




你们关心功能, 我来提升性能, 这里是<老虎刘谈SQL优化>, 今天介绍的这个案例来自一个金融行业的生产系统.
我在对系统做主动性能检查时,发现了一个执行时间长达30多秒的SQL, 3个相关表的记录数都只有几十万条, 可能存在较大的优化空间. 经过分析,并与业务人员进行沟通, 我对SQL进行了改写(两种方法), 改写后的SQL执行效率都有几十倍的提升.
下面是生成Test Case的脚本(测试环境:数据库版本19.17, Linux虚拟机@笔记本):
--创建两个表(结构都一样):create table T_DEMO_648_QDII_H(i_code varchar2(20),beg_date date,end_date date,DP_CLOSE number);create table T_DEMO_648_Wind_W(i_code varchar2(20),beg_date date,end_date date,DP_CLOSE number);--为 T_DEMO_648_QDII_H表(以下简称H表)生成 74.4万记录,--大概占用存储空间24Mdeclarev_beg_date date :=date'2010-01-01';v_end_date date :=date'2023-08-01';c_date date;beginfor i in 1..150 loopc_date:=v_beg_date;while v_end_date>c_date loopinsert into T_DEMO_648_QDII_H values('C'||lpad(i,3,'0'),c_date,c_date+1,round(dbms_random.value(1,10)));c_date:=c_date+1;end loop;end loop;commit;end;/---为T_DEMO_648_Wind_W表(以下简称W表) 生成34w+记录,--大概占用存储空间12Mdeclaren number;v_beg_date date :=date'2010-01-01';v_end_date date :=date'2023-08-01';c_date date;beginfor i in 1..150 loopc_date:=v_beg_date;while v_end_date>c_date loopn:=round(dbms_random.value(0,1)*0.6)*7+1;insert into T_DEMO_648_Wind_W values('C'||lpad(i,3,'0'),c_date,c_date+n,round(dbms_random.value(1,10)));c_date:=c_date+n;end loop;end loop;commit;end;/--收集两表统计信息:exec dbms_stats.gather_table_stats(user,'T_DEMO_648_QDII_H');exec dbms_stats.gather_table_stats(user,'T_DEMO_648_Wind_W');
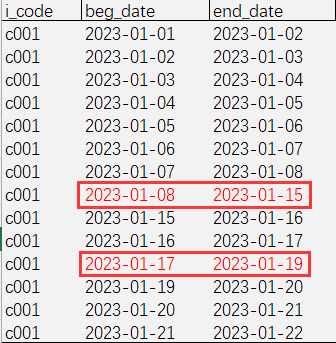
通过观察W表的数据分布并得到业务人员确认:对于同一个I_code值的每一条记录, 大部分记录的end_date比beg_date大一天, 少量记录的间隔会大于一天; 日期范围不存在交叉. 部分记录如下图所示:
业务SQL(做了简化处理, 用count是为了方便测试):
select count(w_dp_close) from(select h.*,w.dp_close as w_dp_closefrom T_DEMO_648_QDII_H HLEFT JOIN T_DEMO_648_Wind_W WON H.I_CODE = W.I_CODEAND W.BEG_DATE <= H.BEG_DATEAND W.END_DATE > H.BEG_DATE);
SQL执行时间47秒+, 执行计划如下:

根据业务SQL的实现逻辑与相关表的数据分布规律, 老虎刘给出如下两种优化改写方法:
优化方法1:
使用connect by将W表日期间隔大于1天的记录, 拆分成多条一天间隔的记录,然后做等值关联, 改写后的SQL执行时间为1.84秒.
select count(w_dp_close)from(select h.*,x.dp_close as w_dp_closefrom T_DEMO_648_QDII_H Hleft join(select i_code,w.beg_date+level-1 as beg_date,end_date ,w.dp_closefrom T_DEMO_648_Wind_W Wconnect by level<=end_date-beg_dateand prior rowid=rowidand prior dbms_random.value is not null)xon h.i_code=x.i_code and h.beg_date=x.beg_date);
SQL对应执行计划如下:

优化方法2:
使用区间检索+标量子查询, 这个写法需要W表上创建对应的索引来配合, 执行时间1.39秒.
create index idx_T_DEMO_648_Wind_W_1 on T_DEMO_648_Wind_W(i_code,end_date);select count(w_dp_close)from(select H.*,(select dp_close from(select w.dp_close,w.beg_datefrom T_DEMO_648_Wind_W Wwhere H.beg_date<W.end_date and H.i_code=W.i_codeorder by W.end_date)xwhere rownum<=1 and H.beg_date>=x.beg_date) as w_dp_closefrom T_DEMO_648_QDII_H H);
SQL对应执行计划如下:

很多数据库中都隐藏着大量的低效SQL等待优化处理, 是时候找个专业人士做个检查了.
(全文结束)
文章转载自老虎刘谈SQL优化,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
