





今日分享论文 RetroMAE: Pre-Training Retrieval-oriented Language Models ViaMasked Auto-Encoder
本篇论文出自 EMNLP 2022,由华为泊松实验室联合北京邮电大学、华为昇思 MindSpore 团队提出。该方法在稠密检索领域刷新了多项指标,证明了该预训练模型的有效性。
稠密检索 Dense Retrieval
稠密检索这一任务广泛的应用于搜索引擎、推荐系统中。稠密检索的核心是将 query 和 document 编码成低维向量,而后通过计算两两之间的向量相似度来估计 query 和 document 之间的相似性。用于编码的模型通常有双塔模型、交互式模型等多种形式。预训练语言模型的出现极大地促进了稠密检索的发展。
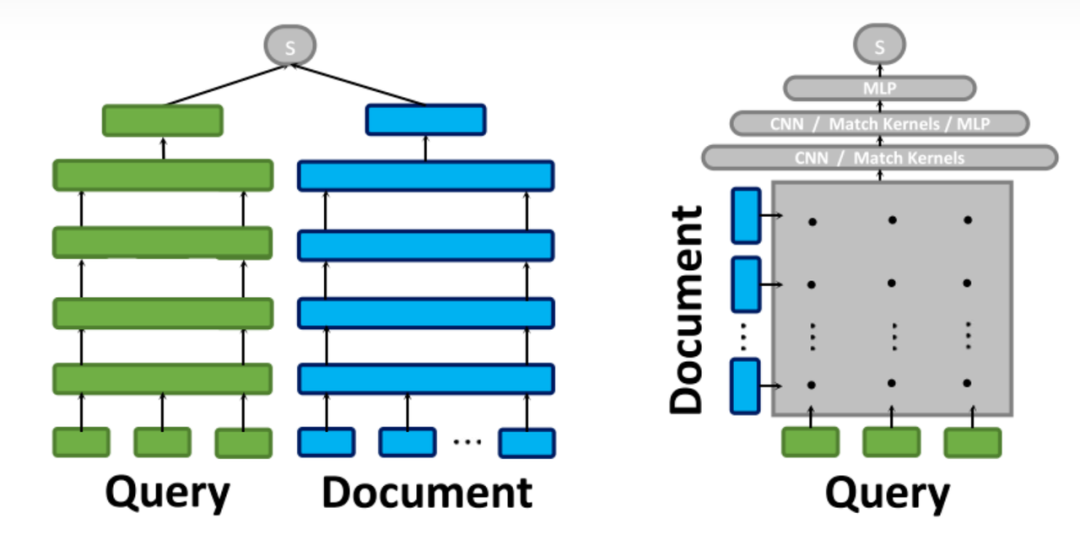
以 BERT 为代表的预训练语言模型已被普遍用作稠密检索中的骨干网络架构。借助预训练语言模型强大的语义建模能力,稠密检索的精度得到了极大的提升。但在 NLP 常用的预训练模型通常是由token级别的任务进行训练的,如MLM和Seq2Seq,而密集检索任务更倾向于句子级别的表示,需要捕捉句子的信息。
例如,Bert 的 MASK 机制是以 token 为单位随机选择句子中 15% 的 token,然后将其中 80% 的 token 使用 [MASK] 符号进行替换,将 10% 使用随机的其他 token 进行替换,剩下的 10% 保持不变。可以认为这种方法更适合去捕捉上下文词之间的信息,而不是句子信息。
若想更好的捕捉句子的信息,一般主流的策略是自我对比学习和基于自动编码。其中对比学习的方法更依赖于数据增强的质量和负样本的数量。故作者提出了基于自动编码的方案。
Retro MAE 的主要特点
1.新的自动编码方案。输入句子被掩码两次,第一次的掩码结果输入到编码器生成句子嵌入,另一个掩码结果结合生成的句子嵌入,输入到解码器中,通过 MLM 恢复原始句子;
2. 非对称的结构。编码器是一个全尺寸的BERT,用来生成句子嵌入;解码器只有一个单层的 transformer;
3. 非对称的 Mask 率。编码器的输入掩码率为15%-30%;解码器的掩码率为50%-70%。
● 编码阶段 ●
在编码阶段,输入句子 XMASK 后记为 Xenc,掩码率为15~30%,然后将其输入到编码器,转化为句子嵌入 hx。该编码器为 BERT,有12层以及768隐藏维度。ϕ(·)是编码器。
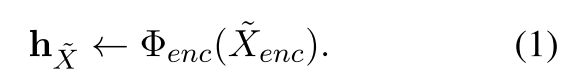
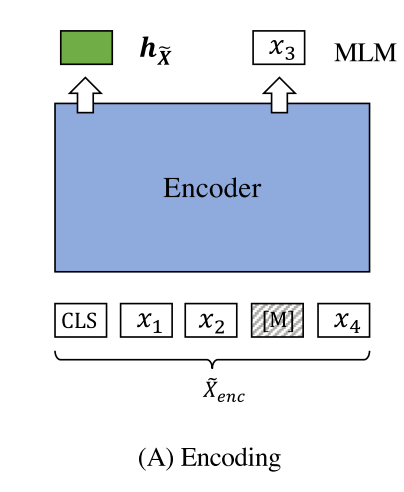
● 解码阶段 ●
首先,输入句子 X 同样 MASK 为 Xdec,掩码率为50~70%,然后和句子嵌入 Hx 结合作为 Hxdec 输入到解码器,完成原始句子的重建。更具体的来说,句子嵌入和掩码输入的结合方法如下:
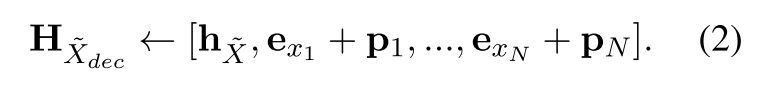
解码器输入序列其中 exi 是 token 的嵌入,pi 指的是位置嵌入,蕴含了 token 的位置信息。最后优化下面的目标函数来进行重建。
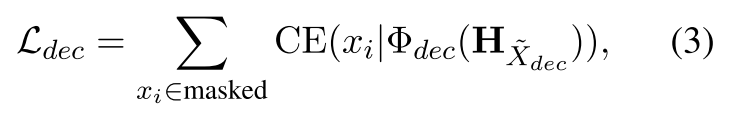
其中 CE 是交叉熵损失。
作者认为,解码器结构简单,只有单层 transformer,而且输入句子的掩码率很高,会使得解码变得具有挑战性,可以迫使生成高质量的句子嵌入,以便可以更好的恢复成原始输入句子。
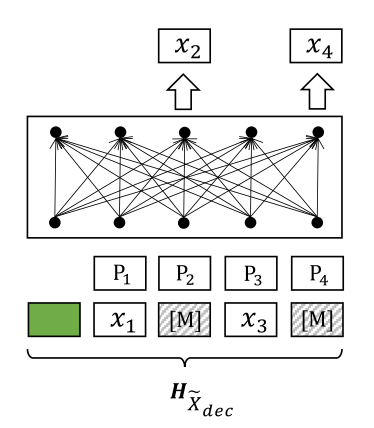
● 增码阶段 ●
在上式中可以看出,decode 部分的交叉熵损失是由被 mask 的词而来,而每个被 mask 的词都依赖于相同的上下文信息,也就是每个词对应的 Hxdec 都是相同的。
作者认为解码需要满足以下两点才可以更好的增强整个预训练的效果:
1.在输入句子中获得更多的训练信号。
2.基于多样的上下文执行重建任务。
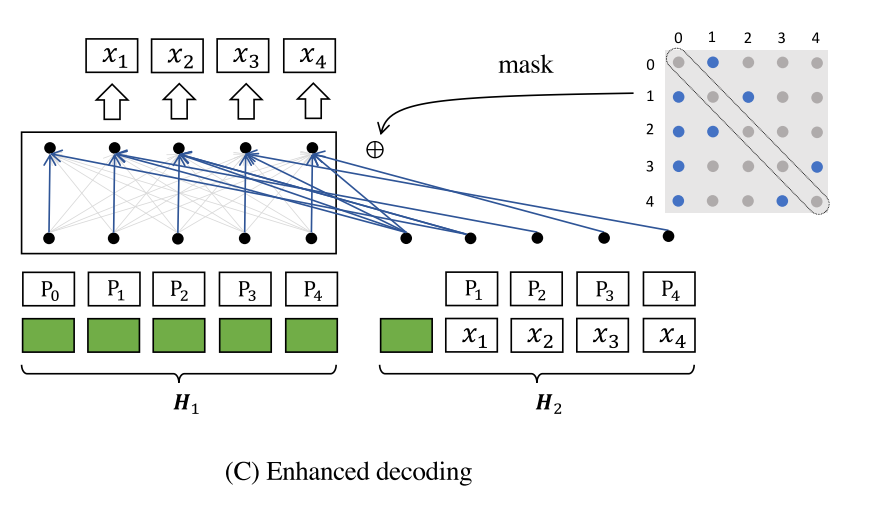
基于以上考虑,作者提出了增强解码的方法:通过双流自我注意力和特定位置注意力掩码的增强解码。具体来说,作者生成了两个输入流:H1(0query)和 H2(context)
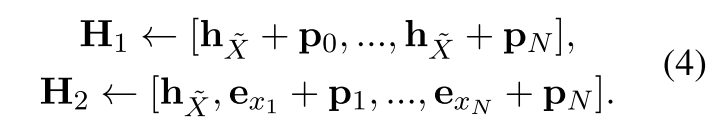
其中:
hx是句子embedding
exi是token embedding(此处没有token被mask)
pi是位置嵌入。
引入特定位置注意掩码矩阵 M ∈ RL×L,其中自注意力计算为:
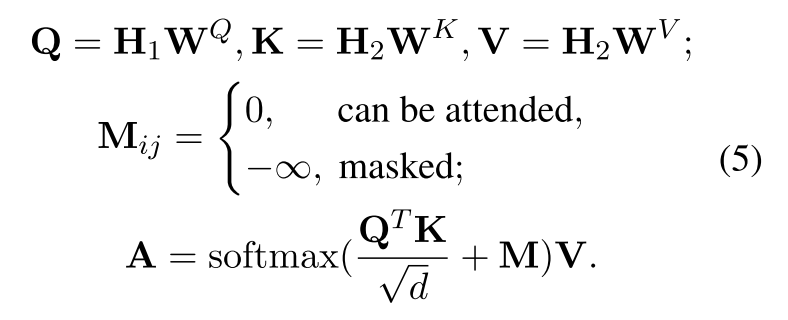
损失函数定义为:
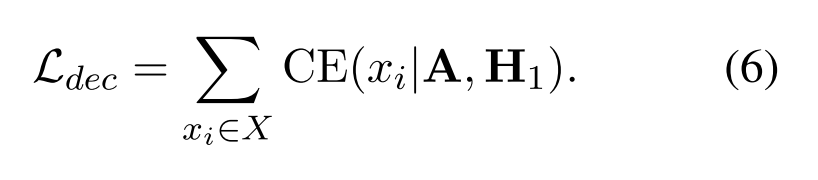
实验
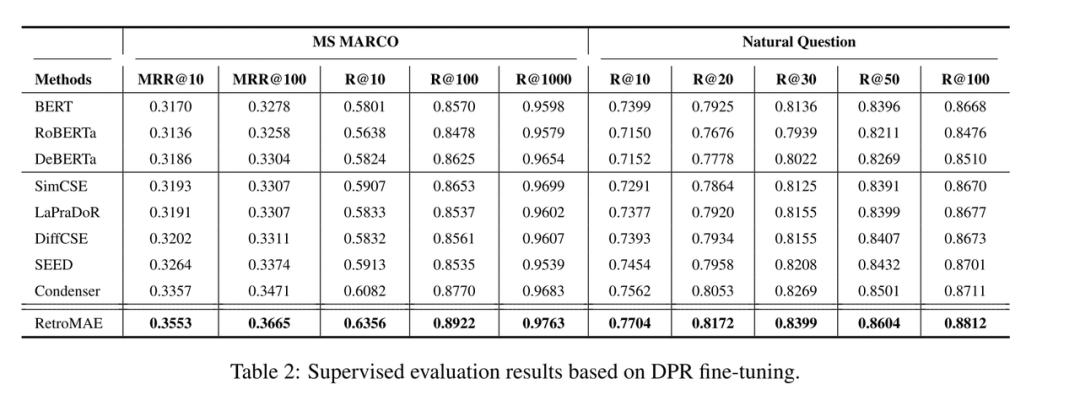
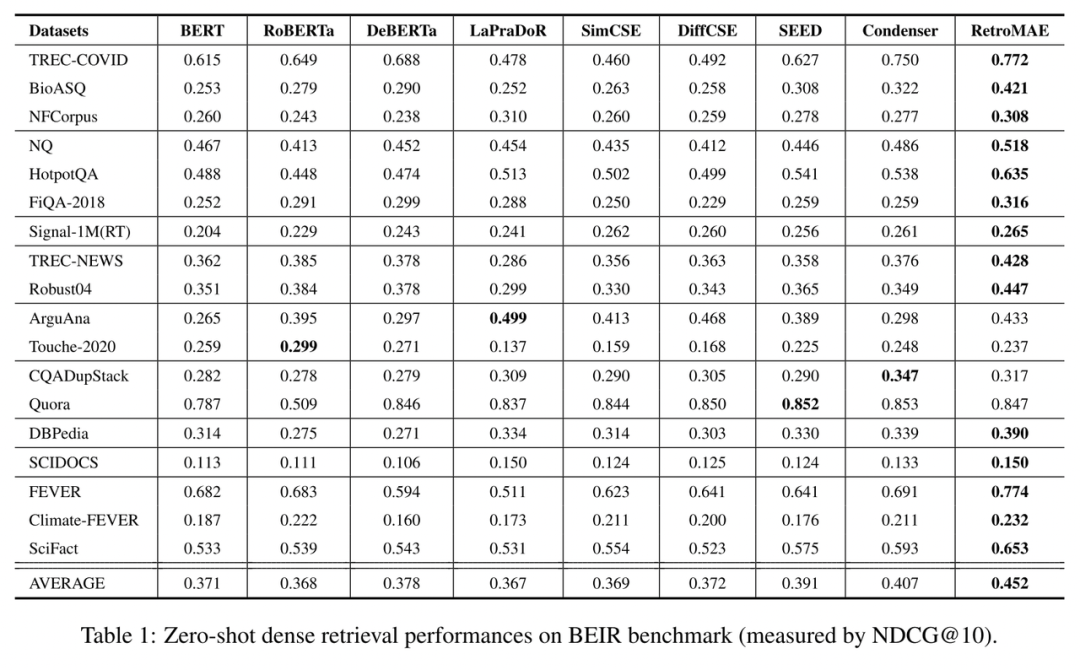
RetroMAE 在零样本学习(zero-shot learning)与监督学习(supervised learning)场景下均展现了极强的稠密检索性能。根据在零样本稠密检索基准 BEIR 之上的表现,RetroMAE 在绝大多数任务中都明显优于 BERT、RoBERTa、DeBERTa 等传统基线,其平均检索精度更是远超此前同等规模的预训练模型。
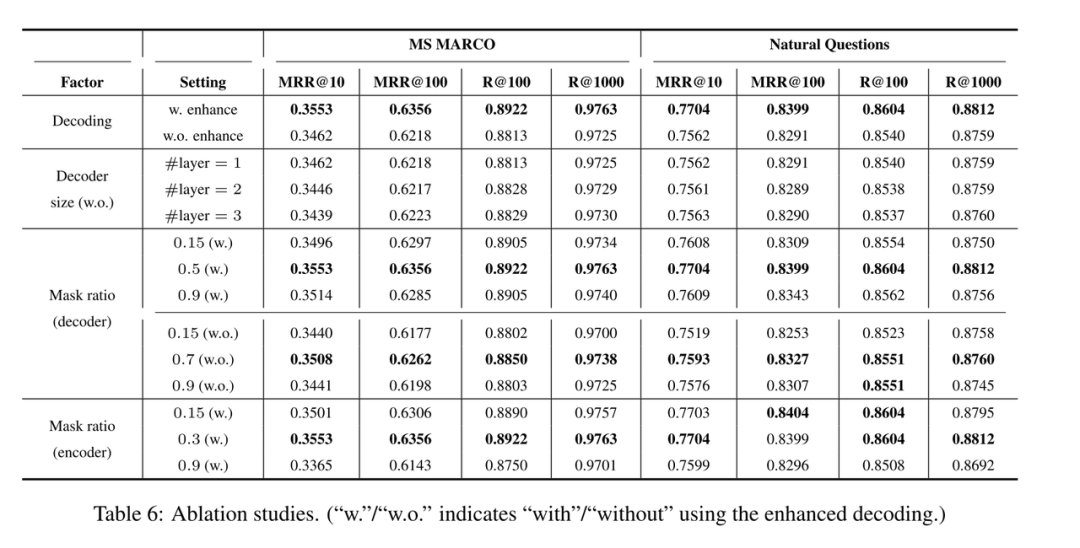
该实验可以看出解码方法、解码器规模、解码器的掩码率和编码器的掩码率的影响。
总结
作者提出RetroMAE,面向稠密检索任务的预训练模型,该模型有着掩码编码的非对称结构。这种设计使得重建的难度大,故可以生成更关注句子信息的的特征表示。最终在零样本密集检索以及有监督的密集检索性能都有所提升。

向量检索实验室
微信号:VectorSearch
扫码关注 了解更多

