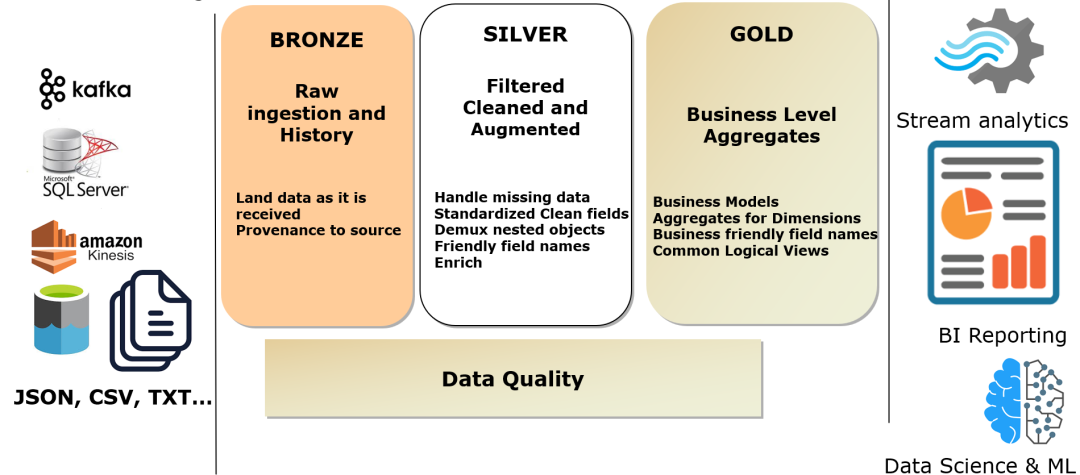
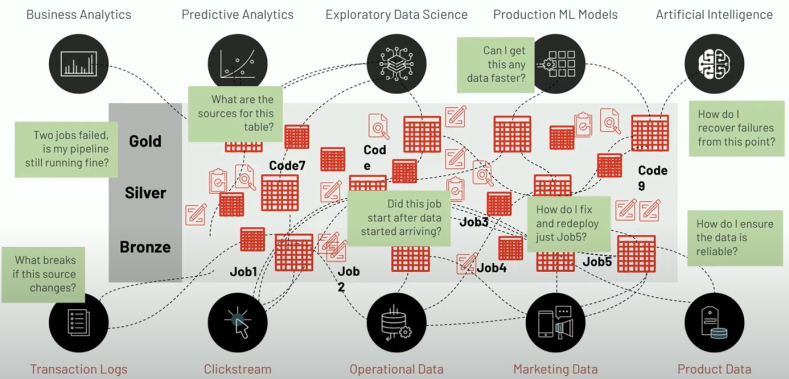
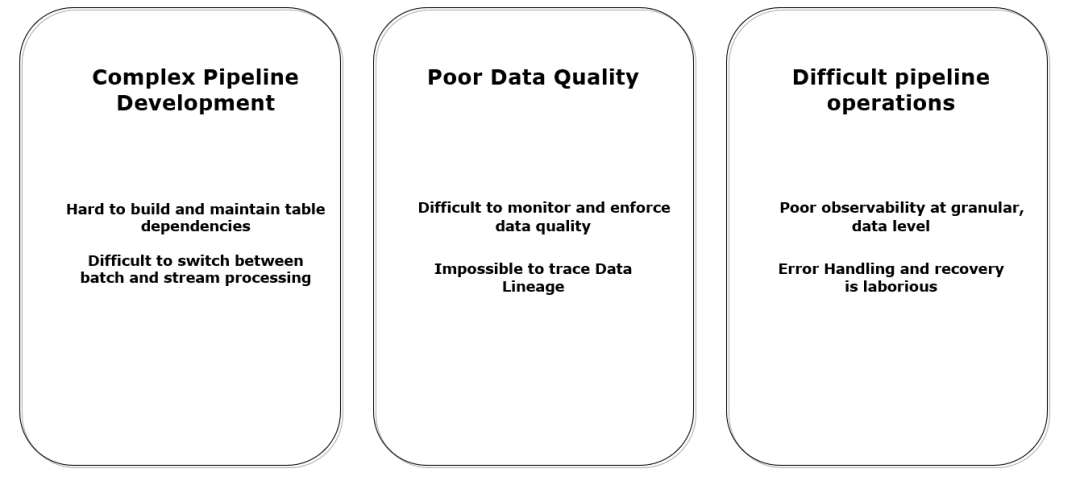
通过流计算或批处理进行 ETL 是数据分析、数据科学和机器学习常规诉求,在将企业日常产生的原始、非结构化数据转化为干净、完整且高质量信息之前,需要进行关键的步骤,以便用于推动业务洞察力。从实践上看,无论是通过代码,还是 SQL 来设计 ETL 流水线都会涉及大量繁琐、复杂的操作工作,特别是流式和批计算混合的场景,即使在小规模下,数据工程师的大部分时间往往更多是花在工具和基础设施管理上,而不是数据流转上。从用户反馈看,流批混合的数据加工可观察性和治理难以实施,因而对这类对时效性有更高要求的治理往往被完全忽略。过去我们从大量客户的生产实践中有大量因为口径不一致,数据不统一而产生的治理难题,这些治理的问题最终导致了数据不可信、不可靠和成本高昂。面向这类问题,Databricks 新提出了 Delta Live Table(DLT),目标是使用简单声明性方法构建可靠数据流水线并自动管理基础设施的 ETL 框架,因此数据分析师和工程师可以在工具上花费更少的时间,并专注于从数据中获得价值。特别针对流批混合的场景,DLT 允许数据工程师和分析师通过加速开发和自动化复杂的操作任务来大大减少实施时间。值得一提的是,DLT 不是类似于 Delta/Iceberg/Hudi 这样基础格式的定位,而是 Databricks Lakehouse 平台工具中的特性,涵盖了数据开发和数据治理的一系列功能,DLT 相当于数据研发中流批一体的开发模块,并且在开发流程中嵌入了数据治理的能力。Delta Live Tables (DLT) 已经在亚马逊 AWS 和微软 Azure 云上正式推出(GA),并且在谷歌云上公开提供。在 Databricks 官网介绍中,号称 DLT 已经接入超过 400 家公司,包括 ADP、Shell、H&R Block、Jumbo、Bread Finance、JLL 等[1]。对于 Data pipeline,databricks 给出了一个较为普适的图来说明[2]:Databricks 将数据加工大致分了三层,分别对应国内讲得比较多的 ODS,DWD 和 DWS 数据。而在这样泛化的数据管道中,保持数据质量和可靠性非常复杂,主要原因在于:- 如果 Pipeline 一个环节失败,会影响下游系统和依赖它的团队
- 需要耗费大量的工作将 SQL 转换为 ETL pipeline
针对这三点现状和三点问题,Databricks 需要开发一个产品至少具备三点特性:
- 简单的开发和维护:使用声明性工具开发和管理数据管道,并且同时适用于批处理和流计算
- 自动测试:内置质量控制和数据质量监控,实现自动化测试,以更好支持 CICD 等软件最佳时间
- 简化运维:通过提供更加深入的自动优化、自动伸缩和容错技术,实现简化运维
从官方的介绍中,我总结了 DLT 以下 4 个核心特性,基本解决了上面提出的问题[3]:通过自我优化和自动伸缩的数据处理架构,为应用程序提供最实时新鲜的数据,并且为工程师提供最具性价比的技术方案。与其他数据产品强制用户使用不同的产品开发流计算任务和批处理任务。DLT 在流批一体上最核心的创新在于研发层面尽可能地统一了流和批的开发范式,仅仅在调度等有限的配置层面,保留了让用户选择流还是批来执行加工任务。
与需要手动编写代码片段来构建端到端 pipeline 的解决方案不同,DLT 使得可以用 SQL 和 Python 声明性地表达整个数据流。此外,DLT 支持现代软件工程最佳实践,比如能够在与生产环境分开的环境中进行开发,能够在部署前轻松测试,使用参数化部署和管理环境,进行单元测试和文档化。因此,用户可以使用简洁先进的构造来表达数据流转,CI/CD,SLA 和质量期望,无缝地进行批处理和流计算,并简化 ETL pipeline 的开发、测试、部署、运营和监控。
DLT 从底层开始构建,支持基础架构自动化管理。根据不断变化和不可预测的数据量来调整集群大小,以实现最佳性能。DLT 通过为用户提供设置最小和最大并发让 DLT 根据资源利用情况调整集群大小以自动扩展计算资源满足性能和 SLA。此外,DLT 支持自动编排、恢复和容错,有了 DLT,用户可以专注于数据流转,而不是运营。DLT 通过内置的质量控制、测试、监控和执行来提供可靠的数据,以更加有效地支持对准确性要求更高的 BI、数据科学和 AI。DLT 通过名为 Expectations 的功能,让创建可信数据变得更加容易,Expectations 有助于防止不良数据流入表格,跟踪数据质量随时间的变化,并提供工具来排除不良数据,让 Data pipeline 具备更细粒度的可观测性,用户可以获得 Data pipeline 的高保真谱系图,跟踪依赖关系,并聚合数据质量指标。Delta Live Tables 是一个声明性框架,用于构建可靠、可维护和可测试的数据处理管道(以下统称 pipeline)。用户定义要对数据执行的转换,Delta Live Tables 则管理任务编排、集群管理、监控、数据质量和错误处理。
与使用一系列独立的 Apache Spark 任务定义 pipeline 不同,用户可以用 DLT 定义流表和物化视图,一个典型的 pipeline 或 workflow 由这些流表,物化视图以及定义这些 Table 的转换方式构成,完成 pipeline 后 DLT 就会负责创建和保持这些表的数据更新。用户还可以通过 Delta Live Tables 的 Expectations 来强制执行数据质量,允许用户定义期望的数据质量并指定如何处理未达到这些期望的记录。Delta live tables 包含三种类型(统一叫 dataset),这里直接引用官方的定义[4]:View 的特性是在每次计算中生成,不会持续占用的存储资源,视图不会发布到 UnityCatalog 中,因此视图只能在 pipeline 内引用,考虑使用视图的情况:- 如果有一个大型或复杂的计算,想将其分解为易于管理的计算时
- 当你想使用 Expectations 语法来验证中间结果时,建议通过配置 Expectations 为下游提供高质量数据
- 如果想减少存储和计算成本,可以考虑用视图代替物化视图。因为物化需要额外的计算和存续资源
物化视图也叫 Live Table,是预先计算的视图。物化视图根据声明的计算逻辑进行刷新。它们可以处理输入中的任何更改。每次 pipeline 有数据更新时,查询结果会重新计算以反映可能由合规性、更正、聚合或一般 CDC 引起的上游数据集中的更改。Delta Live Tables 通过 Delta 表实现物化视图,但抽象出了与数据更新相关的复杂性,允许用户专注于编写计算和转换逻辑。考虑使用物化视图的情况:- 当多个下游查询使用该表时,因为视图是按需计算的,每次查询视图时都会重新计算视图
- 当其他 pipeline、作业或计算使用该表时,需要物化视图,因为视图没有被物化,所以只能在同一管道中使用它们
- 当你想在开发过程中查看计算结果。如果表是物化的,可以在管道之外查看和计算,所以在开发过程中使用物化视图可以帮助验证计算的正确性。验证后,可将不需要物化的物化视图转换为视图
Streaming table 是物化视图的一种增强,是在 live table 的基础上对流计算和增量处理做了特殊的优化,这点对理解 DLT 的流批一体至关重要,DLT 的流表只能应用于 append-only 的数据集,如果是 CDC 数据,Databricks 提供了一个 APPLY CHANGES INTO 的语法来代替复杂的 Merge into SQL,考虑使用流表的情况[2]:
- 当需要高吞吐量和低延迟的 data pipeline
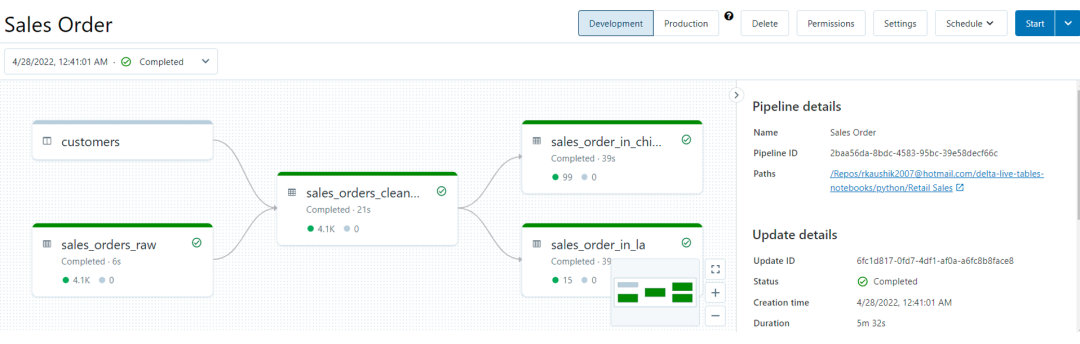
Pipeline 是用于配置和运行 Delta Live Tables 数据处理工作流程的主要单元。在 Databricks 中,pipeline 展示为一个将数据源连接到目标端(源和目标都可能不止一个)的有向无环图,如下图所示[2]:Pipeline 包含在 Python 或 SQL 源文件中声明的物化视图和流表。DLT 会推断这些表之间的依赖关系,确保更新以正确的顺序进行。对于 dataset,Delta Live Tables 将当前状态与期望状态进行比较,并使用高效的处理方法创建或更新数据集。DLT pipeline 设置分为两部分内容:
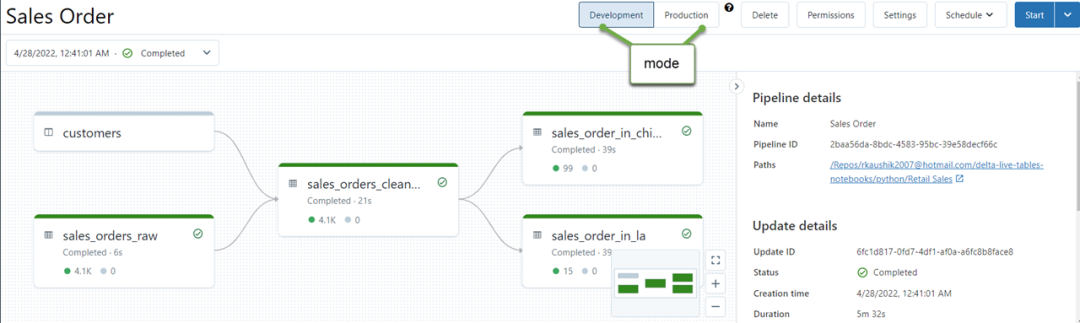
- 定义一组 Notebook(IDE 中保存的代码记录)或文件(称为源代码或库),这些笔记本或文件使用 DLT 语法声明 dataset 的配置
- 配置 pipeline 的基础架构、如何处理更新以及如何保存 DLT Table 在工作区的配置。
更多 pipeline 配置相关的内容参考 DLT 实践中的章节。在 DLT 中,所有计算逻辑理论都应该用声明式语言创建和维护,所有 SQL 语句都使用 CREATE OR REFRESH 定义 Delta live table。当 pipeline 有数据更新时,DLT 判断是否可以通过增量处理实现表的正确结果,还是需要进行完全重新计算[5]。以下示例通过从对象存储中加载 JSON 文件来创建表:CREATE OR REFRESH LIVE TABLE clickstream_raw
COMMENT "The raw wikipedia clickstream dataset, ingested from databricks-datasets."
AS SELECT * FROM json.`/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/2015_2_clickstream.json`;
物化视图是使用 live virtual 模式从当前 DLT pipeline 中声明的其他数据集中计算生成数据。以这种方式声明新表会创建一个依赖关系,Delta Live Tables 自动更新维护数据。Live 模式是 DLT 实现的自定义关键字,如果想要发布数据集给其他 pipeline,需要在 pipeline 配置中配置目标 schema 和 metastore 地址。以下代码还包括了使用 Expectations 监控和强制执行数据质量的示例:CREATE OR REFRESH LIVE TABLE clickstream_prepared(
CONSTRAINT valid_current_page EXPECT (current_page_title IS NOT NULL),
CONSTRAINT valid_count EXPECT (click_count > 0) ON VIOLATION FAIL UPDATE
)
COMMENT "Wikipedia clickstream data cleaned and prepared for analysis."
AS SELECT
curr_title AS current_page_title,
CAST(n AS INT) AS click_count,
prev_title AS previous_page_title
FROM live.clickstream_raw;
DLT 的流表既可以流式或增量使用,也可以作为物化视图使用,从而可以方便地将一张流表当做批表来用,比如下面的用例:CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM cloud_files(
"abfss://path/to/raw/data", "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(LIVE.streaming_bronze) WHERE...
CREATE OR REFRESH LIVE TABLE live_gold
AS SELECT count(*) FROM LIVE.streaming_silver GROUP BY user_id
为了便于理解,上面的过程首先通过对象存储中的文件创建了一张 ODS 表,对它进行简单的过滤,生成一张 DWD 的流表,之后基于这张流表生成一个聚合的 ADS 物化视图,在最后一个步骤中,将流表当成一张物化视图来使用,从而可以聚合所有历史数据。在 Amoro 实践中,我们也大量遇到了流表当做批量来应用的场景,通过将流表和物化视图声明到一个 pipeline 中,可以极大程度简化 pipeline 逻辑,如果没有 DLT,数据工程师不得不在两套 pipeline 逻辑中分别操作流表和批表,并且在生产中可能会引入更多没必要的数据摄入。除了流表到批表的的转换,DLT 也支持将 live table 当做维表来和 streaming table 实现我们常说的实时维表 join:CREATE OR REFRESH STREAMING TABLE customer_salesAS SELECT * FROM STREAM(LIVE.sales)INNER JOIN LEFT LIVE.customers USING (customer_id)
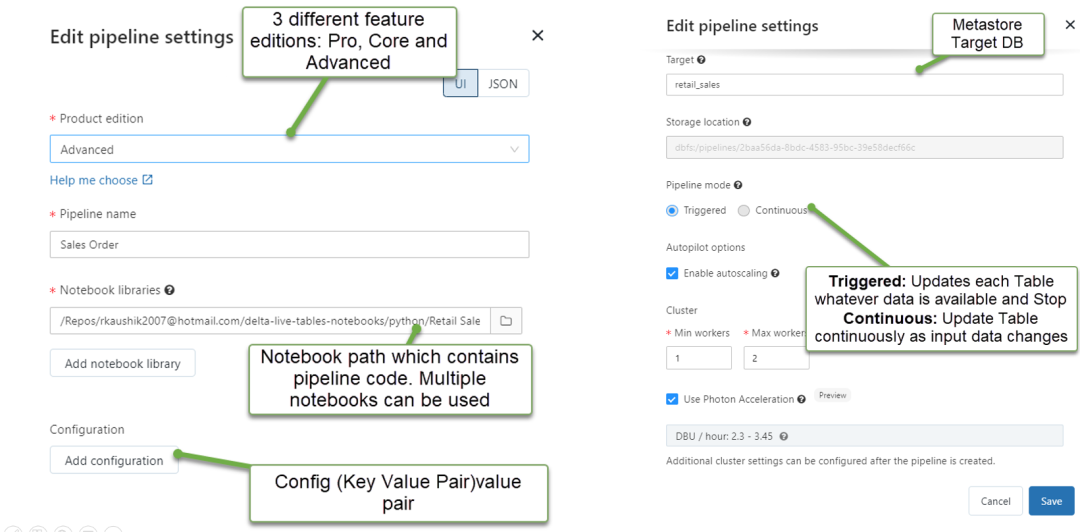
不过目前 live table 作维表只能当静态数据来用,如果 live table 有新的更新,除非手动执行一个 refresh,否则不会反应到持续计算的 pipeline 中。DLT 的 streaming 特性依托于 struct streaming,功能性方面或许不如 Flink。1. Pipeline 配置在 Pipeline settings 页面中定义和更改,例如 Notebook、目标数据库、运行模式、集群配置和 Properties 配置,以下是典型 Pipeline settings 的示例[2]:大多数配置都是可选的,但某些配置需要特别注意,特别是在配置生产 pipeline 时。这些配置包括以下内容:- 要使数据在 pipeline 外可用,必须声明目标 schema 以发布到 HiveMetastore 或声明目标 Catalog 和目标 Schema 以发布到 UnityCatalog。
- 数据访问权限需要在集群中配置,确保集群已为数据源和目标存储位置(如果指定)配置了适当的权限。
- 开发模式:重新集群以避免重启,并禁用管道重试以检测和修复错误
- 生产模式:对于可恢复的错误(例如内存泄漏或过期的凭据),重新启动集群。在特定错误的情况下重新执行
Delta Live 能够理解源数据集之间的依赖关系,并提供了一种非常简单的机制来部署和使用 data pipeline:- Live Table 能够理解并维护 Data pipeline 中的所有数据依赖关系
- 使用 SQL、Python 或 Scala 以声明方式构建具有业务逻辑和链式表依赖关系的数据管道
- Data pipeline settings 中可以轻松配置批处理或流处理模式运行
- 用户可以选择在本地 IDE 或 Databricks Notebook 中面向 DLT 进行开发,再在 databricks 中配置 data pipeline
根据行业最佳实践,如果将数据视为代码,会更加易于维护,并为开发提供更多灵活性。更改代码将重塑数据。- 而且可以使用 Delta expectations 防止错误数据流入表格
- 使用预定义的错误策略(FAIL、DROP 或 QUARANTINE 数据)检测和处理质量的错误
- 自动维护 pipeline 运行期间的血缘,并且支持可视化查询时间日志和 pipeline 血缘关系
Delta Live 表提供自动错误处理,并且很容易重新计算 data pipeline,因此可以显著减少停机时间。它还消除了一定的运维需求,因为 Delta 表可以自动执行一系列运维操作。- 降低停机时间:通过自动错误处理和简单重放,有助于减少停机时间。
- 减少运维:Databricks Delta Lake 自动优化 Delta Live 表以及为用户自动伸缩资源,减少优化开销。
本文较为详细地介绍了 DLT 诞生的背景、目标和能力,并且通过实践介绍了它在产品层面强大的功能。总体来说,Delta Live Table 是一个非常理想的流批一体的解决方案,官方对它是这么定义的:Delta Live Tables is a declarative framework for building reliable, maintainable, and testable data processing pipelines.
本质上说,DLT 不是一个产品,而更多的是一个基础软件,如果我们深入去理解它的能力,会发现它在数据优化、自动伸缩、流批一体方面构建了一套基础能力,DLT 把这些能力打包成一个独特的领域,并且为这个领域量身定制了声明式的语言,这正是 DDD 和 DSL 的最佳实践,从我的视角来看,Databricks 真正做到了用有限的、小而美的技术和产品为客户的应用场景提供了无限的想象空间,而这得益于 Databricks 在基础软件多年沉淀下来的思考和实践,以及基础架构师在产品设计上的强大领导力。这里我简单总结一下 DLT 凭什么让产品用简单的功能形态来支持流批一体:- DLT 让用户可以在代码、SQL、Notebook(IDE)中用声明式语言分别定义流表和批表,只需要通过 streaming, live 等关键字即可让用户传达他想要的场景
- Pipeline 或 workflow 中依赖关系是通过 DLT 的定义自动生成的,所有 pipeline 的节点都是 DLT 表,DLT 的方法论遵循了 Data as code 的理念。而大部分平台由用户显示管理依赖关系,每个节点的含义由用户自己解释,而这样的方法无法适用在流场景,在用户体验上天然存在巨大的割裂
- Pipeline 层面在使用,配置和用户指导上不存在流和批的差异,这些差异隐藏在了简单的 DLT 声明式语言中。但是 pipeline 确实保留了由用户决定流还是批的顶层触发模式
- 虽然 Spark 中依然没有主键定义,DLT 提供了一些关键的语法来实现类似的功能(apply change to)
- DLT 可以像 Amoro 一样对流表进行自动优化,比如小文件合并,还支持自动伸缩和自动化测试
从这次调研中我个人最大的感悟是:一家成功的 2B 公司,需要用领先的软件实践来支撑和引导客户的软件实践,回看 Oracle 等 2B 巨头,莫不如是。
[1] https://www.databricks.com/blog/2022/06/29/delta-live-tables-announces-new-capabilities-and-performance-optimizations.html[2] https://rajanieshkaushikk.com/2022/06/24/why-the-databricks-delta-live-tables-are-the-next-big-thing/[3] https://www.databricks.com/blog/2022/04/05/announcing-generally-availability-of-databricks-delta-live-tables-dlt.html[4] https://learn.microsoft.com/en-us/azure/databricks/delta-live-tables/[5] https://learn.microsoft.com/en-us/azure/databricks/delta-live-tables/tutorial-sql