





微软全新发布的多风格、多语言的神经网络版声音定制功能(Custom Neural Voice,以下简称 CNV)是 Azure AI Speech 文本转语音(Text to Speech)服务的一项特色功能。用户可基于此项服务创建一种高度逼真、自然的 AI 语音,听感和真人配音演员完全一致。随着最新功能的发布,这项语音服务支持多情感的表达并具有跨语言能力。
自推出以来,CNV 已经助力 AT&T、Progressive、Vodafone、Swisscom、海尔等众多国内外知名企业开发出具有品牌特色的语音解决方案,支持包括语音助手、客服机器人、有声读物、语言学习、新闻播报等不同场景,为千百万听者带来愉悦的听感体验。

支持更多情感和风格的语音服务,将极大地提升终端用户使用体验。通过多风格 CNV 功能,用户无需额外添加新的训练数据,通过风格转换(Style Transfer)技术即可创建多风格、多情绪的语音表达。
风格转换技术,能将一个说话者(源说话者)的语调和韵律(即节奏、语调、节奏)应用到另一个说话者(目标说话者)身上。这将使目标说话者采用源说话者的语调和韵律,同时保留自己的音色。
随着多风格 CNV 的正式推出,微软发布了新的美式英语风格转换模型,并将该功能扩展到了汉语和日语。
如何
创建多风格语音
首先,你需要准备一个大约300多句话的语音样本(不需要多风格语音数据)作为其默认风格。
再将准备好的数据导入到 Speech Studio 门户后,在训练方法中选择 Neural - multi style(神经网络 - 多风格)。
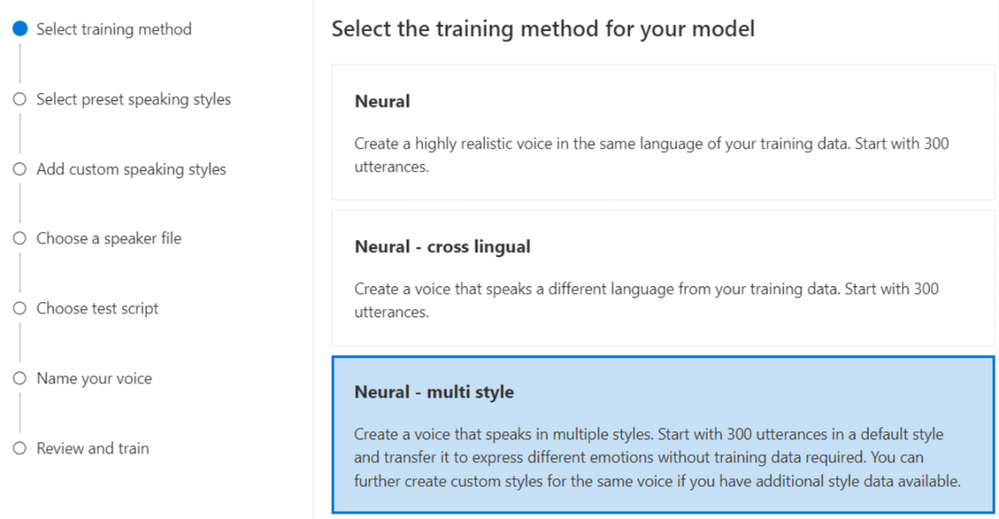
从预设的风格列表中选择你想要启用的目标说话风格。如果你有其他风格的录音数据,也可以在这一步选择自己的风格数据来创建自定义的说话风格。
多情感模型的训练时间取决于训练数据的大小、语言和所选择的风格,可能需要40小时或者更长时间完成。模型创建成功之后,系统会自动生成一批测试音频,你可以通过这些试听样本来测试声音效果。
效果测试完成之后,把声音模型部署到云端,你就可以通过音频内容生成工具(Audio Content Creation)来创建新的音频了,此过程无需任何编程。如果你是开发者,你也可以用语音开发工具包 SDK,用代码把这个声音集成到自己的app里。通过语音合成标记语言(SSML),你可以切换不同的说话风格,以更好地匹配你的应用场景。

在当今互联互通的世界中,开发人员需要构建能够覆盖全球用户的语音应用程序。借助跨语言迁移学习技术,CNV 可以让你的定制声音轻松获得多语言能力,而无需额外添加特定语言的训练数据。该功能已支持数十种语言。
跨语言模型是一个整体性的单一模型,它使用来自不同说话人和不同语言的数据进行训练。跨语言模型的基础是 Conformer,它结合了卷积神经网络(convolution neural networks)和转换器(transformers),以高效地在数据序列中对局部或全局的关联性进行建模。
为了解决不同语言数据不平衡的问题,微软采用了数据平衡训练策略,提高低资源语言的模型性能。此外,微软结合说话者分类器(speaker classifier)对模型进行训练,最大限度地减少了跨语言说话者之间的相似性损失,并改善跨语言场景中的说话者相似性。新模型可以利用来自 L1(母语)说话人的信息,进一步提高跨语言语音的自然程度。
跨语言 CNV 功能已正式推出以下语言支持:中文(普通话),荷兰语(荷兰),英语(澳大利亚),英语(英国),英语(美国),法语(加拿大),法语(法国),德语(德国),印度尼西亚语,意大利语,日语,韩语,葡萄牙语(巴西),俄语,西班牙语(墨西哥),西班牙语(西班牙)。你只需要提供以上某一个语言的录音数据,你的定制声音就能获得其他所有语言能力。
如何
创建多语种语音
在训练方法中选择 Neural – cross lingual(神经-跨语言)。
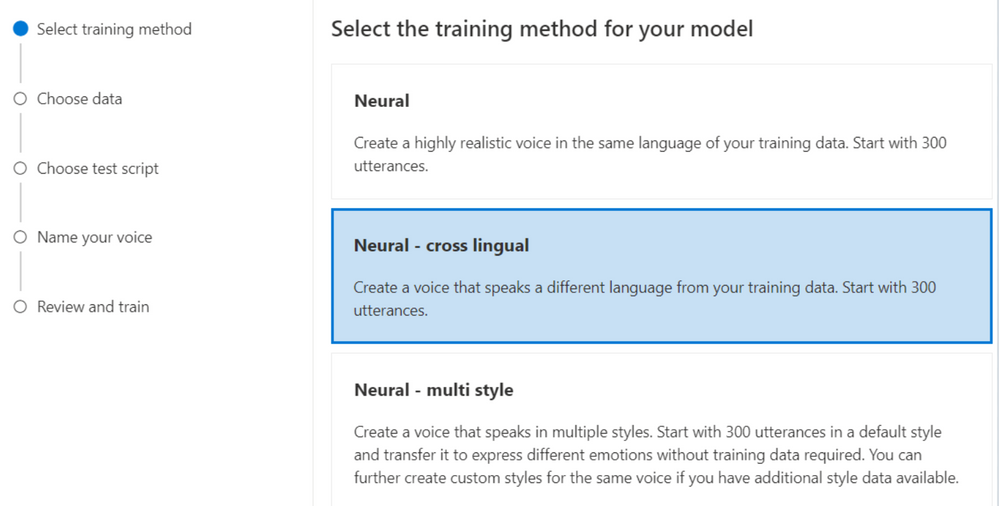
选择你所需要的目标语言。CNV 平台即可将你的 AI 声音转换成为你所选择的目标语言。
训练过程需要约20个小时,具体取决于用户训练数据大小和所选语言。类似地,你可以通过测试样本来评估声音效果。
模型部署后,使用目标语言提供文本输入,就可以合成该语言的语音内容了。你可以同样选择通过音频内容生成工具(Audio Content Creation)或通过语音 SDK 进行合成服务。
微软多风格和多语种的神经语音声音定制(CNV)功能现在 Azure 国际版推出,对于希望构建与全球用户无缝交流的语音应用程序的开发人员来说,是一项具有革命性意义的进步。
定制神经语音是一项有限访问服务,这是微软对「负责任的 AI」的承诺的一部分。如果你对这项功能感兴趣,请扫描下方二维码申请访问该技术的权限,并遵循「负责任的 AI」部署准则以确保负责任地使用这项功能。

