




2023年8月24日消息,Neo4j 在其核心数据库功能中添加了向量搜索和向量存储,以帮助客户从语义搜索和生成人工智能应用程序中获得更好的结果。

此外,该供应商的目标是通过添加向量搜索和存储作为核心功能,减少人工智能的“幻觉”——人工智能产生的不准确和误导性的响应。
向量搜索是一种搜索非结构化数据(例如文本和图像)的方法,方法是为其分配数字表示形式以赋予其结构。一旦分配了数值,非结构化数据就可以用于语义搜索,因此用户可以使用近似最近邻算法找到相似的数据,并最终对相似的数据进行建模以告知决策。
关键词搜索同样试图发现相似的数据。然而,根据 Neo4j 的说法,向量搜索可以提供更快、更相关的结果。
此外,客户可以通过使用向量索引以前的非结构化数据来提高生成人工智能模型和语义搜索的准确性。语言模型和语义搜索倾向于支持最新数据,用户可以应用可能被生成人工智能模型和语义搜索忽略的索引数据来提高其准确性。
Neo4j 总部位于加利福尼亚州圣马特奥,是一家图形数据库供应商,其平台使客户能够以与传统关系数据库不同的方式访问和使用数据。
图形数据库简化了数据点之间的连接,使其能够一次与多个其他数据点连接,从而更快地发现和组合来自多个来源的数据,并加快将数据转化为见解和行动的过程。关系数据库使数据点一次只能连接到另一个数据点。
除了Neo4j之外,TigerGraph是图数据库专家,而AWS和Oracle等科技巨头也提供图数据库。
新功能
6 月,Neo4j 推出了与 Google Vertex AI 的集成,使用户能够通过生成式 AI 改进他们的知识图谱。
通过集成,Neo4j 客户现在可以使用自然语言而不是代码与知识图进行交互,使用Vertex AI将非结构化数据转换为知识图,通过生成式 AI 丰富现有知识图,并验证大型语言模型 (LLM) 的响应,以确保幻觉不会导致基于错误数据的决策。
Neo4j 建立在通过与 Vertex AI 集成以及通过与 OpenAI、微软和 AWS 的持续合作而添加的生成式 AI 功能的基础上,于 8 月 22 日在其核心数据库功能中添加了向量搜索。
向量搜索本身并不是一种生成式人工智能功能。但它提高了生成人工智能模型和语义搜索的准确性。
Constellation Research 分析师 Doug Henschen 表示,出于这个原因,向量搜索是Neo4j 核心功能的重要补充。
“数据库供应商和客户之间显然有一个广泛的认识,即向量搜索功能应该成为客户已经用来管理数据的数据库中的一个功能,”他说。“这一功能将为 Neo4j 客户提供一个机会来告知和提高语义搜索和生成人工智能功能的准确性。”
然而,Neo4j 并不是唯一添加向量搜索的公司,Henschen 继续说道。
鉴于向量搜索提高了语义搜索和生成式人工智能应用的准确性,而且 ChatGPT 和 Google Bard 等法学硕士有时会出现幻觉并面临安全风险,因此许多数据库供应商正在将向量搜索作为核心功能。
Henschen 指出,阿里巴巴、AWS、Cassandra、Cockroach Labs、DataStax 和Dremio等公司已经将向量搜索添加到其数据库功能中,并且更多供应商正在开发向量搜索功能。
“通过宣布这一功能,Neo4j 加入了一个快速扩张的数据库和数据平台公司集团,这些公司最近发布或即将发布向量搜索相关的公告,”他说。
Neo4j 首席产品官 Sudhir Hasbe 表示,Neo4j 必须做出的关键决策之一是,是否将向量搜索和存储作为其现有数据库的核心功能,或者开发一个专门用于向量搜索和存储的新数据库。
在认识到人们对生成式人工智能日益增长的兴趣后,Neo4j 咨询了大约十几家主要客户,并征求他们对如何整合生成式人工智能的意见。
哈斯贝说,客户告诉供应商他们想使用自然语言来询问他们的知识图问题。他们希望 Neo4j 在与生成式 AI 供应商集成方面保持不可知论。他们希望他们的生成式人工智能模型能够拥有向量存储提供的长期记忆,而不是仅使用最近的数据进行训练。
他们希望这一切都集中在一处。
“我们不得不问向量数据库是否应该是一个不同的类别,或者它是否应该是现有数据库的一个功能,”哈斯贝说。“根据反馈,让向量搜索成为我们数据库的一个功能是有意义的,您可以利用显式关系和隐式相似性并将它们组合成一个用例。保持不同的环境似乎不是正确的解决方案。”
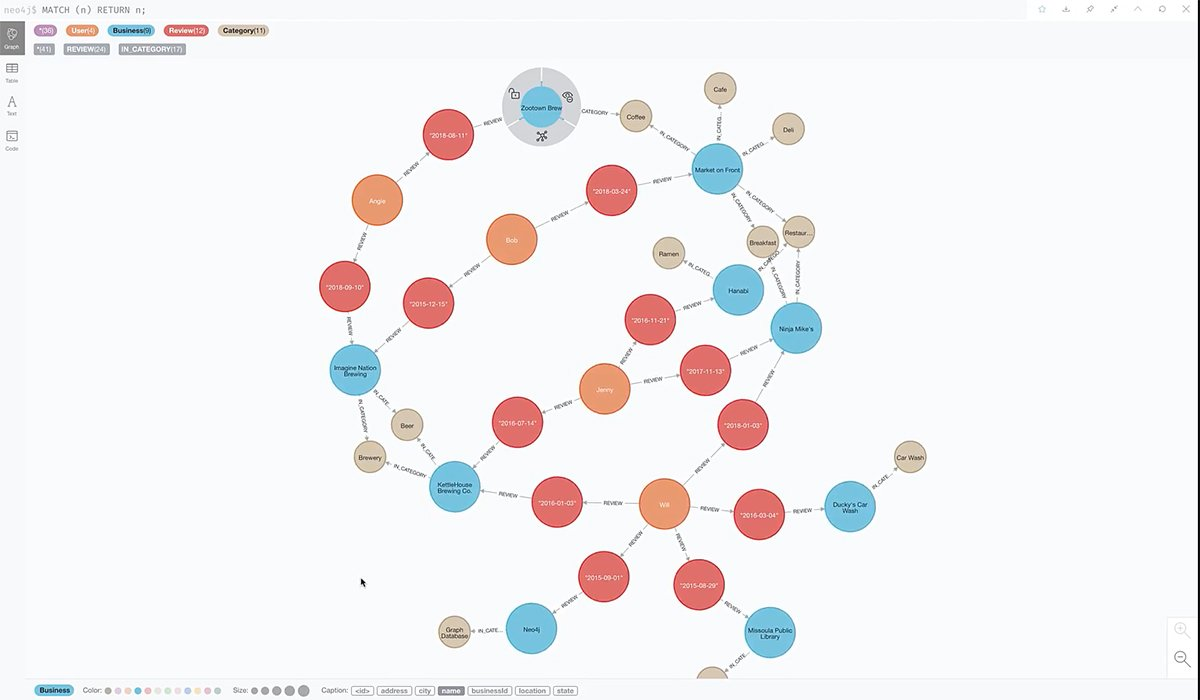
组织的数据集显示在 Neo4j 的图形数据库中
未来的计划
Hasbe 表示,继最近与 Vertex AI 集成并添加向量搜索和存储之后,Neo4j 计划继续添加生成式 AI 功能。
向量搜索和存储建立在与 Vertex AI 集成的基础上,通过在 Google 提供的非结构化数据转换功能中添加相似性搜索和向量存储来推进通过集成添加的功能。
Hasbe 指出,其主要目标之一是通过与 OpenAI 的生成式 AI 系统、Azure OpenAI 和 AWS Bedrock 密切合作,就像与 Vertex AI 一样密切合作,从而保持平台无关性。
“我们希望让这些功能随处可用,”他说。
哈斯贝继续说道,另一个目标可能是开发一种文本到密码工具。
Cypher 是 Neo4j 的图查询语言。正如Monte Carlo 和 Dremio 等供应商已经构建了将自然语言转换为SQL代码的文本到 SQL 工具一样,Neo4j 正在考虑开发一种将自然语言转换为 Cypher 代码的工具。
Hasbe 表示,除了生成式人工智能之外,Neo4j 还专注于与所有主要云数据平台的集成。
他说:“我们所有的客户都在迁移到云端,因此确保我们的所有产品都位于所有云平台上,并与所有云提供商以及领先的数据平台完全集成是当务之急。”
与此同时,Henschen 指出,多云关注对于 Neo4j 非常重要。
具体来说,他表示希望 Neo4j 添加到 AuraDB (该供应商的完全托管图形数据库服务)的多云和跨云功能中。
此外,他指出 Neo4j 明智的做法是继续向图形数据科学(供应商的机器学习工具)添加功能,以实现生成式 AI 的更多使用。
“对向量搜索的支持只是一个开始,”他说。“但要利用生成式人工智能来支持开发、优化、分析等并使之民主化,还有更多工作要做。”
文章作者:Eric Avidon 是 TechTargetEditorial 的高级新闻撰稿人,也是一位拥有超过 25 年经验的记者。他涵盖分析和数据管理。
文章来源:https://www.techtarget.com/searchdatamanagement/news/366549617/Neo4j-adds-vector-search-to-improve-generative-AI-outputs
