




点击蓝字 关注我们
大家好,我是来自Apache SeaTunnel社区的陈卓宇。今天,我将从四个方面向大家介绍Apache SeaTunnel:项目简介,核心设计理念和架构,如何进行数据同步(通过一个简单的MongoDB到HDFS的数据同步Demo进行演示),以及Apache SeaTunnel对未来云原生化的展望。
文|陈卓宇
编辑整理| 曾辉
讲师介绍

陈卓宇
Apache SeaTunnel 贡献者

第五,同步场景变得越来越复杂,除了离线数据同步,我们现在还有实时同步,包括全量和增量同步。
第六,我们需要关注同步作业的可观测性,包括数据源、目标端的数据量,数据质量,同步速度(QPS)等。
01
项目简介
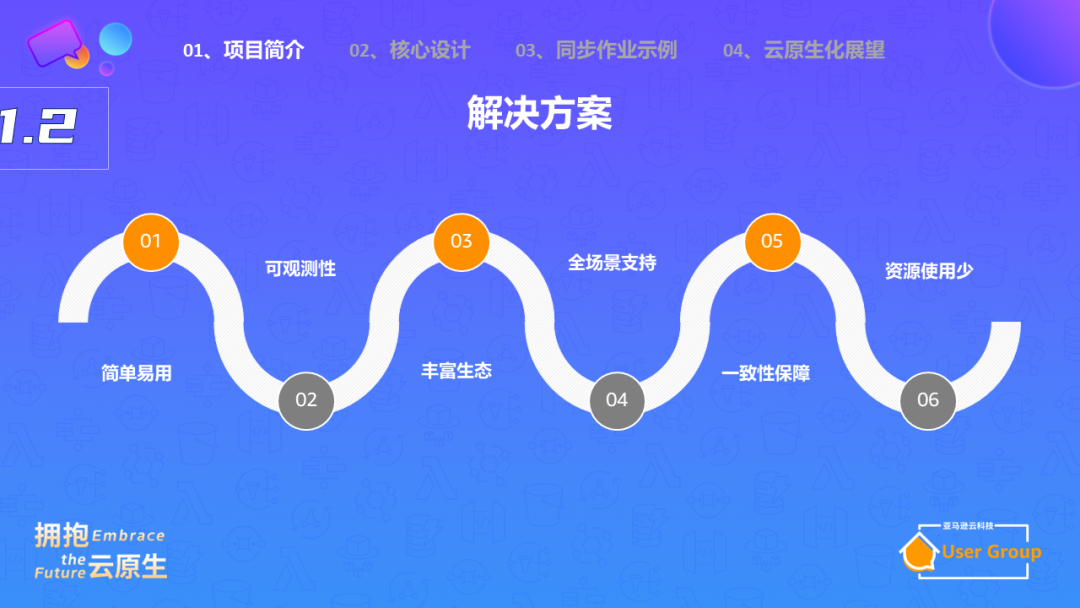
为了解决这些挑战,Apache SeaTunnel提供了六个方面的解决方案:简单易用,可观测性强,支持丰富的生态系统,全面支持各种同步场景,保证实时作业同步的一致性,以及在满足这些需求的同时,尽量减少资源消耗。
Apache SeaTunnel项目起源于2017年的一个名为waterdrop的开源项目,当时的初衷是为了简化使用Flink和Spark进行数据同步的工作。
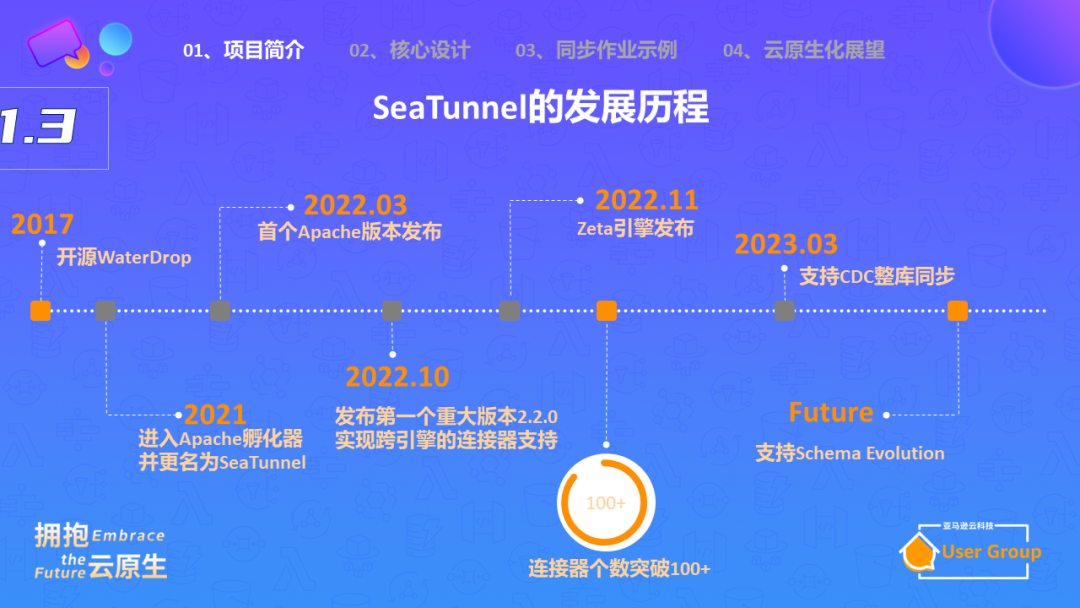
2021年,该项目进入Apache孵化器并更名为Apache SeaTunnel。
2022年,我们发布了第一个版本,并对整个项目进行了重构,目标不再只是作为一个封装工具,而是专注于数据同步这个垂直领域,实现最优化的解决方案。
在2022年末,我们发布了专为数据同步场景量身定制的Zeta引擎,与Flink和Spark的全能型设计不同,我们的目标是在数据同步领域做到极致。
到2023年3月,我们已经支持了整库CDC同步,也就是说,我们可以将一个库中的所有表的数据全量同步到Hive或其他数据平台,并且可以实时同步所有的数据库操作。
下一步,将支持Schema Change Evolution,也就是动态地适应源数据的schema变化。
02
核心设计
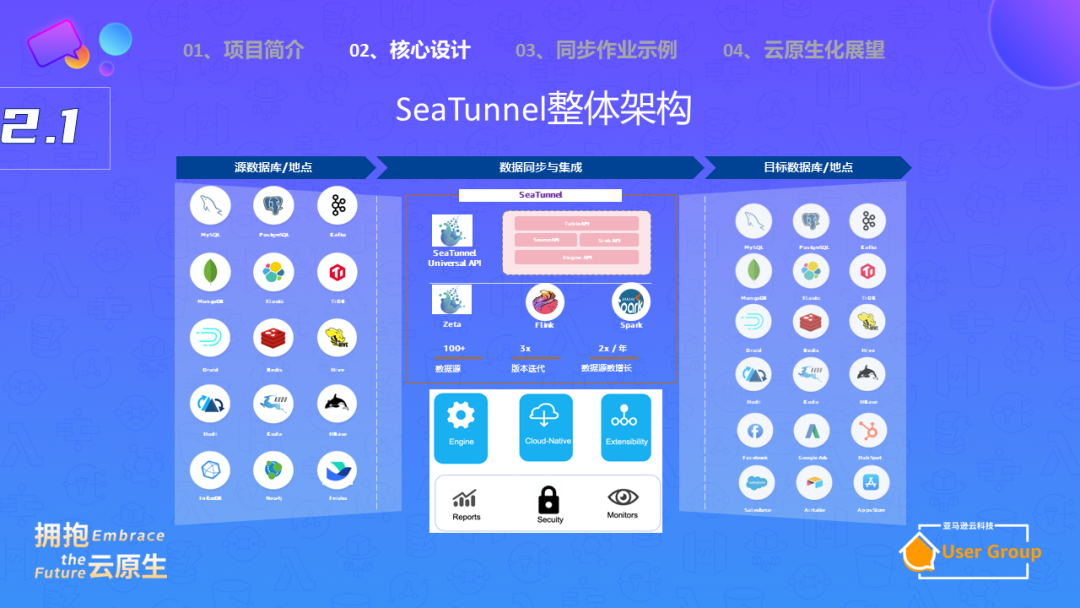
再来说说Apache SeaTunnel的整体架构。下图在左右两边是我们的数据源和数据目标,我们支持多种数据源,如MongoDB,MySQL等,也支持写入到多种目标,如Hive,数据湖等。
中间是我们的引擎,它负责进行数据类型转换,比如将MongoDB的数据类型转换为Apache SeaTunnel的数据类型RowData,再将其转换为MySQL的数据类型写入。
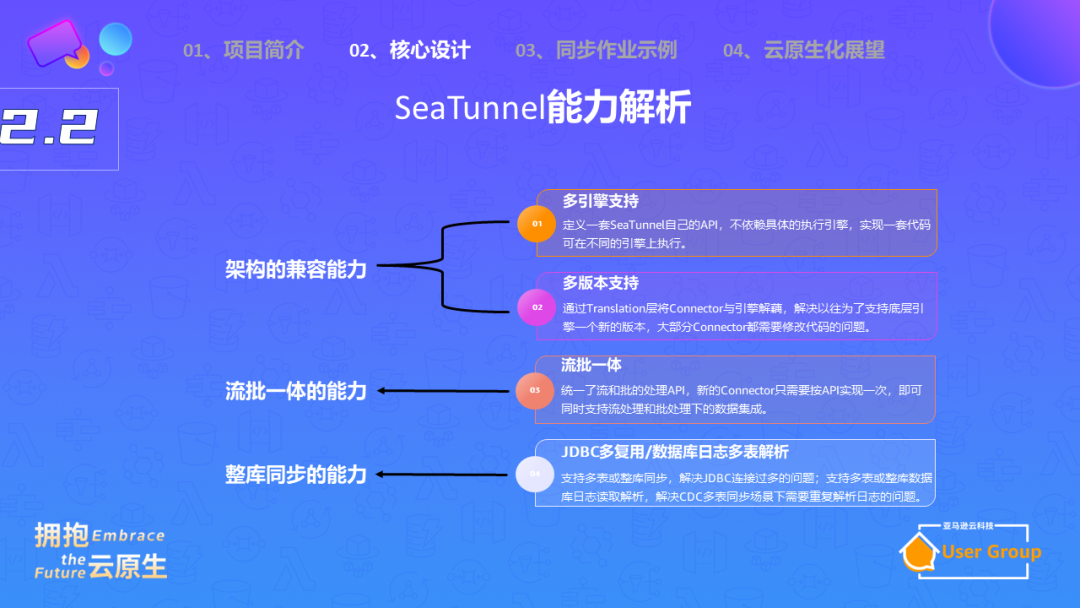
第二点是流批一体的能力,这个主要体现在 API 层面和使用上。
在 API 层面,开发一个新的Connector时,不需要考虑是流还是批,API支持流批一体。
在使用上,如果需要批的同步,只需要加一行配置;如果是流同步的话,系统会不断地监控表的变更,有新的数据时进行实时读取。
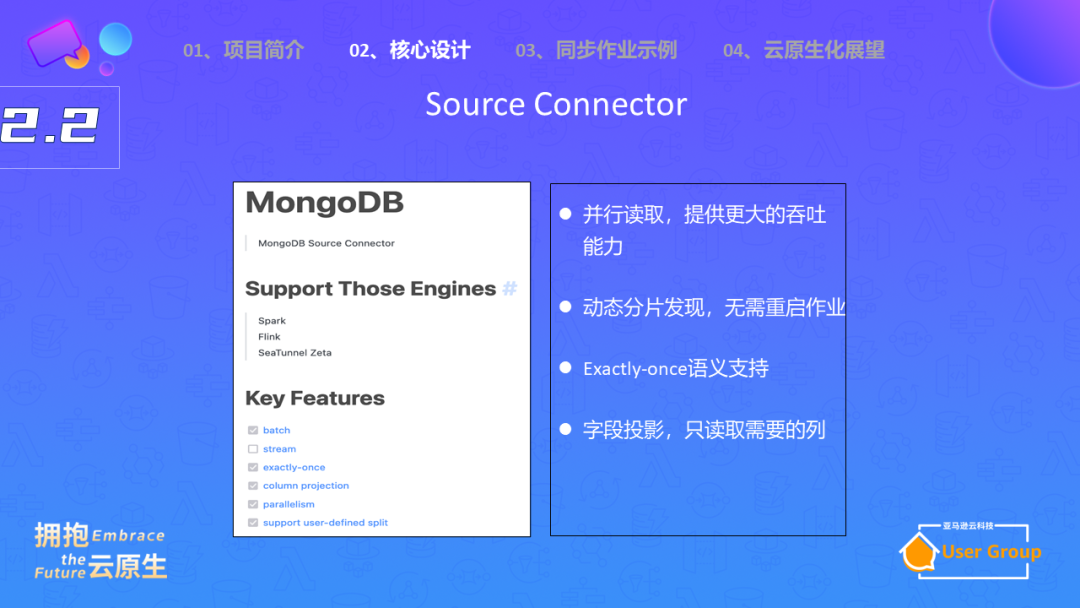
第三点是整库同步的能力。如果要做数据同步,首先需要找到源端的Connector。例如,如果需要同步MongoDB和HDFS,首先需要找到MongoDB的源端Connector。source端连接器的介绍,支持的引擎类型、功能(例如支持批的能力、流的能力、数据一致性保证、字段映射、并行读取能力等)都需要了解。
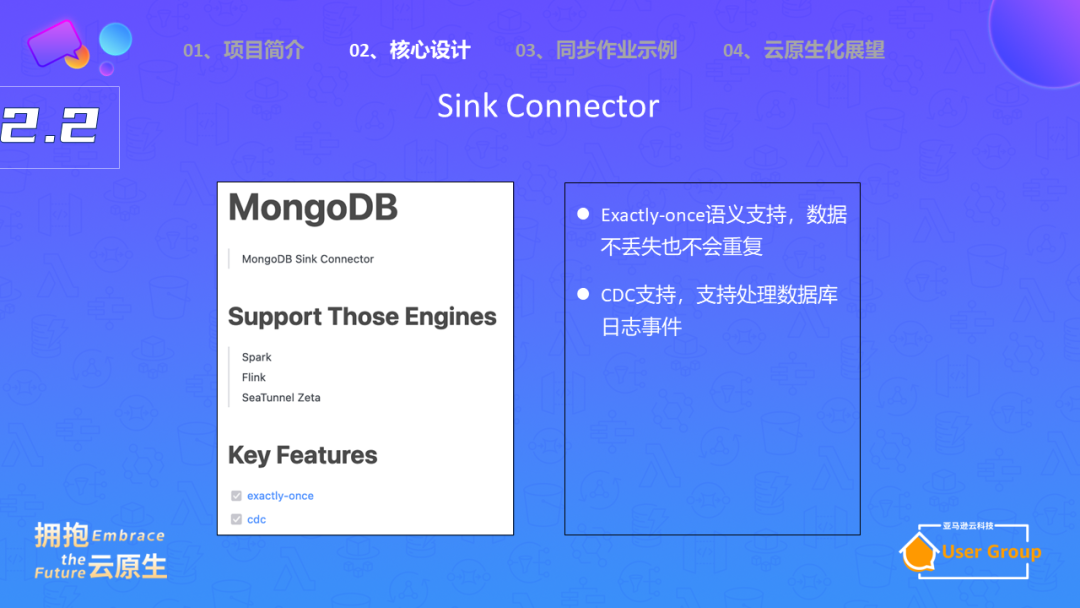
同样,Sink端的连接器也需要了解其支持的引擎类型和功能。

在数据同步过程中,Apache SeaTunnel 提供了一些轻量级的操作,如复制一列到新列、字段改名、替换数据内容、一列拆成两列等,也支持用户自定义一些UDF接口。
CDC(Change Data Capture)是 Apache SeaTunnel 未来重点支持的功能。它可以极大程度上降低同步成本。
通过 CDC,可以实时捕获并同步数据库的变更,从而提高数据实时性和系统效率。CDC 支持基于事件的写,能根据源端的变更立即更新,例如当源端进行插入或更新操作时,可以立即进行相应的操作。
Apache SeaTunnel 遵循小 t 原则,即在数据同步过程中进行轻量级的处理,而将聚合等重量级操作放在数据仓库层面完成。这样可以减少数据同步的时间,提高系统效率。
在处理变更数据捕获(CDC)时,我们经常遇到一些挑战。首先,你需要进行全量和增量同步。例如,你可能需要先扫描目标数据库,将所有数据读取过来,同时持续捕获新的数据变动。这被称为全量增量一体化模式,我们需要实现这个模式。
第二个挑战是需要支持分库分表的场景。
此外,第三个挑战是处理Schema Change Evolution的问题。
在实时作业中,任务是7*24小时持续运行的,不能停止,否则就可能导致数据不准确或丢失。Schema Change Evolution能够解决由于业务调整(如新增列或减少列)导致的数据问题,无论业务如何变动,都能确保数据的完整性。
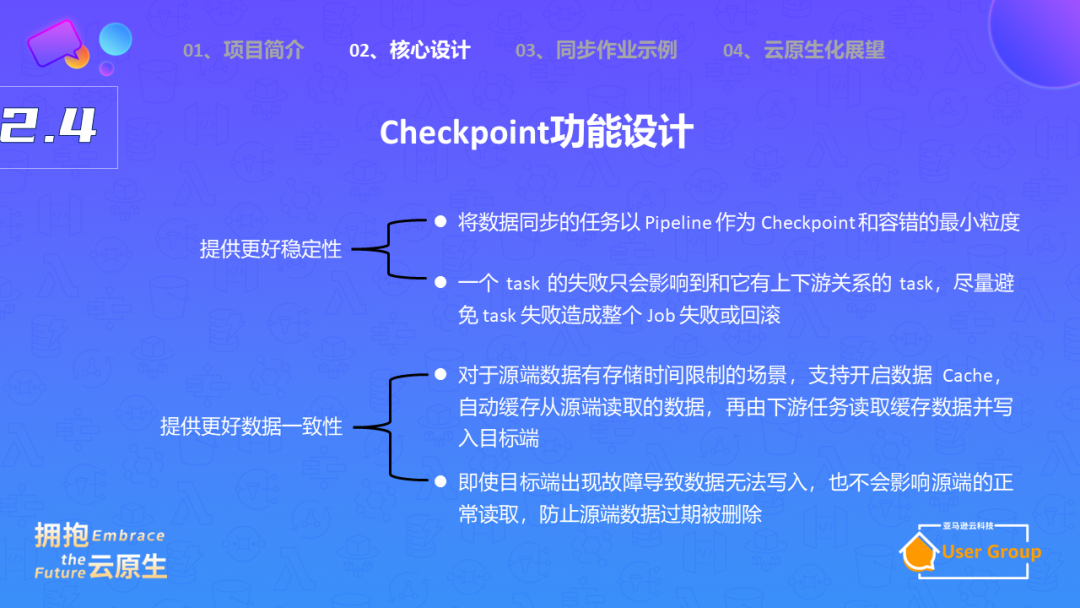
另外,需要支持checkpoint流程。在实时服务中,数据同步是关键,而且必须具有高可用性,不能出现故障。如果数据同步任务突然挂起一小时,那么数据的准确性就会受到影响。
这时候,checkpoint就派上了用场。你可以在某个时间点设置一个checkpoint,像拍照一样保存状态,然后将状态存储在第三方库(如HDFS)中。如果后续出现故障,你可以回滚到checkpoint的状态,重新开始数据同步。
在CDC中,我们可以读取MySQL的binlog日志,将MySQL视为Kafka这样的消息中间件。我们可以通过offset进行回滚,如果发现数据丢失或者重复,可以回滚到某个时间点,补回丢失的数据。我们可以在checkpoint中保存这个offset,当程序重新开始运行时,我们读取这个offset,然后继续从MySQL的binlog日志中读取数据,从而补回丢失的数据或回滚数据。
为了保证下游数据不会重复,我们可以通过两阶段提交来实现。在完成checkpoint后,我们会提交写入操作,从而确保源端和目标端都不会丢失数据,也不会出现重复数据。Zeta引擎其他引擎相比,CDC功能有一些优化点,Zata引擎使用pipeline作为checkpoint的最小容错单位,提高了系统的稳定性。
此外,如果源端数据存储时间受到限制,它支持开启缓存操作,先将数据缓存住,如果目标端出现故障无法写入,也不会影响源端数据的读取,从而防止源端数据过期被删除。
另一方面,我们需要能够查询任务进度,而且需要有多种指标可以查看。在程序运行中,会有日志输出,例如job ID,用于区分在同一个服务中运行的多个实时同步作业。同时,日志还会显示读写的数据条数,以及平均的QPS。最后,它还会记录统计时间。
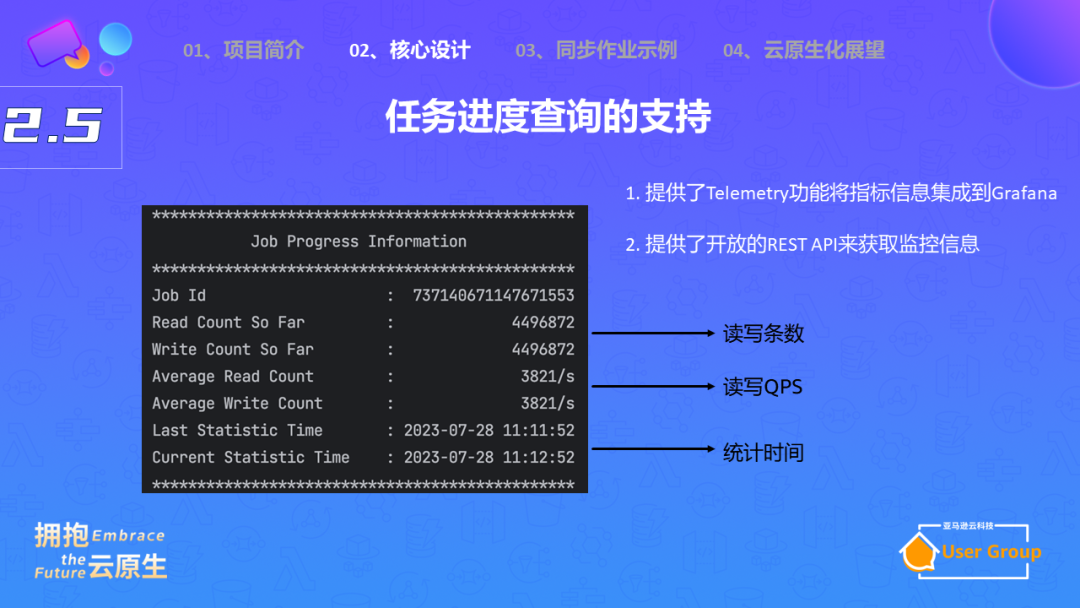
但是,通过日志查看这些数据并不是最优雅的方法。我们还可以通过Telemetry的方式,将数据集成到Grafana中,通过普罗米修注册exporter来暴露这些指标,包括服务的指标,数据同步进度的指标。
你还可以通过rest API获取这些指标,拿到这些指标后,你可以建立一个数据大盘,进行监控。
03
同步作业示例
最后,我将展示如何使用Apache SeaTunnel配置数据同步作业。
首先,你需要配置源端和目标端的信息。例如,如果你要从MongoDB同步数据,你需要在外层设置Source标识,并指定MongoDB作为数据源,然后写入MongoDB的连接字符串,以及需要同步的集合名称。
另外,你还可以选择是否将boson打成json格式,方便处理MongoDB可能发生的schema变更问题。

在Sink配置中,你需要设置HDFS的文件地址,指定存储路径,还可以设置是否写入分区,选择存储格式(例如ORC格式),并确定是否开启事务,即前面提到的两阶段提交,保证数据不会丢失,也不会重复。

最后,你还需要配置环境信息,例如执行模式,以及checkpoint的间隔时间。

配置好后,你可以提交脚本,将配置信息放入configure文件中,然后执行脚本,按照部署模式进行服务启动。

另外,我们在社区还开发了一个新项目,叫做SeaTunnel Web。这个项目使得我们可以通过Web界面进行模块配置,例如源模块、MongoDB模块、HDFS模块等,通过拖拽和连线,就可以完成数据同步任务的构建。
04
未来展望
在未来,Apache SeaTunnel 的目标之一是实现云原生化。
Apache SeaTunnel计划在 Kubernetes 上实现。在现有的Standalone模式下,SeaTunnel的部署很简单,无需Kubernetes这种资源管理器。
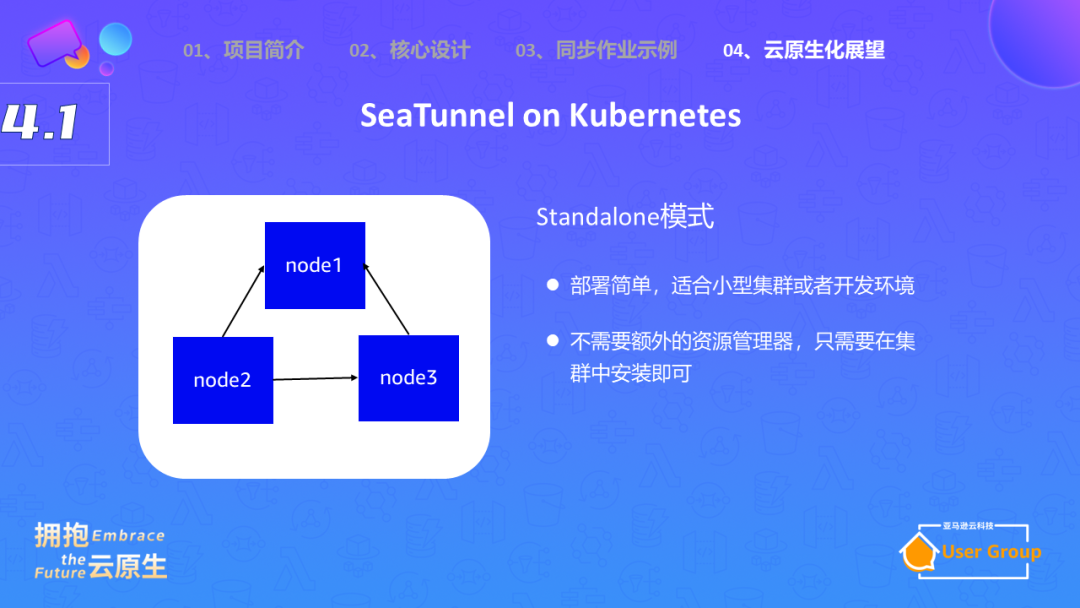
然而,这种模式的问题在于,当任务不运行时,所占用的资源无法被其他服务使用。对于一个公司来说,如果有大量的数据同步任务,那么就需要分配大量的机器,而这些机器在任务不运行时会闲置,这种资源浪费是不可接受的。
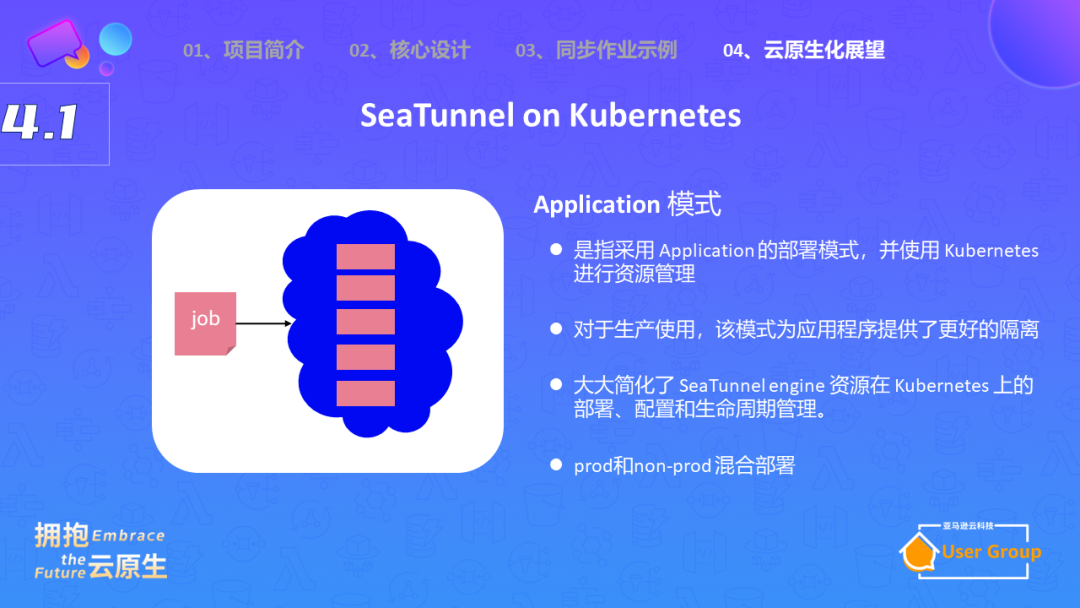
为了解决这个问题,我们提出了在Kubernetes上实现SeaTunnel的想法。在这个模式下,每一个任务对应一个Deployment。这种模式不仅提供了良好的隔离性,而且可以更好地管理任务的生命周期。
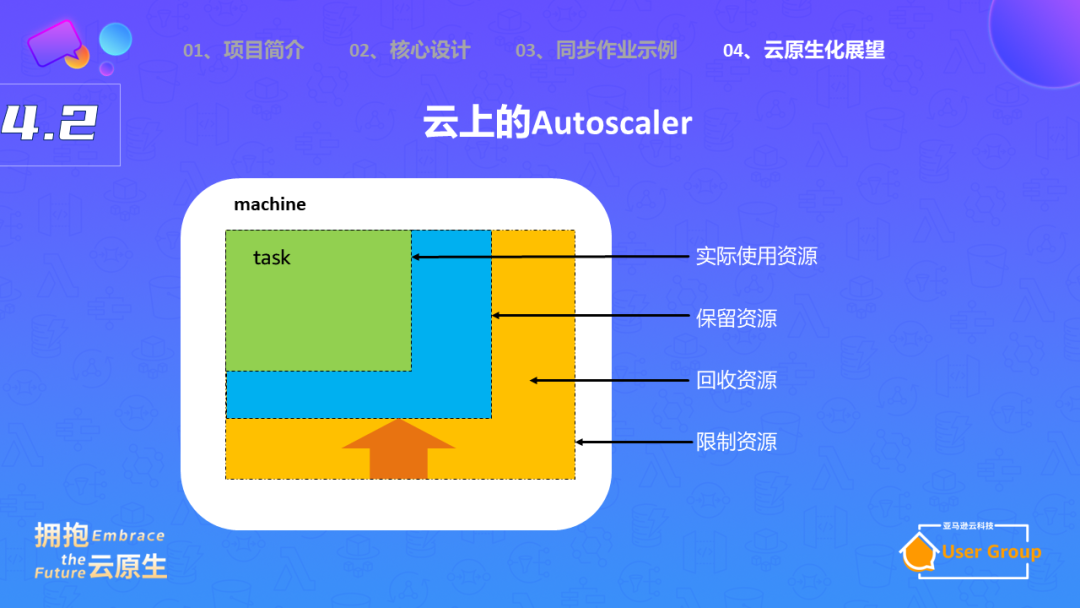
在Kubernetes的支持下,SeaTunnel还可以实现动态扩缩容。对于批处理任务,我们可以根据数据量自动进行并行度计算。对于实时任务,我们可以根据数据流量动态调整节点数量(横向扩缩容),或者根据CPU和内存的使用情况动态调整资源配额(纵向扩缩容)。
这样,我们可以确保资源的充分利用,提高处理效率,同时减少资源浪费。
总的来说,Apache SeaTunnel的目标是实现云原生化,以支持在Kubernetes上运行,并实现动态扩缩容,以更好地利用资源,提高处理效率。我们希望这种改进可以为用户提供更加便捷、高效的服务。
Apache SeaTunnel
精彩推荐
一键三连-点赞在看转发⭐️!

