模态的nDCG即为各模态数据的nDCG的几何平均。即:
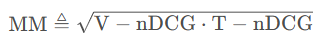
一些考虑
Vector Search
(1)将查询图片和文本转变为一个向量,然后检索,这种方案检索出的图片相似度较大,但多模态综合相似度一般;
(2)文本过滤+图像相似度检索,文本的相似度较高,多模态综合相似度一般;
(3)文本过滤+图像和文本转化为一个向量的检索,多模态综合相似度最好。
参考文献
[1906.06620] Joint Visual-Textual Embedding for Multimodal Style Search (arxiv.org)
点击【阅读原文】可以直接跳转到王梦召博士在 CSDN 上发表的原文。
向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

