




公司的业务主要是B TO B 为商户服务的. 我们大约有750个商户,活跃的不多. 业务订单表每周20万单. 购买阿里云 RDS FOR MYSQL 5.7 8核16GB独享服务.
应用程序基本分为 运营端,销售端,商户端和交易端, 基本上算是4个微服务吧! 另外还有什么监控,作业微服务.
我规划了慢SQL基线,虽然RDS默认1秒就是慢SQL,并保存起来. 自然不是1秒就得去优化,有的伙伴规定的是5秒. 我这里的话规定,运营端是10秒, 销售和商户端是5秒,交易端是1秒. 主要是因为查数据量的大小和使用者身份不同来规划的. 毕竟运营端经常查大范围,全部商户的订单数据. 当然商户也会查自己过去某个月的数据,只是他们是我们的客户,身份贵重! 必须得到重视,使用慢给客户不好的体验,要在他们投诉之前优化掉,何况很多时候客户会用脚投票.
心得一 关联表
select count(*)from order aleft join b on a.merchant_no=b.merchant_noleft join c on a.channel_code=c.channel_codeleft join d on a.product_code = d.channel_codewhere 1=1and b.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?';
像这样的SQL 基本上属于分页统计总数的. 另外还有分页SQL. JAVA开发人员为了快速交付,喜欢用分页插件. 分页插件只是在分页SQL外面套一层子查询. 其实上面有一个表无需参与关联,也不妨碍最后得到的总数.
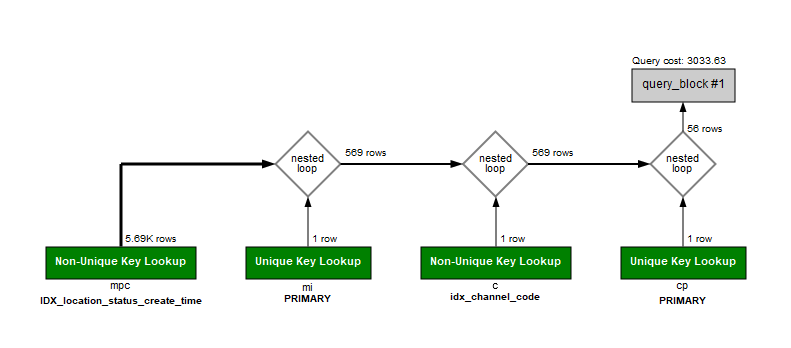
从图形执行计划看 主表5.69K 行 去跟三个表关联理论上来说,数据会越来越少. RDS计算方法是 乘法! 就是 A*B*C*D=5.69K*1*1*1 这里是指数.5.69K(千行)^3
以前ORACLE 算法是 乘法+加法.
(((A*B)*C)*D)=5.69K*1
=569*1
=569*1
=5.69K+569+569
所以此时优化重点就是 能不关联就不要去关联.通过JAVA MAP的IF 判断
select count(*)from order aleft join b on a.merchant_no=b.merchant_no<if parameter not null > <left join c on a.channel_code=c.channel_code >left join d on a.product_code = d.channel_codewhere 1=1and b.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?';
是什么原理呢? 或许我猜是 MYSQL是服务层和引擎层分离的
过滤条件在服务层处理, 而索引条件就下推到引擎层处理.
那么关联应该是在引擎层完成关联,
也就是先在引擎里做下面的关联
from order aleft join b on a.merchant_no=b.merchant_noleft join c on a.channel_code=c.channel_codeleft join d on a.product_code = d.channel_code
然后在服务层做过滤
where 1=1and b.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?';
这样就能解释通 为什么MYSQL的 LEFT JOIN 事实上是INNER JOIN
心得二 小表驱动
在ORACLE经验里,小表驱动大表 是天津第一的! 狗不理包子. 在MYSQL也是这样认为的.实际上小表驱动大表反而慢
select a.*from order aleft join b on a.merchant_no=b.merchant_noleft join c on a.channel_code=c.channel_codeleft join d on a.product_code = d.channel_codewhere 1=1and b.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?';
执行计划可能是 B JOIN A, JOIN C, JOIN D
因为按经典理论 B返回数量少,应该它做驱动表. 实际上它最终执行时间反而长. 为什么呢? 只要看源代码才明白一二! 也许你花费精力看源码,奥原来如此,结果人家在MYSQL8.0给顺手优化了.至于有没有优化,我没有证实! 公司主要业务跑在5.7上.另外两个项目跑在8.0.25上.数量不大,看不出来.
为了避免这种情况发生,我们使用STRAIGHT_JOIN 非标准链接.它按你的写法顺序去关联.
select a.*from order aSTRAIGHT_JOIN b on a.merchant_no=b.merchant_noSTRAIGHT_JOIN c on a.channel_code=c.channel_codeSTRAIGHT_JOIN d on a.product_code = d.channel_codewhere 1=1and b.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?';
心得三 ORDER BY
select a.*from order aSTRAIGHT_JOIN b on a.merchant_no=b.merchant_noSTRAIGHT_JOIN c on a.channel_code=c.channel_codeSTRAIGHT_JOIN d on a.product_code = d.channel_codewhere 1=1and b.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?'order by create_time desclimit 0,10;
5.7 这里 优化器可能会使用CREAT_TIME 索引,因为它觉得,是它觉得,通过索引可以避免排序操作 FILE SORT, 同时因为LIMIT 返回数量少.
那怕OPTIMER TRACE 反映出 CREAT_TIME 索引成本高昂, 最优索引是PAY_TIME. 实际上要跑6秒钟,因为符号条件的数据量非常少,所以要找全,则要扫描整个CREATE_TIME索引. 就是说把CREATE_TIME索引下推到引擎上,引擎每返回数据,服务层都说NO,继续帮忙扫描.其实优化器这里没有使用CBO成本去考虑.
该怎么优化才好呢? 也许MYSQL 8.0 的直方图能解决此排序问题.
如果删除索引,觉得不太合适,或许其它SQL也会受其影响.
心得四 注意值的范围
什么是值的范围? 是时间条件的具体值变长后,它会自动改变执行计划,原来通过索引的,现在变成了其它!
select a.*from order aSTRAIGHT_JOIN b on a.merchant_no=b.merchant_noSTRAIGHT_JOIN c on a.channel_code=c.channel_codeSTRAIGHT_JOIN d on a.product_code = d.channel_codewhere 1=1and b.subname='微信'and a.create_time >='2022-01-01' and a.create_time <='2022-01-31'and a.pay_time >='2022-01-01' and a.pay_time <='2022-01-02'and a.merchant_no='009'order by create_time desclimit 0,10;
和 a.pay_time <='2022-01-15'
select a.*from order aSTRAIGHT_JOIN b on a.merchant_no=b.merchant_noSTRAIGHT_JOIN c on a.channel_code=c.channel_codeSTRAIGHT_JOIN d on a.product_code = d.channel_codewhere 1=1and b.subname='微信'and a.create_time >='2022-01-01' and a.create_time <='2022-01-31'and a.pay_time >='2022-01-01' and a.pay_time <='2022-01-15'and a.merchant_no='009'order by create_time desclimit 0,10;
心得五 痛苦的SQLID
对于ORACLE DBA来说 没有SQL_ID 和绑定变量的分离,以及SQL_ID跟执行计划的绑定.MYSQL真心没法下手!
心得四 该怎么优化,我也难下手,MYSQL 没有绑定变量这一手法, MYSQL直接收到上面的具体的值的SQL
这样的. 虽然JAVA 使用?号 进行占位符. MYSQL也可以使用PS库看到通过占位符对SQL进行归类
select a.*from order aSTRAIGHT_JOIN b on a.merchant_no=b.merchant_noSTRAIGHT_JOIN c on a.channel_code=c.channel_codeSTRAIGHT_JOIN d on a.product_code = d.channel_codewhere 1=1and b.subname='微信'and a.create_time >='2022-01-01' and a.create_time <='2022-01-31'and a.pay_time >='2022-01-01' and a.pay_time <='2022-01-15'and a.merchant_no='009'order by create_time desclimit 0,10;
实际上 最终是每个值编译下,形成自己的执行计划.
ORACLE 通过绑定变量方式,让每个SQL共享一个执行计划.
类似这样的SQL 在ORACLE基本上共享一个执行计划.
select a.*from order aSTRAIGHT_JOIN b on a.merchant_no=b.merchant_noSTRAIGHT_JOIN c on a.channel_code=c.channel_codeSTRAIGHT_JOIN d on a.product_code = d.channel_codewhere 1=1and b.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?'order by create_time desclimit 0,10;
有些情况下可能是多个执行计划,通过偷窥变量和直方图生成最低成本的执行计划.
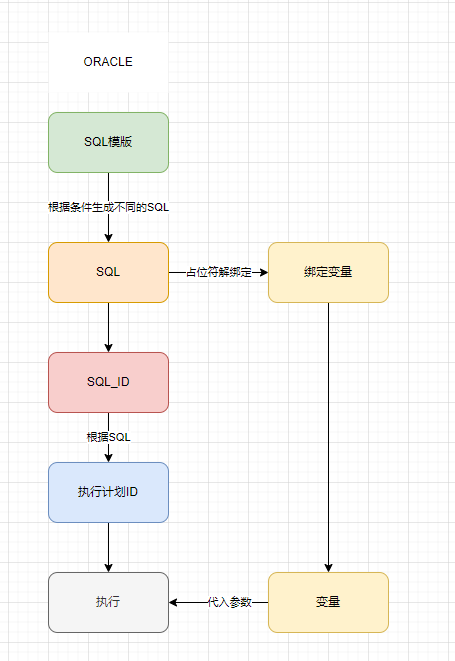
MYSQL 就非常直接
这样话 你不可能在数据库端 针对不同具体的SQL进行优化,没有ORACLE的SQLID和执行计划任意绑定.
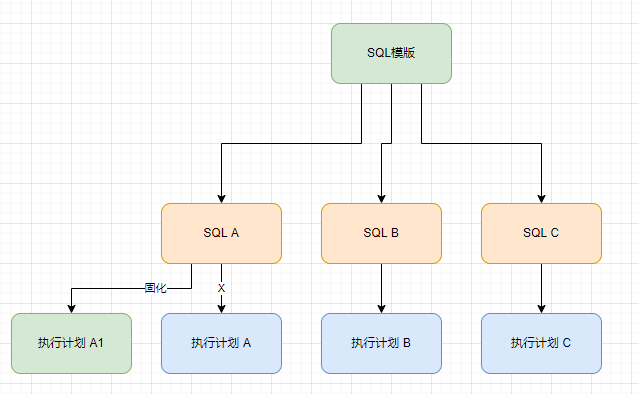
显然MYSQL没有这方面功能, 唯一能动的只要模版了,把一个模版做出多个模版. 或许还可以通过JAVA各种IF判断,形成更多的SQL.不过这样可读性非常差.
心得六 宽表
比如说你的业务表去关联字典表,使用其中一个字段,或者用来过了,比如说上面的
select count(*)from order aleft join b on a.merchant_no=b.merchant_nowhere 1=1and b.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?';
按照我们的心得,能不关联,最好不要关联.在ORACLE这里关联咋了,这能算啥事呢? 哎 在MYSQL里不关联 还真心快,汉人不骗汉人. 所谓宽表,我们把B表的 SUBNAME加到A表里去! 这样一来就不用关联呀!
select count(*)from order awhere 1=1and a.subname='?'and a.create_time >='?' and a.create_time <='?'and a.pay_time >='?' and a.pay_time <='?'and a.merchant_no='?';
如果不这样做,无法优化有条件的关联, 同时它又是小表,一不小心它就变成了驱动表. 走STARGE_JOIN 野路子也不太好! 毕竟20万*4*750次 表关联,就变成了小于20万*4次.
当然这是一件大工程,比如先对A表在夜晚添加字段, 添加字段属于REBUILD行为,要观察硬盘空间是否足够. 另外在对旧数据进行关联更新,且要分批更新. 最后还要把SUBNAME加入某些索引里去.
所以这是个辛苦活,不够能得到巨大回报的!
自然 你要做个概率统计下,哪些表经常被业务关联,且里面必须的字段,才能最大收益!
扩展阅读:
用SHELL输出HTML的MYSQL巡检
MYSQL AWR 报表
MYSQL 安全更新测试
MYSQL 产生大量数据的过程
MYSQL LEFT JOIN 优化
MYSQL 加字段优化
MYSQL 字符集优化
MYSQL ID 的混乱星海
MYSQL8.0索引算法问题
MYSQL排序ORDER BY
