




大家好,我是小老弟。
上周我们科普了磁盘的工作原理,我估计你现在都迫不及待想知道,怎么才能衡量磁盘的 I/O 性能。
那我们今天主要是科普 Linux 磁盘 I/O 的性能指标和性能工具。
1磁盘性能指标
磁盘性能指标说到磁盘性能的衡量标准,必须要提到五个常见指标。就是使用率、饱和度、IOPS、吞吐量以及响应时间,是衡量磁盘性能的基本指标。每次我们排查I/O性能的时候,都会使用这五个指标来判断I/O负载,所以必须要掌握这五个指标。
使用率,是指磁盘处理 I/O 的时间百分比。使用率只考虑有没有 I/O,而不考虑 I/O 的吞吐量。换句话说,当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求(磁盘支持并行写),如果没有出现延迟,依然没有达到性能瓶颈。 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。 IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。机械硬盘的 IOPS,大概只能做到每秒 100 次左右。 吞吐量,是指每秒的 I/O 请求大小,如:SATA3.0接口的机械硬盘的吞吐量200MB/S,SATA3.0接口的固态硬盘的吞吐量400MB/S,PCI Express的SSD的吞吐量在1.2GB/S。对于机械盘,我们可以通过减少悬臂的寻道次数,来达到降低IOPS,增加吞吐量。 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。因I/O是最慢的一环,所以有了缓存机制。如应用服务mysql就有自己的缓存机制,文件系统也会有自己的缓存机制。
这些指标,很可能是我们经常挂在嘴边的,一讨论磁盘性能必定提起的对象。
但是我们还是需要注意:磁盘性能分析,不能孤立地去比较某一指标,而要结合读写比例、I/O 类型(随机还是连续)以及 I/O 的大小、并行I/O的数量,综合来分析。
随机读写的场景中,我们一般都是参考IOPS值;对于顺序读写,我们一般都是参考吞吐量。
比如应用程序启动时,读的比例占到80%。 在数据库、大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能; 多媒体等顺序读写较多的场景中,吞吐量才更能反映系统的整体性能。对于 HDD 硬盘的顺序数据读写,吞吐率还是很不错的,可以达到 200MB/s 左右。 对于SSD,在随机I/O与顺序I/O时,通常没有什么区别。由于SDD执行的是读-改-写的效应,如果写入比较小的块,特别是随机写,可能会导致写放大,出现性能问题。
2基准测试
一般来说,我们在为应用程序的服务器选型时,要先对磁盘的 I/O 性能进行基准测试,以便可以准确评估,磁盘性能是否可以满足应用程序的需求。
我们首先肯定是磁盘性能测试工具 fio ,来测试磁盘的 IOPS、吞吐量以及响应时间等核心指标。但还是那句话,因地制宜,灵活选取。比如ceph,就需要自带性能工具测试磁盘io与网络的吞吐量。
在基准测试时,一定要注意根据应用程序 I/O 的特点,来具体评估指标。 当然,这就需要我们测试出,不同 I/O 大小(一般是 512B 至 1MB 中间的若干值)分别在随机读、顺序读、随机写、顺序写等各种场景下的性能情况。
用性能工具得到的这些指标,可以作为后续分析应用程序性能的依据。一旦发生性能问题,我们就可以把它们作为磁盘性能的极限值,进而评估磁盘 I/O 的使用情况。了解磁盘的性能指标,只是我们 I/O 性能测试的第一步。
我们一般得到如下数据:
最大磁盘吞吐量 最大磁盘IOPS 最大磁盘随机读IOPS 顺序读响应时间 随机读响应时间
3磁盘 I/O 观测
首先我们要观测的,是每块磁盘的使用情况。 iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 proc/diskstats。可以通过man,或者help查看参数含义。
[sdk_test@ssdk1 server]$ iostat -d -x -k 1 2
Linux 2.6.32-431.11.15.el6.ucloud.x86_64 (ssdk1) 10/14/2016 _x86_64_ (4 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
vda 0.00 0.19 0.00 0.65 0.04 3.37 10.41 0.00 0.78 0.41 0.03
vdb 0.00 5.85 0.29 1.13 6.23 27.93 48.06 0.00 1.44 0.41 0.06
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
这些指标中,我们要注意:
%util ,就是前面提到的磁盘 I/O 使用率; r/s+ w/s ,就是 IOPS; rkB/s+wkB/s ,就是吞吐量; r_await+w_await ,就是响应时间。 avgrq-sz 平均每次设备I/O操作的数据大小(扇区) avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。
在观测指标时,也别忘了结合请求的大小rareq-sz(平均读:单位KB) 和 wareq-sz(平均写:单位KB)一起分析。从 iostat 并不能直接得到磁盘饱和度。
事实上,在linux4.20之前,饱和度通常也没有其他简单的观测方法,不过,我们可以把观测到的,平均请求队列长度或者读写请求完成的等待时间,跟基准测试的结果(比如通过 fio)进行对比,综合评估磁盘的饱和情况。
但是在inux 4.20中增加了磁盘I/O饱和度统计信息,包含了是否有I/O压力,而且还显示了过去五分钟内的变化情况。执行 cat proc/pressure/io 命令,输出如下:
cat /proc/pressure/io
some avg10=0.00 avg60=0.00 avg300=0.00 total=56385169
full avg10=0.00 avg60=0.00 avg300=0.00 total=54915860
这些指标中,我们要理解:
avg 给出了任务由于硬件资源不可用而被停顿的时间百分比。avg10、**avg60 **和 **avg300 **分别是最近 10 秒、60 秒和 300 秒的停顿时间百分比。 some 指标说明一个或多个任务由于等待资源而被停顿的时间百分比。 full 指标表示所有的任务由于等待资源而被停顿的时间百分比。
4进程 I/O 观测
除了每块磁盘的 I/O 情况,每个进程的 I/O 情况也是我们需要关注的重点。上面提到的 iostat 只提供磁盘整体的 I/O 性能数据,缺点在于,并不能知道具体是哪些进程在进行磁盘读写。要观察进程的 I/O 情况,我们还可以使用 pidstat 和 iotop 这两个工具。我们首先给pidstat 加上 -d 参数,就可以看到进程的 I/O 情况,如下所示:
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 996 0.00 10.00 0.00 0 rsyslogd
从 pidstat 的输出我们能看到,它可以实时查看每个进程的 I/O 情况,包括下面这些内容。
用户 ID(UID)和进程 ID(PID) 。 每秒读取的数据大小(kB_rd/s) ,单位是 KB。 每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。 每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。 块 I/O 延迟(iodelay),进程在磁盘I/O上被阻塞的时间,包括等待同步块 I/O 和换入块 I/O 结束的时间(时钟周期)。 该进程号的命令Command,可以用来推断应用服务名称。
除了pidstat命令,我们查看要 I/O 压力,还可以使用:iotop。 它是一个类似于 top 的工具,我们可以按照 I/O 大小对进程排序,然后找到 I/O 较大的那些进程。
一般需要手动安装,可以通过iotop 的软件包安装。iotop的默认输出如下所示:
$ iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/ TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald
从这个输出,我们可以看到,前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。 因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等。 剩下的部分,则是从各个角度来分别表示进程的 I/O 情况,包括线程 ID、I/O 优先级、用户及以下参数:
DISK READ:每秒读磁盘的大小 DISK WRITE:每秒写磁盘的大小 SWAPIN:线程花在等待换入I/O的时间百分比 I/O :线程花在等待I/O的时间比
这两个工具,是我们分析磁盘 I/O 性能时最常用到的。我们必须了解它们的功能和指标含义,才能在平常的工作中使用的游刃有余。
5案例排查
1.当我们收到I/O飙升的告警时,登录服务器查看分析。遇事不决,先top。 通过 top 命令查看,因为 top 命令最直接,且信息量够大,覆盖面够全,可以看到 CPU 的 wa 有点高。
CPU 的 wa 是是 wait,是 CPU 等待时间,通常是由于磁盘 IO 问题引起,当然也有可能是网络或者其他原因引起的。
通过 top 命令查看,因为 top 命令最直接,且信息量够大,覆盖面够全,可以看到 CPU 的 wa 有点高。
CPU 的 wa 是是 wait,是 CPU 等待时间,通常是由于磁盘 IO 问题引起,当然也有可能是网络或者其他原因引起的。
2.我们使用iostat命令,使用参数-x,输出详细的磁盘信息。 从 iostat 中能更直观的看到那个磁盘在进行大量的写操作。我们此刻已经确认了磁盘的I/O负载偏高。
从 iostat 中能更直观的看到那个磁盘在进行大量的写操作。我们此刻已经确认了磁盘的I/O负载偏高。
3.我需要判断是哪一个进程在使用磁盘,再使用iotop命令,直观的判断出哪一个进程在进行I/O请求。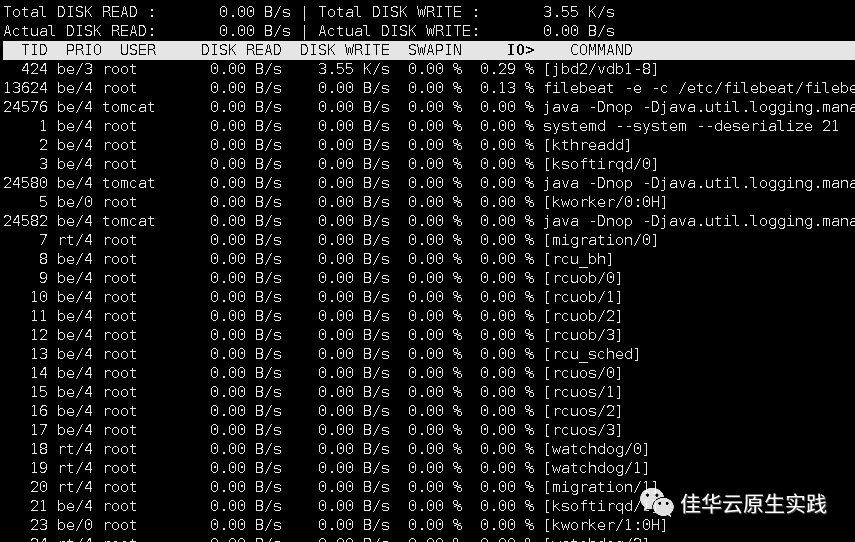
4.得出结论
I/O 升高是由于 jbd2 引起的,jbd2 是一个文件系统的日志功能,为了保证文件系统的完整性,而引入了这么一个日志功能,会将所有的操作写盘记录日志,这也是为什么刚开始分析看到的磁盘写操作频繁。
5.解决方案
最后请示领导,在k8s的无状态的服务中,我们通过挂载参数关掉了jbd2,最终I/O问题解决。(不是所有场景都能关闭。)
6总结
我们梳理了 Linux 磁盘 I/O 的性能指标和性能工具。我们通常用 IOPS、吞吐量、使用率、饱和度以及响应时间等几个指标,来评估磁盘的 I/O 性能。
我们可以用 iostat 、PSI获得磁盘的 I/O 情况,也可以用 pidstat、iotop 等观察进程的 I/O 情况。不过在分析这些性能指标时,我们要注意结合读写比例、I/O 类型以及 I/O 大小等,进行综合分析。
最后我们给出了一个I/O飙升的案例。从排查过程,定位到进程,了解到进程作用,告知领导同意后,关闭该进程,最终解决问题。
